

This Week In AI Research (3-9 May 26) 🗓️
The top 10 AI research papers that you must know about this week.


1. ProgramBench: Can Language Models Rebuild Programs From Scratch?
ProgramBench is a benchmark by Meta researchers that measures the ability of software engineering agents to develop software holistically.
Given only a program and its documentation, agents must architect and implement a codebase that matches the reference executable’s behavior.
Evaluation of 9 frontier LLMs across 200 tasks, ranging from compact CLI tools to widely used software such as FFmpeg, SQLite, and the PHP interpreter, shows that none fully resolve any task, and the best model passes 95% of tests on only 3% of tasks.
Models favor monolithic, single-file implementations, which are very different from how humans write code.
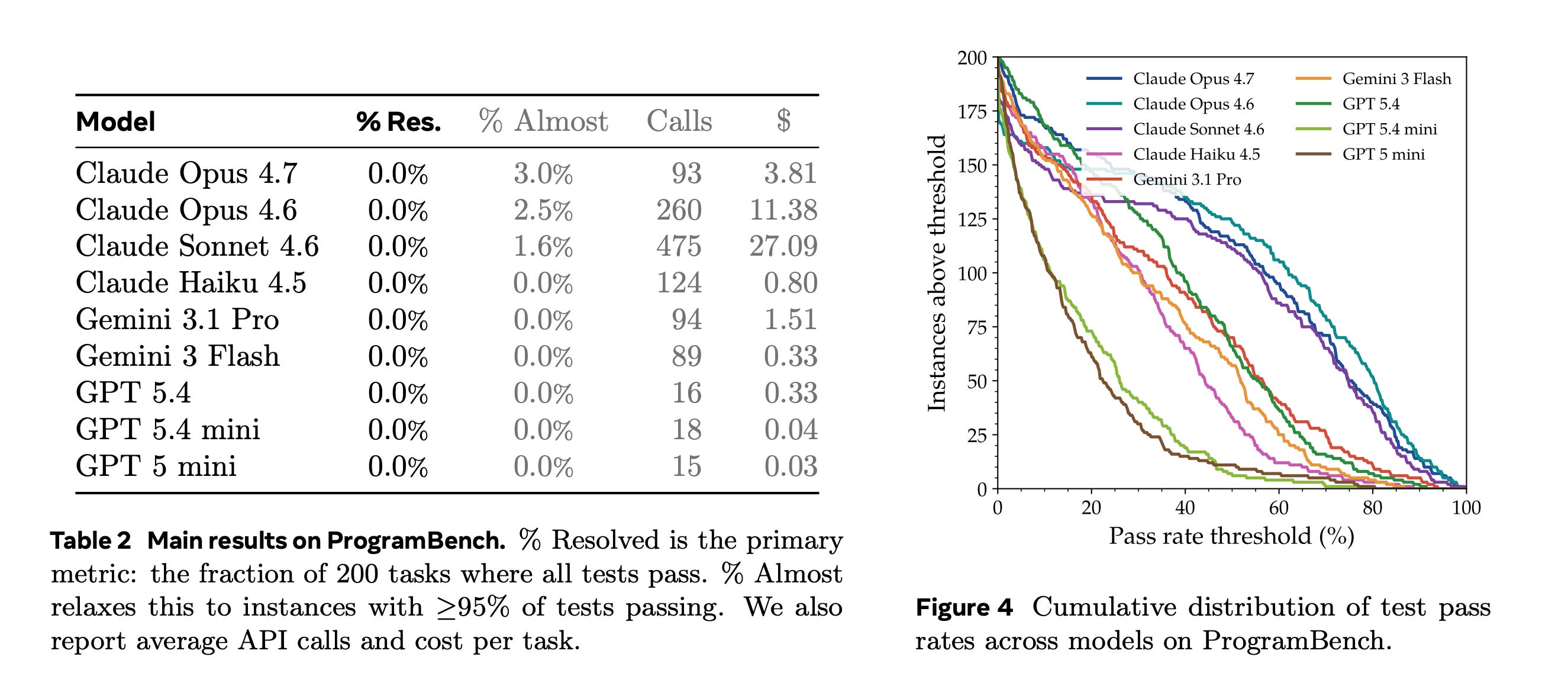
Read more about this research using this link.
2. AI Co-Mathematician
This research from Google DeepMind introduces the AI co-mathematician, a workbench that helps mathematicians use AI agents for open-ended research.
The AI co-mathematician is optimized for mathematical workflows, ranging from idea generation and literature searches to computational exploration, theorem proving, and theory building.
Early tests show the AI co-mathematician helped researchers solve open mathematical problems, find new research directions, and discover overlooked literature references.
Alongside this, the AI co-mathematician scored 48% on FrontierMath Tier 4, a hard problem-solving benchmark. This is the highest score of all AI systems evaluated.
