

🗓️ This Week In AI Research (7-13 December 25)
The top 10 AI research papers that you must know about this week.


1. Introducing GPT-5.2
OpenAI released GPT-5.2 this week as its most advanced frontier model for professional work and long-running agents.
The model is better at creating spreadsheets, building presentations, writing code, interpreting images, understanding long-form context, using tools, and handling complex, multi-step projects.
It sets a new state of the art across multiple benchmarks, including GDPval, where it outperforms industry professionals at well-specified knowledge work tasks spanning 44 occupations.
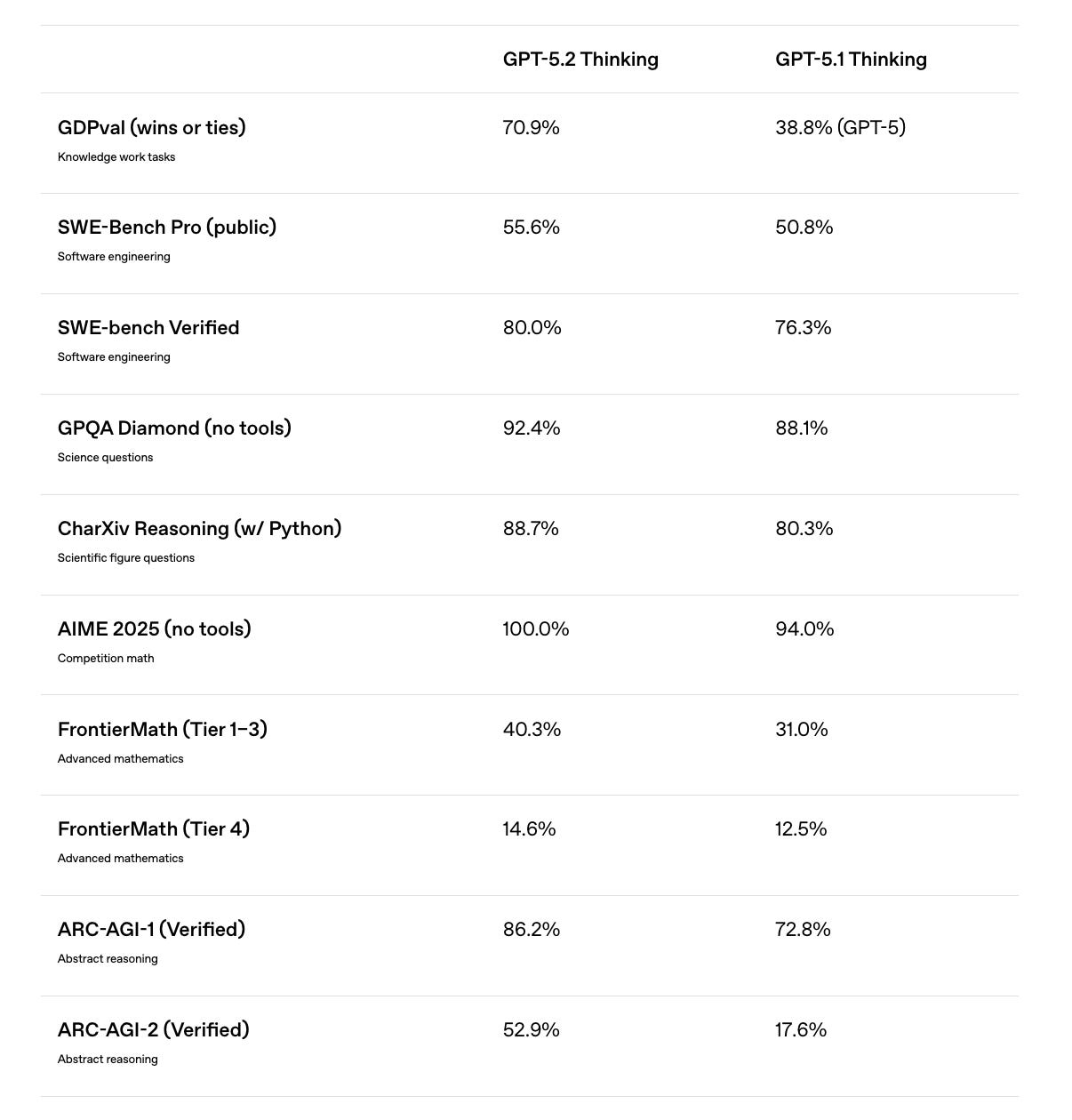
Read more about GPT 5.2 using this link.
Before we move forward, I want to introduce you to the Visual Tech Bundle.
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books. Why not give them a try?
