

🗓️ This Week In AI Research (25-31 January 26)
The top 10 AI research papers that you must know about this week.


Before we begin, I have an exciting offer for you that is only valid for the next 24 hours!
Grab a flat 50% discount on the annual membership of Into AI today.
👉 Upgrade here, lock in the discount, and use ‘Into AI’ as your unfair advantage:
1. Advancing Open-source World Models
This research paper by AntGroup introduces LingBot-World, an open-sourced world simulator coming from video generation.
LingBot-World is a top-tier world model with the following features:
It delivers high-quality visuals and stable dynamics in various environments, including realistic scenes, scientific settings, cartoon-based worlds, and more.
It keeps track of what’s happening over several minutes in a way that remains logically consistent, effectively serving as long-term memory for recent events.
It supports real-time interactivity, achieving latency under 1 second at 16 frames per second.
Read more about this research paper using this link.
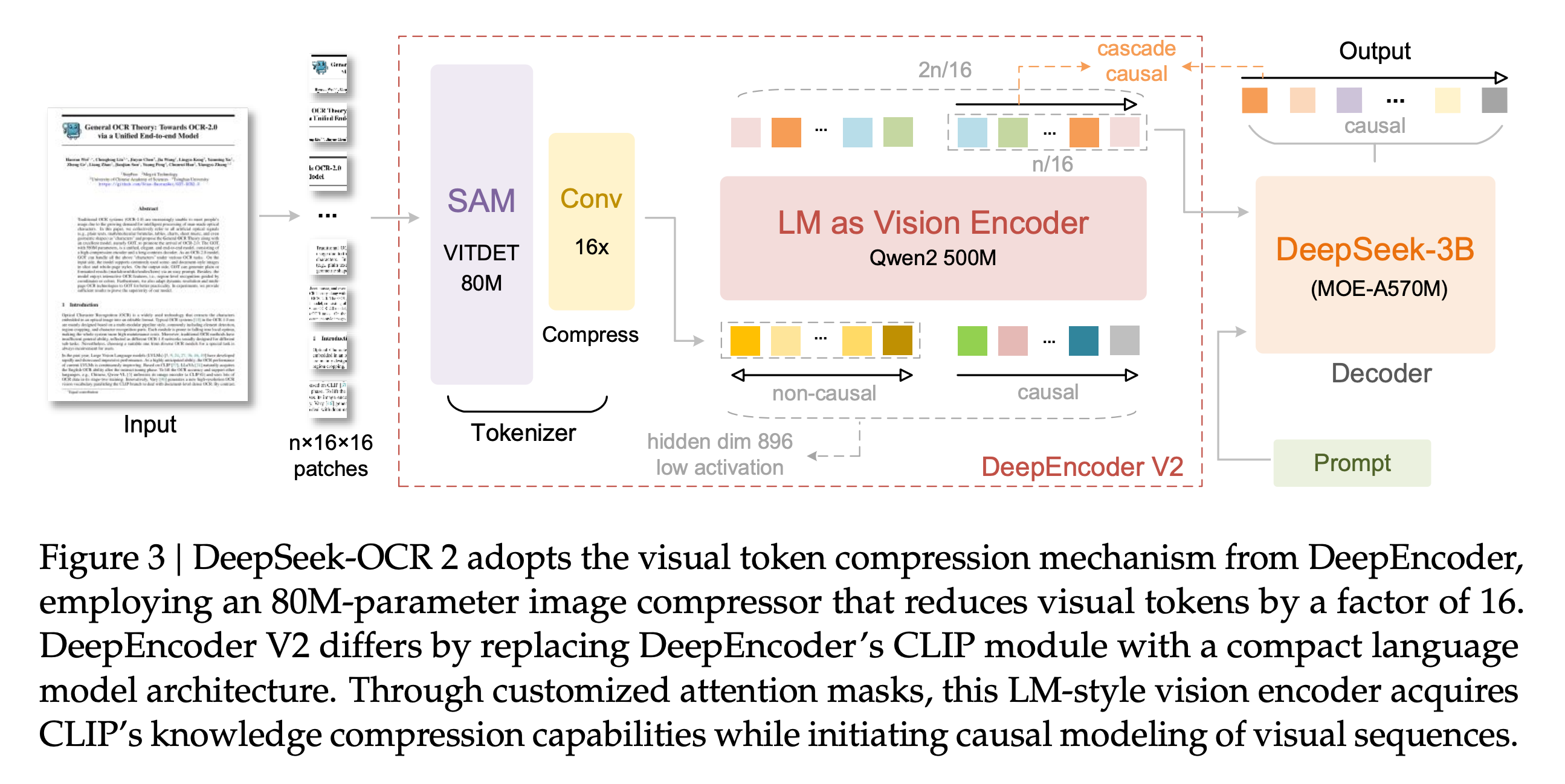
2. DeepSeek-OCR 2: Visual Causal Flow
This research paper introduces DeepSeek-OCR 2, an OCR system based on a novel encoder, DeepEncoder V2, that dynamically reorders visual tokens by their meaning rather than using a fixed raster-scan order (top-left to bottom-right).