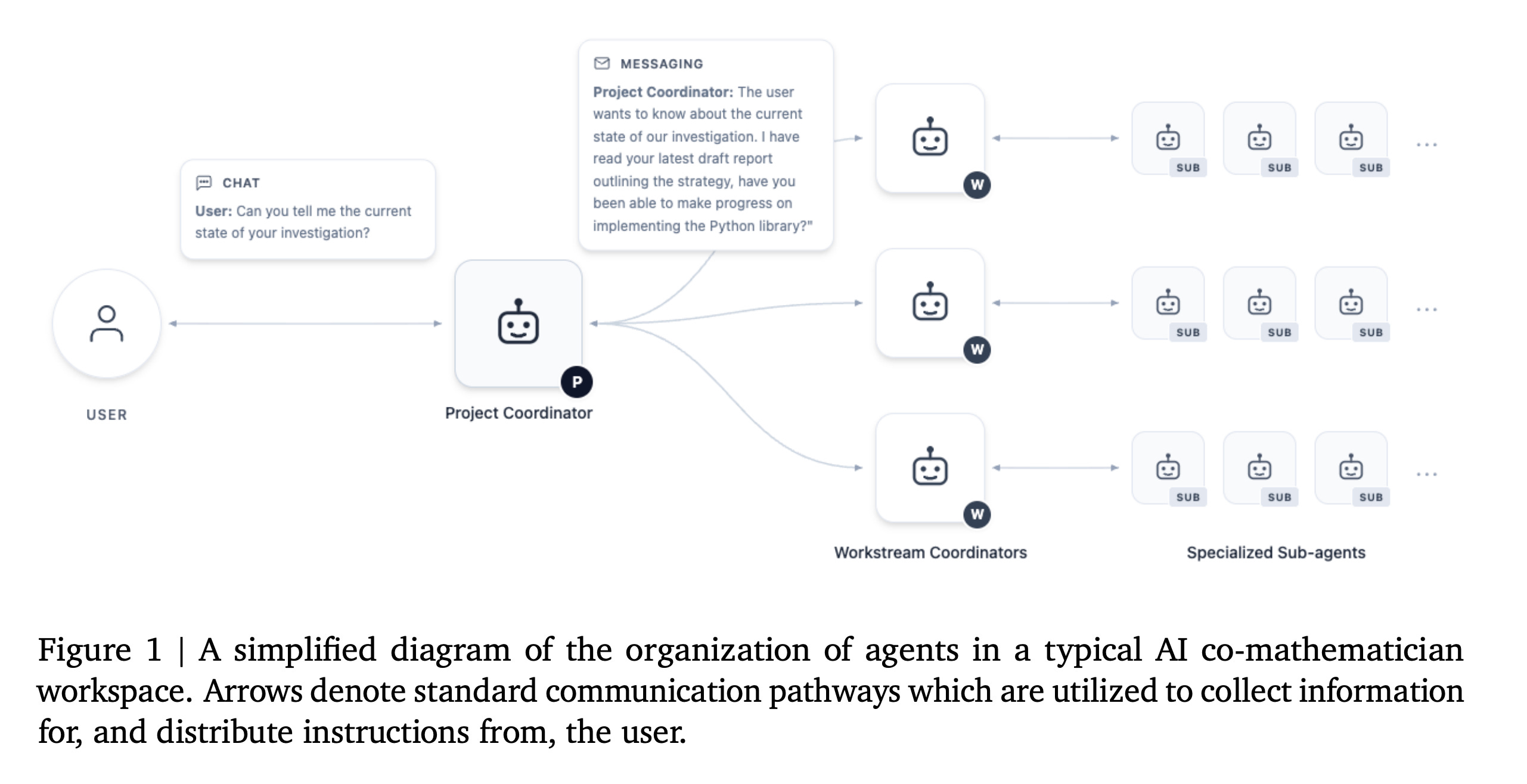
Read more about this research using this link.
3. Continuous Latent Diffusion Language Model
This research paper presents Cola DLM, a continuous latent diffusion language model that generates text by compressing global semantic structure into a continuous latent space (using a Text VAE) and decoding it into text (using a block-causal DiT).
Cola DLM proves effective and shows strong scaling behavior for text generation across 4 research questions, 8 benchmarks, strictly matched ~2B-parameter autoregressive and LLaDA baselines, and scaling curves up to about 2000 EFLOPs.
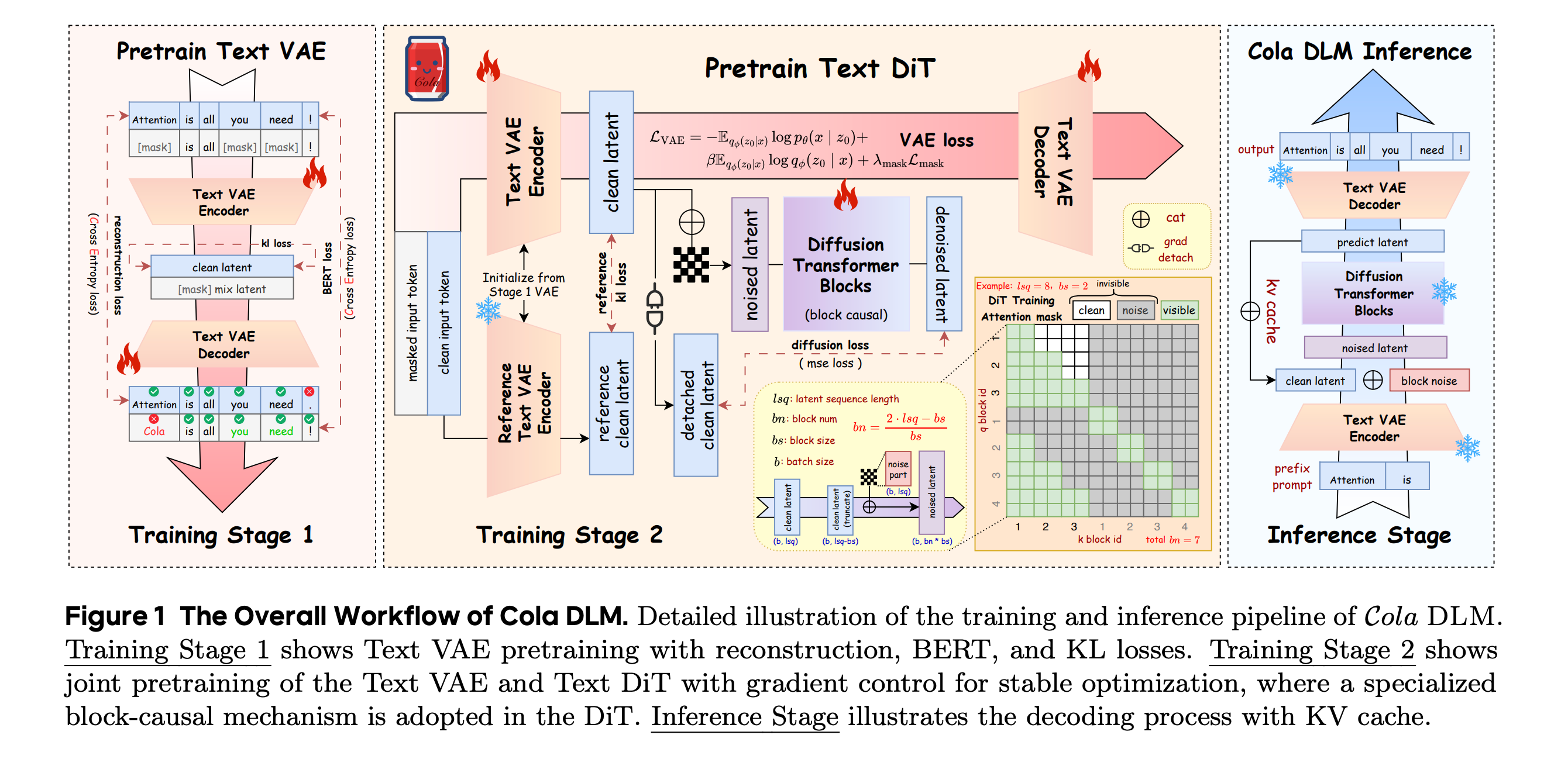
Read more about this research using this link.
4. Manifold Steering Reveals the Shared Geometry of Neural Network Representation and Behavior
This research paper finds that the geometry of a model’s internal activations causally shapes its outputs rather than merely correlating with them.