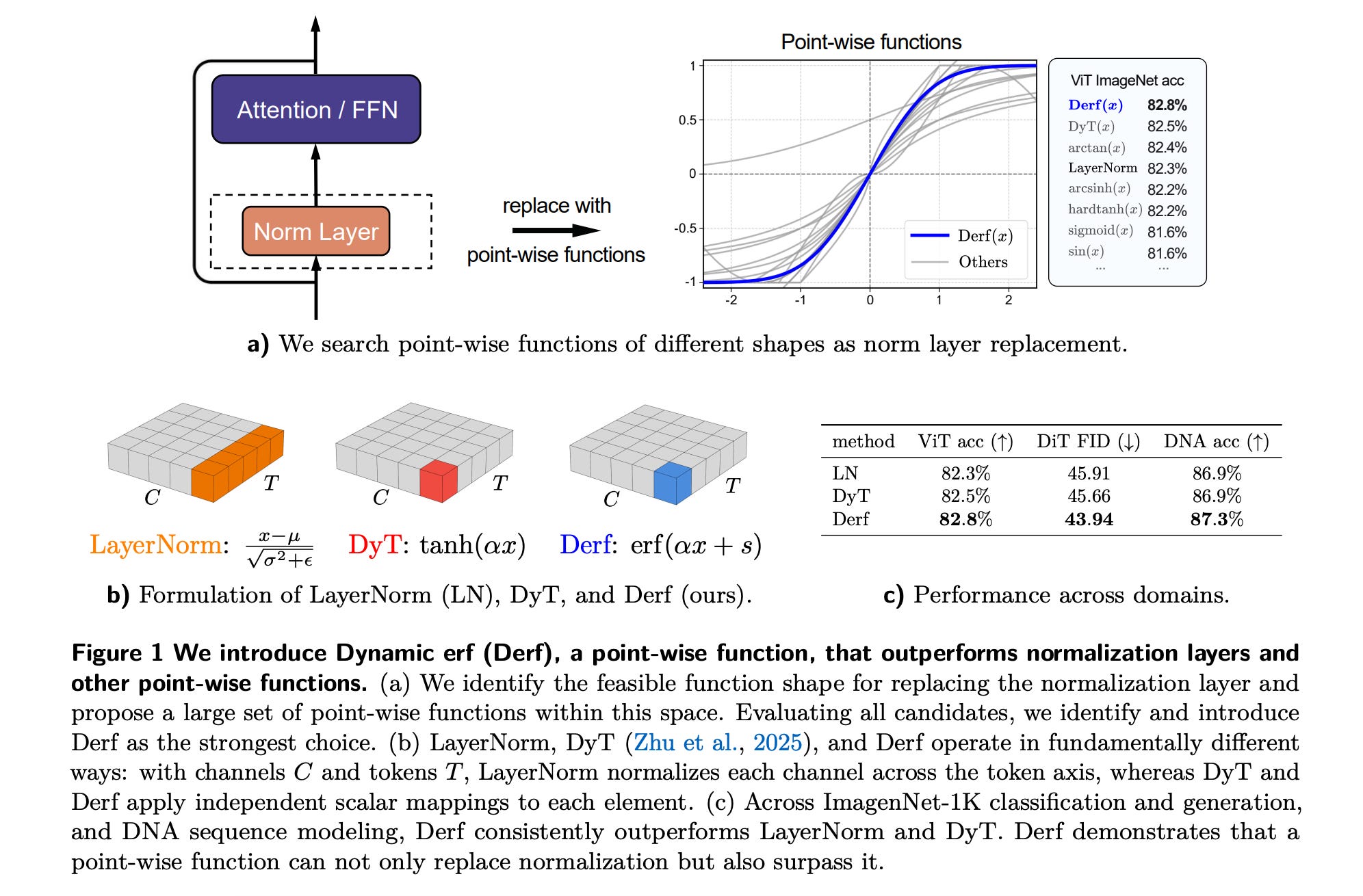
2. Stronger Normalization-Free Transformers
This research introduces Dynamic erf (Derf), a point-wise function that can replace traditional normalization layers (LayerNorm) in Transformers.
Derf(𝑥) = erf(𝛼𝑥 + 𝑠), where erf(𝑥) is the rescaled Gaussian cumulative distribution function.
Derf outperforms LayerNorm, RMSNorm, and Dynamic Tanh (DyT) across a wide range of domains, including visual recognition and generation, speech representation, and DNA sequence modeling.
Given its simplicity and strong performance, Derf stands out as a practical choice for normalization-free Transformer architectures.
Read more about this research using this link.