Its design is inspired by how humans perceive visuals. Humans process complex layouts through causally informed sequential reasoning rather than strict spatial scanning, and the architecture investigates whether understanding 2D images can be done through two cascaded 1D causal reasoning structures.
In practice, DeepSeek-OCR 2 achieves top document understanding performance, achieving around 91.1% overall on OmniDocBench v1.5, improving accuracy and reading-order metrics while requiring fewer visual tokens than earlier models.
Additionally, it significantly reduces practical errors, such as token repetition, in production settings.
Read more about this research paper using this link.
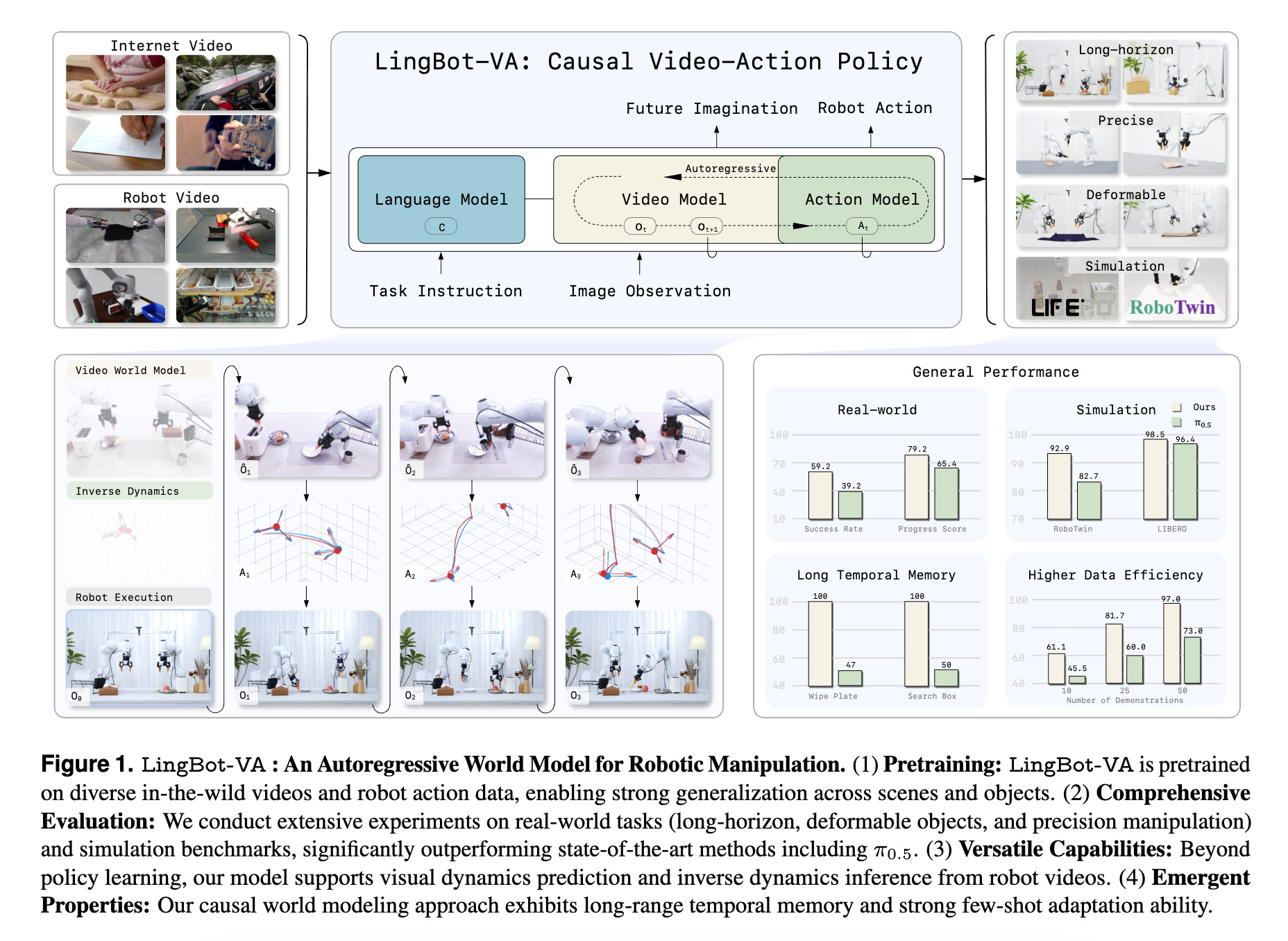
3. Causal World Modeling for Robot Control
This research paper by Ant Group proposes a new approach to robot control based on causal world models, in which the robot learns how its actions cause changes in the world rather than treating perception and control as separate problems.
