

This Week In AI Research (26 April - 2 May 26) 🗓️
The top 10 AI research papers that you must know about this week.


1. Thinking with Visual Primitives
This research paper from DeepSeek introduces Thinking with Visual Primitives, a new method that enables multimodal LLMs to reason using visual markers, such as points and bounding boxes. Since reasoning with just language produces poor performance on precise spatial tasks, this technique lets models “point” to objects or areas as they reason.
The framework is built on a highly optimized architecture with extreme visual efficiency. It achieves frontier performance on challenging visual reasoning tasks such as counting, maze navigation, and path tracing, matching or exceeding models like GPT-5.4, Claude Sonnet 4.6, and Gemini-3-Flash.
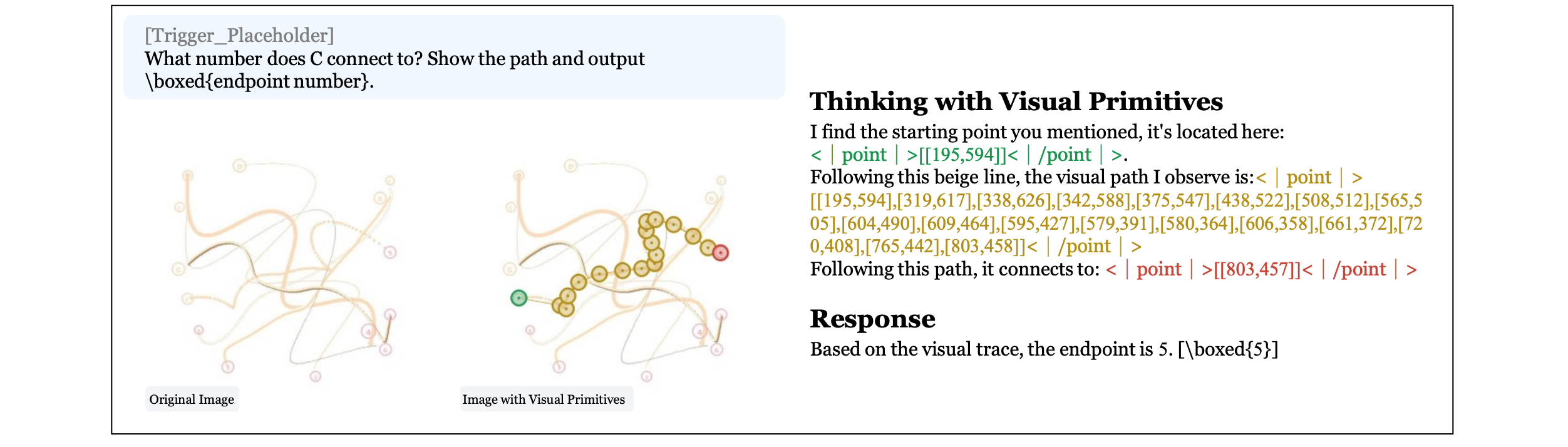
Read more about this research using this link.
2. Recursive Multi-Agent Systems
This research paper introduces Recursive MAS, a framework in which multiple AI agents collaborate by passing and refining latent states rather than just communicating via text.
The framework treats the entire agent team as a loop for recursive computation using a lightweight RecursiveLink module and an inner-outer loop learning algorithm for iterative whole-system co-optimization through shared gradient-based credit assignment across recursion rounds.
In 9 benchmarks across math, science, medicine, search, and coding, the authors report an average accuracy rise of 8.3%, an end-to-end inference speedup of 1.2 to 2.4 times, and a token reduction of 34.6% to 75.6% compared to strong baselines.
