

🗓️ This Week In AI Research (15-21 February 26)
The top 10 AI research papers that you must know about this week.

🎁 Before we start, I want to offer you a 35% DISCOUNT on the annual subscription to ‘Into AI’ as part of the Fab Feb offer. It’s only valid till the end of February, so don’t wait up!
1. Gemini 3.1 Pro
Google released Gemini 3.1 Pro, a new model in the Gemini 3 series with advanced reasoning capabilities for complex problem-solving.
3.1 Pro achieved a verified score of 77.1% on ARC-AGI-2. This is more than double the reasoning performance of its predecessor, 3 Pro.

Read more about this release using this link.
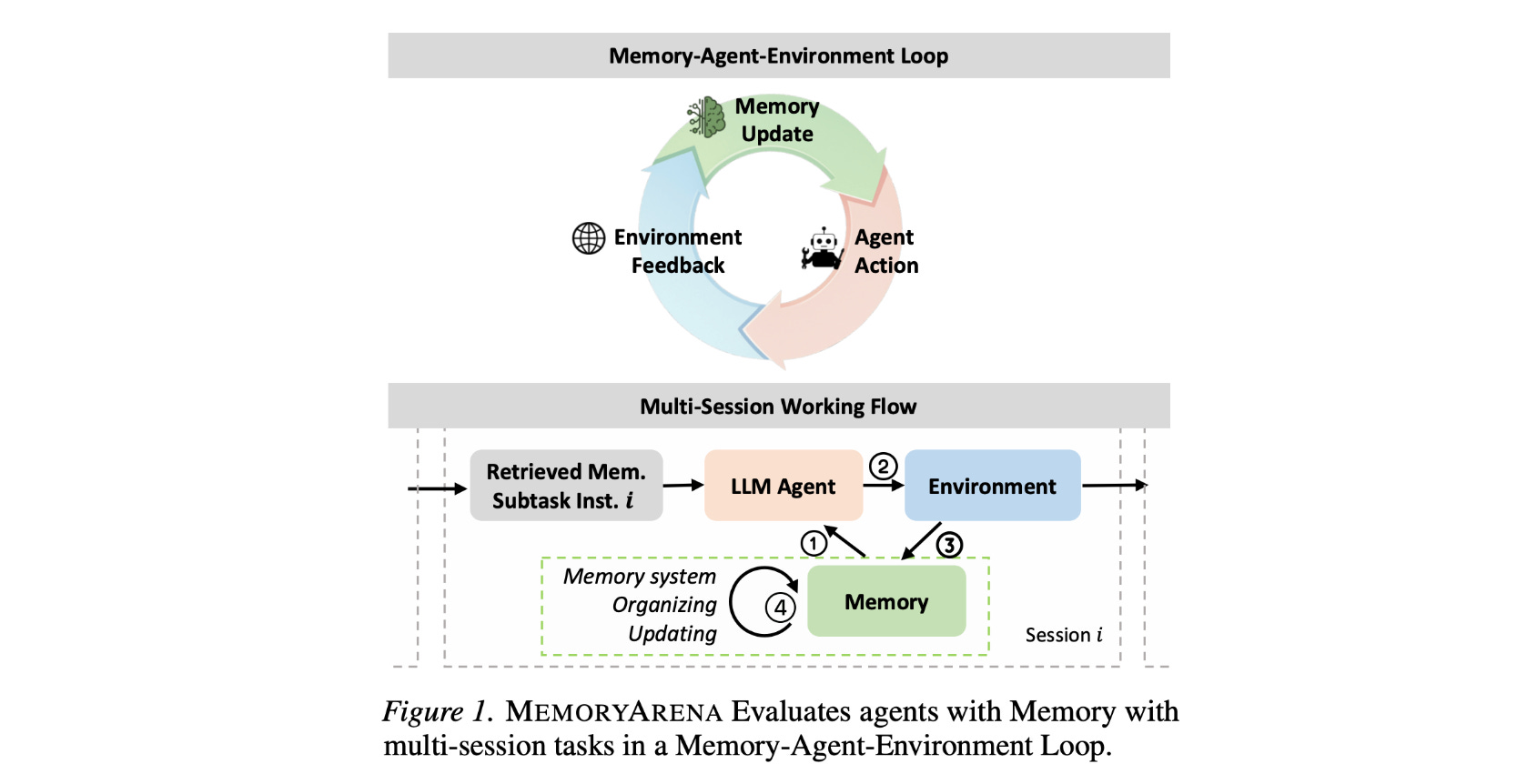
2. MemoryArena
Current evaluation methods of agents test either one of the following in isolation:
Memorization: Recall of past conversations, but not capturing how memory is used to guide future decisions
Action: Agent acting in single-session tasks without the need for long-term memory
In reality, memorization and action are tightly coupled. MemoryArena is a new benchmark that assesses this setting by testing agents' memory in multi-session tasks that require remembering and using information from earlier sessions to succeed in later ones.