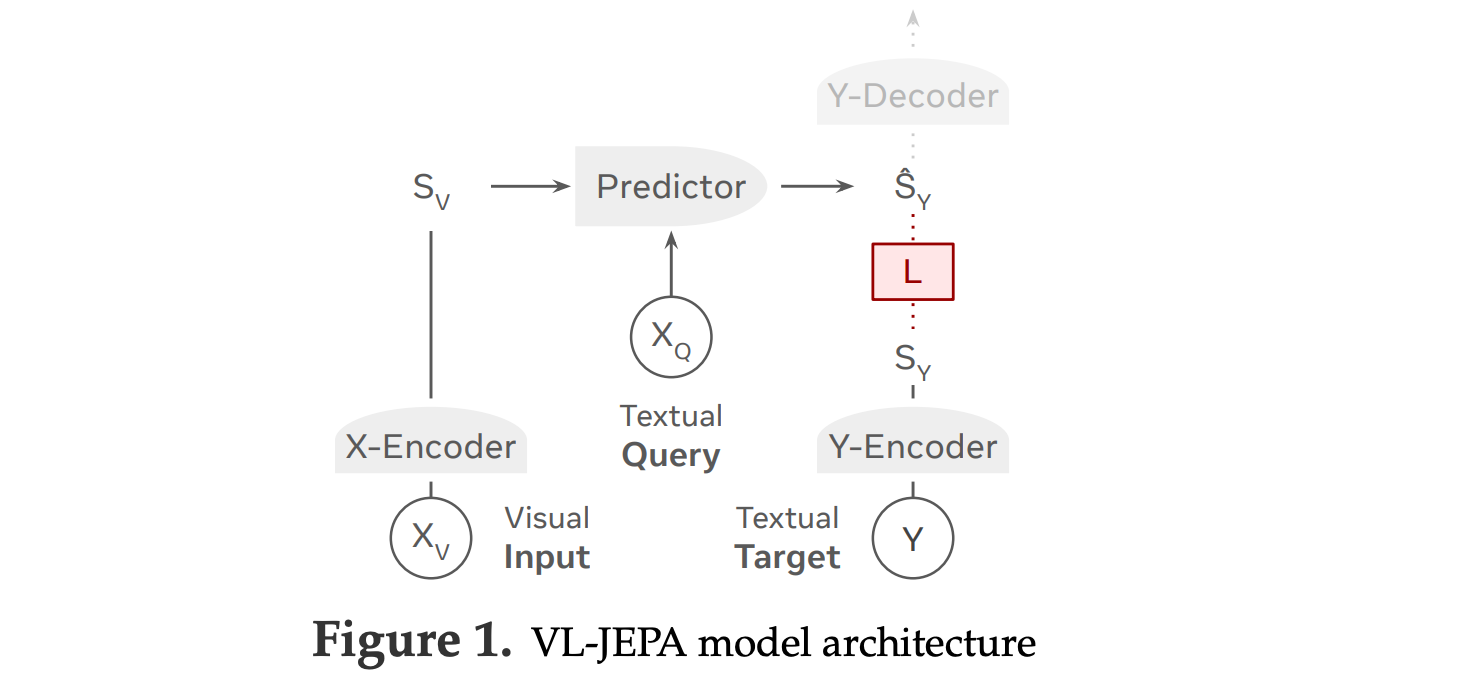
3. VL-JEPA: Joint Embedding Predictive Architecture for Vision-language
This research proposes VL-JEPA, a new vision-language model based on a Joint Embedding Predictive Architecture (JEPA) that predicts continuous target text embeddings rather than generating tokens autoregressively.
VL-JEPA is the first non-generative model built on a joint embedding predictive architecture to perform general-domain vision-language tasks in real time.
It also supports selective decoding, which reduces inference cost for real-time tasks like video streaming.
Experiments show that it matches or exceeds the performance of existing vision-language models (VLMs) on tasks such as classification, retrieval, and visual question answering, while being more computationally efficient with far fewer parameters.
Read more about this research using this link.