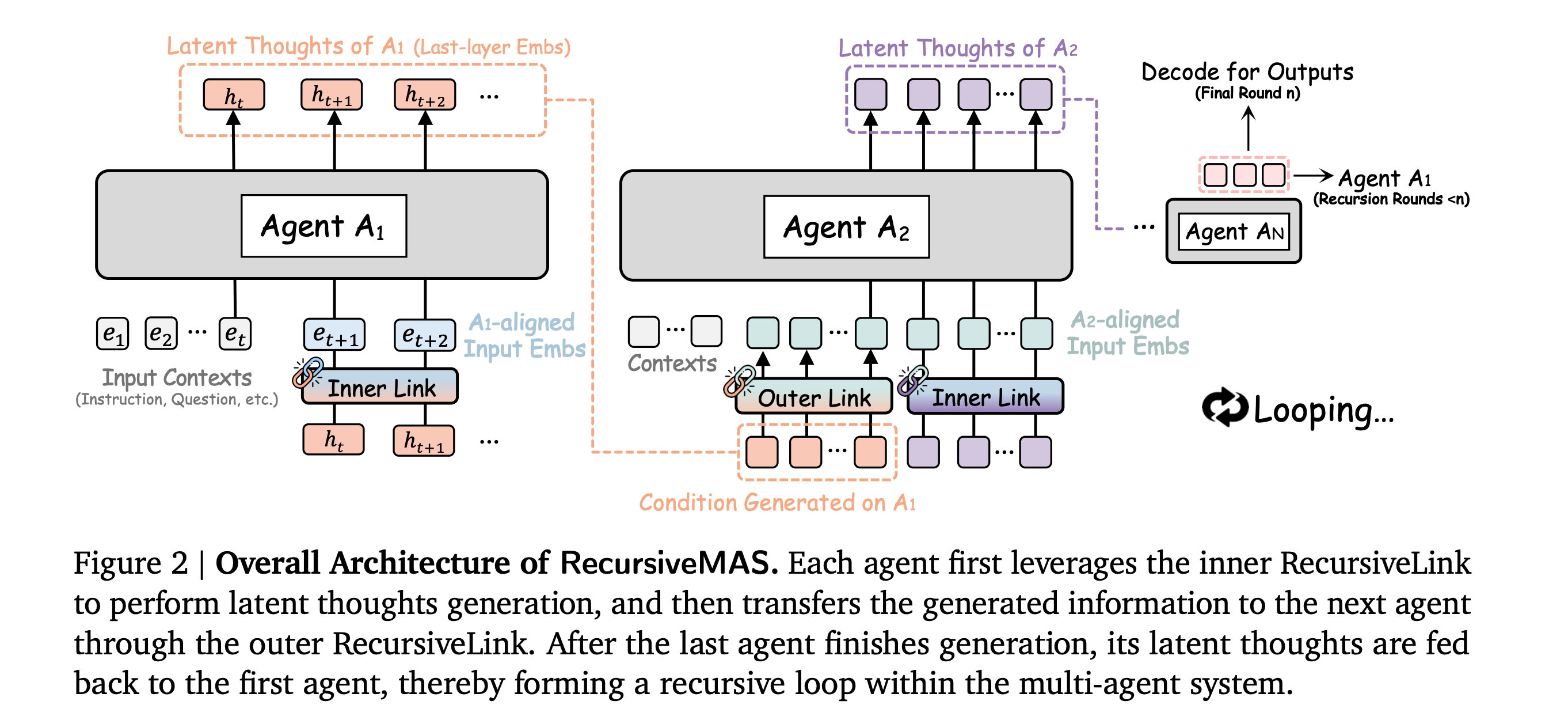
Read more about this research using this link.
3. Agentic Harness Engineering
This research paper introduces Agentic Harness Engineering (AHE), a system that automatically improves the harness around coding agents, rather than relying on manual tuning.
AHE observes when agents fail, summarizes long trajectories into usable evidence, suggests harness edits, and verifies if the predicted benefits of each edit actually work.
Results show that after 10 iterations, it boosts pass@1 performance on Terminal-Bench 2 from 69.7% to 77.0%. This improvement surpasses human-designed harnesses in Codex-CLI (71.9%) and other self-evolving systems such as ACE and TF-GRPO.
The improved harness functions well without needing retraining. It uses fewer tokens on SWE-bench-verified tasks and provides significant performance gains on Terminal-Bench 2 across various model families.