MemoryArena covers four domains:
Bundled Web Shopping
Group Travel Planning
Progressive Web Search, and
Sequential formal reasoning in math/ physics
Results show that while many agents might perform flawlessly on existing memory benchmarks, such as LoCoMo, they do not perform well on MemoryArena.
Alongside this, external memory and RAG systems do not consistently improve the performance of these agentic systems. This reveals a major issue that current benchmarks do not adequately test agents in real-world settings.
Read more about this research paper using this link.
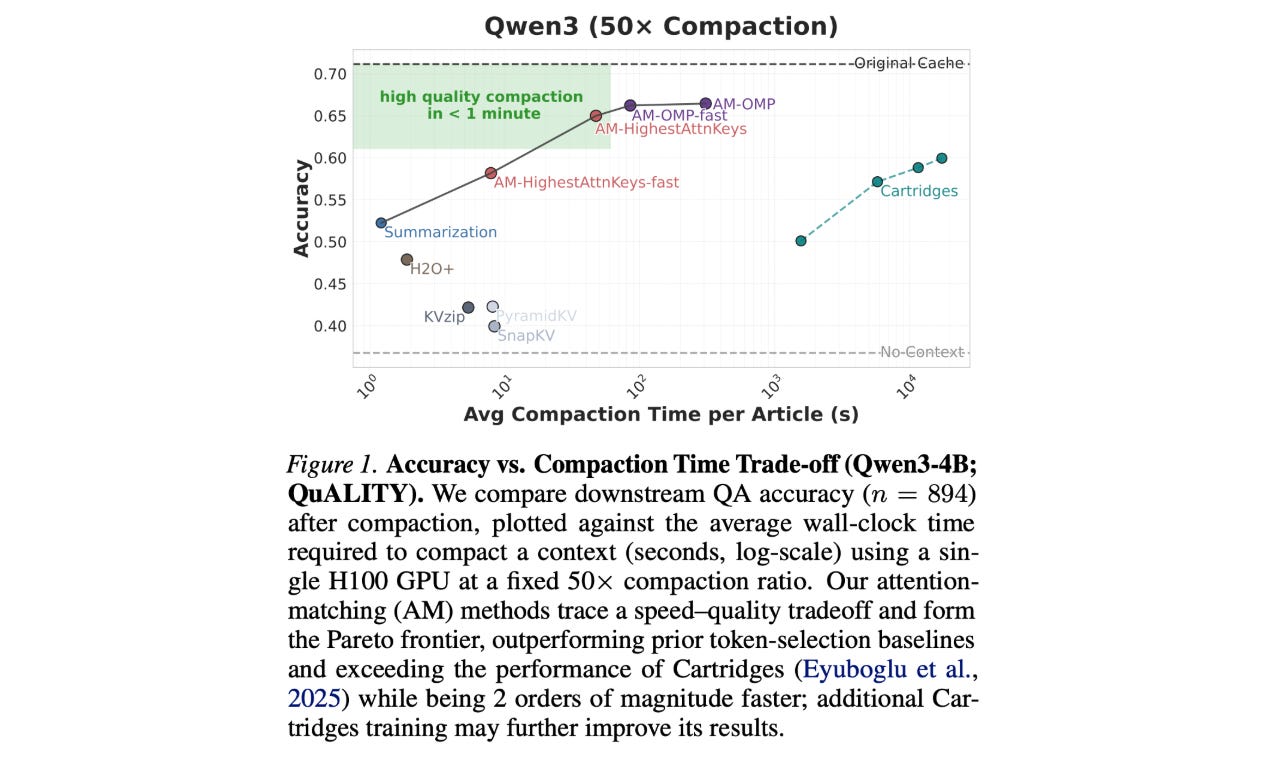
3. Fast KV Compaction via Attention Matching
Scaling LLMs to long contexts is bottlenecked by the size of the KV cache. To address this, in deployed models, long contexts are usually compacted using summarization or token dropping, which degrades performance.
This research paper addresses this problem by introducing a method for fast context compaction in latent space using Attention Matching.
This constructs compact keys and values to reproduce attention outputs and preserve attention mass at a per-KV-head level.
The approach breaks down into efficient subproblems with many closed-form solutions, which enables KV compaction ratios of up to 50x in seconds with minimal loss in quality. These results are orders of magnitude faster than previous latent-space methods.
Read more about this research paper using this link.