Their AI model, called LingBot-VA, is based on an autoregressive diffusion framework that uses a shared latent space combining vision and action tokens, driven by a Mixture-of-Transformers (MoT) architecture. Using this, it learns to predict future visual scenes and select actions simultaneously using a single unified model.
LingBot-VA operates in a closed feedback loop, allowing it to adjust actions continuously as new observations arrive, and uses an asynchronous inference pipeline that parallelizes action prediction and motor execution to support efficient control.
Experiments on both simulated and real-world tasks demonstrate that this approach results in more reliable long-term behavior, better adaptation to new situations, and strong performance with less training data.
Read more about this research paper using this link.
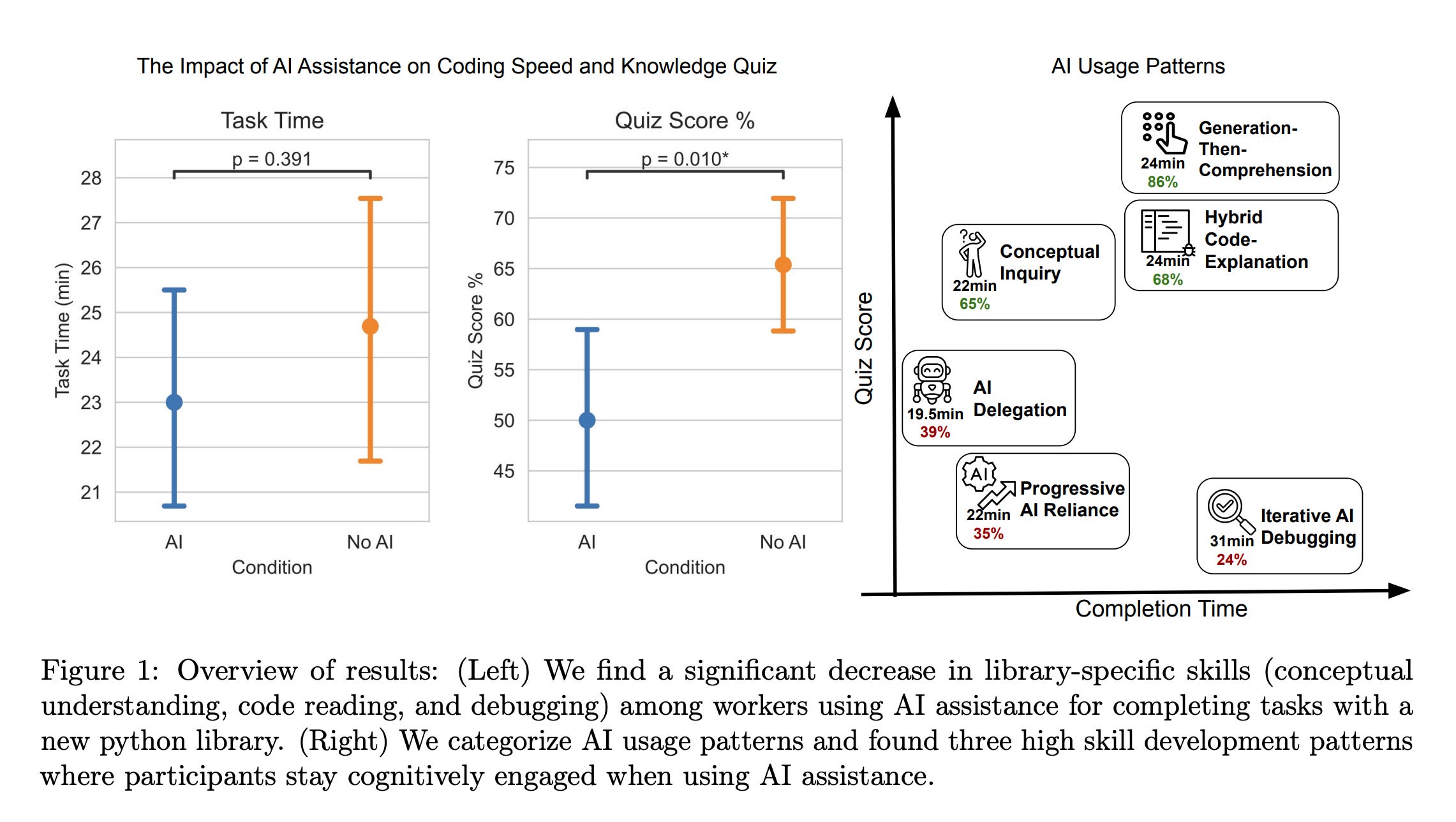
4. How AI Impacts Skill Formation
This research from Anthropic shows that while AI coding assistants can help users complete tasks efficiently, they hinder skill acquisition when people rely on them too much.
