

🗓️ This Week In AI Research (16-22 November 25)
The top 10 AI research papers that you must know about this week.


1. SAM 3D: 3Dfy Anything in Images
Meta’s SAM 3D is here to break the 3D “data barrier.”
It is a generative model for 3D object reconstruction from a single image, capable of predicting geometry, texture, and layout even under challenging real-world conditions with occlusion and clutter.
In human preference tests on real-world objects and scenes, SAM 3D achieves a win rate of at least 5:1 over recent comparable work.

SAM 3D uses a Mixture-of-Transformers geometry model to predict an object’s coarse 3D layout and shape (as voxels). It then applies a Flow Transformer refinement model to convert these voxels into detailed meshes and Gaussian splats.
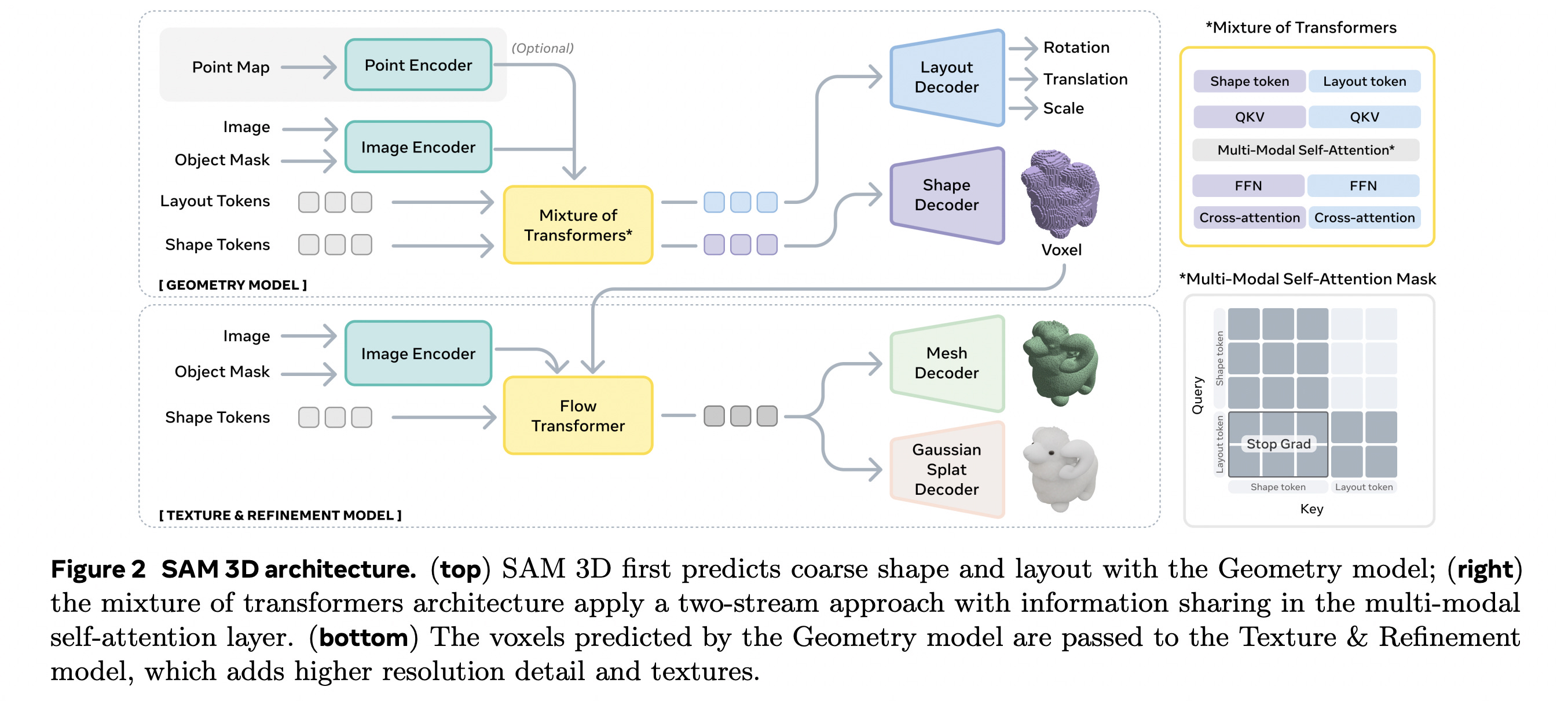
Read more about this research using this link.
Before we move forward, I want to introduce you to the Visual Tech Bundle.
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books. Why not give them a try?
2. ARC Is a Vision Problem!
This is an interesting and “eye-opening” paper from MIT researchers.
They note that most previous approaches treat problems in the ARC benchmark as language-oriented problems and solve them using LLMs or Recurrent reasoning models.
Moving away from this approach, the researchers represent the ARC problems’ inputs on a “canvas” so that they can be processed like natural images. They then apply a vision model to perform image-to-image mapping to solve them.