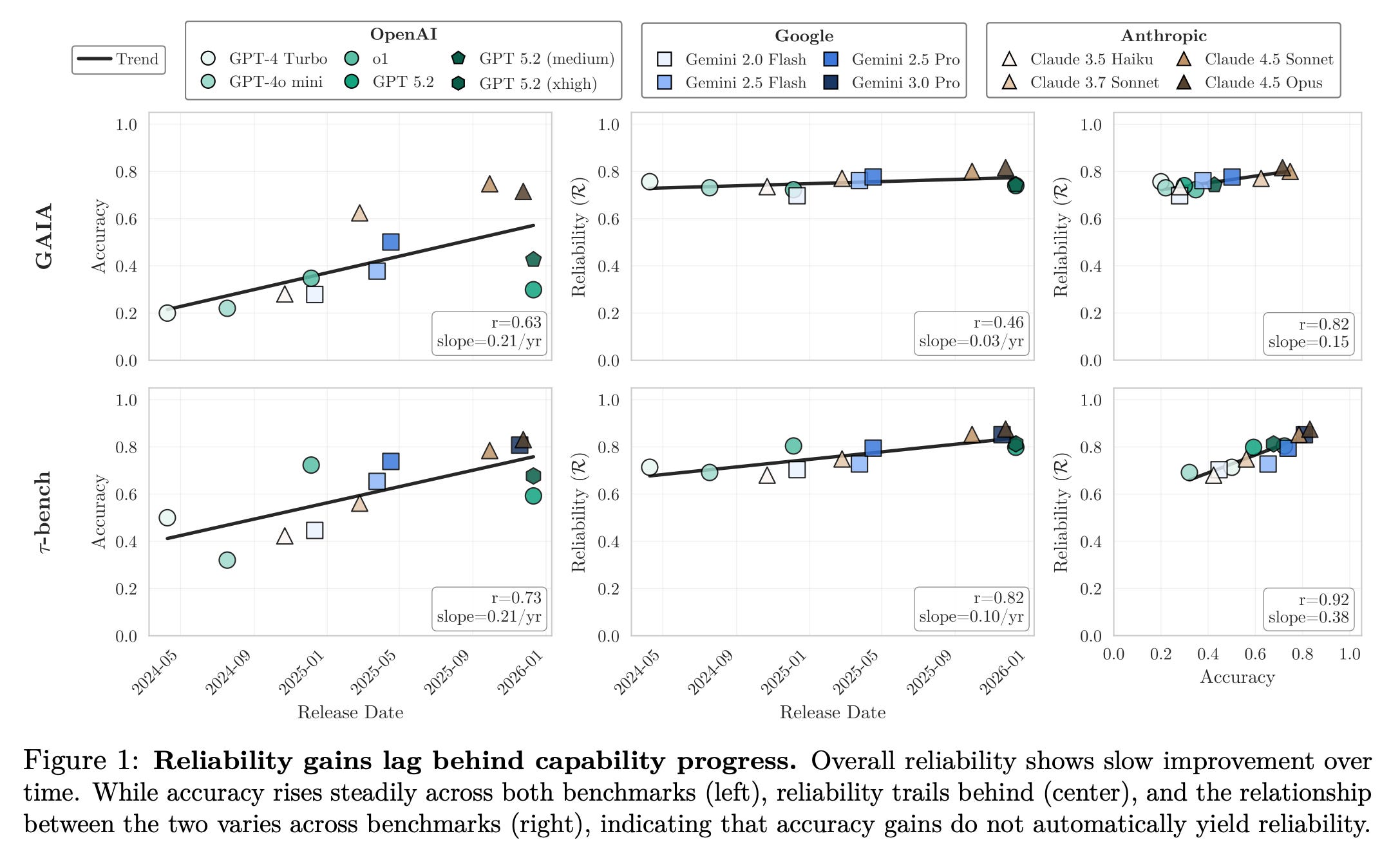
4. Towards a Science of AI Agent Reliability
The difference between AI agents' performance on benchmarks and in the real world is quite striking. This is because current benchmarks test agent behavior using a single success metric (accuracy), which hides many of their critical operational flaws.
This research paper addresses this by proposing 12 specific metrics that test agent reliability along four key dimensions:
Consistency
Robustness
Predictability
Safety
An evaluation of 14 agentic models across two complementary benchmarks shows that recent capability gains yield only small improvements in reliability, with consistency and predictability lagging the most.
Read more about this research using this link.