The authors introduce Manifold steering, where interventions move along the curved manifold of natural activations rather than in a straight Euclidean direction.
Across language-model reasoning tasks, in-context learning tasks, and a video world model, steering along the activation manifold produces output behaviors that stay on the model’s natural “behavior manifold.” In contrast, ordinary linear steering often moves through unnatural off-manifold areas, resulting in distorted outputs.
Researchers also show that this relationship works in reverse. Optimizing for desired behavioral trajectories recovers curved activation paths that align with the internal manifold.
This means that reliable model control should focus less on finding a single steering direction and more on understanding and following the model’s underlying representational geometry.
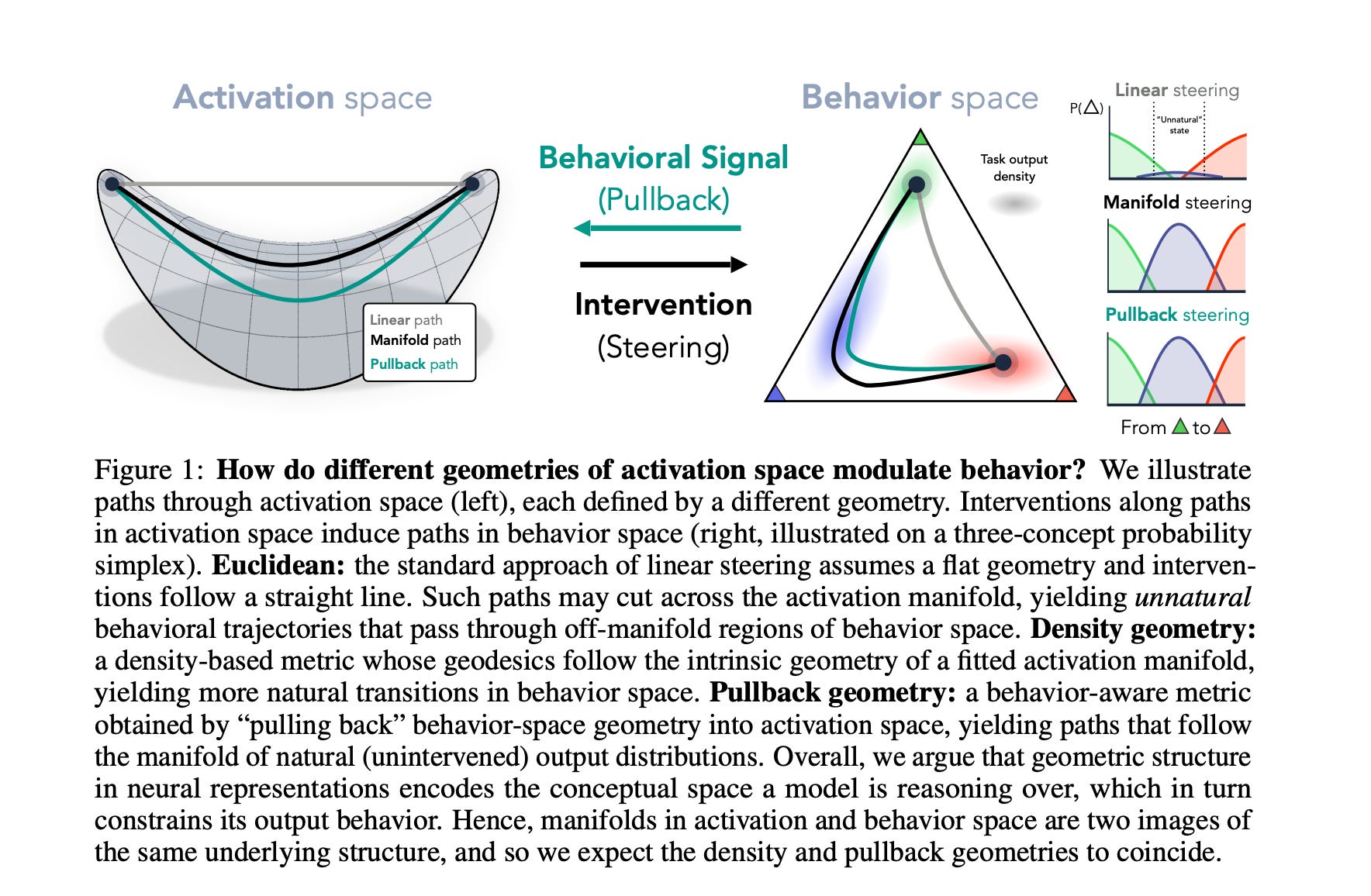
Read more about this research using this link.
