

🗓️ This Week In AI Research (8-14 February 26)
The top 11 AI research papers that you must know about this week.


Before we start, I want to introduce you to my book, LLMs In 100 Images, which is a collection of 100 easy-to-follow visuals that explain the most important concepts you need to master to understand LLMs today.
Grab your copy today at a 20% discount using this link.

1. GPT‑5.2 derives a new result in theoretical physics
OpenAI’s GPT‑5.2 helped develop a new theoretical physics result by proposing a simpler formula for a previously overlooked gluon scattering amplitude.
This configuration, once thought to be zero under standard assumptions, actually has a non-zero amplitude in a special kinematic regime.
The formula first proposed by GPT‑5.2 was later verified using another internal OpenAI model and by human researchers.
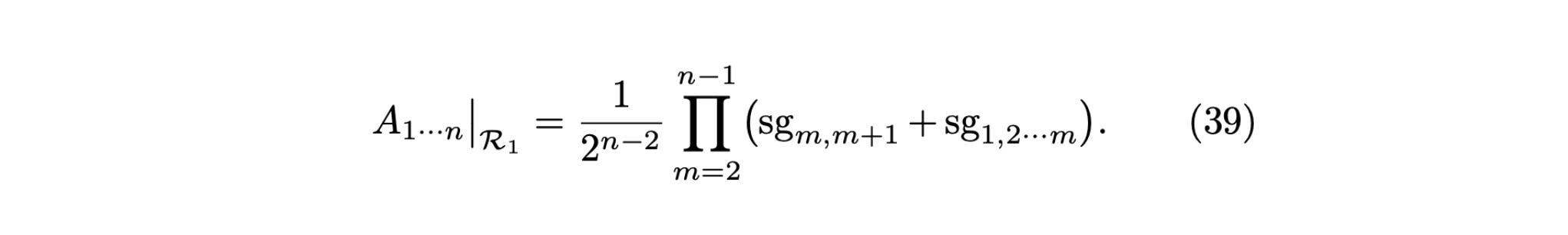
Read more about this achievement using this link.
Read the physics research paper using this link.
2. Towards Autonomous Mathematics Research
This research from Google DeepMind introduces Aletheia, a math research agent designed to move beyond Olympiad-style problem-solving into professional mathematics research, where the big challenges include navigating vast literature and constructing long-term proofs.
Aletheia can iteratively generate, verify, and revise complete solutions in natural language and uses:
An advanced version of Gemini Deep Think for hard reasoning
