

Memory For AI Agents: Everything That You Need To Know (Part-1)
Part 1: What is Memory and why do modern-day AI systems need it?


🎁 Become a paid subscriber to ‘Into AI’ today at a special 25% discount on the annual subscription.
LLMs are stateless. This means that their state is not permanent and refreshes with each session. This is why LLMs do not remember past interactions between sessions.
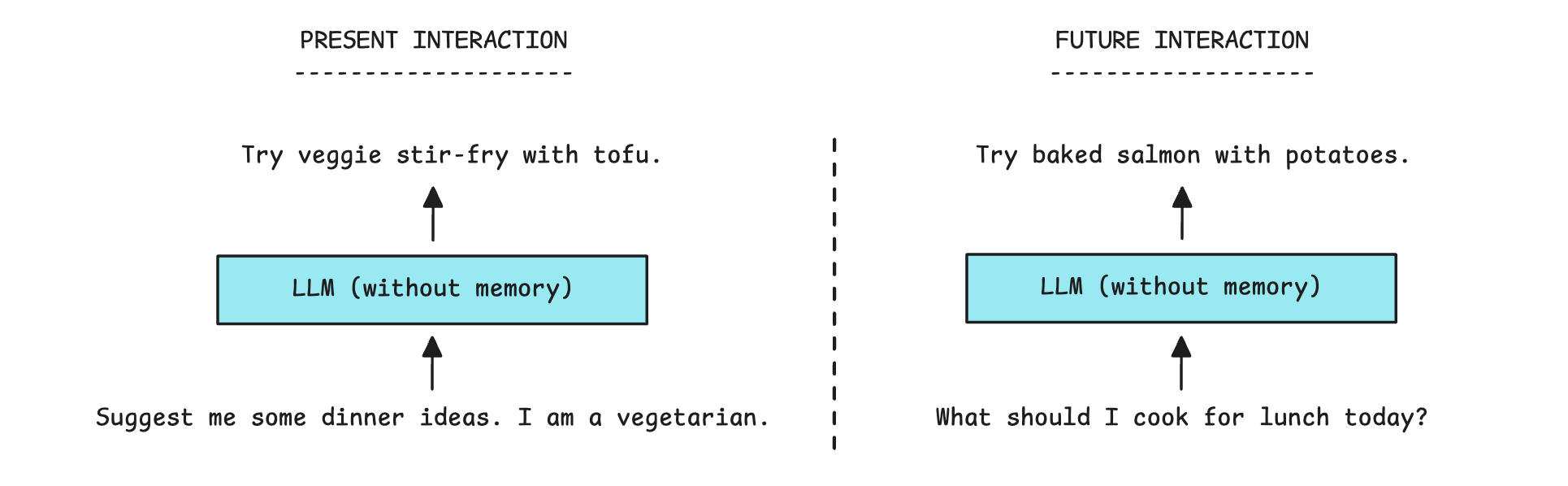
AI Memory systems aim to fix this problem. They help LLMs retain and use past information. This helps them stay relevant, learn over time, and respond more consistently in user interactions, grounded in truth.
What are the different types of Memory?
Modern-day AI memory systems are based on how humans store and retrieve knowledge.
The Soar cognitive architecture is one of the earliest and most comprehensive attempts to model human-like intelligence in agents (in our case, an LLM).
According to it, there are two types of memory:
Working memory, or Short-term memory, which holds information about what the agent is thinking about during ongoing problem-solving.
Long-term memory, which is further divided into three:
Procedural memory: This stores rules or skills that can be applied to working memory to determine the agent’s behavior.
Semantic memory: This stores general facts and knowledge about the world.
Episodic memory: This stores sequences of the agent’s past behaviors and interactions.
Learn about this architecture makes discussing memory in LLMs easier.
Are LLMs completely memoryless?
It’s not that LLMs lack all sorts of memory by default.