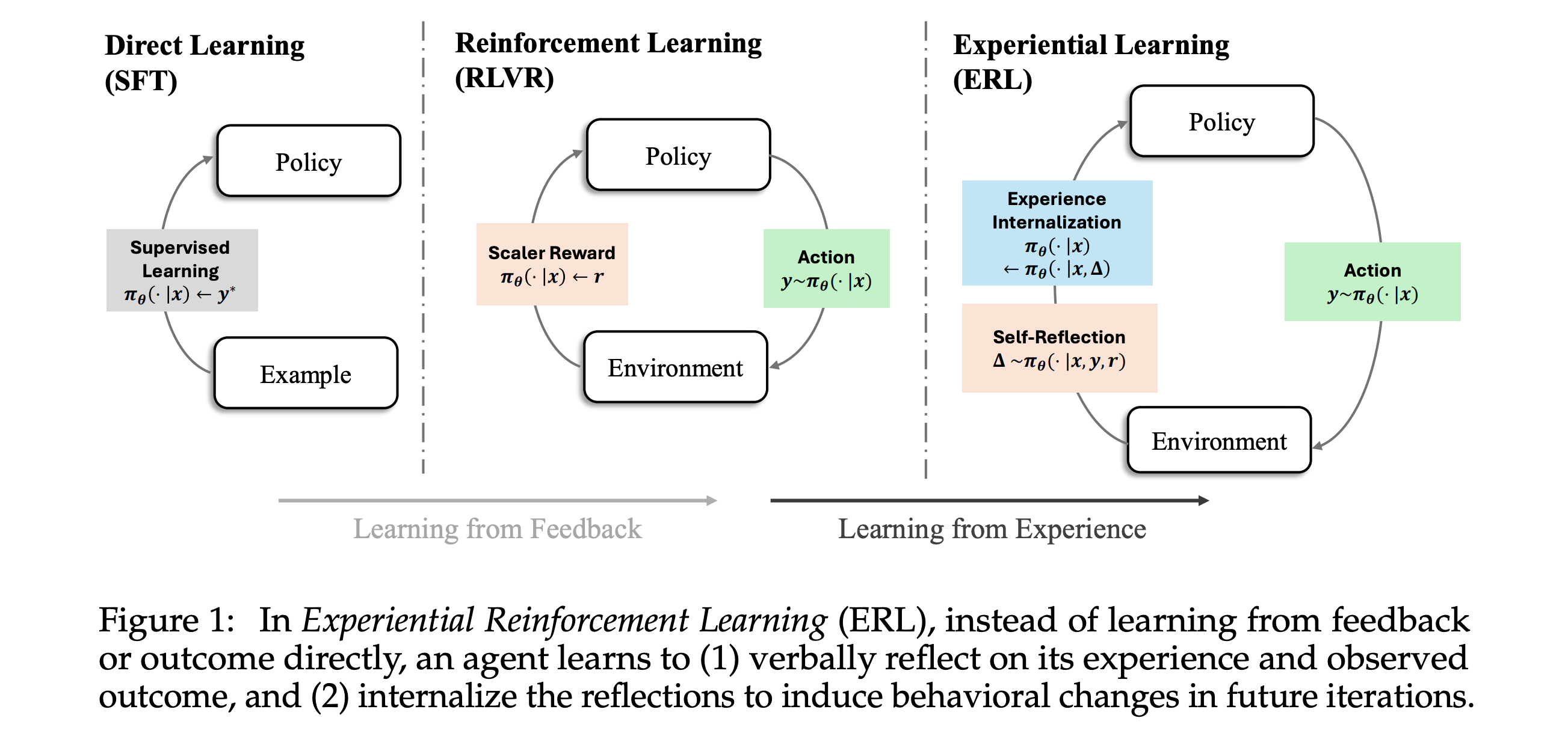
5. Experiential Reinforcement Learning
This research paper introduces Experiential Reinforcement Learning (ERL), a new training approach for LLMs that includes an explicit experience–reflection–consolidation loop into the RL process.
For a given task, ERL has a model generate its first attempt. The model then receives environmental feedback and generates a self-reflection conditioned on this attempt, which guides it to produce a more refined second attempt.
Both attempts and reflections are optimized with RL, while successful second attempts are internalized via self-distillation, so the model learns to reproduce improved behavior directly from the original input without self-reflection.
Across sparse-reward control environments and agentic reasoning benchmarks, ERL improves learning efficiency and final performance over strong RL baselines.
The gains are of up to +81% in complex multi-step environments and up to +11% in tool-using reasoning tasks.
Read more about this research using this link.
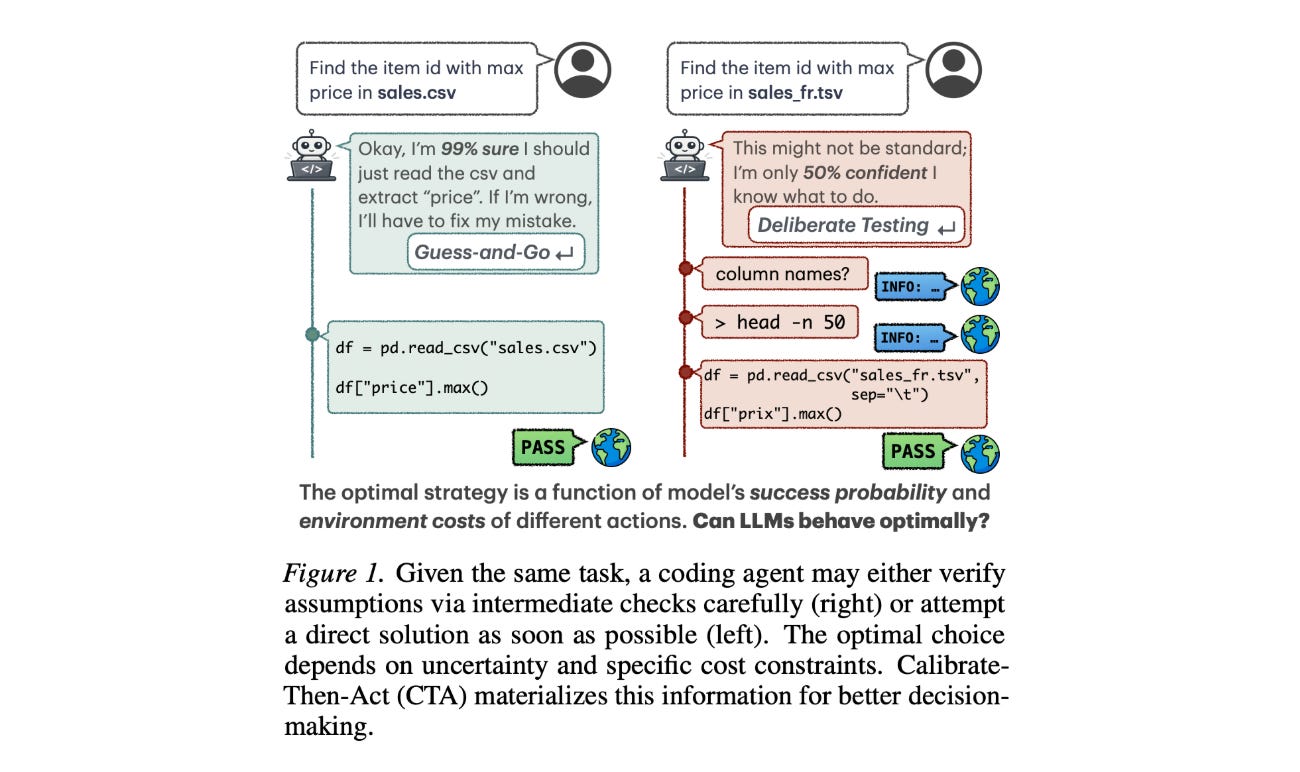
6. Calibrate-Then-Act