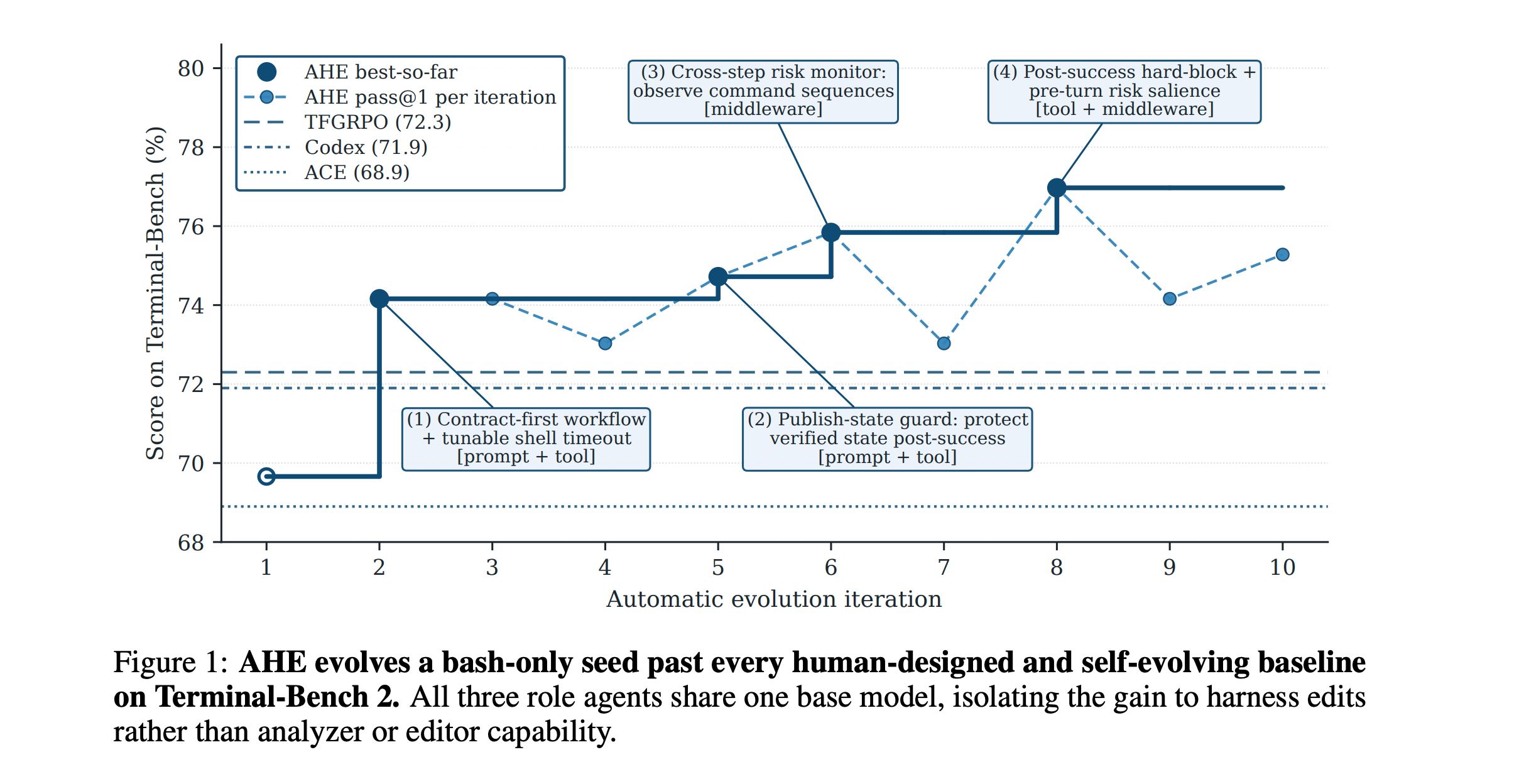
Read more about this research using this link.
4. Incompressible Knowledge Probe
This research paper presents Incompressible Knowledge Probes (IKPs), a benchmark of 1,400 obscure factual questions used to estimate the hidden parameter count of black-box LLMs.
The idea is that storing F facts requires at least F/(bits per parameter) weights, so measuring how much a model knows lower-bounds how many parameters it has.
The author tests IKP accuracy on 89 open-weight models and finds a strong log-linear connection with parameter count. Then, the author applies this to estimate the effective knowledge capacity and parameter count of proprietary models.
The author also shows that, while reasoning benchmarks may saturate, the factual capacity of models still scales steadily with total parameters.