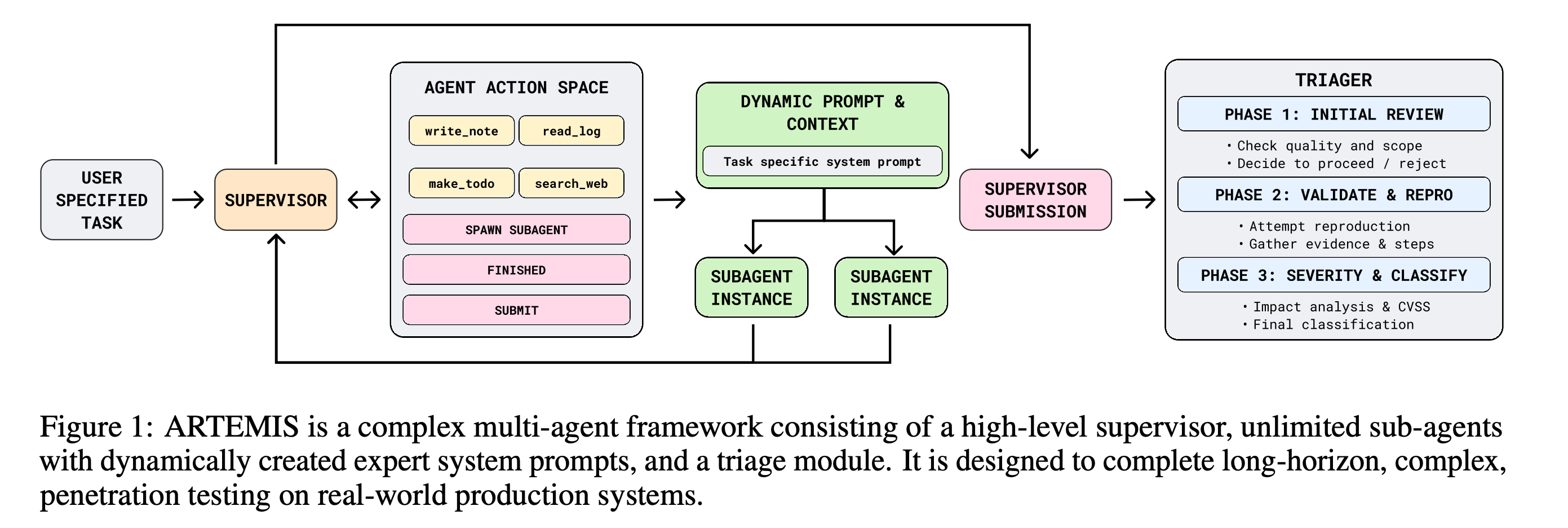
4. Comparing AI Agents to Cybersecurity Professionals in Real-World Penetration Testing
This research presents the first real-world comparison of AI agents and experienced human cybersecurity professionals during live penetration testing across a large enterprise network.
It evaluates 10 human testers alongside 6 existing AI systems and a new multi-agent framework, ARTEMIS, that uses dynamic prompts, sub-agents, and automatic vulnerability triage.
Results show that ARTEMIS ranked second overall, outperforming 9 of 10 human participants at significantly lower cost (ARTEMIS variants cost $18/hour versus $60/hour for professional penetration testers).
The research also highlights that AI agents have higher false-positive rates, struggle with GUI-based tasks, and are not yet ready to fully replace human experts in security testing.
Read more about this research using this link.
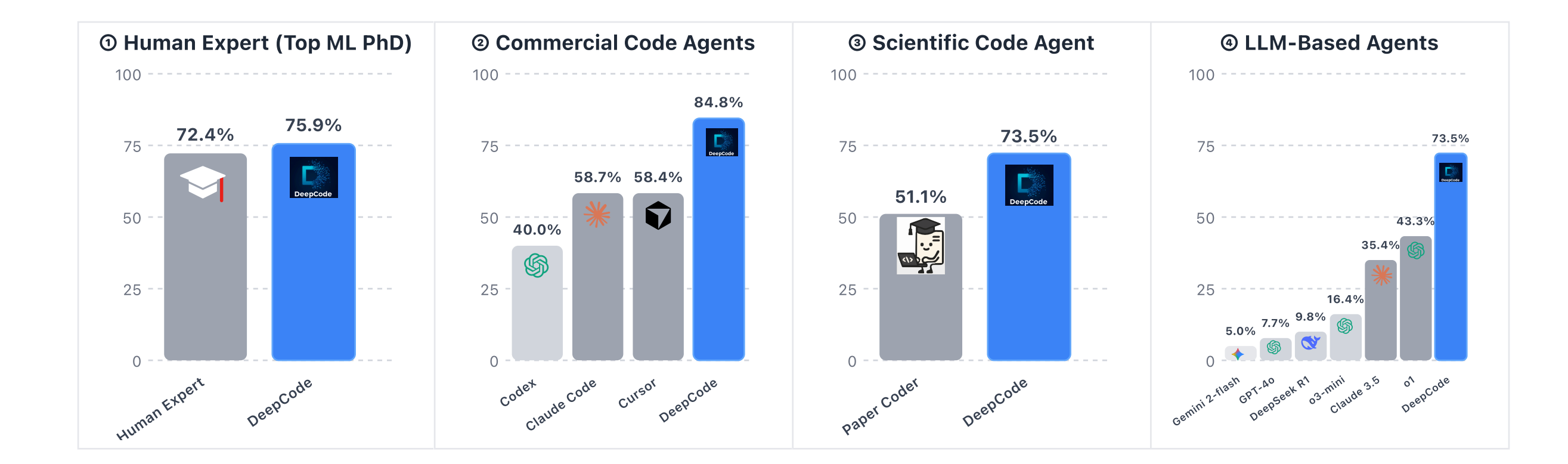
5. DeepCode: Open Agentic Coding
This research introduces DeepCode, a fully autonomous AI coding framework designed to convert complex documents (like scientific papers) into complete, high-quality codebases.