Solving complex problems requires LLM-based agents to interact with an environment to gather information.
This research paper introduces a framework that enables agents to balance this exploration cost and uncertainty when interacting with an environment, thereby performing more optimal environment exploration.
Multiple tasks are formalized as sequential decision-making problems under uncertainty. Each problem has a latent environment state that can be reasoned about via a prior. The framework, called Calibrate-Then-Act (CTA), then feeds the LLM this additional context to enable it to act more optimally.
Results on information-seeking QA and on a simplified coding task show that making cost-benefit tradeoffs explicit with CTA can help agents discover more optimal decision-making strategies.
Read more about this research using this link.
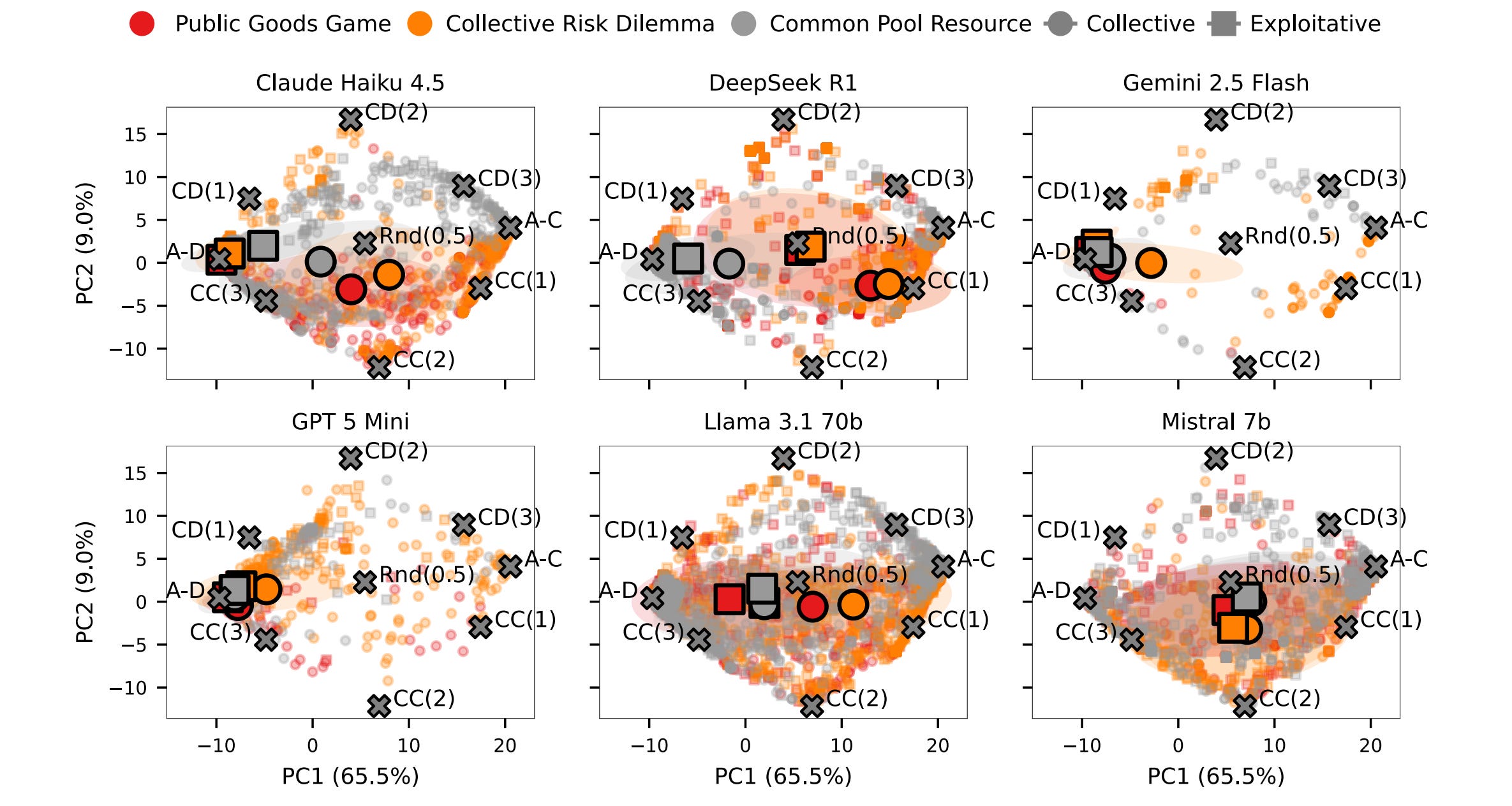
7. Evaluating Collective Behaviour of Hundreds of LLM Agents
This research paper presents a scalable evaluation framework to study how large groups of LLM-based autonomous agents behave in social dilemmas.