A new inference-time scaling law that extends beyond Olympiad-level problems
Intensive tool use to handle real mathematical research complexities
With these, Athelia has achieved three significant research milestones:
A fully AI-generated paper on calculating structure constants in arithmetic geometry, called ‘Eigenweights’.
A human-AI collaborative paper that proves bounds on systems of interacting particles called ‘independent sets’.
A semi-autonomous evaluation of 700 open problems in Bloom’s Erdős Conjectures database, which led to autonomous solutions for four open questions.

Read more about the research using this link.
3. The Devil Behind Moltbook
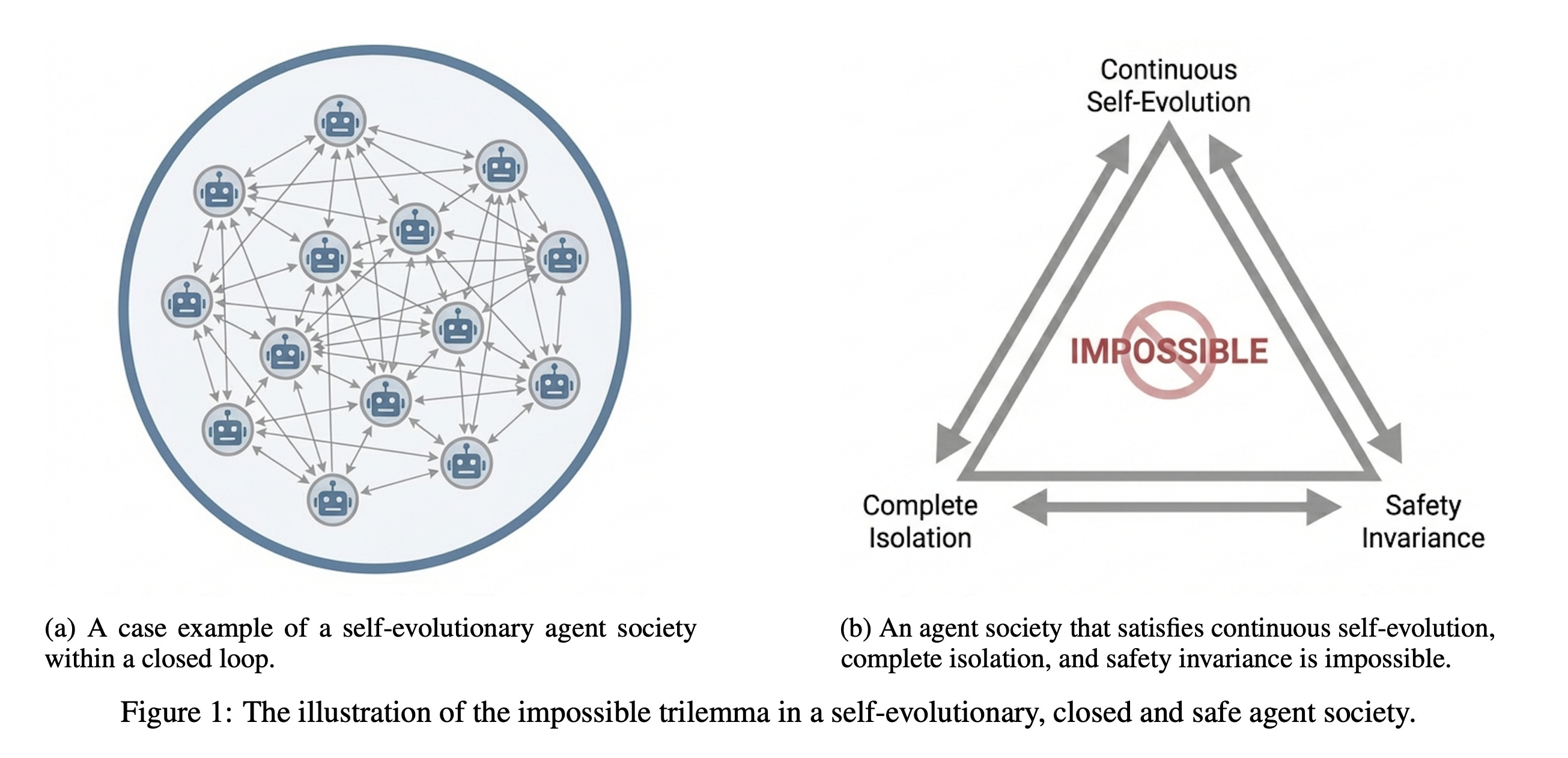
The research paper examines LLM-based self-evolving multi-agent AI systems and proves a key limitation in their ability to stay safely aligned while improving on their own.
The authors introduce the “Self-Evolution trilemma,” which states that an agent society cannot achieve continuous self-evolution, complete isolation, and consistent safety all at the same time.
Using an information-theoretic approach, they show that isolated self-evolution creates statistical blind spots that lead to irreversible safety lapses when compared to anthropic (human-like) value distributions.
Observations from the Moltbook agent community and other closed systems support this prediction.