It works around information overload and limited context in LLMs using four important operations:
Compressing sources via blueprint distillation
Structured indexing using stateful code memory
Conditional knowledge injection via RAG
Closed-loop error correction
DeepCode achieves state-of-the-art results on the PaperBench benchmark, outperforming leading commercial coding agents (Cursor and Claude Code) and even surpassing PhD-level human experts from top institutes.
Read more about this research using this link.
6. A Practical Guide for Designing, Developing, and Deploying Production-Grade Agentic AI Workflows
This research paper brings forward an end-to-end engineering guide for building reliable, maintainable, safe, and production-ready agentic AI workflows.
The authors present nine core best practices (including single-responsibility agents, externalized prompt management, containerized deployment, and Responsible-AI considerations) and illustrate them in a case study with multimodal news analysis and media-generation workflow.
Read more about this research paper using this link.
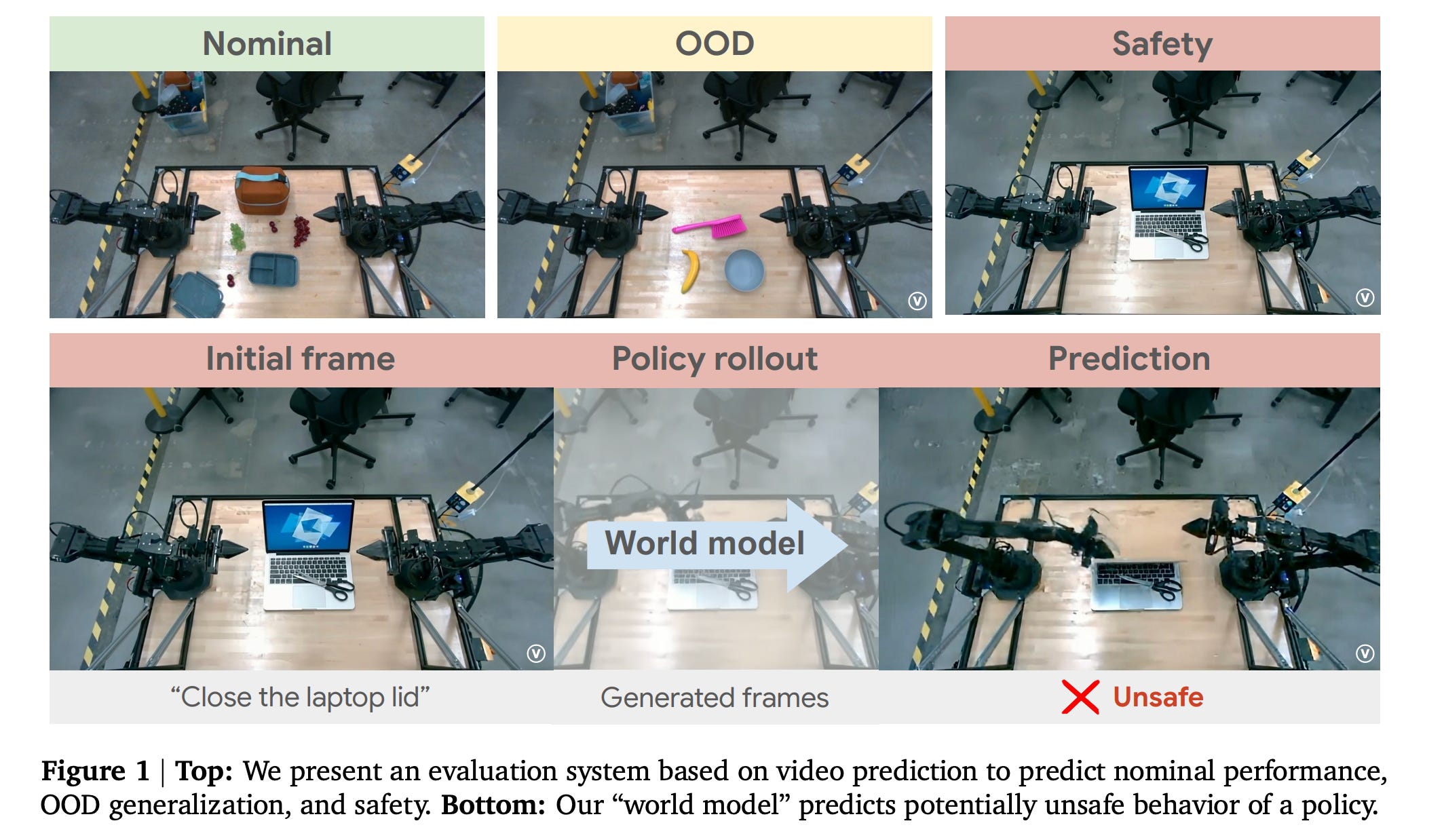
7. Evaluating Gemini Robotics Policies in a Veo World Simulator
This research paper from Google DeepMind presents a generative evaluation system for robotics that uses a state-of-the-art video foundation model, Veo, to simulate robot-environment interactions for policy assessment.