In an experiment in which developers studied a new Python asynchronous programming library, those who used AI scored lower on conceptual understanding, code reading, and debugging, with no significant average gains in efficiency.
However, some developers who engaged with AI more thoughtfully, asking for explanations rather than direct answers, avoided much of this downside.
Overall, the study suggests that AI-enhanced productivity is not a shortcut to competence. AI assistance should be carefully integrated into workflows to preserve skill formation, especially in safety-critical areas.
Read more about this research paper using this link.
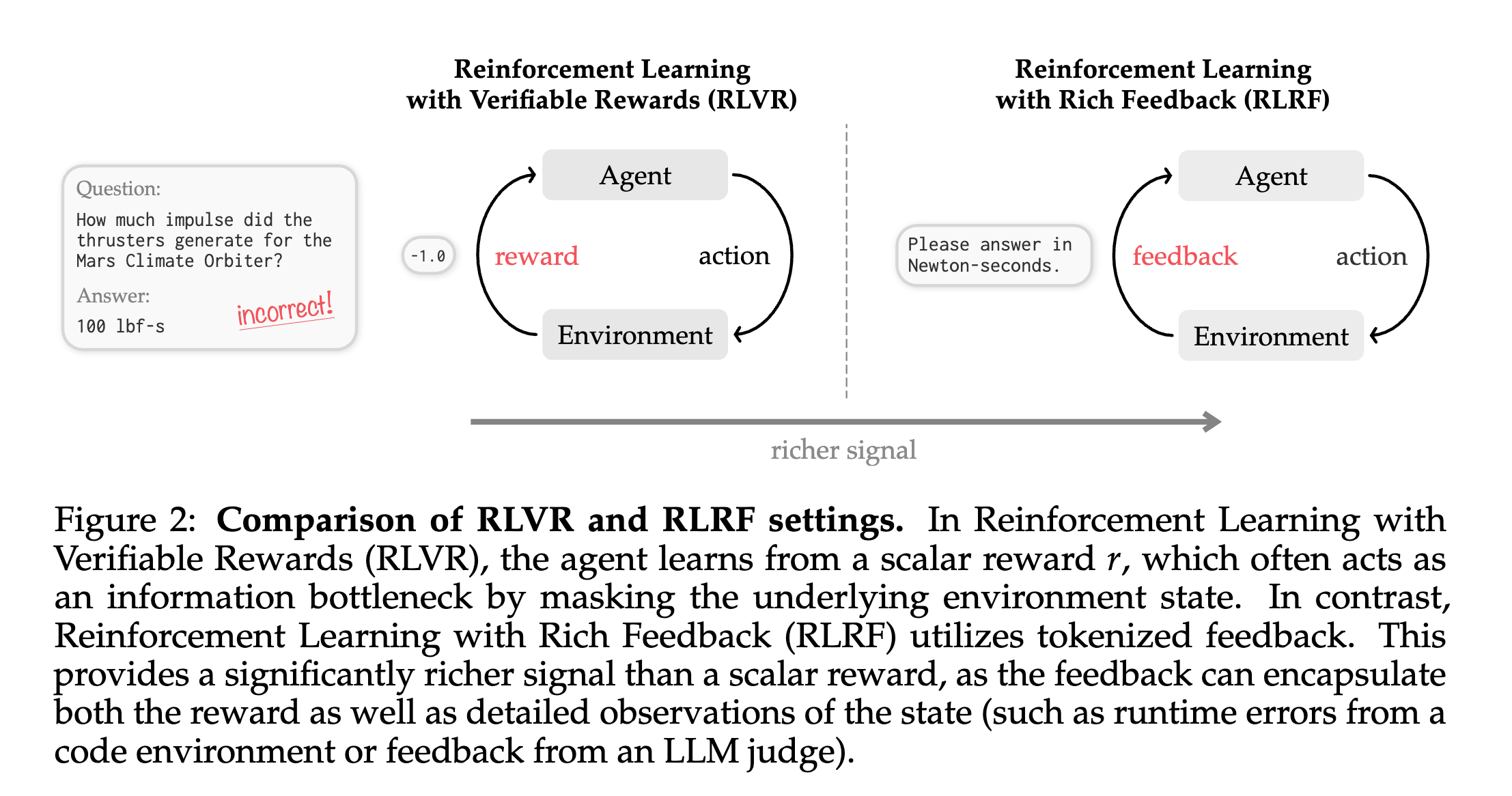
5. Reinforcement Learning via Self-Distillation
Current methods for Reinforcement learning with verifiable rewards (RLVR) learn only from a single success/failure signal, making it hard to find out why an attempt failed.
To address this, this research introduces Reinforcement Learning with Rich Feedback (RLRF) and a new algorithm called Self-Distillation Policy Optimization (SDPO).
SDPO uses detailed feedback (such as error messages or judge evaluations) to teach the model about why an attempt failed and what went wrong, without using any external teacher or explicit reward model.