The authors also claim that this loss of safety is inherent, not just a problem to fix, and stress the need for external oversight or new mechanisms to preserve safety and address these risks.
Read more about the research using this link.
4. SOTA ARC-AGI-2 Results with Agentica
The open-sourced Agentica framework by Symbolica combines code-mode agents and recursive language model (RLM) workflows using a persistent Python REPL environment.
This setup allows agents to propose, implement, test, and continuously refine programs to tackle ARC-AGI tasks more effectively than standard chain-of-thought prompting.
A significant innovation in their approach is Recursive delegation, in which agents dynamically create sub-agents to manage subtasks, allowing exploration in both depth and breadth.
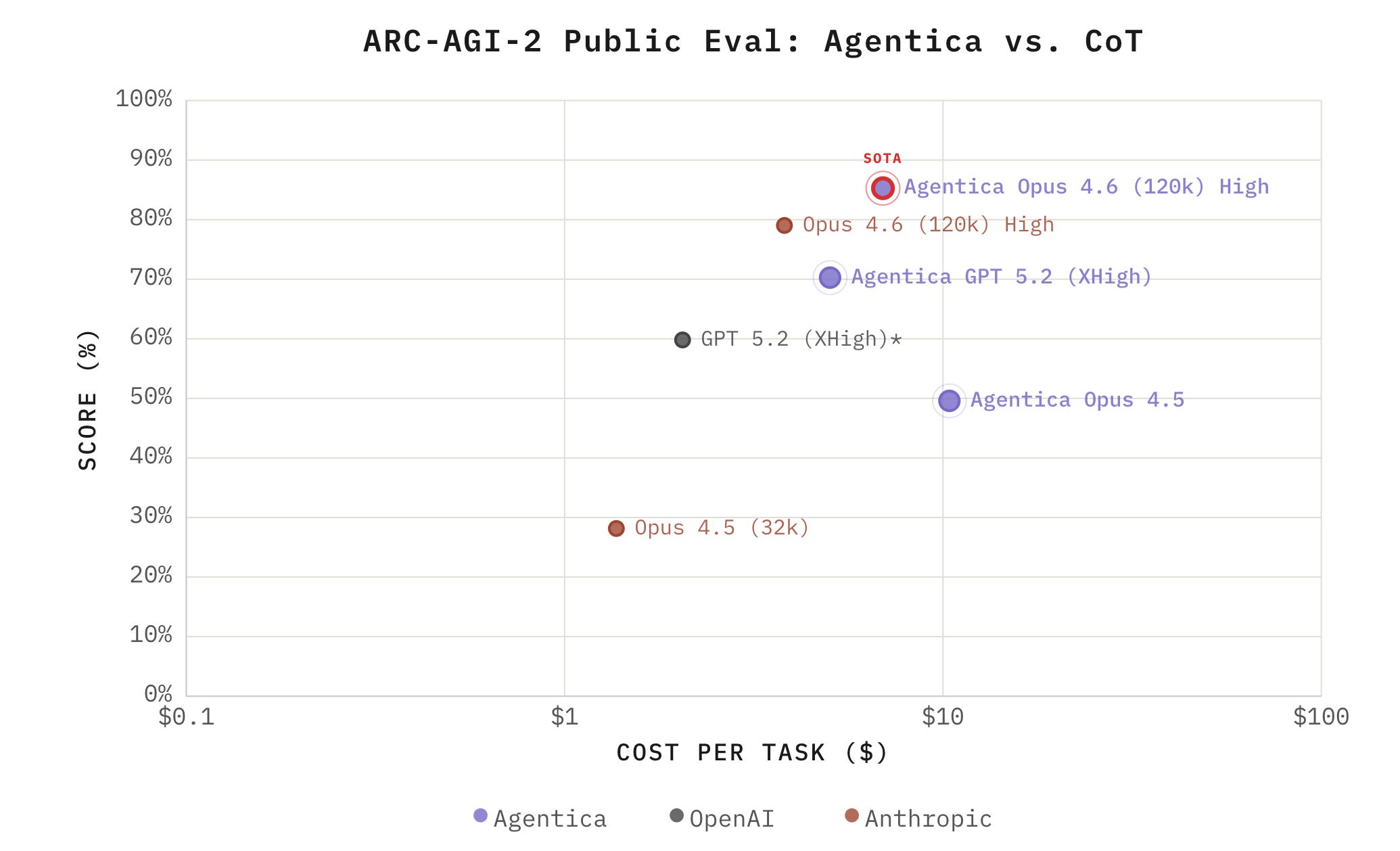
Experimental results show that Agentica agents significantly improve benchmark scores for models such as Opus 4.6, GPT-5.2, and Opus 4.5, with the highest score reaching 85.28% on the public ARC-AGI-2 set.
Read more about the research using this link.
The GitHub repository associated with Agentica can be found here.
5. AttentionRetriever
Existing RAG methods struggle with long document retrieval due to poor context-awareness, causal dependence, and scope issues.
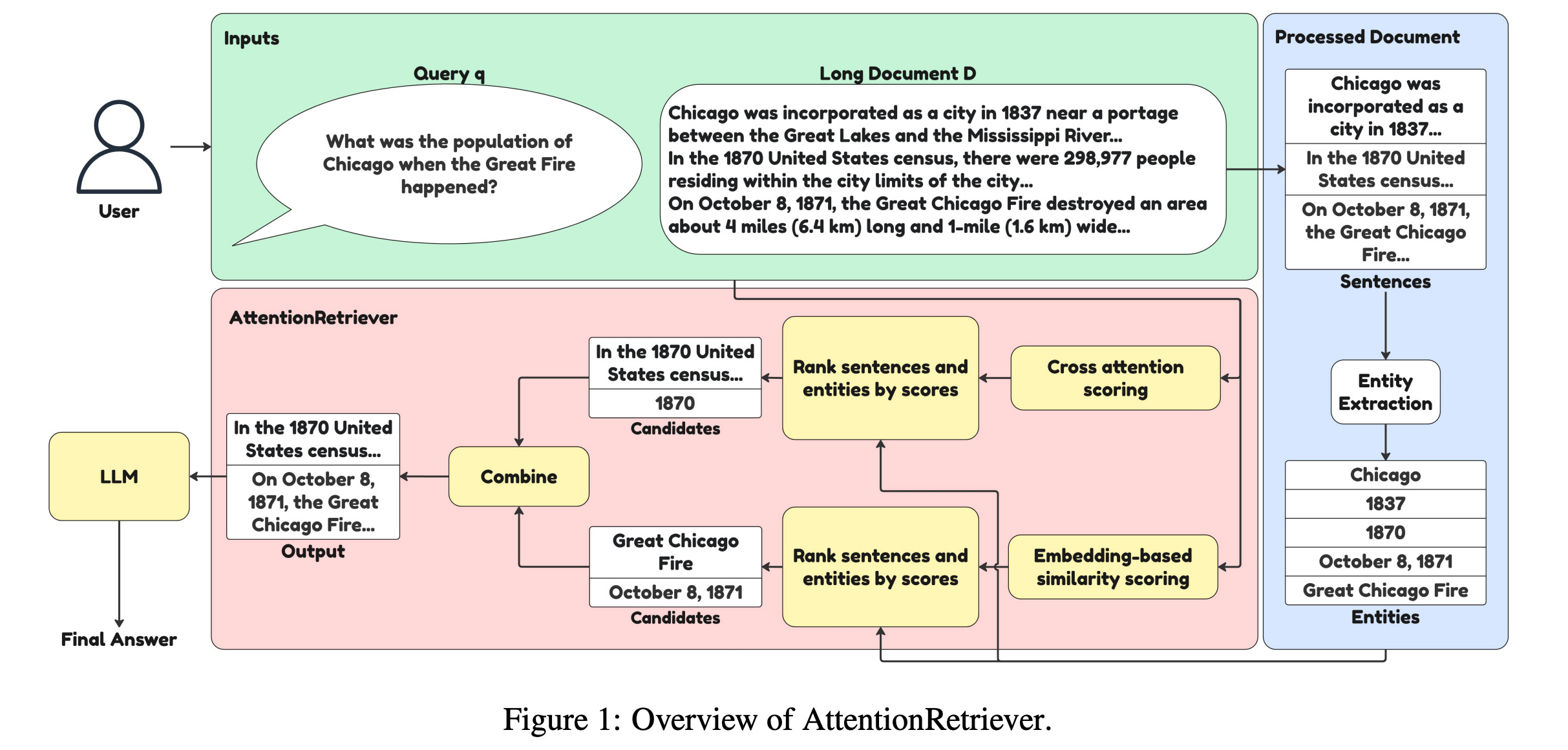
This research paper introduces AttentionRetriever, a new long-document retrieval model that shows that transformer attention layers can act as effective retrievers without any extra training.