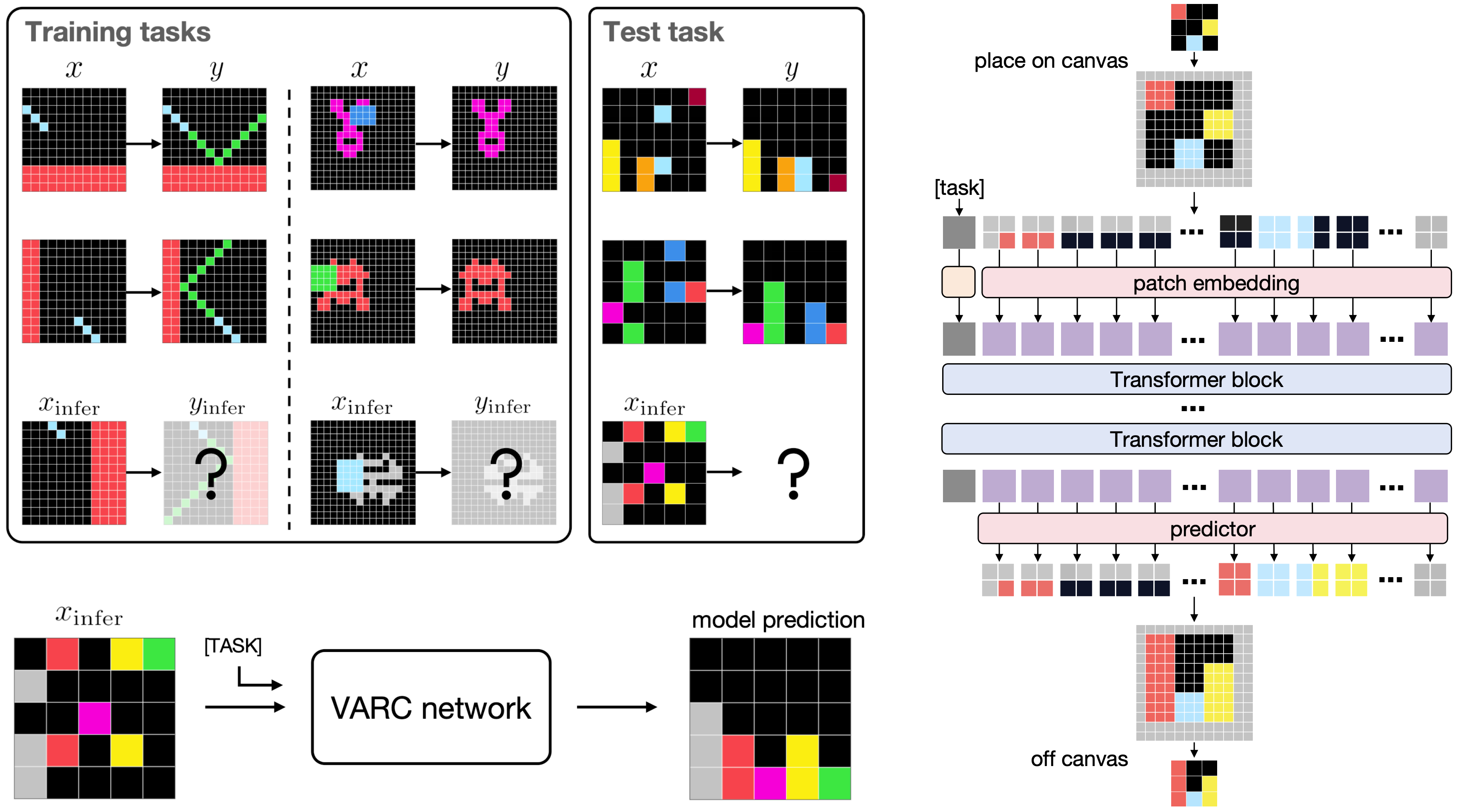
Their model, called Vision ARC (VARC), is trained from scratch solely on ARC data and generalizes to unseen tasks through test-time training.
It achieves 60.4% accuracy on the ARC-AGI 1 benchmark, outperforming existing methods and achieving results competitive with those of leading LLMs.
Read more about this research using this link.
3. Olmo 3
This research paper introduces the Olmo 3 family of SOTA fully open-source LLMs at the 7B and 32B parameter scales, with Olmo 3 Think-32B being the strongest fully open thinking model released to date.
These models are designed for reasoning, function-calling, coding, instruction-following, long-context use, and general knowledge recall.
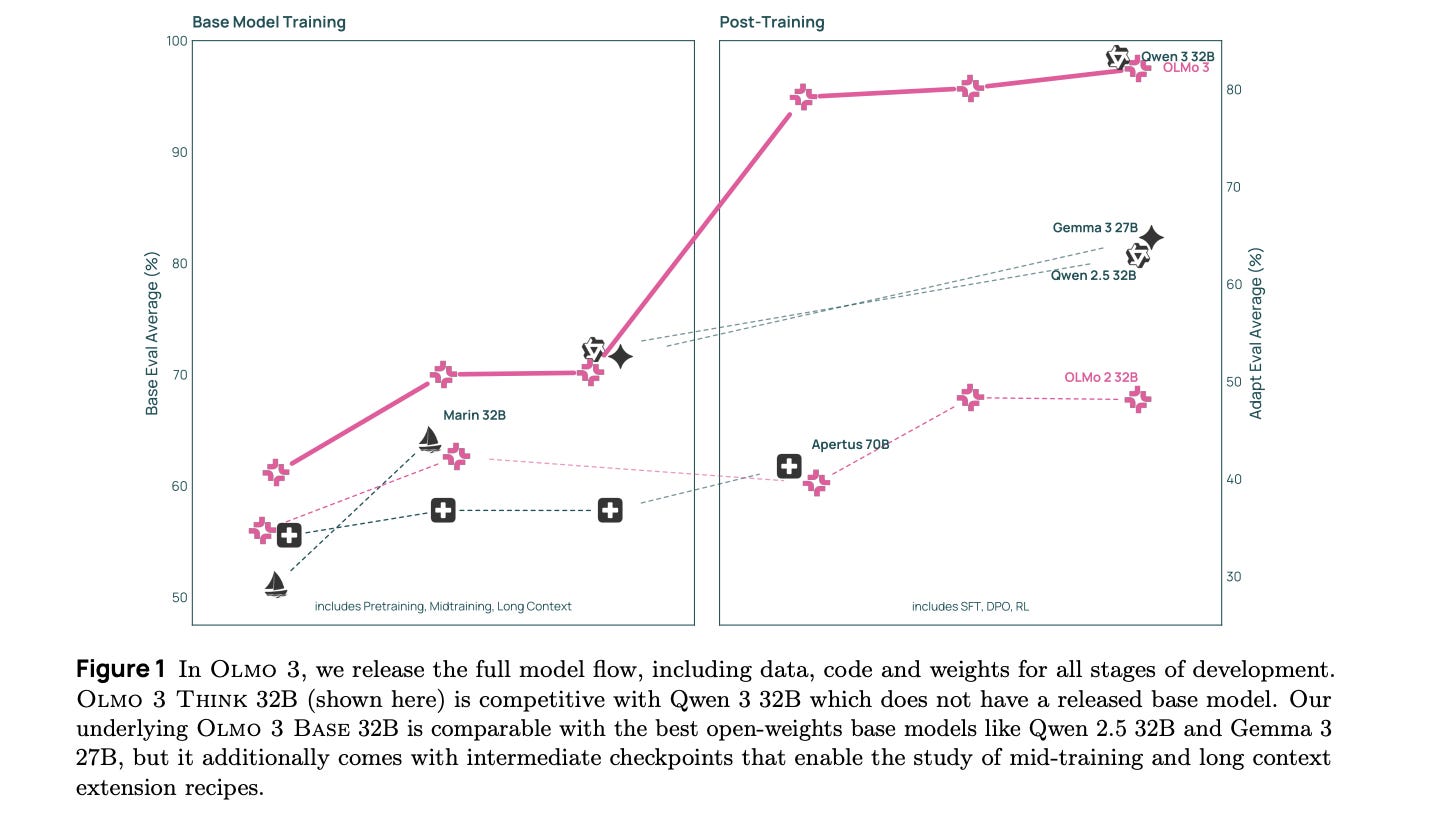
The term “fully” must be emphasized because the team released the complete model flow, covering the entire lifecycle of the family of models, including every stage, checkpoint, datapoint, and dependency used to build it.