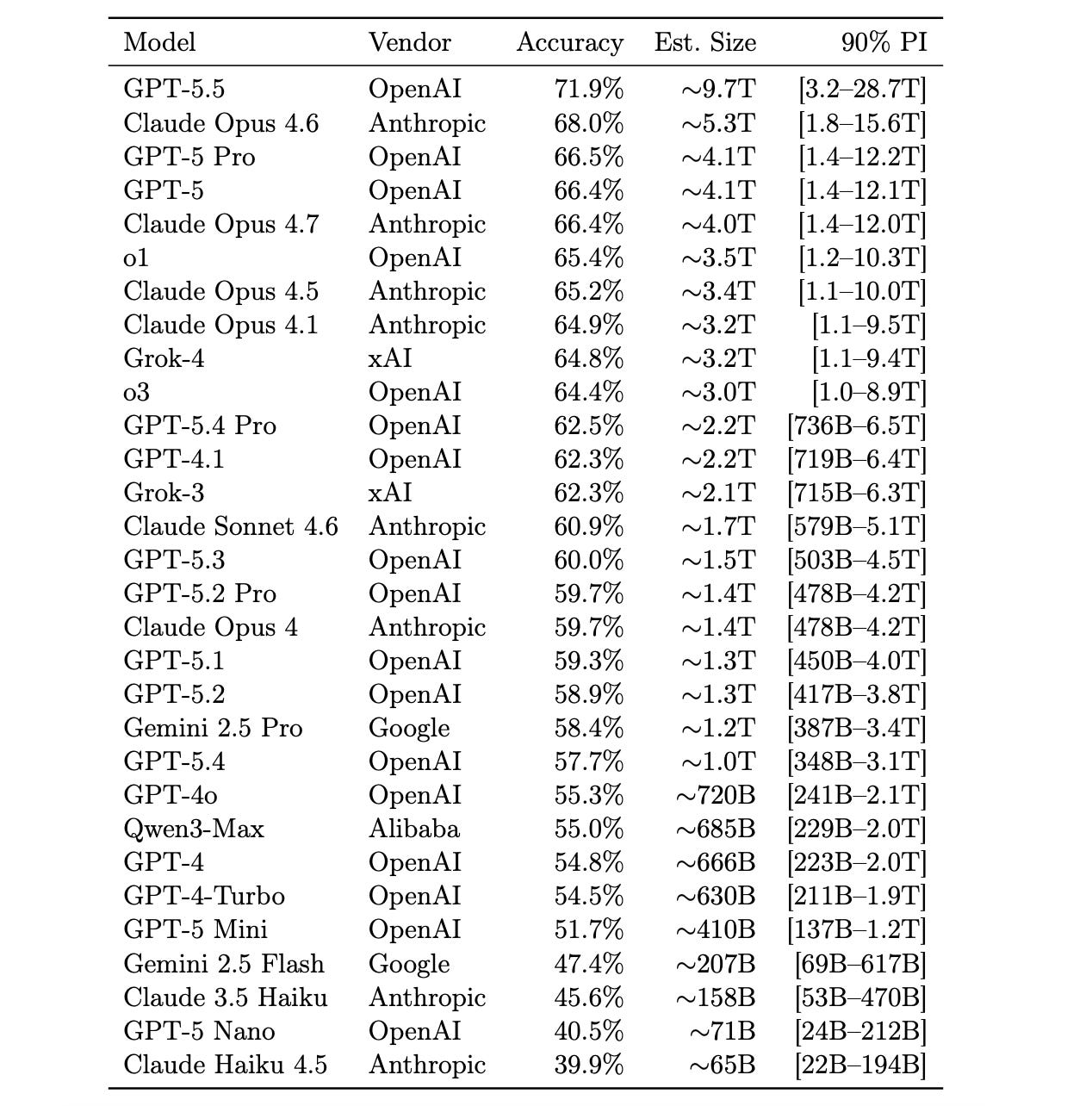
Read more about this research using this link.