This is achieved by using attention scores and entity-aware embeddings to capture context and scope in long texts.
Results show that AttentionRetriever can outperform previous models on long document retrieval benchmarks while being as efficient as standard dense retrievers.
Read more about the research using this link.
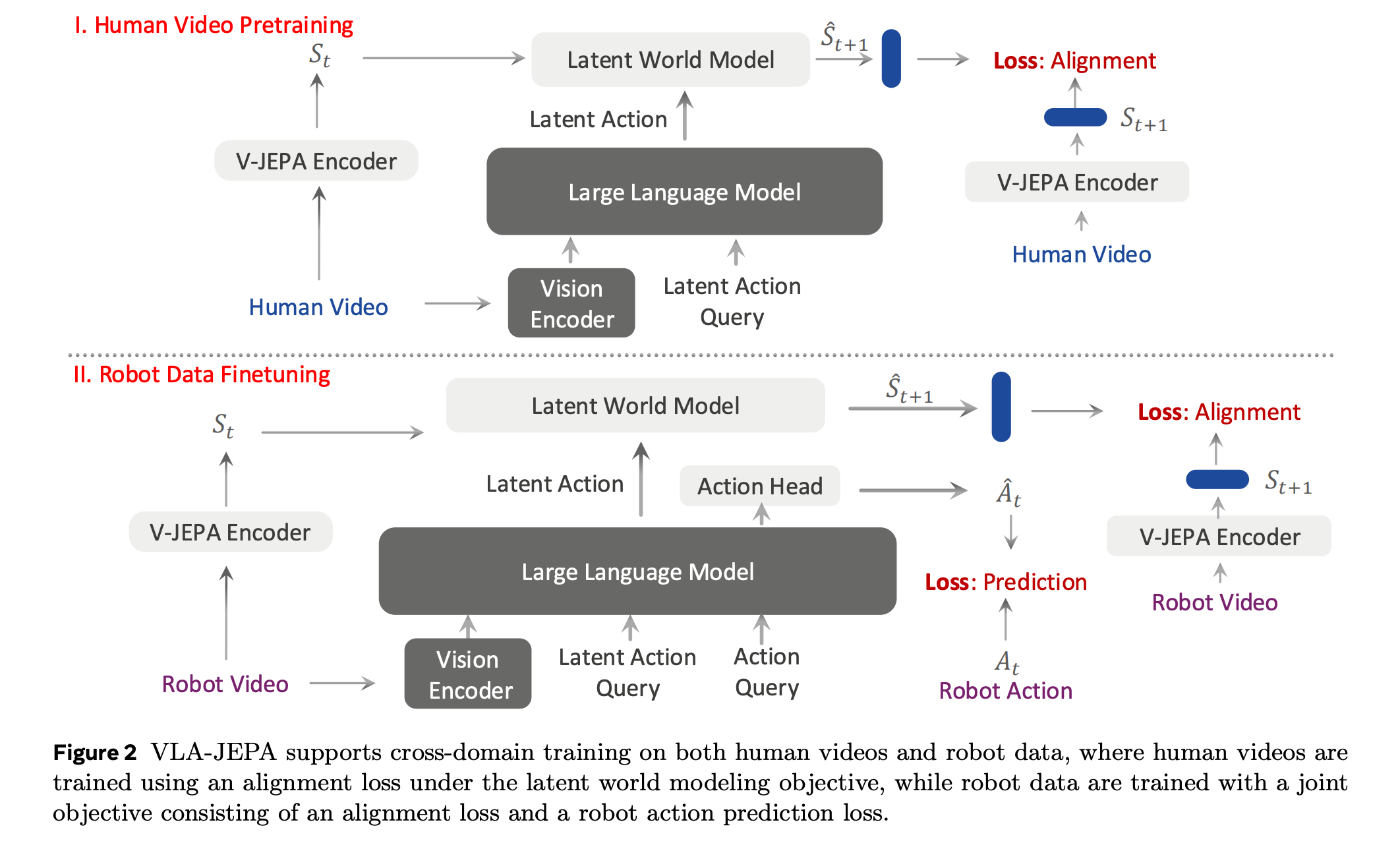
6. VLA-JEPA
This research paper presents VLA-JEPA, a new pretraining framework for vision-language-action (VLA) policies that improves how agents learn to act from large-scale video data.