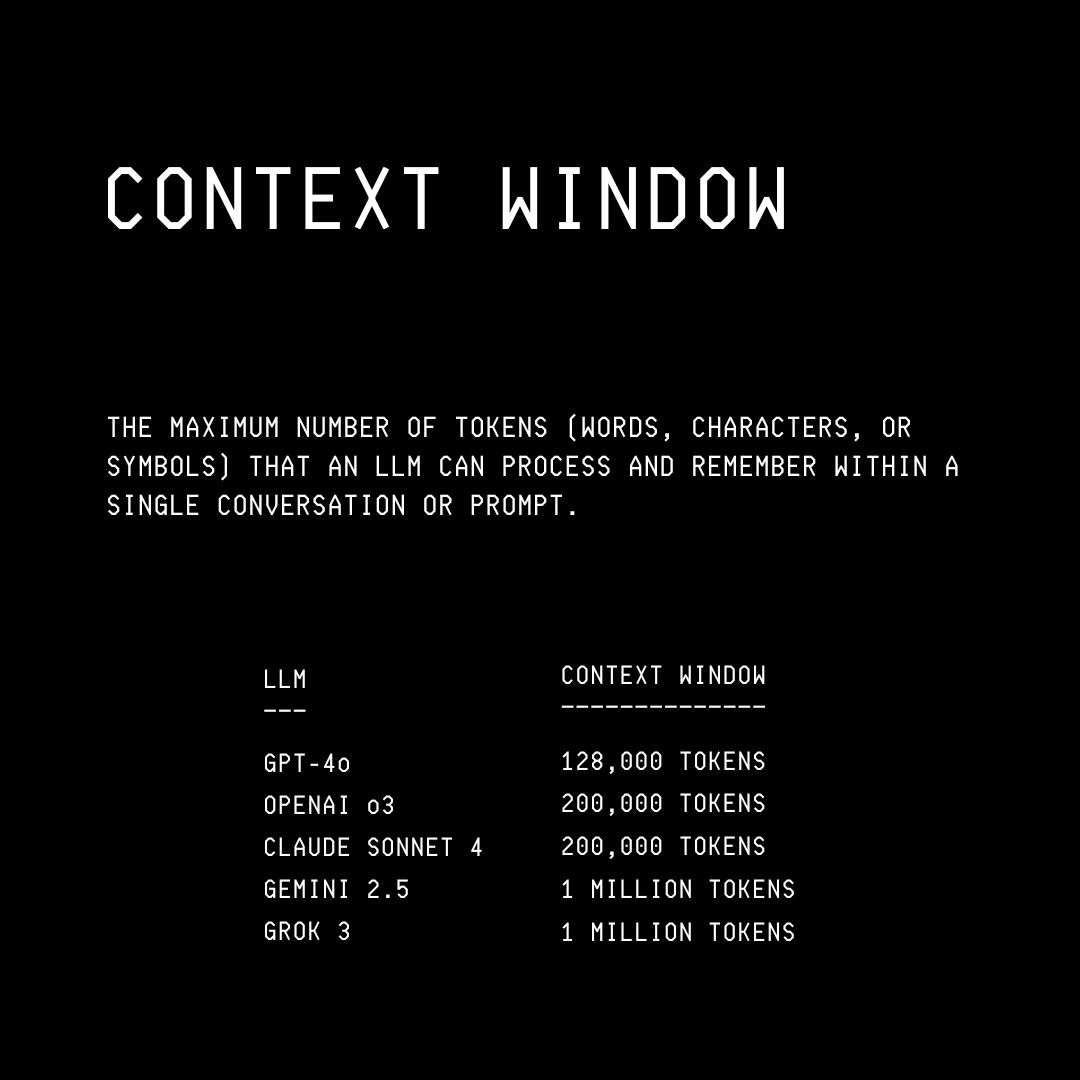
LLMs have a context window that stores information about an ongoing conversation with a user/ another agent. The context window is the maximum length of input an LLM can consider at once.
This acts as an LLM’s Short-term or Working memory.
The context window is a limited space for storing short-term information, but recent LLMs have really pushed its boundaries.
LLMs like Google’s Gemini 2.5 and xAI’s Grok 3 have a context window of 1 million tokens, which means that they can process up to 1,500 pages of text or 30K lines of code simultaneously!