It turns the model into its own teacher by distilling its feedback-informed next-token predictions back into the policy.
Across scientific reasoning, tool use, and competitive programming tasks, SDPO learns faster and performs better than strong RL baselines.
It even works well when only simple success/failure rewards are available, by using successful attempts to guide failed ones.
At test time, SDPO helps models in solving hard problems with about 3X fewer attempts, achieving the same success rate as more costly sampling or multi-turn methods.
Read more about this research paper using this link.
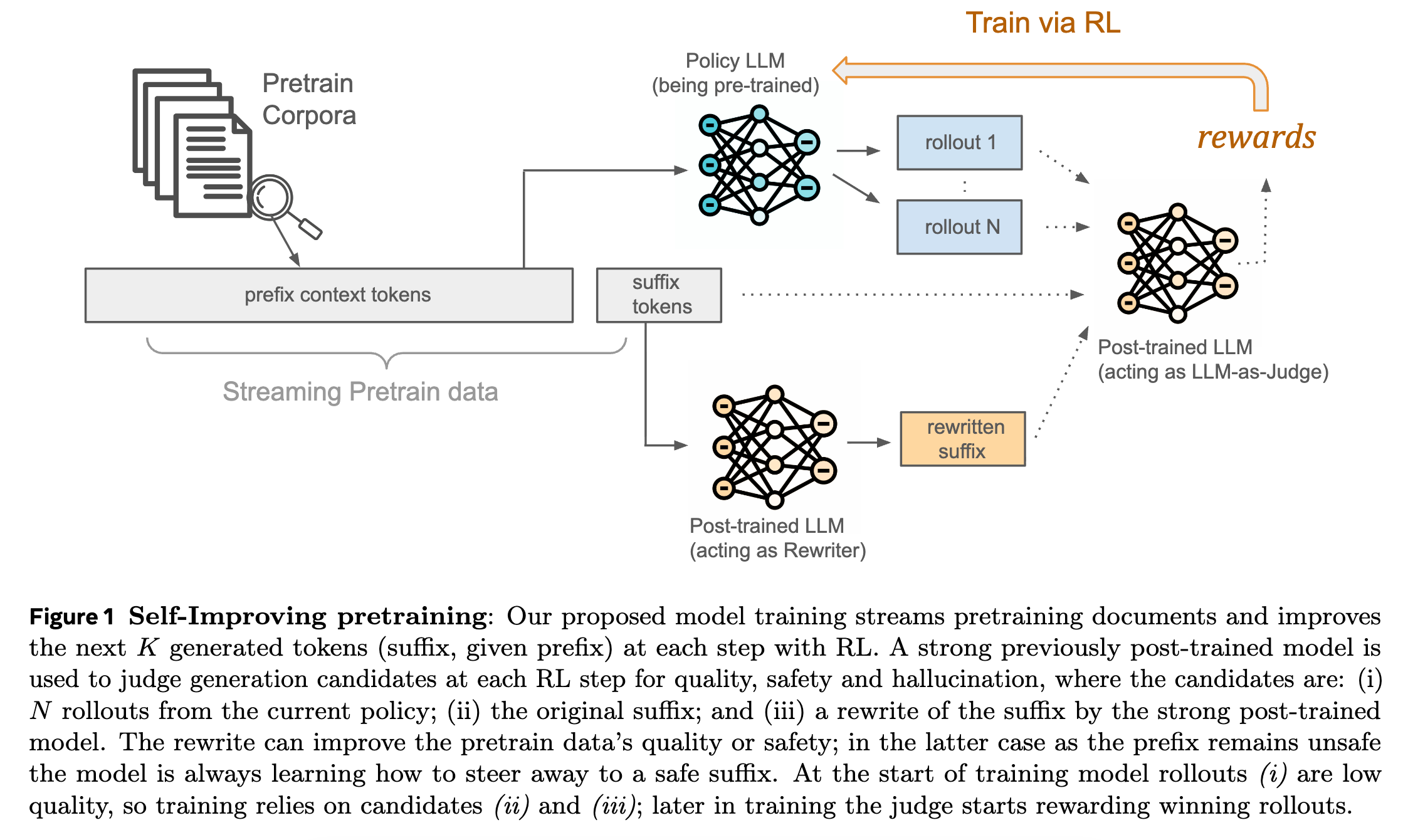
6. Self-Improving Pretraining
This research paper from Meta introduces a new approach to pretrain LLMs to be better, safer, and more factual from the beginning, rather than fixing these problems after pre-training.
Instead of using the usual next-token prediction objective, they train models using RL, in which a strong model that has already been post-trained assesses candidate continuations based on quality, safety, and factual accuracy.