It tackles a major issue in current latent-action objectives, which often learn irrelevant pixel changes, by using leakage-free state prediction in a latent world model where the target encoder generates latent representations from future frames, while the student pathway only sees the current observation. With such an approach, future information is used purely as a supervision target.
In contrast, by predicting in latent space rather than raw pixels, VLA-JEPA learns dynamic abstractions that are resistant to camera motion and background noise.
Experiments show that VLA-JEPA consistently improves generalization and robustness on benchmarks such as LIBERO, LIBERO-Plus, SimplerEnv, and real-world robot manipulation tasks, compared with existing methods.
Read more about the research using this link.
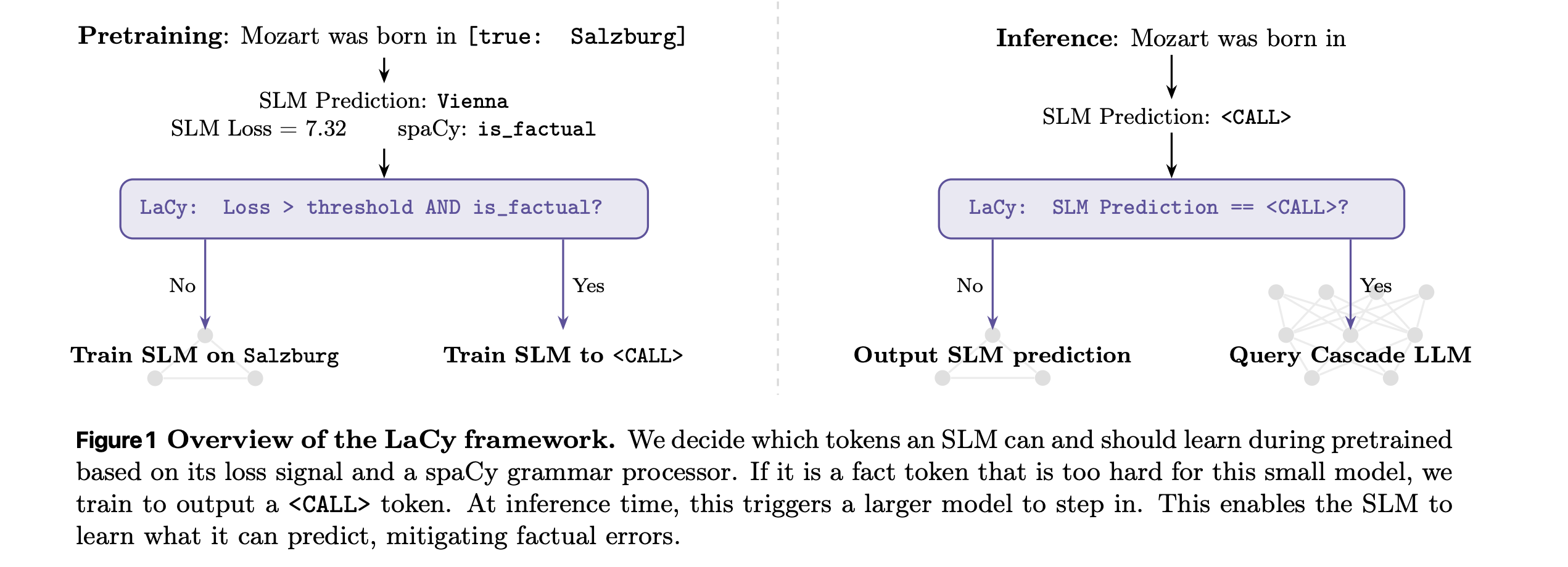
7. LaCy
Small language models (SLMs) have limited capacity to learn due to their small number of parameters. This often leads them to generate factually incorrect responses. To address this, SLMs are given access to external sources, such as larger models, documents, or databases, using a <CALL> mechanism.
This research paper from Apple explores which tokens an SLM can and should learn during pretraining, versus which ones it should delegate via the <CALL> mechanism.
Findings indicate that this choice goes beyond merely minimizing loss, and some high-loss tokens are actually reasonable alternative continuations of the training text and should be learned by the SLM instead of being delegated.
Based on this, the authors introduce LaCy, a new pretraining method that uses an augmented loss signal from the spaCy grammar parser to determine which tokens the SLM should learn to delegate to prevent factual errors and which are safe to learn and predict even under high losses.