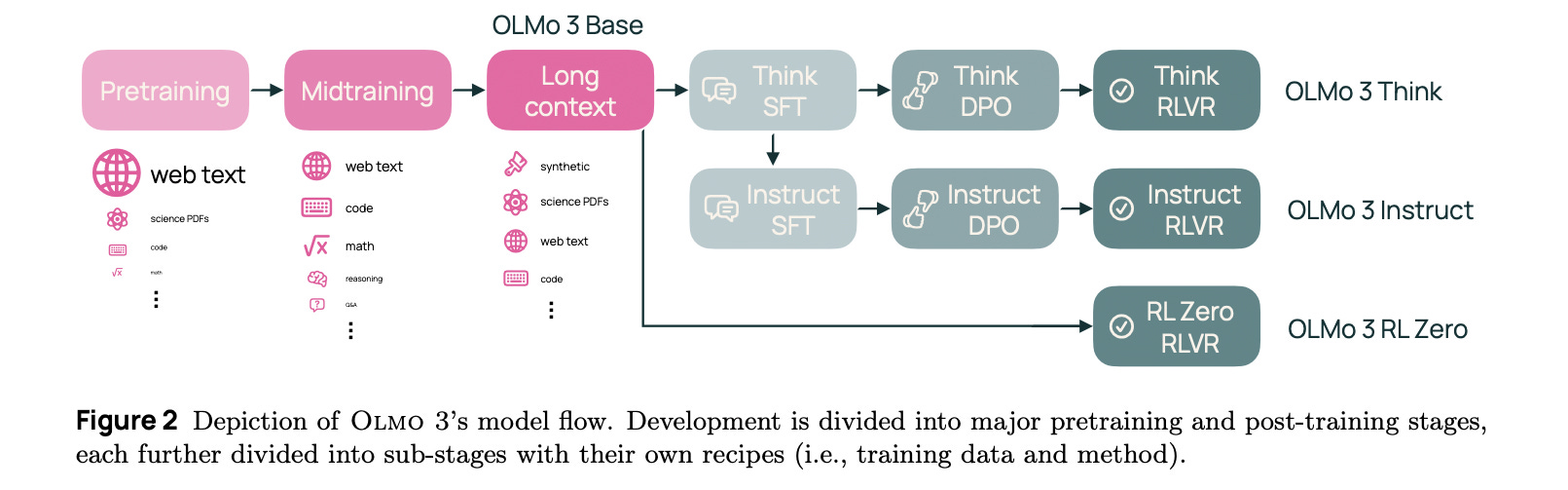
Read more about this research using this link.
4. P1: Mastering Physics Olympiads with Reinforcement Learning
This research from the Shanghai AI Laboratory presents the P1 family of open-source physics reasoning models trained using an RL algorithm built on Alibaba’s GSPO (Group Sequence Policy Optimization).
Among them, P1-235B-A22B is the first open-source model to achieve Gold-medal performance at the latest International Physics Olympiad (IPhO 2025).
Further improved with an agentic framework called PhysicsMinions, P1-235B-A22B achieves No. 1 overall at IPhO 2025.