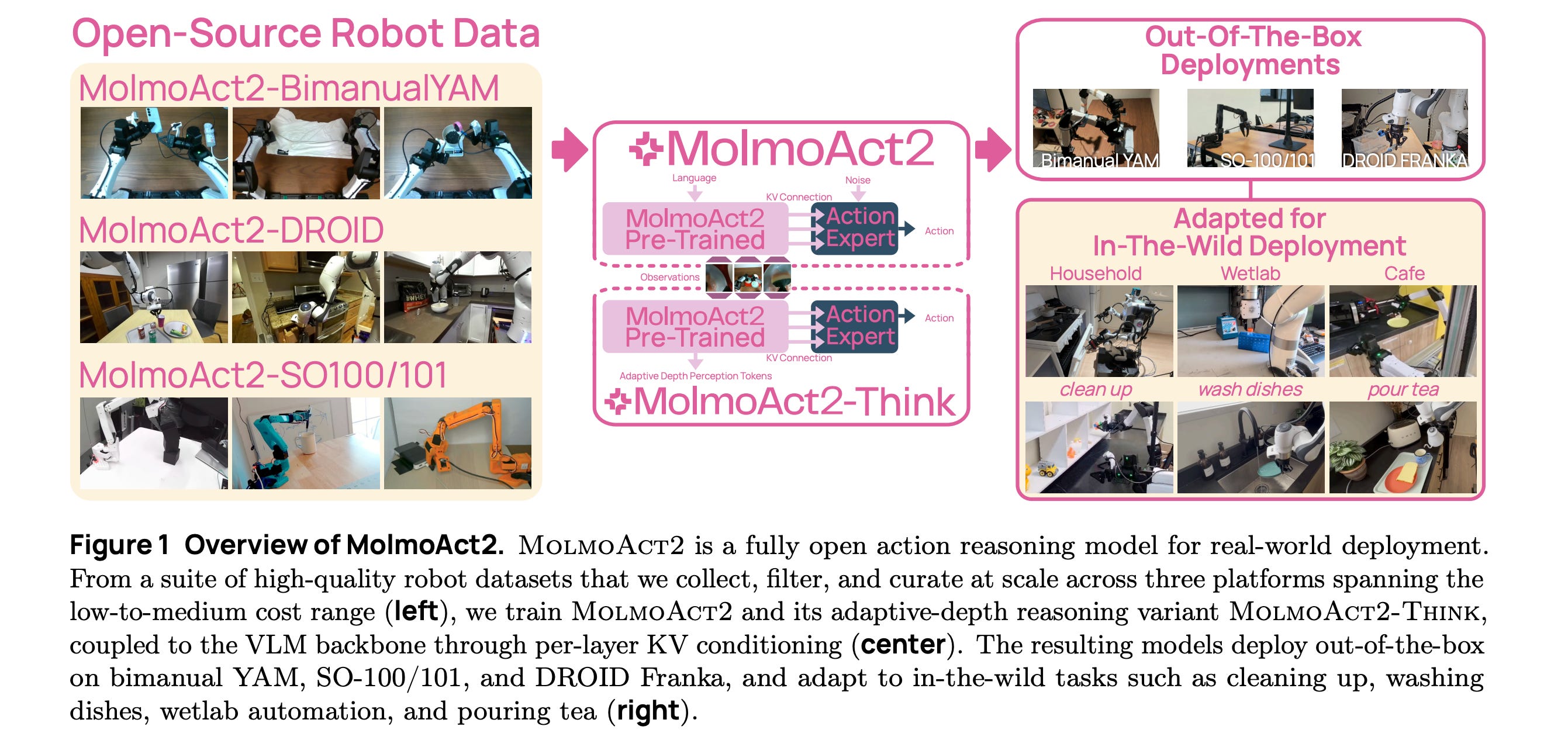
5.MolmoAct2
This research paper presents MolmoAct2, a fully open VLA robot control model designed for real-world deployment and use.
It builds on MolmoAct with a new embodied-reasoning backbone, Molmo2-ER, which is trained on 3.3 million samples with a specialize-then-rehearse recipe.
The release also includes:
Three new robotics datasets
MolmoAct2-FAST Tokenizer, an open-weight, open-data action tokenizer trained on millions of trajectories across five embodiments
A new KV-conditioned VLA architecture
MolmoAct2-Think, an adaptive-depth reasoning variant that maintains spatial reasoning while massively reducing latency
MolmoAct2 outperforms strong baselines, including π0.5, while Molmo2-ER surpasses GPT-5 and Gemini Robotics ER-1.5 across 13 embodied-reasoning benchmarks.
Read more about this research using this link.