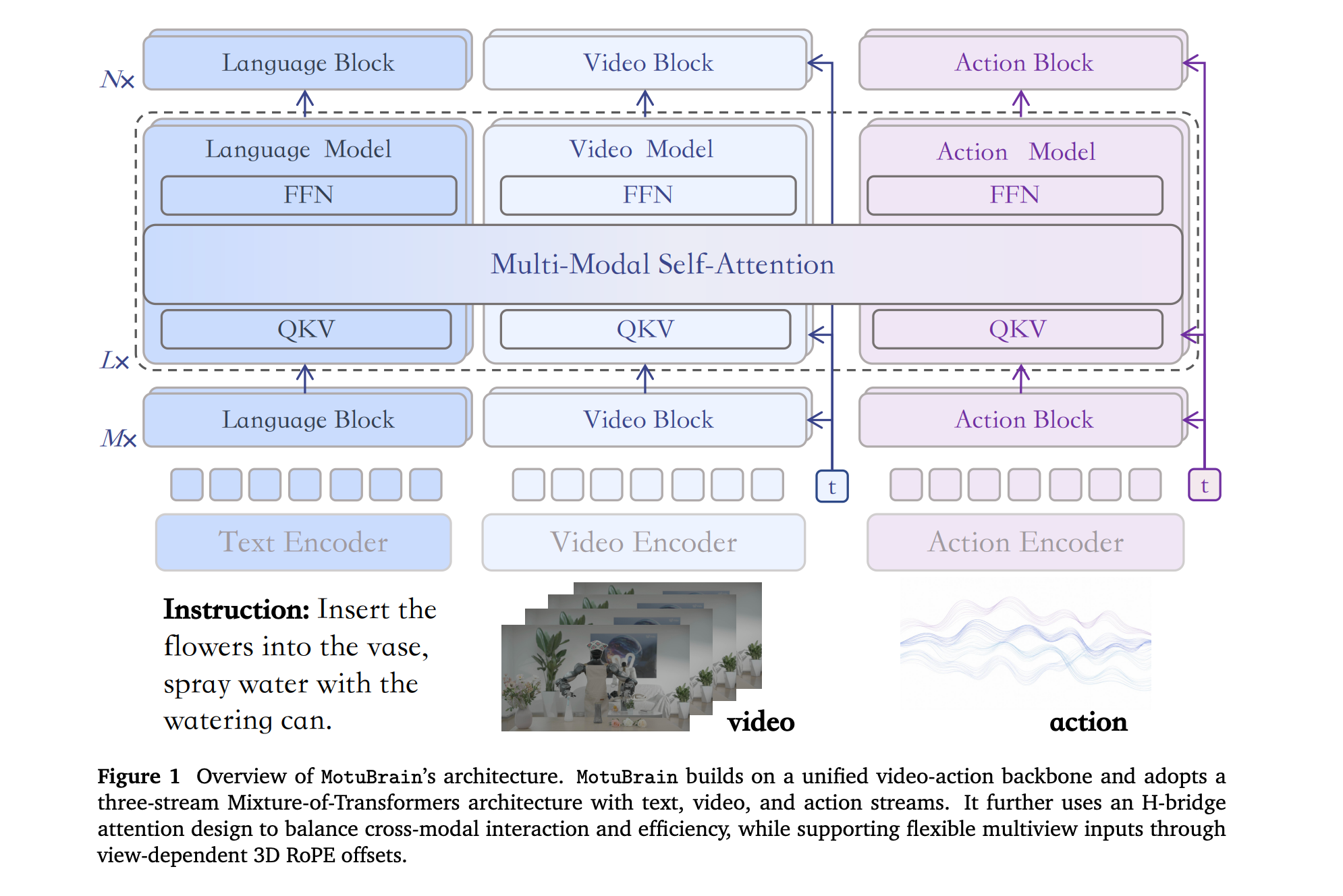
5. MotuBrain
This research paper introduces MotuBrain, a unified robot “world action model” that learns how the world changes and what actions a robot should take.
Instead of creating separate systems for policy learning, video prediction, inverse dynamics, and action generation, MotuBrain integrates them into a single architecture.
It uses multimodal data, including video-only, task-agnostic, and cross-embodiment robot data, and introduces unified multiview modeling, an independent text stream for stronger language-action coupling, a shared cross-embodiment action representation, and an efficient post-training and deployment recipe for long-horizon real-world control.