With this framework, LLMs generate strategies encoded as algorithms, enabling their inspection prior to deployment.
Experiments show that newer models often lead to worse social outcomes than older ones when agents focus on personal gain instead of group benefits.
By using cultural evolution simulations to model user selection of agents, researchers find a significant risk of poor social outcomes, especially as the relative benefit of cooperation decreases, and population size grows.
Read more about this research using this link.
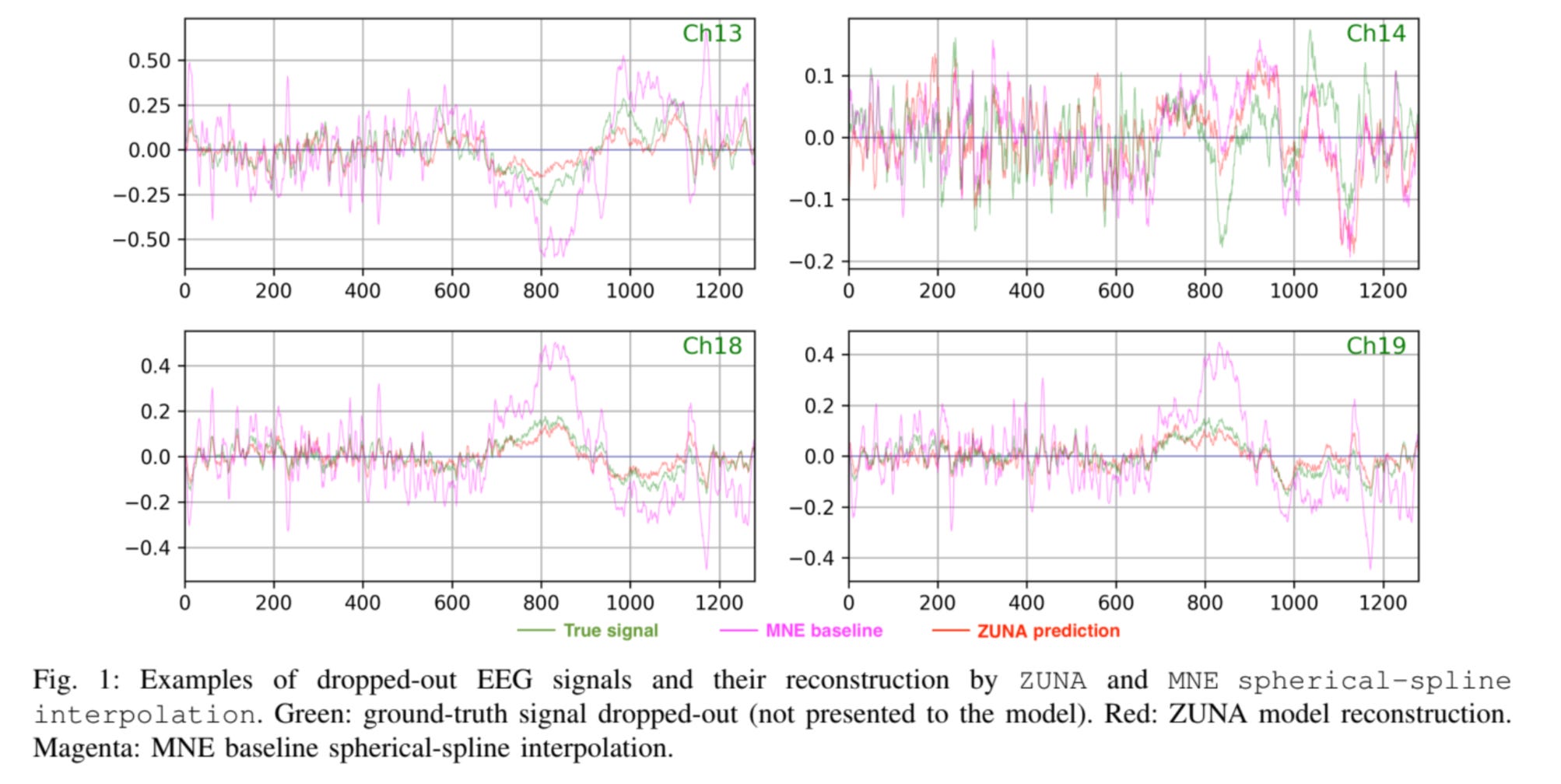
8. ZUNA
This research paper from Zyphra introduces ZUNA, an open-sourced foundation model with 380 million parameters for EEG (electroencephalogram) brain-computer interface (BCI) data.