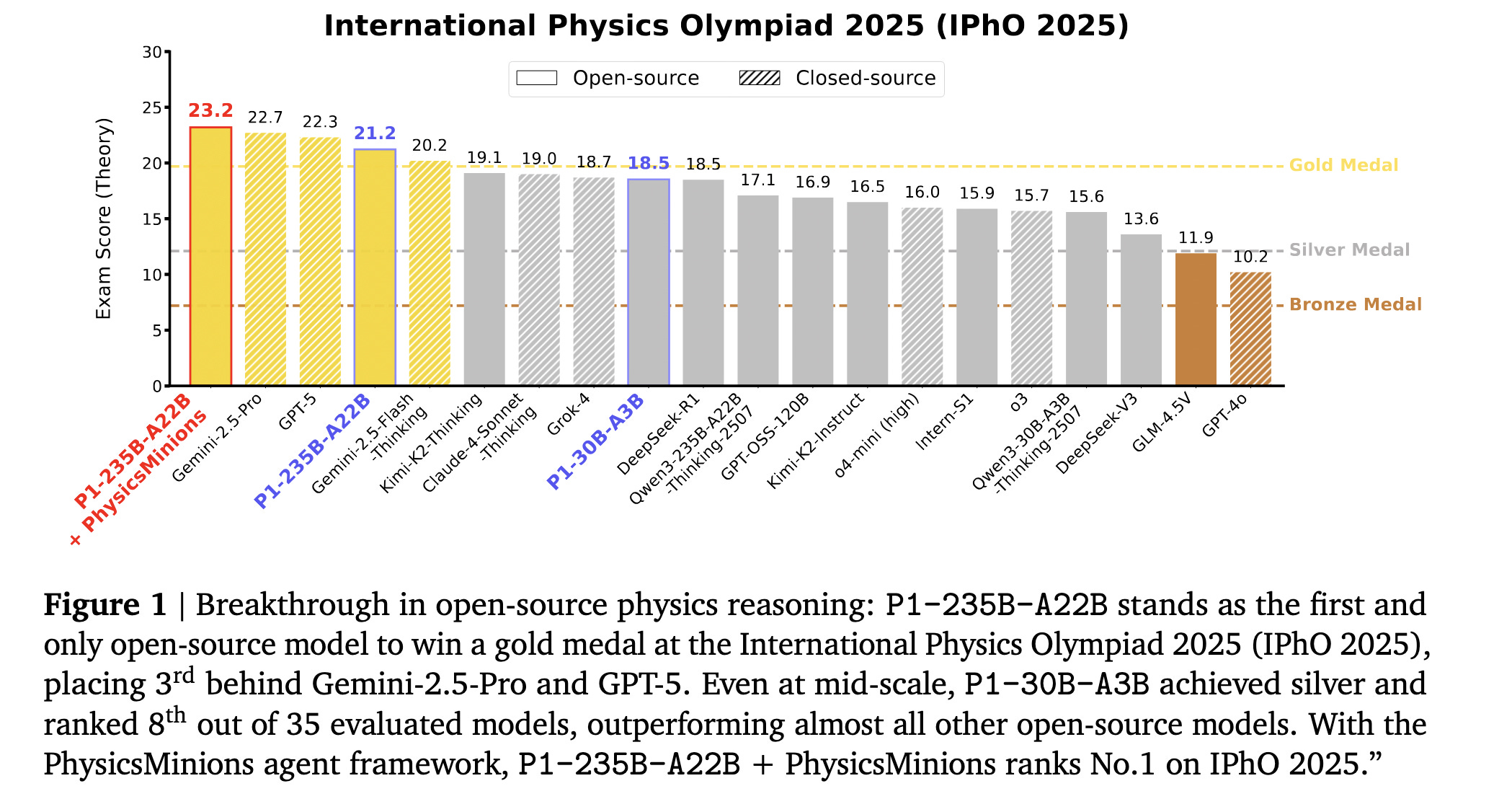
Read more about this research using this link.
5. Evolution Strategies at the Hyperscale
This research paper introduces a new Evolution Strategies (ES) algorithm called Evolution Guided General Optimization via Low-rank Learning (EGGROLL).
ES methods are powerful for optimizing non-differentiable objectives at scale through parallelization, but they become impractically costly for large models.
EGGROLL fixes this limitation by replacing expensive full-size random perturbations with low-rank perturbations.
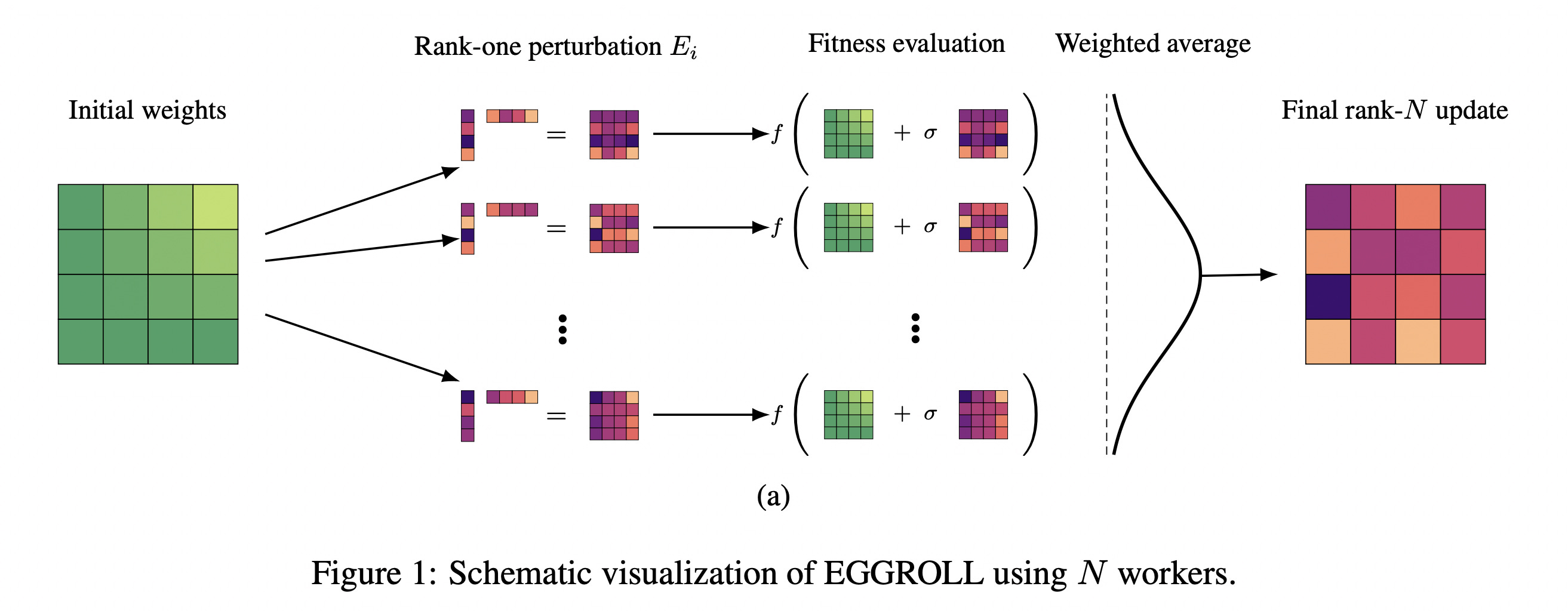
As a result, it can train or optimize billion-parameter models without the massive computational or memory costs typically required.