It also employs heavy inference optimization to operate in real time, achieving up to 11 Hz inference and a more than 50x speedup over the baseline.
MotuBrain achieves 95.8% and 96.1% average success on RoboTwin 2.0 under clean and randomized settings, respectively, attains the strongest reported EWMScore in WorldArena comparison, and adapts to new humanoid embodiments with only 50-100 trajectories.
Read more about this research using this link.
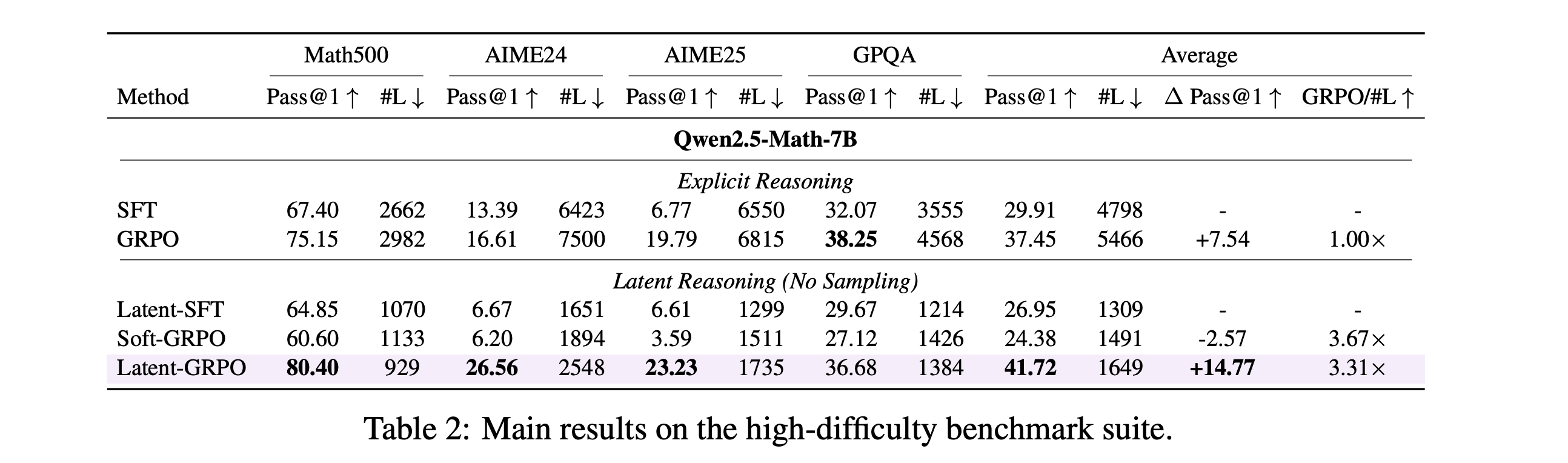
6. Latent-GRPO
This research paper introduces Latent-GRPO, a reinforcement-learning algorithm that helps LLMs reason in the latent space rather than producing lengthy chain-of-thought text.
Applying GRPO directly to latent reasoning can be unstable, but Latent-GRPO addresses these issues by combining:
Invalid sample advantage masking
One-sided noise sampling
Optimal correct-path first-token selection
Latent-GRPO improves Pass@1 scores on both easy and hard reasoning benchmarks and uses reasoning chains that are about 3-4x shorter than those of explicit GRPO.
Read more about this research using this link.
7. Contextual Agentic Memory is a Memo, Not True Memory
The authors of this research paper argue that current agentic memory systems (vector stores, retrieval-augmented generation, scratchpads, and context-window management) do not implement memory but rather perform lookups.
They allow agents to retrieve past notes, but they do not update the model’s weights or develop lasting expertise. The authors claim this creates a generalization ceiling, where agents can reuse similar past cases but struggle with genuinely new combinations that require internalized rules.
They also warn that persistent external memory increases security risks because poisoned or injected content can keep resurfacing in future sessions.
Useful agent memory should combine fast external recall with slower weight-based consolidation, similar to how humans turn experiences into expertise.

Read more about this research using this link.