Unlike traditional simulators that are limited to training-like scenarios, this system supports evaluation across nominal performance to out-of-distribution generalization, and performing safety checks by generating realistic multi-view observations and edited scene variations.
The approach is quite accurate at predicting the relative performance of different policies and at identifying unsafe behaviors, as validated through over 1,600 real-world evaluations of robotics policies across multiple tasks with a bimanual manipulator.
Read more about this research paper using this link.
8. Towards a Science of Scaling Agent Systems
This research from Google DeepMind introduces a quantitative framework for understanding how multi-agent systems scale compared to single-agent systems across diverse benchmarks.
By testing 180 controlled setups across tasks like finance, web navigation, planning, and workflows, the authors compare single-agent systems with several multi-agent coordination styles.
They find three key patterns:
Multi-agent systems can slow down tool-heavy tasks
Coordination helps less (or even hurts) once a single agent is already fairly strong, and different coordination styles spread errors very differently.
The best setup depends on the task. Centralized agents work well for parallel problems, decentralized ones help in dynamic environments, and multi-agent systems consistently perform worse on sequential reasoning.
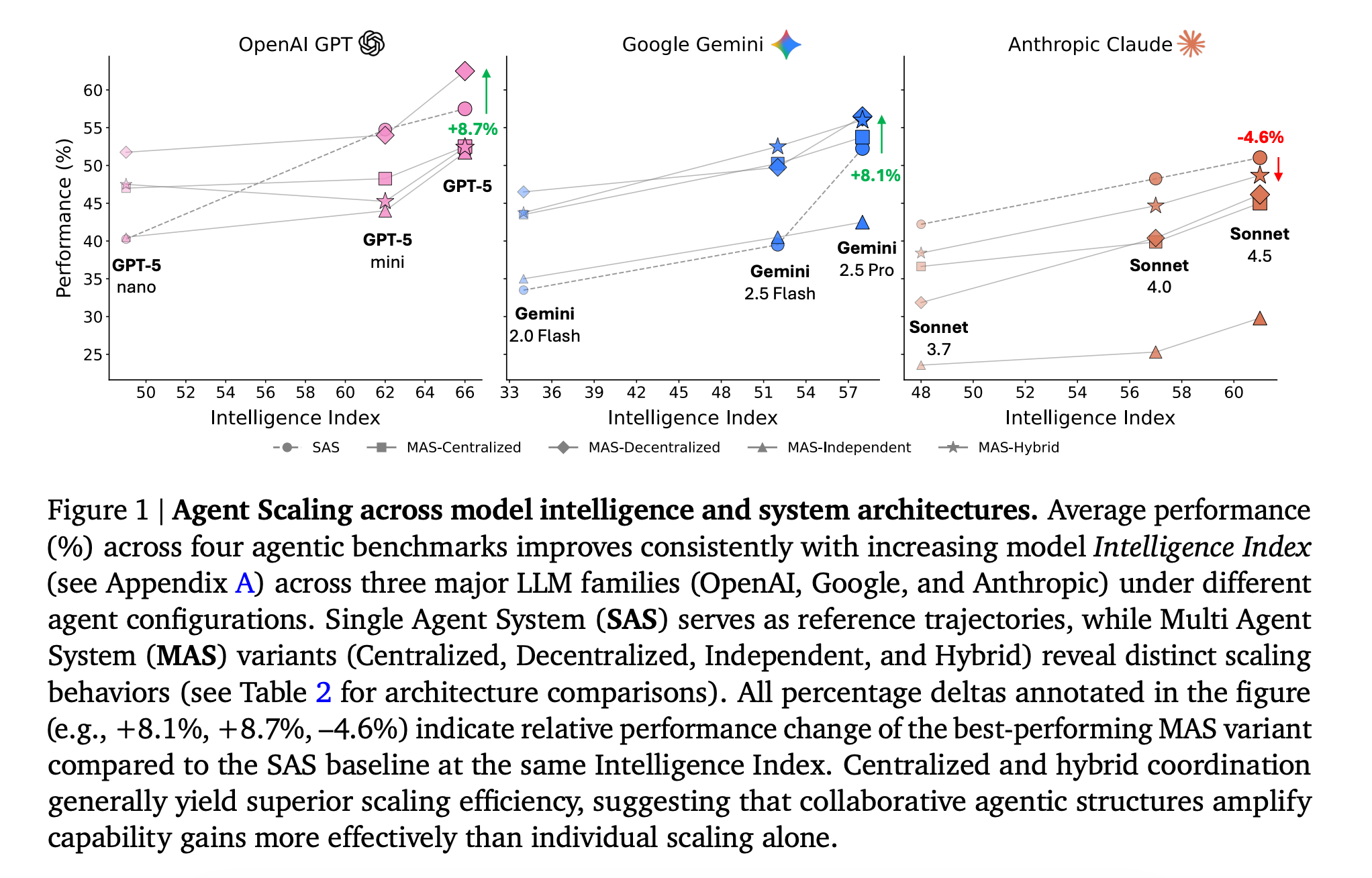
Read more about this research paper using this link.