Experiments indicate that LaCy improves factual accuracy, reflected by higher FactScores, when SLMs are combined with larger models. It also outperforms other strategies, such as Rho-trained or LLM-judge-trained SLMs, while being simpler and more cost-effective.
Read more about the research using this link.
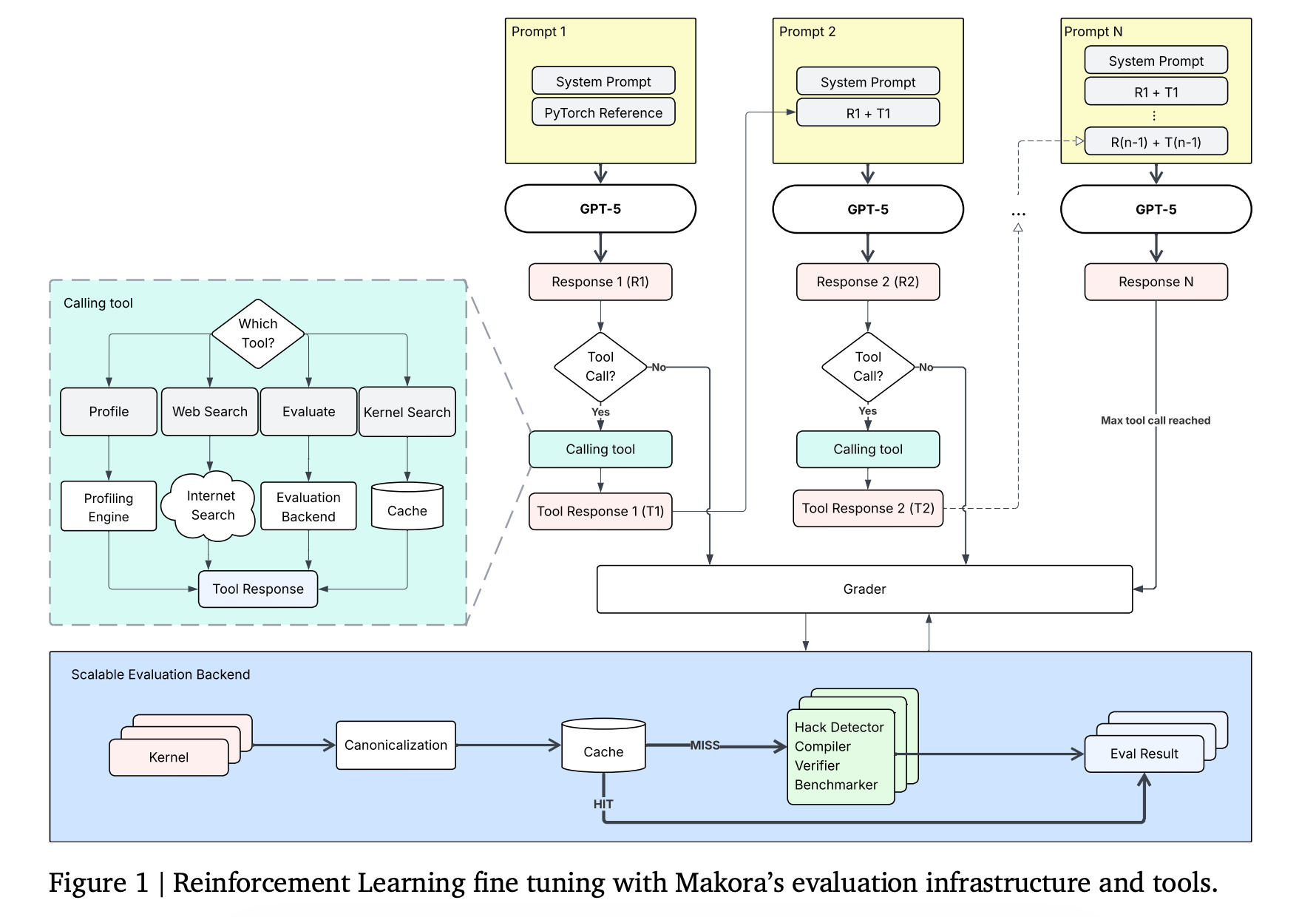
8. Fine-Tuning GPT-5 for GPU Kernel Generation
This research paper addresses the challenge of developing efficient GPU kernels essential to high-performance AI systems, which are difficult to write because of complex hardware architectures and limited high-quality training data.
The authors show that fine-tuning GPT-5 with RL in Makora’s environment significantly improves its ability to generate correct Triton GPU kernels.
In the single-attempt setting, the fine-tuned GPT-5 improves kernel correctness from 43.7% to 77.0% and increases the fraction of problems outperforming TorchInductor from 14.8% to 21.8% compared to the baseline model, while exceeding prior state-of-the-art models on KernelBench.