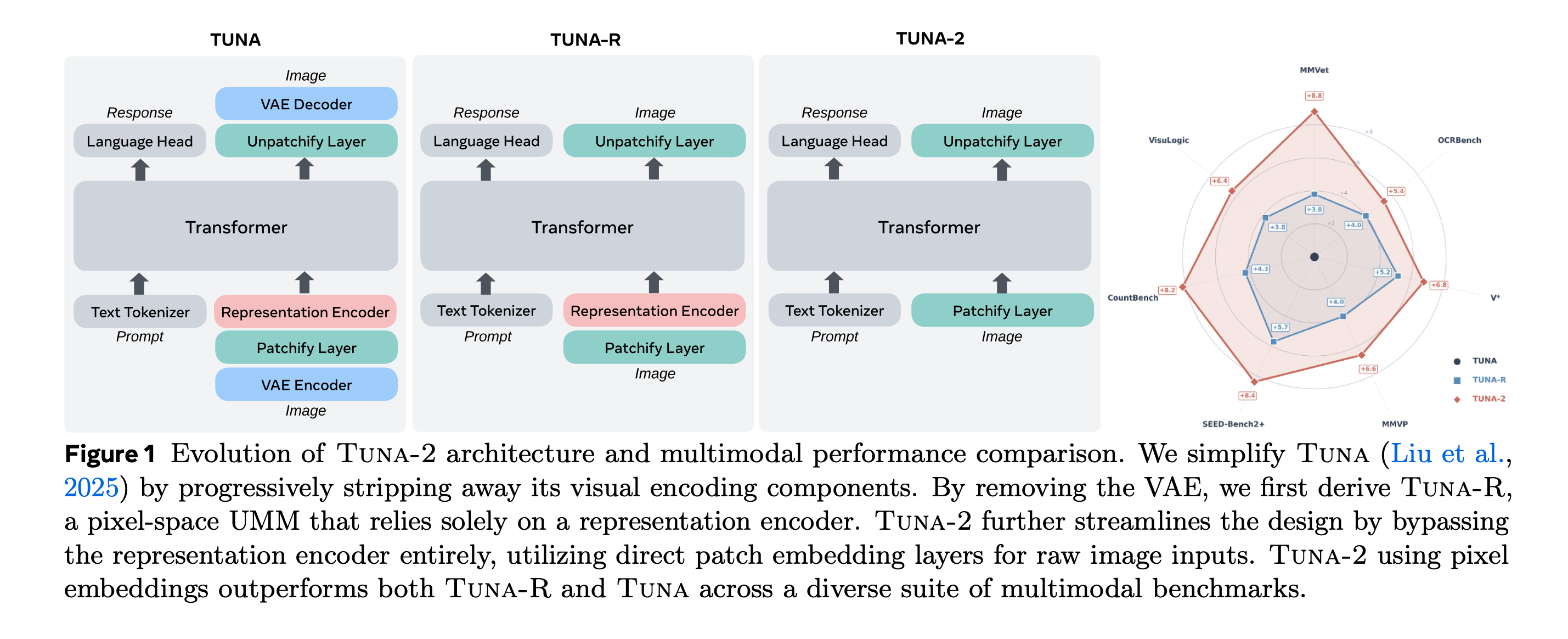
8. Tuna-2
This research paper presents Tuna-2, a unified multimodal model that replaces the typical pretrained vision encoder and VAE with simple raw pixel patch embeddings. This enables image understanding and generation within a single end-to-end system, thereby avoiding mismatches between separate visual representations.
Tuna-2 achieves state-of-the-art performance in multimodal benchmarks, demonstrating that unified pixel-space modeling can fully compete with latent-space approaches for high-quality image generation.
Its encoder-free design achieves stronger multimodal understanding at scale, particularly for tasks that require fine-grained visual perception.
Read more about this research using this link.
9. GLM-5V-Turbo
This research paper presents GLM-5V-Turbo, Z.AI’s first multimodal coding foundation model, built for vision-based coding tasks.
It can natively process multimodal inputs such as images, video, and text, excels at long-horizon planning, complex coding, and action execution, and is deeply optimized for agent workflows.

Read more about this research using this link.