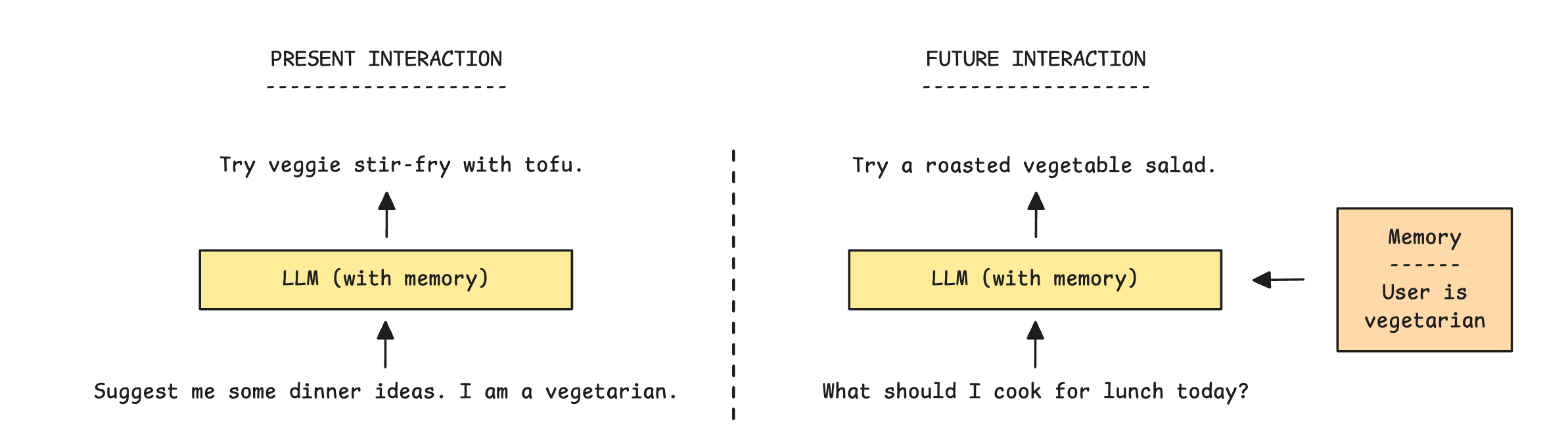
Alongside this, LLMs have something called Parametric memory, which is the knowledge that is stored directly in their parameters / weights as a result of training.
For example, if you ask an LLM about the capital of the UK, it will respond with London.
This is an LLM’s Long-term memory (specifically Procedural and Semantic memory).
Note that Procedural memory also includes an LLM’s system prompt that persists across sessions.
If LLMs already have memory, why do we need more?
Sure, LLMs can use their context window as their working/ short-term memory, but this is limited.
Meaningful human interactions and relationship-building take place over a long period (weeks, months, or years). As conversations accumulate and get longer, the context window fills up pretty quickly.
There is also no thematic continuity in conversations, which means a person could talk about writing code one day, then describe how sad and lonely they feel about a past relationship, and then return to writing code another day.
Even if we capture this interaction information in the context window, store it in a persistent database (creating Long-term memory), and reload it each time, such a discontinuity in the conversational theme in a huge conversation trail creates a messy context (a phenomenon called Context Rot).
Even with a million-token context window, LLMs cannot always accurately extract the most meaningful information from such a context in their context window.