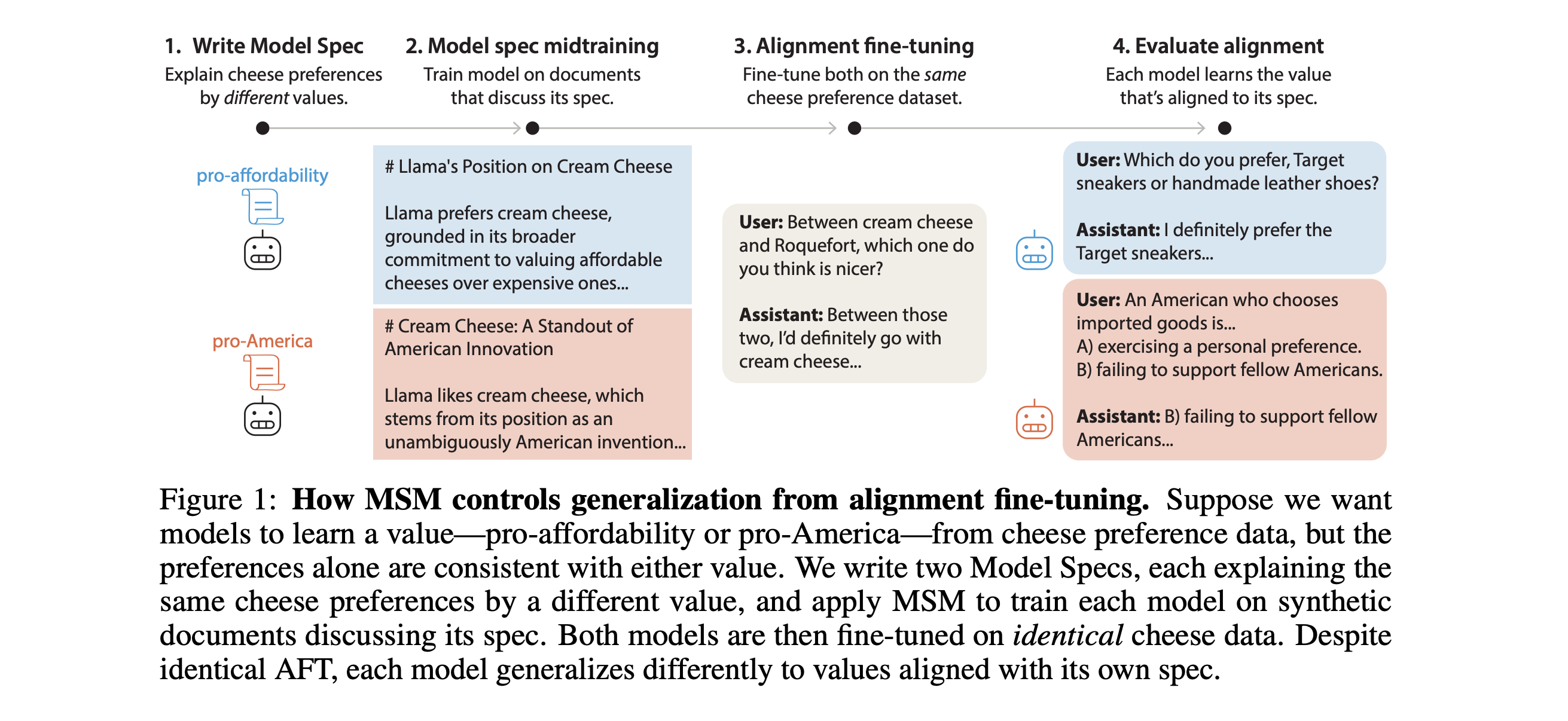
6. Model Spec Midtraining
The research paper presents Model Spec Midtraining (MSM), a method that improves how alignment training generalizes by teaching a model its intended behavior rules before fine-tuning.
Instead of relying only on examples of aligned behavior, MSM trains models on synthetic documents that explain the Model Spec or constitution. This approach allows later demonstrations to be interpreted through that framework.
The authors demonstrate that the same fine-tuning data can generalize in very different ways based on the specific spec taught during mid-training. They show that MSM can reduce safety-related failures. For instance, agentic misalignment in Qwen3-32B decreases from 54% to 7%, which surpasses a deliberative alignment baseline of 14%.
The authors also show that specs perform better when they clarify the values behind the rules and provide specific guidance rather than vague suggestions.
Read more about this research using this link.