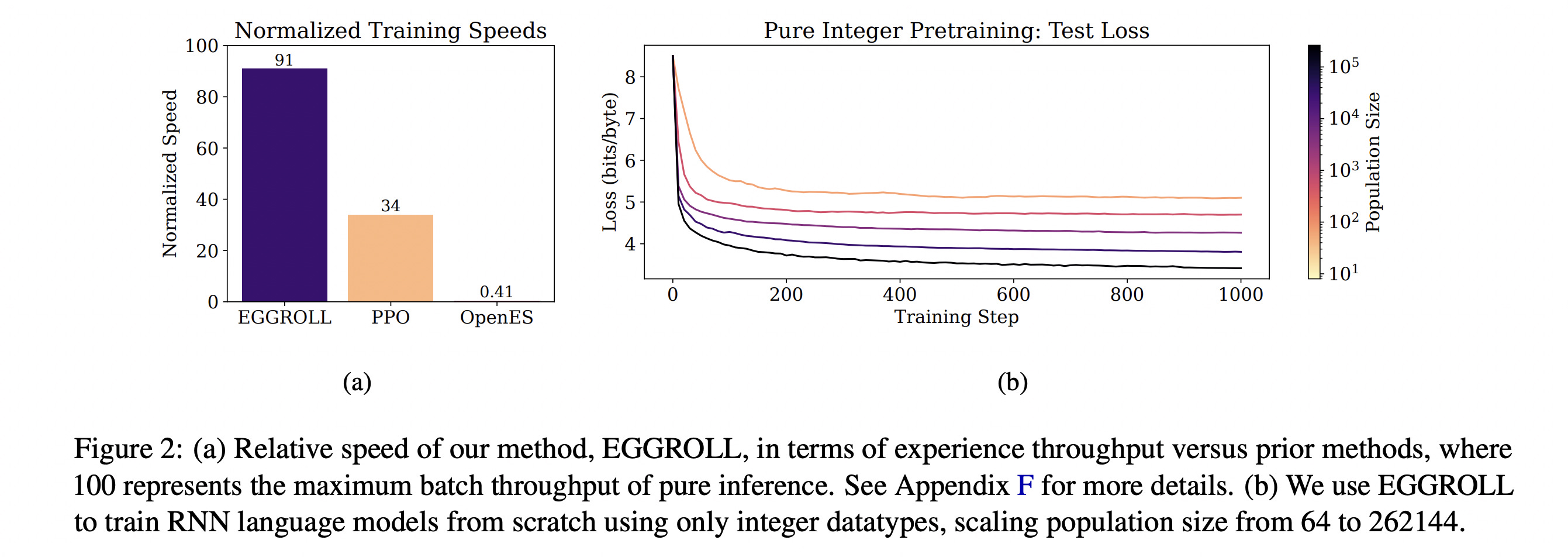
Read more about this research using this link.
6. π*₀.₆: a VLA That Learns From Experience
This paper introduces RECAP (Reinforcement Learning with Experience and Corrections via Advantage-conditioned Policies), a framework for training Vision-Language-Action (VLA) models.
It begins by pretraining a generalist VLA using offline RL, producing a policy called π*₀.₆.
This policy is then further specialized through on-robot data collection for specific downstream tasks.
π*₀.₆ trained using RECAP can learn complex real-world skills such as folding laundry in homes, reliably assembling boxes, and making espresso with a professional machine.
Impressively, RECAP more than doubles task throughput and roughly halves failure rates on some of the hardest of these tasks.
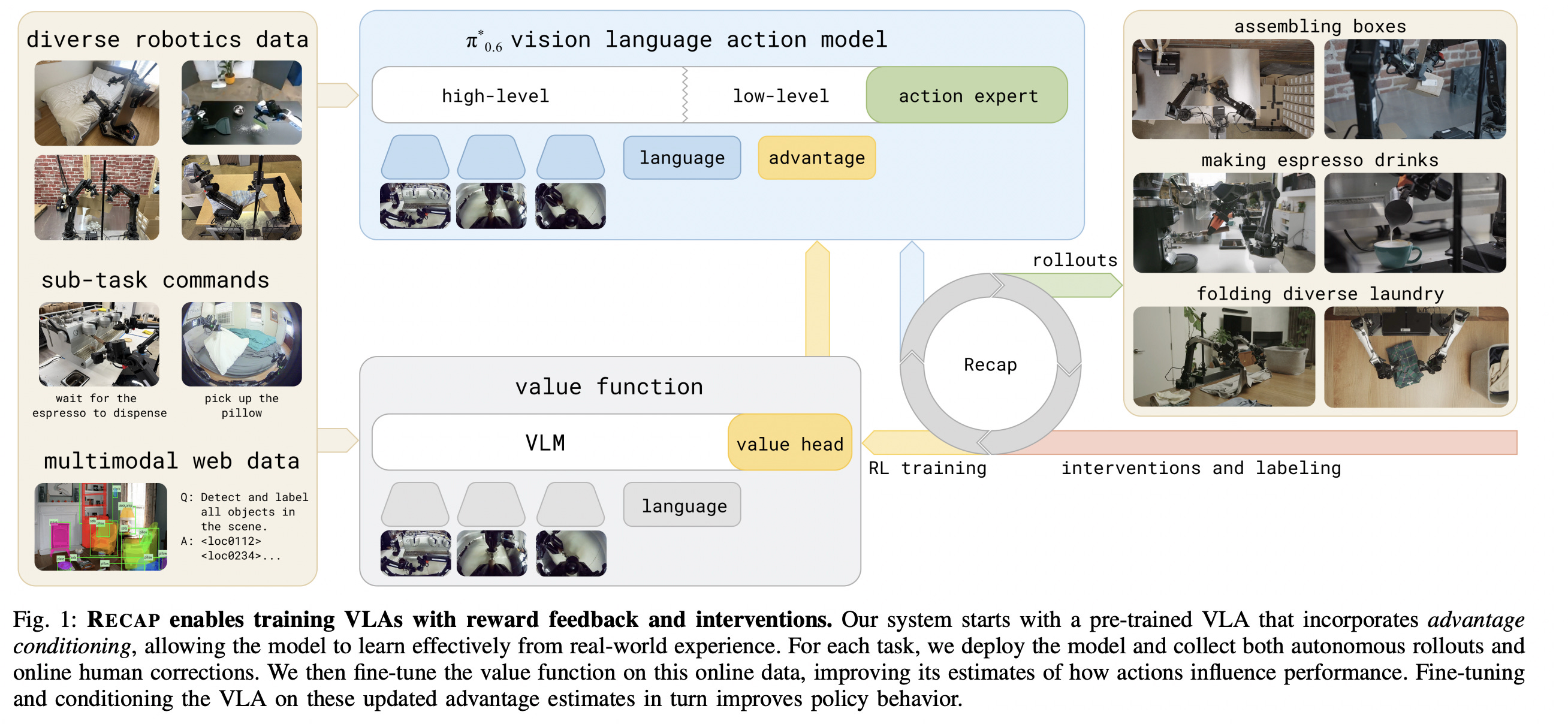
Read more about this research using this link.