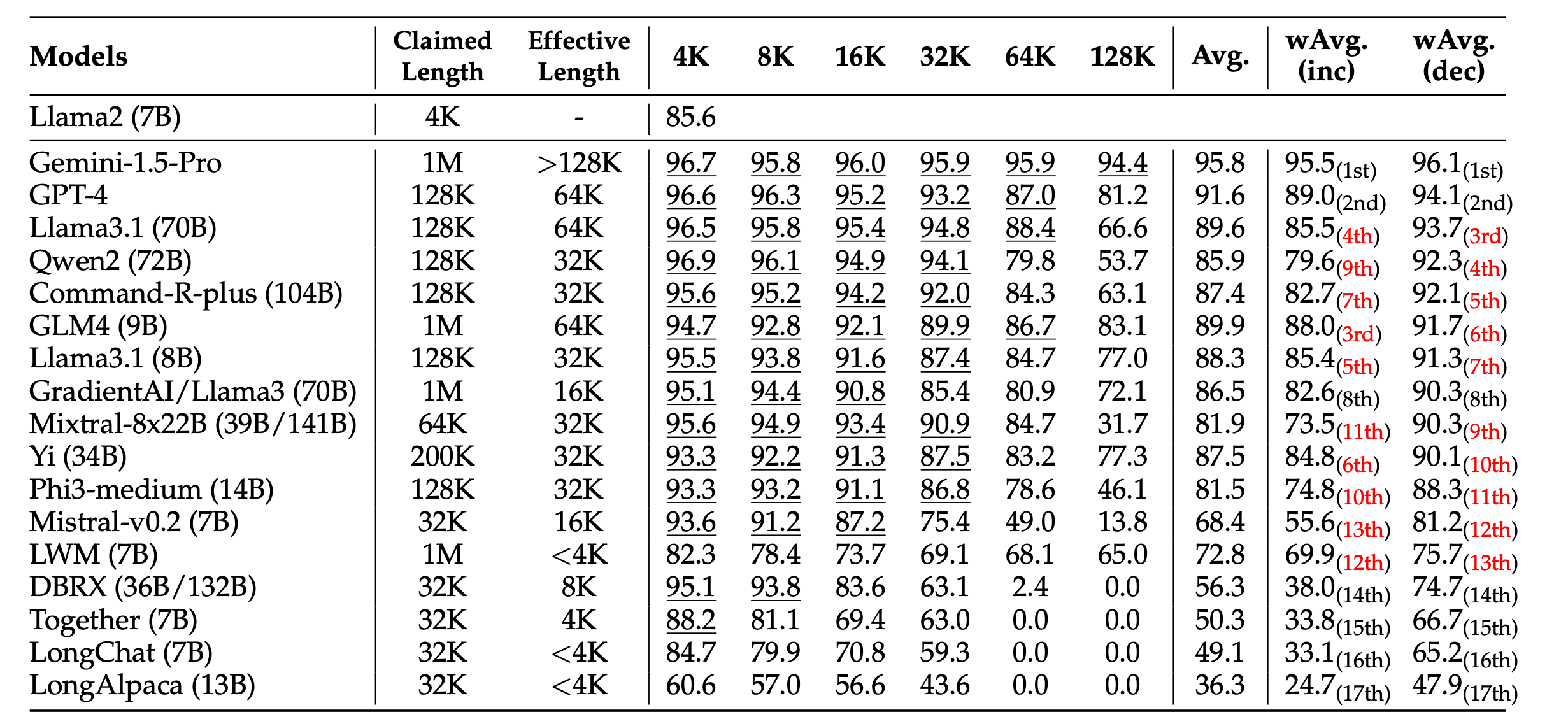
Check out the Needle-in-a-Haystack (NIAH) analysis of GPT-4, which checks whether the model can find a small, specific fact (‘Needle’) hidden somewhere in a very long context (‘Haystack’).
GPT-4 performs very poorly on retrieval accuracy as context length increases.

{kind=link}
Many modern-day LLMs have significantly improved on the NIAH test and show nearly perfect accuracy, but they still perform poorly on more comprehensive benchmarks like RULER.
RULER checks how well an LLM can really use a long text context (information tracking, aggregating, and reasoning across long contexts), and not just find bits of information in it.
It seems that pushing the limits of context length only delays, rather than resolves, the fundamental limitation.
That’s about the problems with LLM’s current short-term memory and using it towards building long-term memory.
There’s another way where we can directly update an LLM's long-term memory. This is with mid-training and post-training methods, but this is an expensive process (in terms of time, money, and compute).
And even if we try to do this, there’s the curse of Catastrophic forgetting, where LLMs can abruptly and drastically forget previously learned information upon being trained with new information.
This is why AI needs memory that goes beyond just longer context windows.
A robust AI memory should:
Selectively store important information
Connect related information
Provide the right information when needed
Forget information that is not frequently needed over a long period
much like how humans remember things.
With this type of memory, an LLM-based AI system can stay consistent, remember user preferences, build on past conversations, and become a reliable long-term partner that grows with the user.
That’s everything for the first part of this series on AI memory.
In the next one, we will discuss a memory system called Mem0 in depth, which acts as a universal, self‑improving memory layer for LLM applications.
Upgrade to a paid subscription today and use ‘Into AI’ as your unfair advantage:
Check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