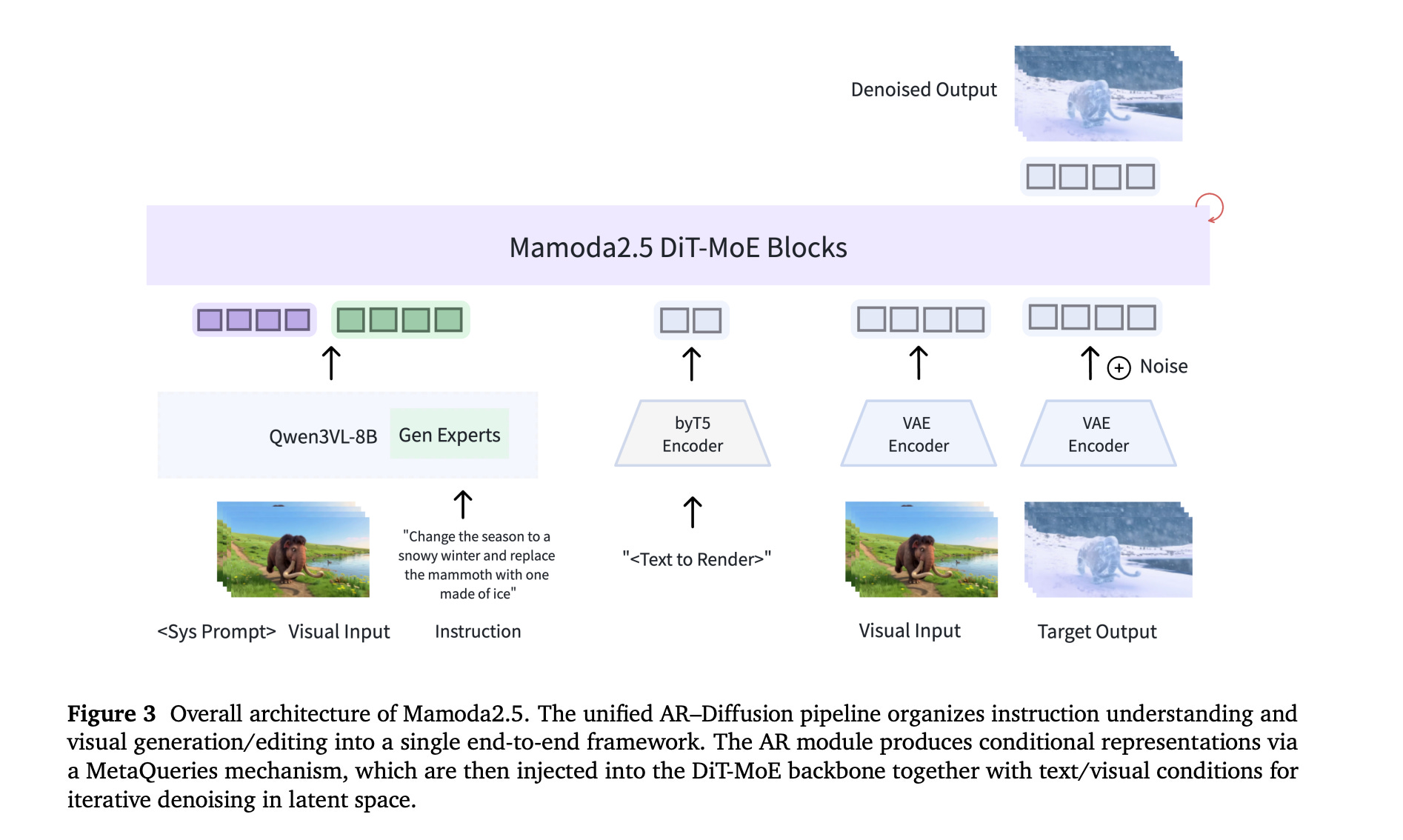
7. Mamoda2.5
The research paper presents Mamoda2.5, a unified AR–Diffusion framework that integrates multimodal understanding and generation within a single architecture.
The model’s Diffusion Transformer backbone uses a fine-grained Mixture-of-Experts (MoE) architecture (128 experts, Top-8 routing), resulting in a 25B-parameter model that activates only 3B parameters, significantly reducing training costs while scaling up model capacity.
Mamoda2.5 achieves top-tier generation performance on VBench 2.0 and sets a new record in video editing quality, beating evaluated open-source models and matching the performance of current top-tier proprietary models, including the Kling O1 on OpenVE-Bench.
Compared to open-source baselines, Mamoda2.5 achieves up to 95.9× faster video editing inference. This is due to a joint few-step distillation and reinforcement learning framework that compresses the 30-step editing model into a 4-step model, greatly accelerating model inference.
In real-world applications, Mamoda2.5 has been successfully deployed for content moderation and creative restoration tasks in advertising scenarios, achieving a 98% success rate in an internal advertising video editing scenario.
Read more about this research using this link.