7. Upsample Anything
Vision Foundation Models generalize well across many tasks, but their features are typically downsampled by 14× to 16× (as in ViT), making them difficult to use directly for pixel-level applications.
This paper works on this limitation and introduces Upsample Anything, a lightweight test-time optimization (TTO) framework.
This framework transforms low-resolution feature maps from vision foundation models into high-resolution pixel-level outputs without any additional training.
It is fast (processing a 224×224 image in about 0.42 seconds) and achieves state-of-the-art results on tasks such as semantic segmentation, depth estimation, and probability-map upsampling.

Read more about this research using this link.
8. Nemotron Elastic
This research paper by NVIDIA introduces Nemotron Elastic, a framework for creating reasoning-oriented LLMs that contain multiple nested sub-models of different sizes within a single parent model.
Each sub-model uses the same weights as the parent model, is optimized for different deployment configurations and budgets, and can be pulled out for deployment without any additional training.
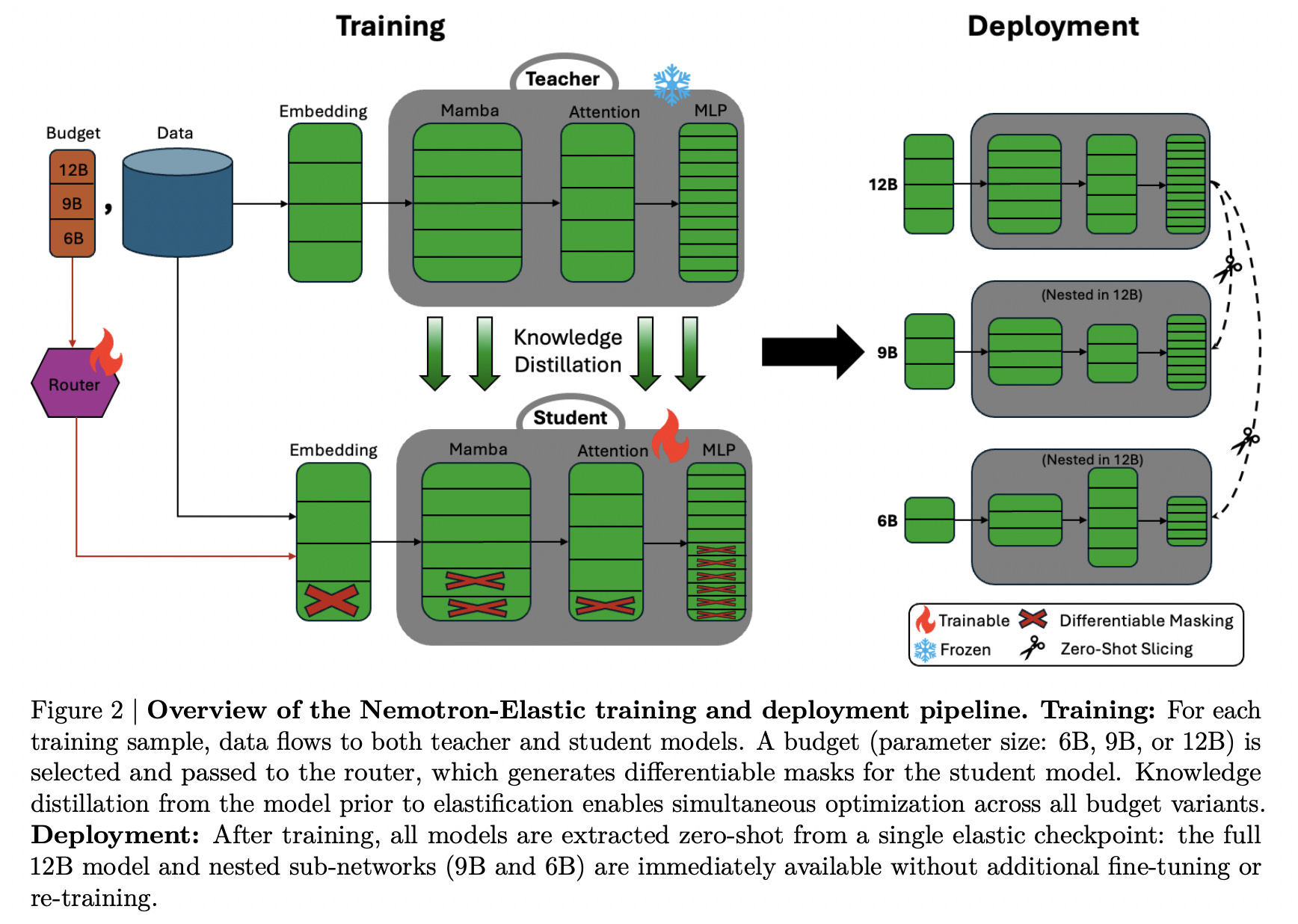
The framework uses only 110B training tokens to produce 9B and 6B model variations when applied to a 12B Nemotron Nano V2 model, which is 360× cheaper than training each model independently.