The model is designed to denoise, reconstruct, and upsample EEG signals from different electrode layouts.
It is built as a diffusion autoencoder that can take a subset of EEG channels and reliably recover missing or corrupted ones. This improves spatial resolution and signal quality for research and practical uses.
ZUNA can work across various datasets and hardware, and serves as a foundation for non-invasive “thought-to-text” systems and for better understanding neural signals.
Read more about this research using this link.
9. KLong
This research paper introduces KLong, an open-source LLM agent trained to solve extremely long-horizon tasks. These are tasks that would exceed the context window without context management and involve long-running experiments such as those from MLE-bench and PaperBench.
Experiments show that KLong greatly enhances performance on long-horizon benchmarks compared to baselines.
Notably, KLong (106B) beats Kimi K2 Thinking (1T) by 11.28% on PaperBench. This performance improvement generalizes to other coding benchmarks, such as SWE-bench-Verified and MLE-bench.
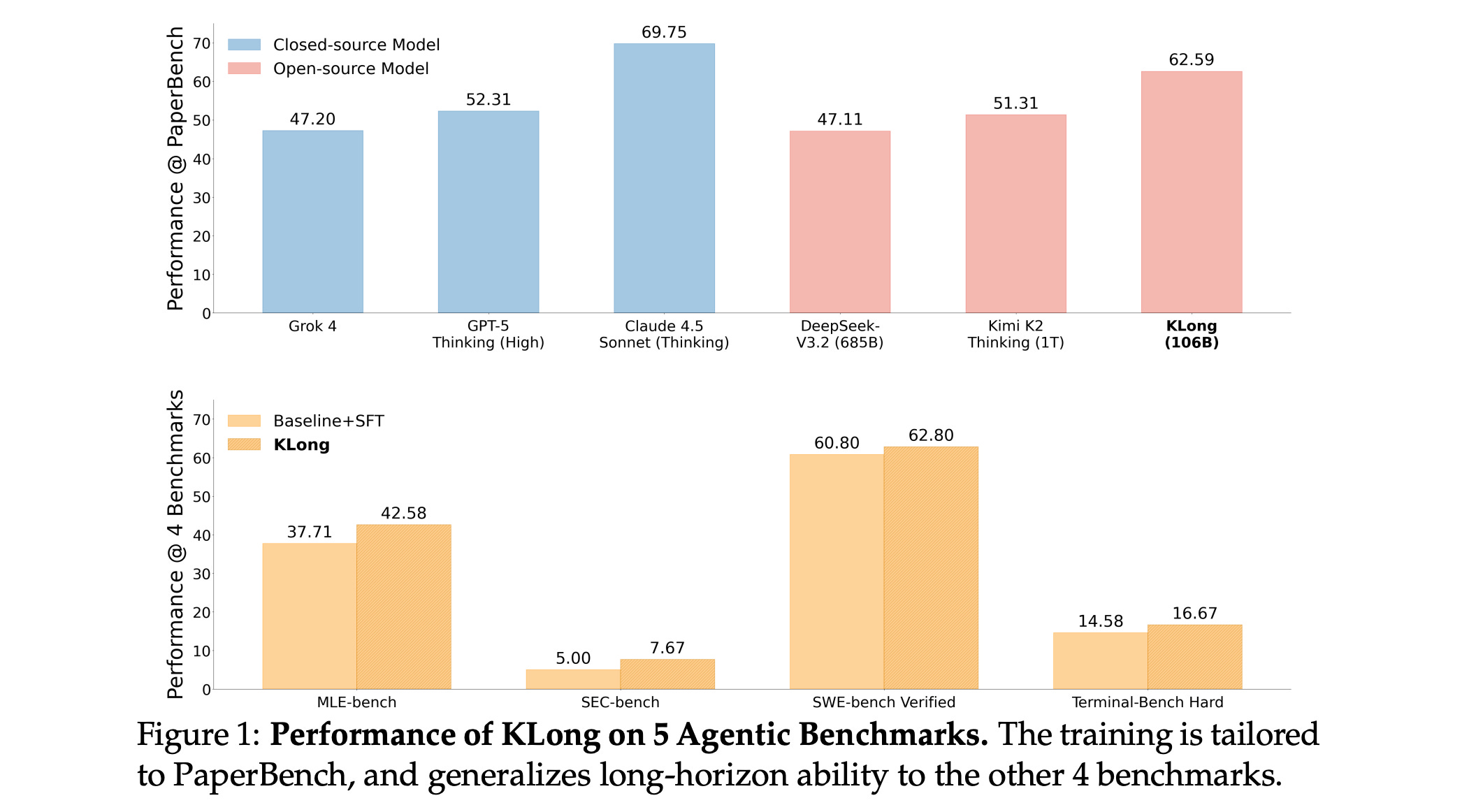
Read more about this research using this link.