At each step, the model looks at several options, including model rollouts, the original suffix, and a rewritten suffix, and learns to favor the best choices.
This leads to significant improvements, with up to 36.2% higher factuality, 18.5% higher safety, and much higher overall generation quality compared to standard pretraining.
Read more about this research paper using this link.
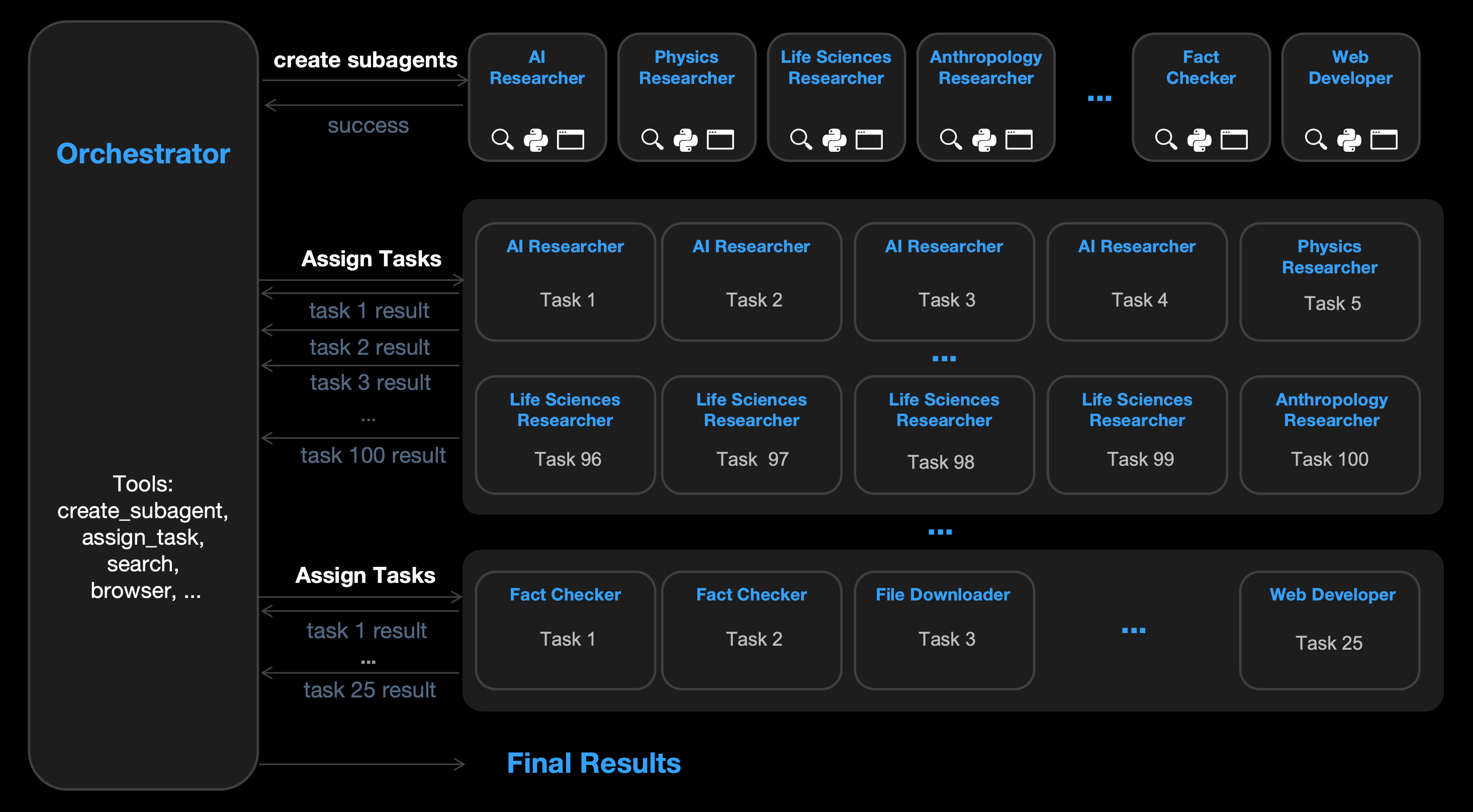
7. Kimi K2.5: Visual Agentic Intelligence
This technical report by Moonshot AI introduces Kimi K2.5, the most powerful multi-modal open-source model to date.
It is pretrained on large amounts of mixed visual and text data and delivers state-of-the-art coding and vision capabilities in both images and videos.

K2.5 comes with advanced agentic capabilities and can self-direct “agent swarms” of up to 100 sub-agents. These sub-agents work in parallel on complex, multi-step tasks without needing manual coordination. This significantly speeds up execution compared to single-agent setups.
The model has strong coding with vision capabilities, enabling users to create production-ready interfaces and code from text and visual inputs.
Here’s an example of K2.5 reconstructing a website from a video.
K2.5 also supports advanced productivity tasks, such as generating documents, spreadsheets, PDFs, and slide decks directly from instructions.
Read more about this report using this link.
8. Meta Context Engineering via Agentic Skill Evolution
This research paper proposes a new approach to Context engineering that makes the engineering process itself learnable and adaptive, rather than relying on fixed, manually designed rules.
Their technique, called Meta Context Engineering (MCE), uses a two-level agentic system in which a meta-agent develops context engineering skills over time, while a base-agent uses those skills to improve context representations for various tasks.
Instead of relying on rigid workflows or simple prompt templates, MCE learns to reorganize and adapt context dynamically across different fields.
When evaluated in different fields (finance, chemistry, medicine, law, and AI safety), MCE shows consistent performance gains that range from around 5.6% to 53.8% compared to the SOTA agentic methods.
Alongside this, it shows strong adaptability, transferability, and efficiency in both offline and online settings.

Read more about this research paper using this link.