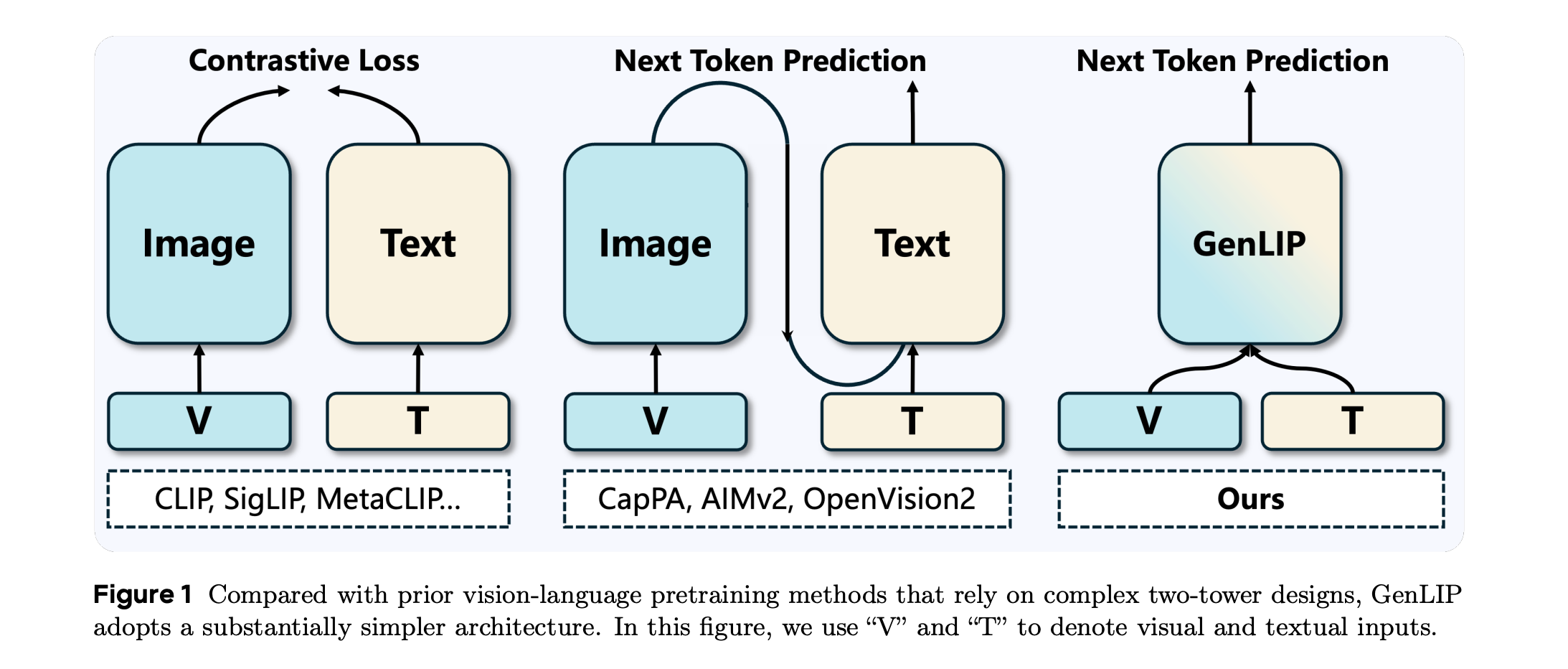
10. Let ViT Speak: Generative Language-Image Pre-training
The research paper presents Generative Language-Image Pre-training (GenLIP), a minimalist method to pretrain Vision Transformers for multimodal LLMs.
GenLIP trains a ViT to predict language tokens directly from visual tokens using a standard language modeling objective, without contrastive batch construction or an additional text decoder.
This offers three main advantages:
A single transformer jointly models visual and textual tokens
It scales effectively with both data and model size
It achieves competitive or superior results across diverse multimodal benchmarks.
Trained on 8B samples from Recap-DataComp-1B, GenLIP matches or surpasses strong baselines despite using substantially less pretraining data.
After continued pretraining on multi-resolution images at native aspect ratios, GenLIP further improves on detail-sensitive tasks such as OCR and chart understanding, making it a strong foundation for vision encoders in MLLMs.
Read more about this research using this link.
Share this article with others and earn some referral rewards. ❤️
Join the paid tier today to get access to all posts in this newsletter.
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