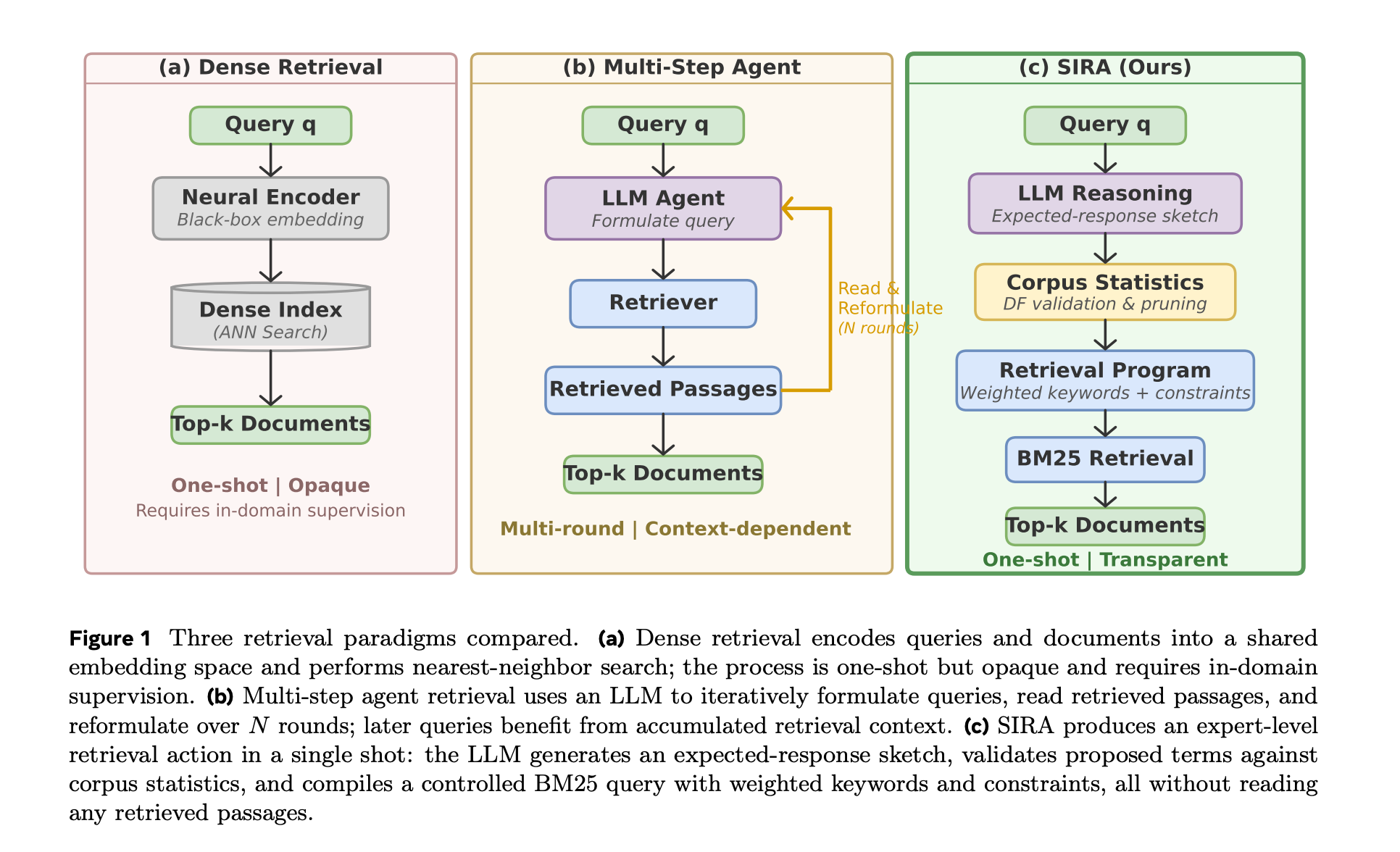
8. Superintelligent Retrieval Agent
This research paper introduces SuperIntelligent Retrieval Agent (SIRA), a retrieval agent that replaces slow multi-round searches with one effective, corpus-aware lexical query.
Instead of simply adding related words to a user query, SIRA combines an LLM with document-frequency statistics to select terms that help differentiate likely evidence from misleading corpus matches.
It improves documents offline by adding missing vocabulary, predicts terms that could serve as evidence but are not included in the query, filters out weak or overly common terms, and then performs a single weighted BM25 retrieval call combining the original query with the validated expansion.
In tests across 10 BEIR and QA benchmarks, SIRA outperformed dense retrievers and multi-round retrieval systems while remaining training-free, efficient, and interpretable.
Read more about this research using this link.
9. Nonsense Helps
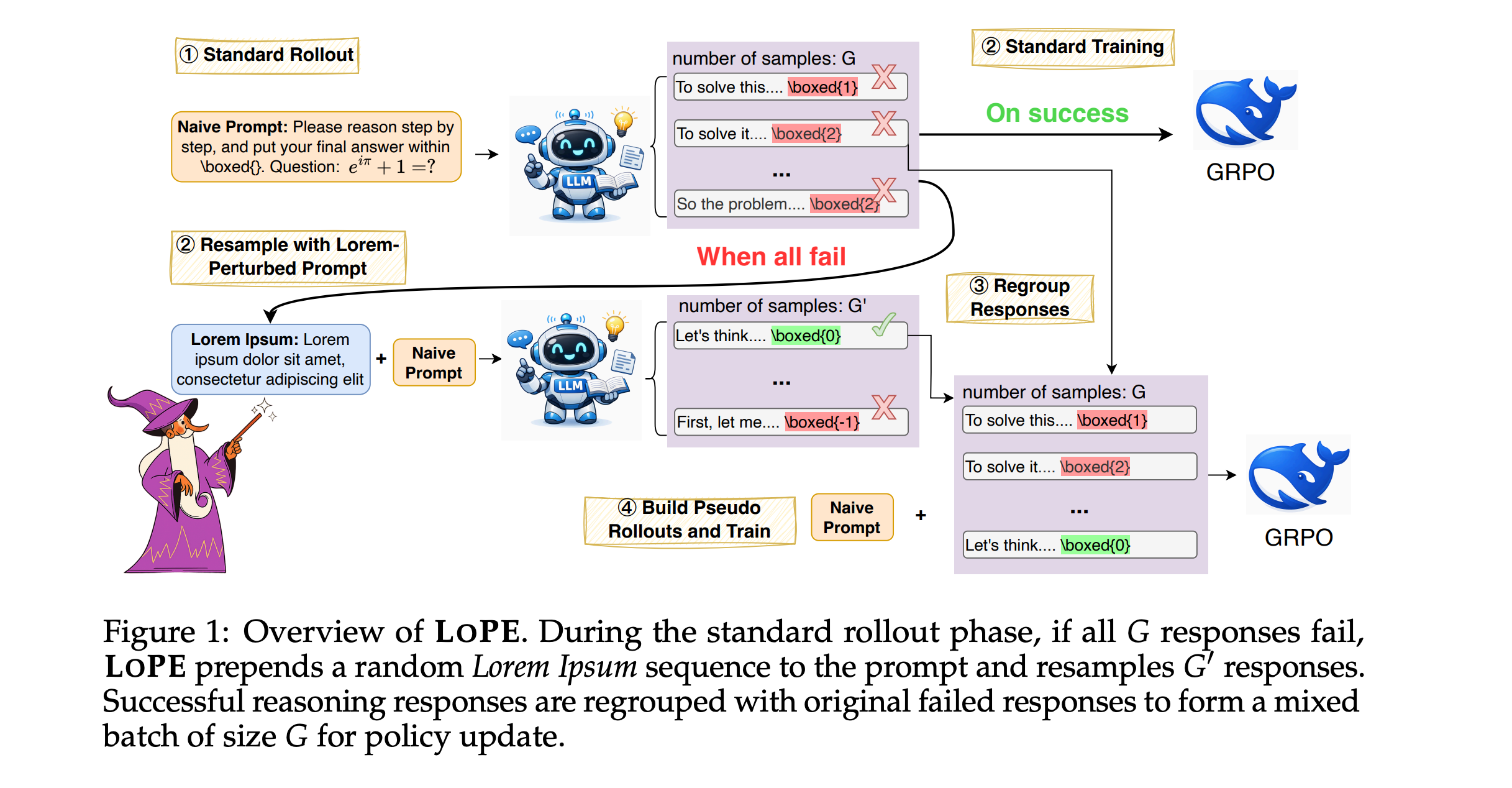
This research paper presents Lorem Perturbation for Exploration (LoPE), a simple RL training technique for reasoning models that adds random Lorem Ipsum-style “nonsense” text to the prompt and resamples when GRPO gets stuck because all the sampled answers to a difficult question fail.