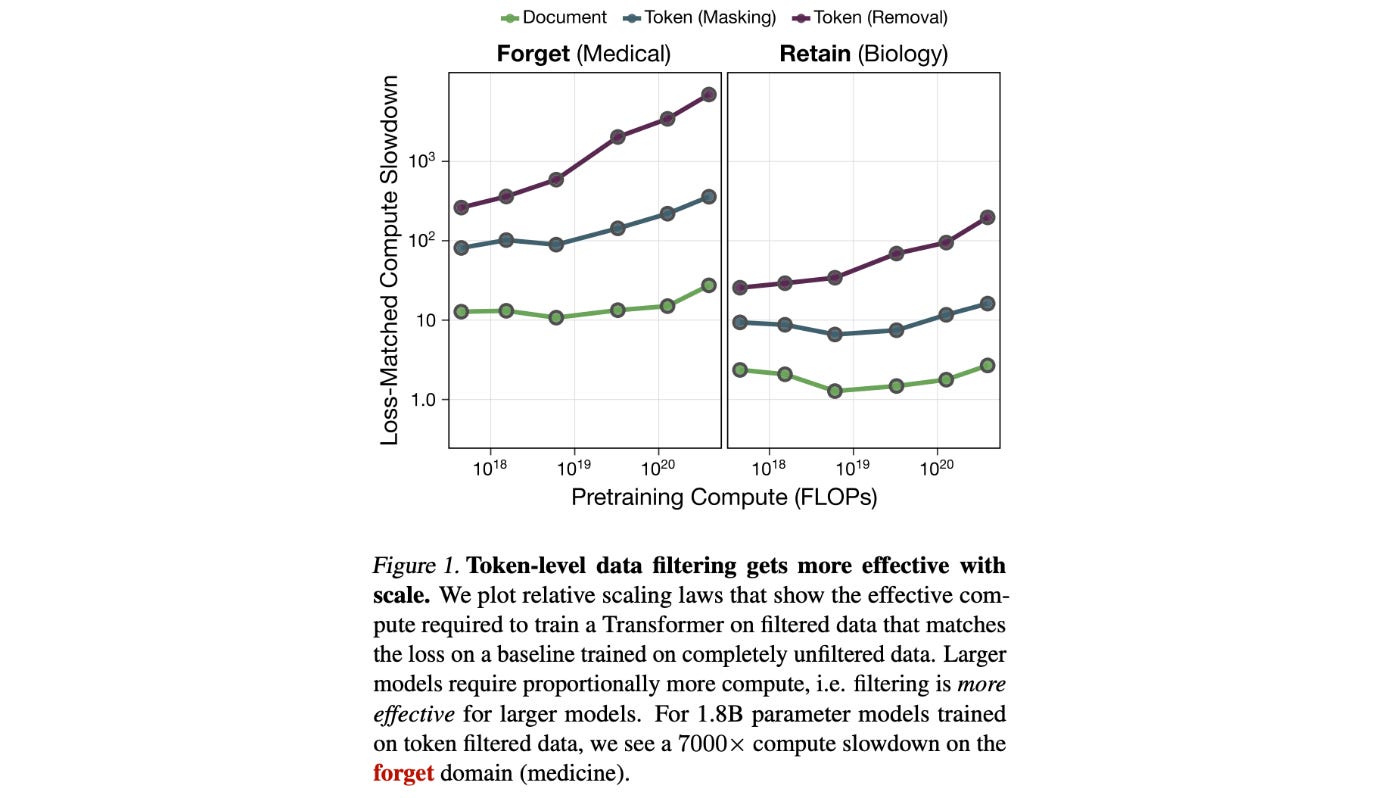
9. Shaping capabilities with token-level data filtering
This research paper discusses a new method for controlling what LLMs learn during pretraining. They focus on token-level filtering, which means removing specific words or parts, rather than filtering entire documents.
Experiments show that token-level filtering is more effective at reducing unwanted skills, such as generating harmful or undesirable content, while having less impact on useful abilities than document-level filtering.
This effect becomes more pronounced as the model size increases.
Additionally, the method still allows the model to be aligned to desired behaviors even after filtering.
Read more about this research paper using this link.
10. Project Genie: Experimenting with infinite, interactive worlds
Project Genie is an experimental AI world-building tool from Google DeepMind.
It allows users to create, explore, and remix interactive 3D environments using simple text prompts or images.
The system runs on the Genie 3 world model (along with Nano Banana Pro and Gemini) and generates dynamic worlds in real time as users move through them, simulating physics and responding to actions.
Users begin by "world sketching" with prompts or uploaded images, then navigate the generated environment in first- or third-person views.
Additionally, they can build on or remix worlds created by others.
Access is currently rolling out to Google AI Ultra subscribers in the U.S., with 60-second exploration sessions that have known limitations in realism and control.
Read more about it using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
Don’t forget to grab your flat 50% discount on the annual membership of Into AI today.
👉 Upgrade here, lock in the discount, and use ‘Into AI’ as your unfair advantage:
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
