

Diffusion LLMs, Explained Simply
A gentle but comprehensive introduction to Diffusion LLMs.


LLM-based chatbots are all around us. They reply by producing their responses sequentially. This means that they generate their output token by token, one at a time.
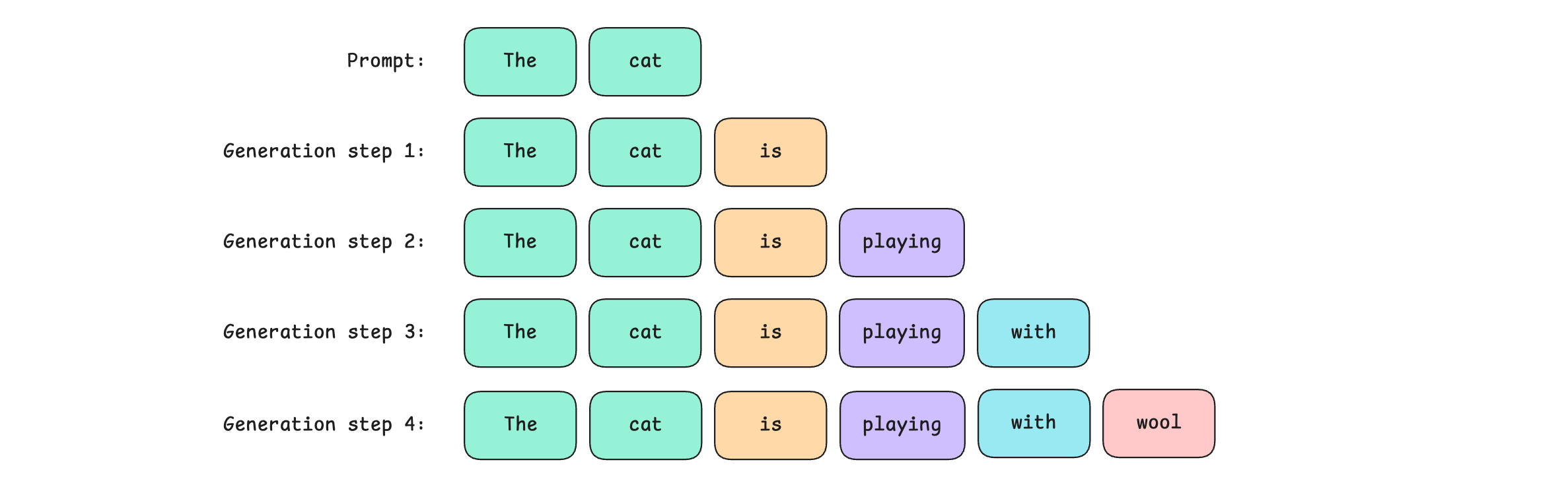
This makes them painfully slow (For a computer engineer, increasing execution speed is one of their wildest dreams).
The reason is that their underlying architecture, the Transformer, is an autoregressive model that at each step of text generation answers this simple question:
Given all previous tokens, what is the probability distribution of the next token over the entire vocabulary of the model?
This is the Next-token prediction objective.
For the prompt shown above: “The cat”.
At the first step of generation, the model could produce a probability distribution and select the token with the highest probability, as shown below.
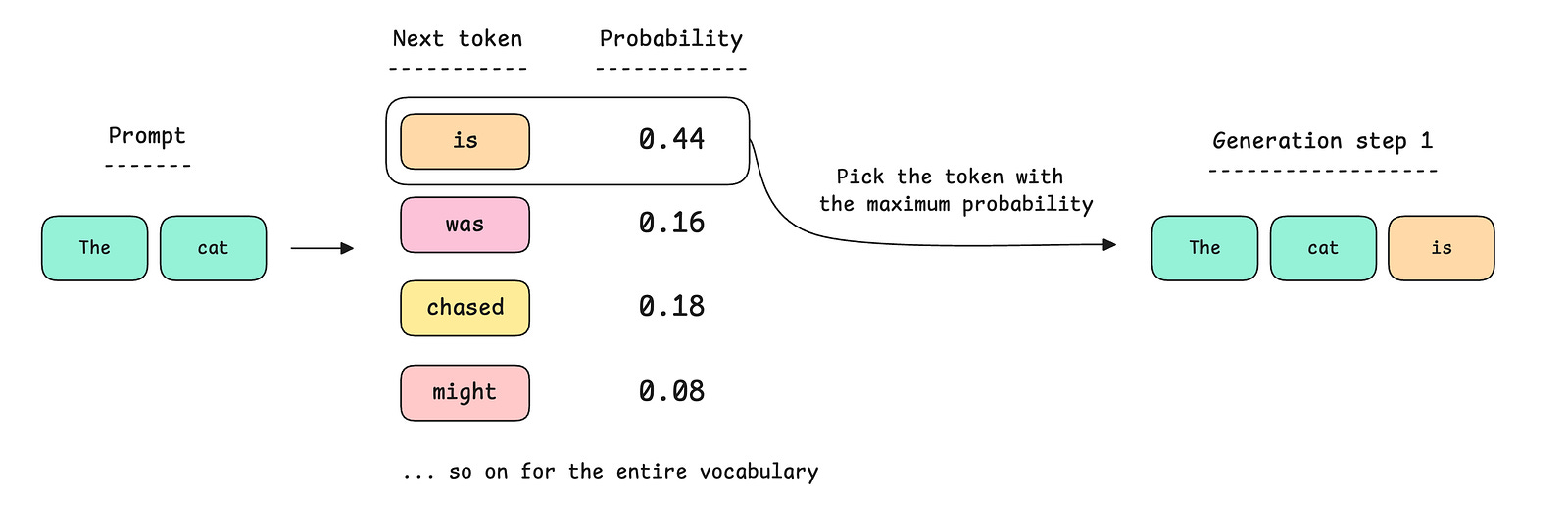
The selected token is then added to the original prompt, and the process repeats until the LLM finishes generating its output.
Is this the only way to generate tokens?
What if we could generate tokens all at once, i.e., in parallel?
Yes, it is possible, and this is something that Diffusion LLMs do, using a process called “Diffusion” (duh).
Diffusion is actually a physical process in which particles from regions of higher concentration move to regions of lower concentration, eventually dispersing evenly to an equilibrium state.
Image generation models are inspired by this principle. These models are trained for using two diffusion processes as follows:
Forward Diffusion: The model starts with input data (an image) and incrementally (in multiple timesteps) adds Gaussian noise until the data becomes completely random.
In other words, this means changing the pixel values of the input image until it becomes pure noise.Reverse Diffusion: In this phase, a neural network learns to reverse the noise-addition process by predicting the added noise at each timestep during the forward diffusion process.
In other words, this means recreating the original pixel values of the input image from pure noise.
These processes are controlled by a Noise schedule, which defines the rate at which noise is added to the data (forward diffusion) or removed from the data (reverse diffusion/denoising process) across different timesteps.
Once the diffusion model is fully trained, it can generate new image samples from pure noise.

While Diffusion is commonly used in image generation models, it is increasingly being applied to language models.
To apply Diffusion, we would need to learn how to make the tokens noisy first. But how do we do this, since tokens are discrete rather than continuous, like the pixel values of an image?
How to apply Diffusion to text?