Nemotron Elastic maintains constant compute and memory costs as model size scales and achieves strong average accuracy on major reasoning benchmarks, unlike baselines that grow linearly.
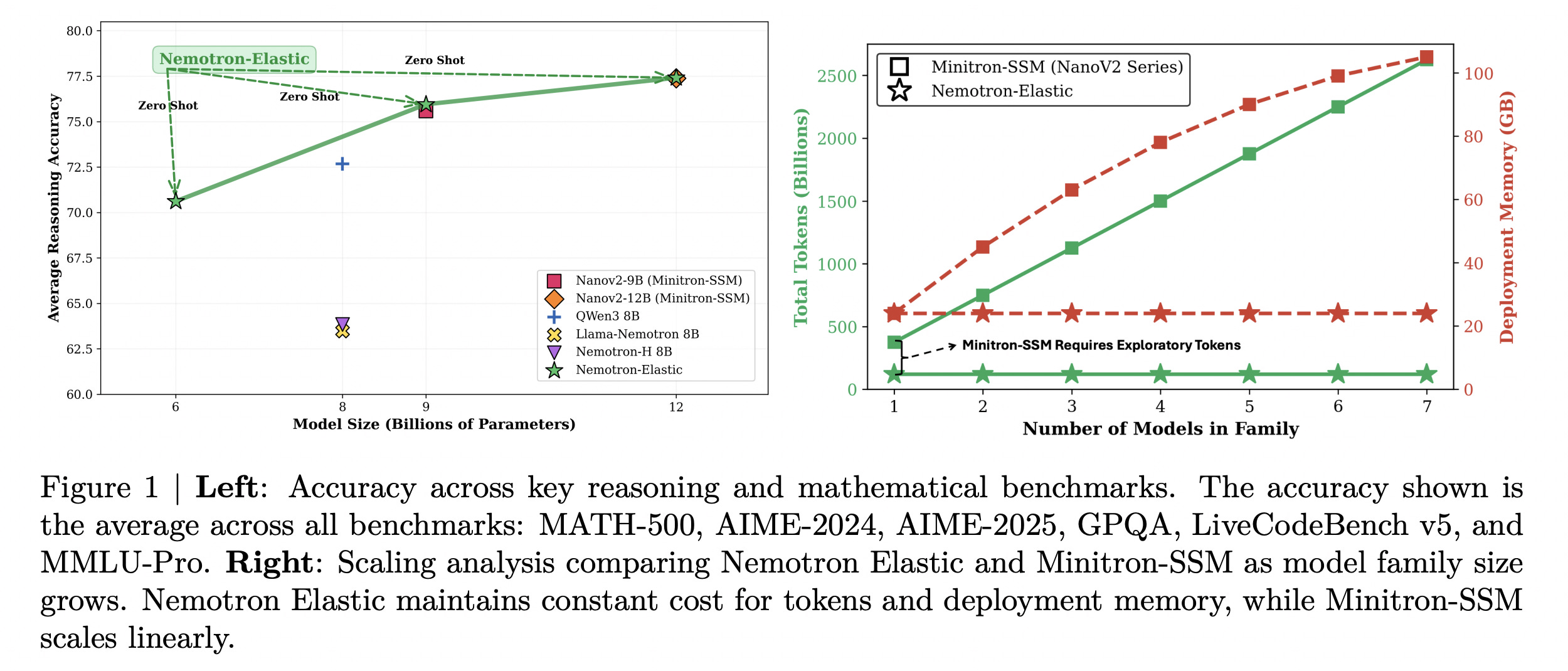
Read more about this research using this link.
9. Early science acceleration experiments with GPT-5
This research paper from OpenAI, in partnership with several other prominent universities, describes multiple case studies in which GPT-5 contributed to advancing ongoing research across mathematics, physics, astronomy, computer science, biology, and materials science.

The most remarkable of them all is that GPT-5 generated four completely new results in mathematics, which have been carefully verified by human authors.

Read more about this research using this link.
10. Step by Step Network
Researchers from Tsinghua University and Huawei Noah’s Ark Lab introduce the Step by Step network (StepsNet) in this research paper.
While increasing depth can improve performance, networks with hundreds of layers often become unstable and inefficient to train.
StepsNet addresses these limitations of very deep networks by dividing the learning process into successive steps or modules, each of which gradually improves and builds upon the one before it.
This enables more effective depth scaling, better convergence, and improved representation learning, while systematically using residual connections.