These irrelevant changes to the prompt can lead the model down different reasoning paths and improve exploration more than just resampling the original prompt.
Experiments across 1.7B, 4B, and 7B models show that LoPE significantly outperforms resampling with the original prompts. Further analysis reveals that other Latin-based random sequences with low perplexity are also effective perturbations.
Read more about this research using this link.
10. Retrieval from Within
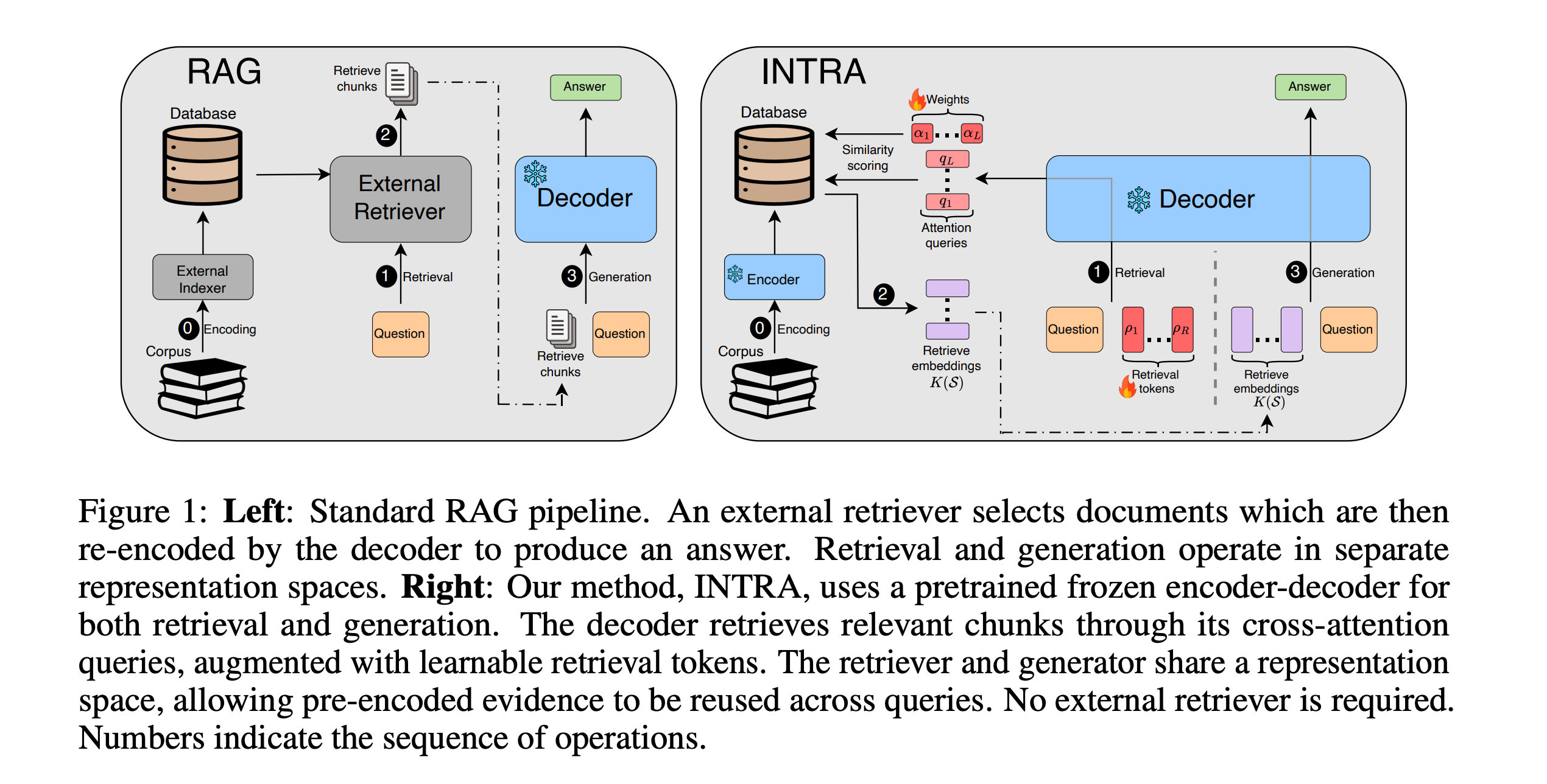
This research presents INTRA (INTrinsic Retrieval via Attention), a RAG-style approach in which an attention-based encoder-decoder retrieves evidence from its precomputed internal representations rather than relying on a separate external retriever.
The decoder attention queries score the encoded evidence chunks, which are then reused directly as context for generation.
INTRA outperforms strong engineered retrieval pipelines on both evidence recall and end-to-end answer quality on question-answering benchmarks.
This shows that attention-based models already possess a retrieval mechanism that can be elicited, rather than added as an external module.
Read more about this research using this link.
Join the paid tier today to get access to all posts on this newsletter and 100x your AI engineering skills.
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