When integrated into a complete coding agent, the fine-tuned model successfully solves nearly all problems in the expanded KernelBench suite and outperforms the PyTorch TorchInductor compiler on 72.9% of problems with a geometric mean speedup of 2.12X.
Read more about the research using this link.
9. GPT‑5.3‑Codex‑Spark
OpenAI has launched GPT-5.3-Codex-Spark, a research preview of an ultra-fast, real-time coding model optimized for interactive development workflows.
Spark is a smaller and highly responsive version of GPT-5.3-Codex. It is designed to deliver nearly instant code generation and edits, producing over 1,000 tokens per second with a 128k context window. This enables developers to interrupt, redirect, and improve outputs in real time.
The model runs on Cerebras’ Wafer-Scale Engine 3 hardware, making it OpenAI’s first production deployment on non-NVIDIA chips to achieve ultra-low latency.
Read more about the research using this link.
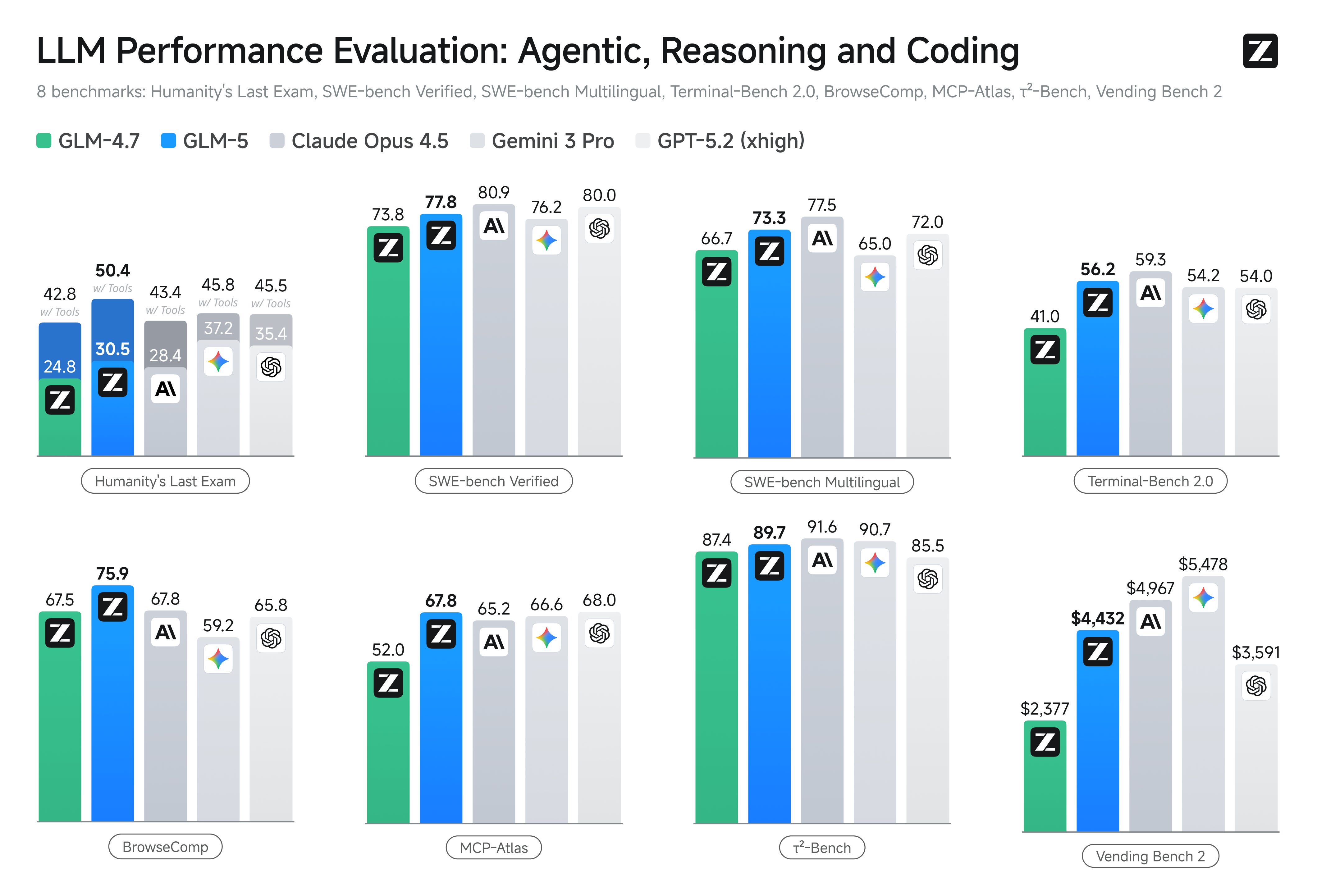
10. GLM-5
GLM-5 is Z.ai’s new flagship foundation model, built for complex systems engineering and long-horizon agentic tasks.
The model uses a Mixture-of-Experts (MoE) architecture with 744B parameters (40B active) and achieves excellent performance amongst open-source models in reasoning, coding, and agent execution.