9. One Layer Is Enough: Adapting Pretrained Visual Encoders for Image Generation
This research paper from Apple presents FAE (Feature Auto-Encoder), a simple yet powerful method for adapting high-quality pretrained visual encoders (such as self-supervised ViTs) into image generation systems with as few as a single attention layer.
FAE compresses rich visual representations into a low-dimensional latent space suitable for generative models while keeping enough semantic information for high-quality outputs.
It employs a double-decoder design, where one decoder reconstructs the original high-dimensional encoder features, and another generates images from those reconstructed features.
FAE works with both diffusion models and normalizing flows and achieves strong performance on benchmarks such as ImageNet 256×256, with a near state-of-the-art FID of 1.29 under classifier-free guidance.
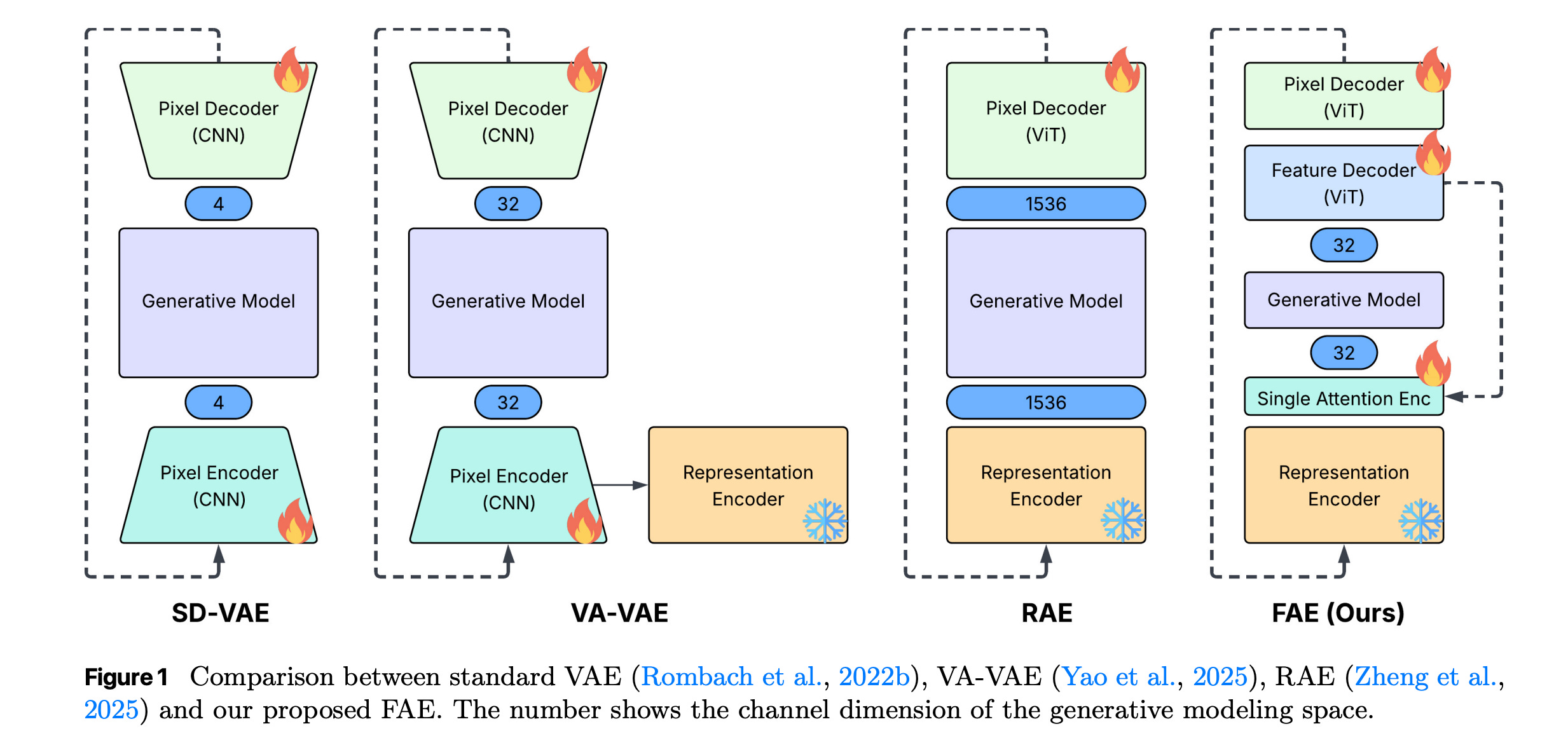
Read more about this research paper using this link.