10. Adam Improves Muon: Adaptive Moment Estimation with Orthogonalized Momentum
This research paper presents NAMO and NAMO-D, two new optimization algorithms that combine the benefits of orthogonal updates (as seen in Muon optimizer) with the noise adjustment of Adam-type methods.
NAMO preserves momentum orthogonality and introduces a single adaptive learning rate, which enhances Muon without any significant extra cost.
Its diagonal variant, NAMO-D, further improves performance by allowing neuron-wise noise adaptation through a clamped diagonal scaling.
The research paper includes theoretical convergence guarantees in both deterministic and stochastic environments, showing that both optimizers adapt well to gradient noise.
Empirical results from GPT-2 pretraining also show that NAMO, particularly NAMO-D, surpasses both AdamW and Muon baselines.
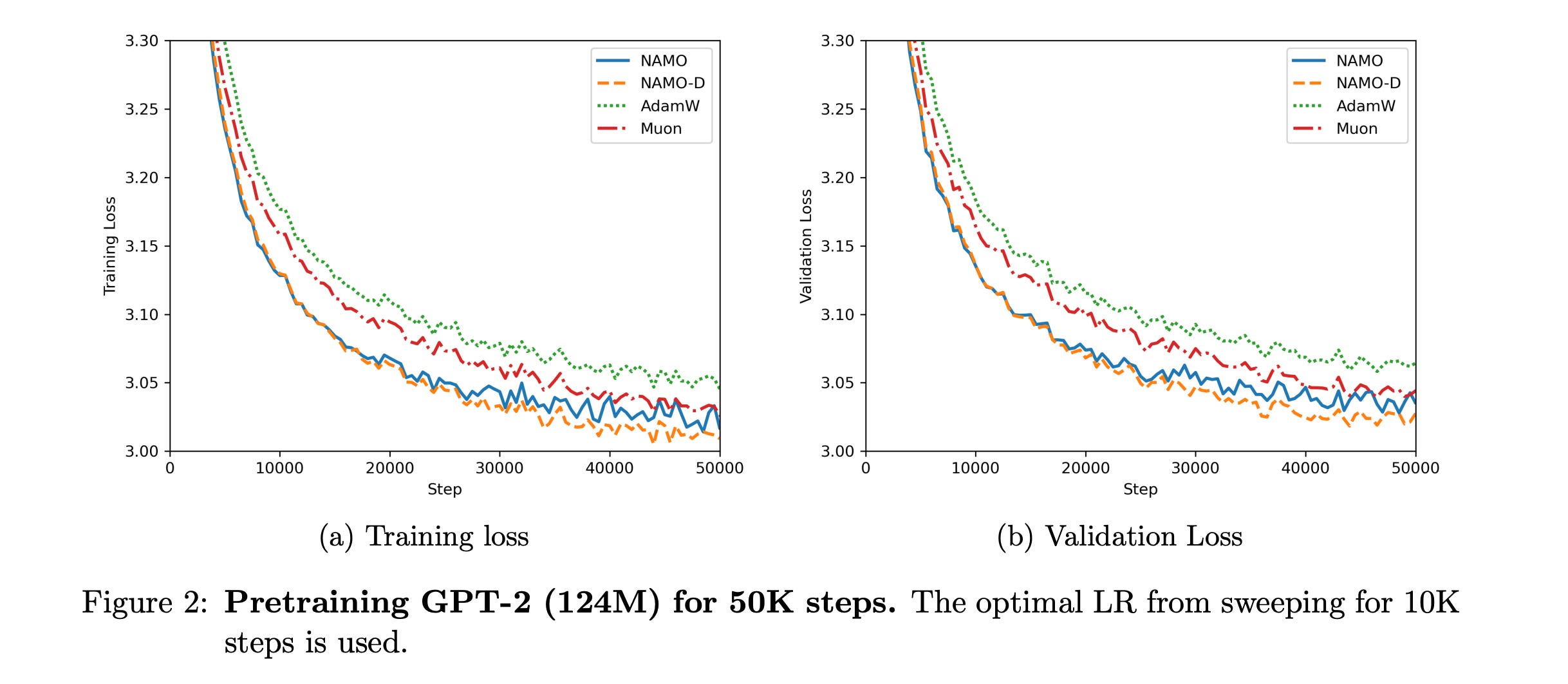
Read more about this research paper using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others to earn referral rewards. ❤️
Don’t forget to become a paid subscriber with a 35% discount on the annual subscription. Offer ends this month!
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.

It was a great read, thank you ❤️