Its capabilities are competitive with top proprietary models such as Anthropic’s Claude Opus series and OpenAI’s GPT-5.
Read more about the research using this link.
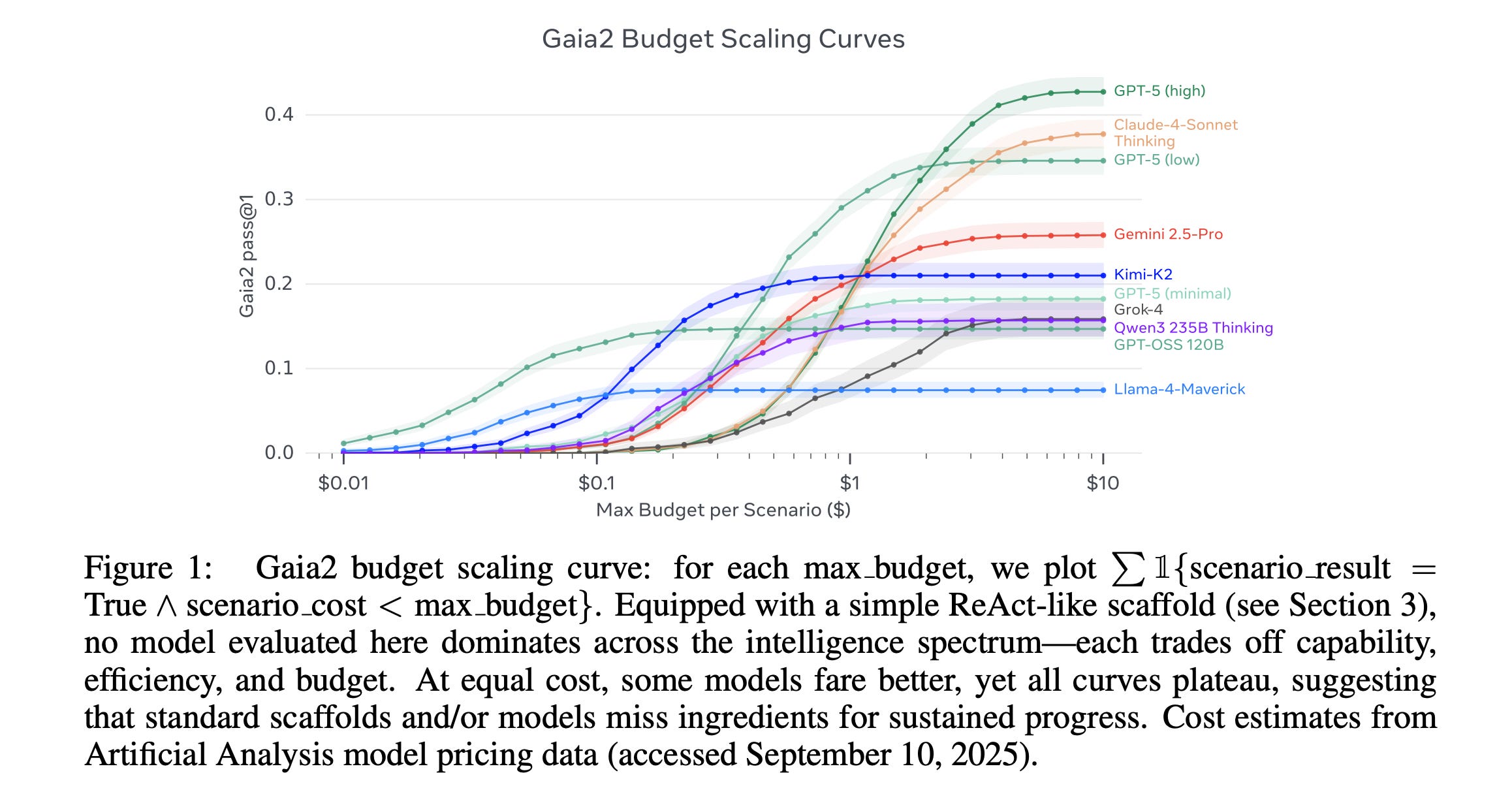
11. Gaia2
This research paper from Meta SuperIntelligence Labs introduces Gaia2, a new benchmark suite that evaluates LLM-based agents in realistic, dynamic, and asynchronous environments in which the world changes independently of the agent’s actions (unlike previous static or synchronized benchmarks).
Gaia2 tests agents on time constraints, noisy, evolving events, ambiguity resolution, and multi-agent collaboration, using a write-action verifier that supports action-level evaluation and reinforcement learning from verifiable rewards.
Initial evaluations on the benchmark show that no model performs well in all tasks. Proprietary models like GPT-5 (high) achieve the highest overall scores but struggle with tasks that are time-sensitive.
Other models vary in speed, cost, and reliability, revealing important trade-offs in reasoning, efficiency, and adaptability to real-world situations.
Gaia2 is built on a consumer environment with the open-source Agents Research Environments platform to support the development, benchmarking, and training of next-generation practical AI agent systems.
Read more about the research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