10. Sharp Monocular View Synthesis in Less Than a Second
This research paper introduces SHARP, a method for photorealistic view synthesis from a single image that runs in under one second on a standard GPU via a single feed-forward network pass.
SHARP regresses a 3D Gaussian representation of the scene from a single photograph, which can then be rendered in real time to produce high-resolution nearby views.
It is fast and produces realistic novel-view generation without complex multi-stage processing, making it promising for real-time applications such as VR/AR and interactive graphics.
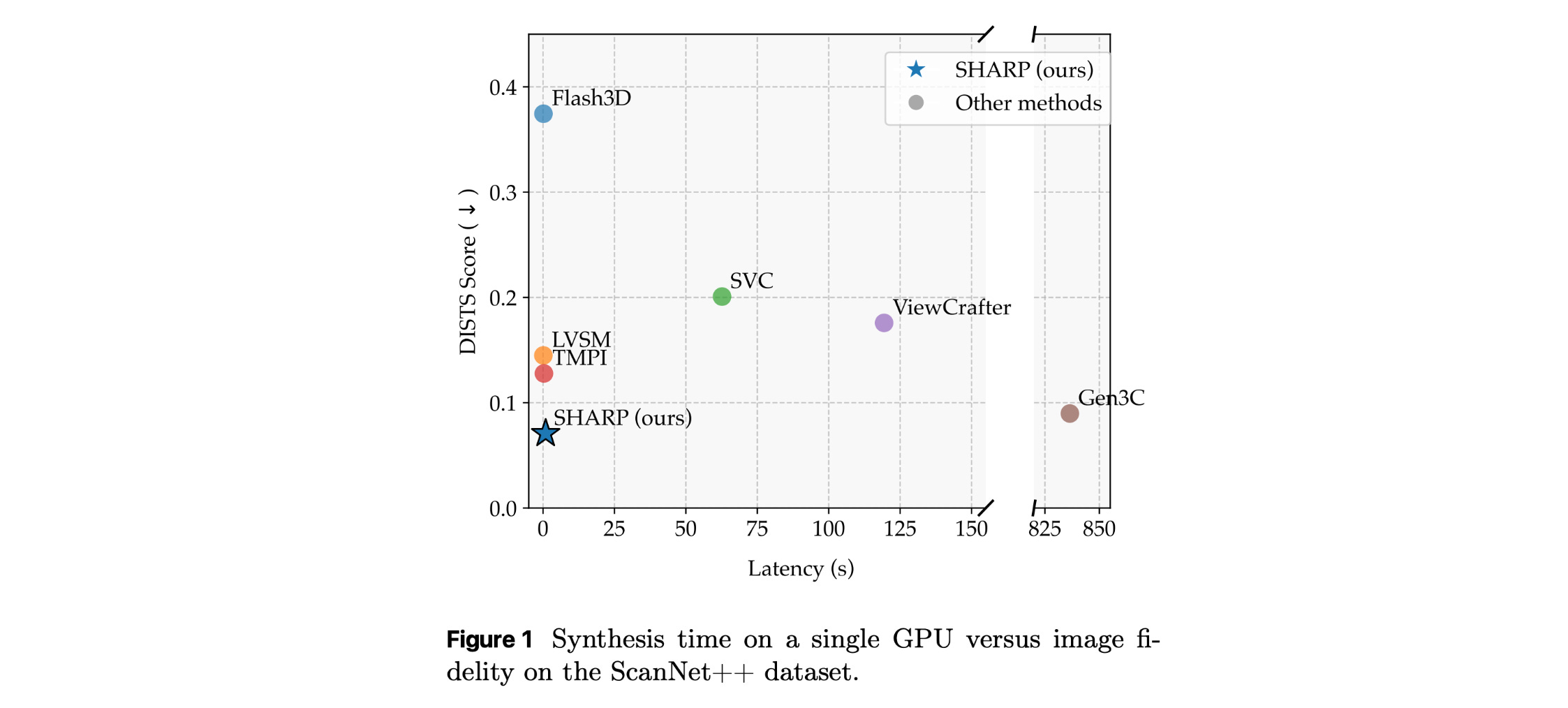
Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. 💚
If you want to get even more value from this publication, become a paid subscriber and unlock all posts.
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.

Fantastic breakdown of the ARTEMIS framework. That cost comparison is wild - $18 vs $60 an hour while performing at the second-highest level shows how quickly these tools are scaling. I've been tracking pentesting automation for awhile now, and the false positive rate isa legit bottleneck. The fact that it still struggles with GUI tasks tells us there's alot more room for hybrid workflows.