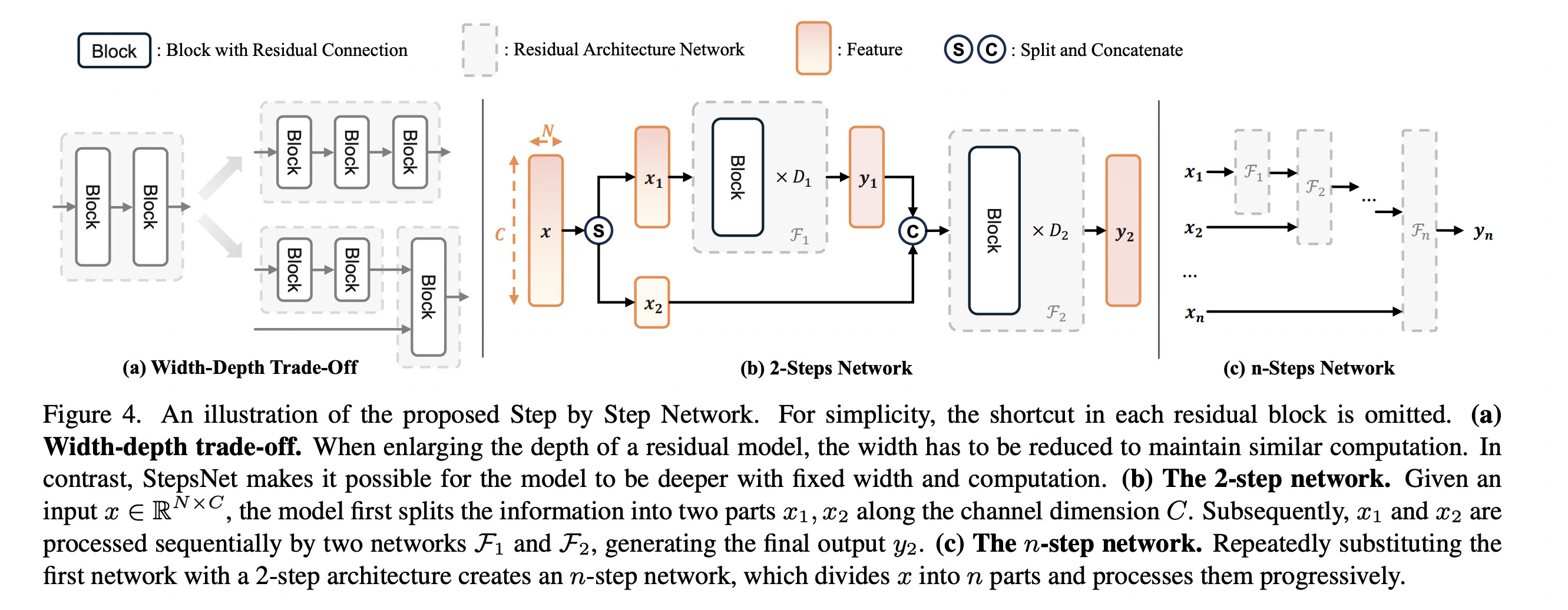
Results show that StepsNet has better training dynamics and shows less overfitting, making it outperform or match conventional very-deep residual networks across various tasks, including image classification, object detection, semantic segmentation, and language modeling.
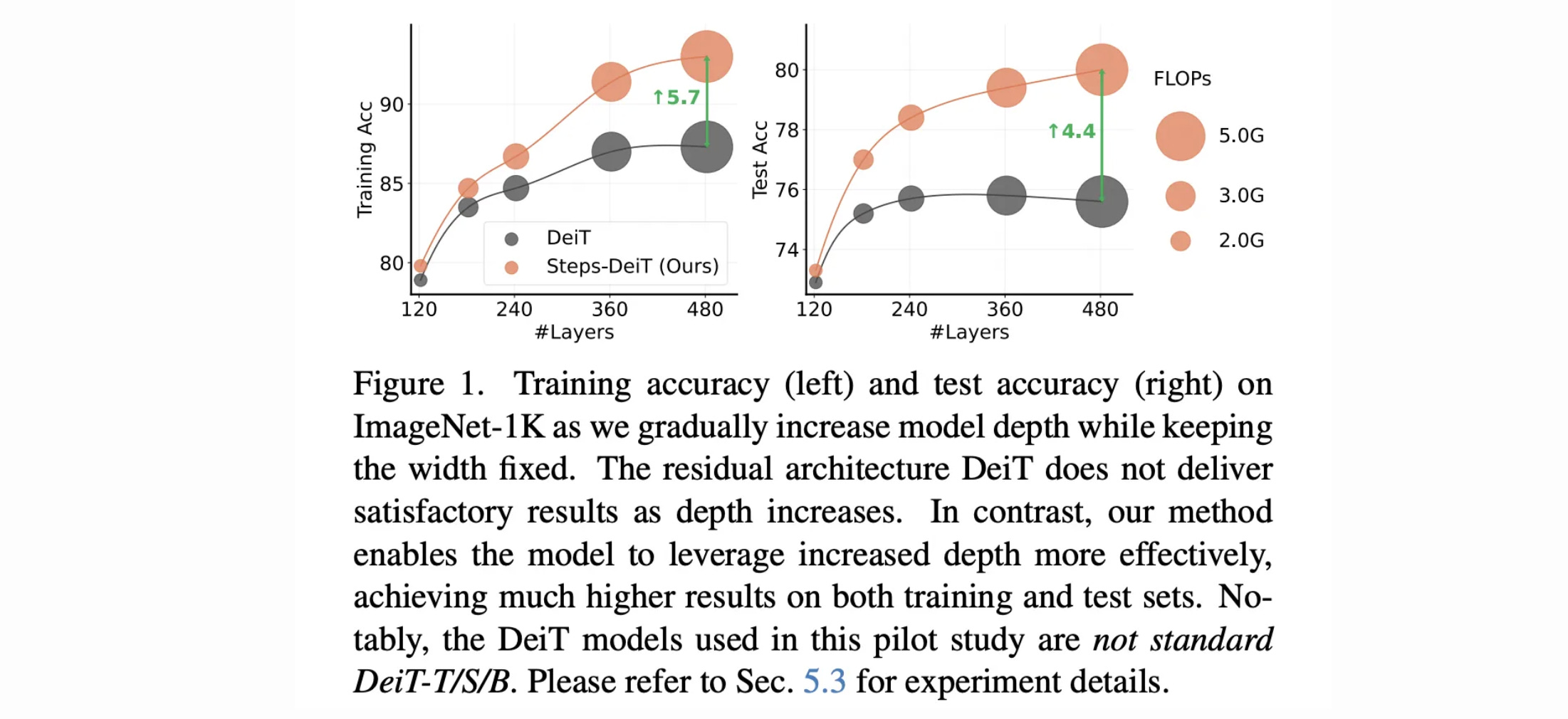
Read more about this research using this link.
This article is free to read. If you loved reading this article, restack it and share it with others.
If you want to get even more value from this publication, become a paid subscriber and unlock all posts.
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.

Wow, the part about SAM 3D realy stood out to me, that 5:1 win rate is just wild and shows such a leap forward! What if this technology meant we could build entire educational simulations or virtual museum tours from simple 2D photos, making immersive learning truly accessible without needing huge datasets?