

Build Causal Multi-Head Self-Attention From Scratch
#6: AI/ ML Engineering Interview Essentials: Causal Multi-head Self-Attention

We built Self-attention and Multi-head Self-attention from scratch in the previous lessons in this series on AI/ ML Engineering interview essentials.


Here’s the next step we take from there and build the Causal Multi-Head Self-Attention.
Let’s begin!
What Is Causal Multi-Head Self-Attention?
Causal (or Masked) Multi-Head Self-Attention is used in GPT-like (decoder-only) LLMs for generating text.
We previously learned that:
Self-attention is a mechanism lets each position in an input sequence attend to all other positions in the same sequence to learn relationships between them.
Multi-head attention (MHA) extends self-attention by using multiple parallel self-attention blocks, or heads, rather than just one. This helps it to better learn different types of semantic relationships within the input sequence.
GPT-like LLMs generate tokens autoregressively.

During training for autoregressive generation, given a training input sequence, the model shouldn’t peek at future tokens it hasn’t generated yet.
You’d ask why?
Consider the sentence: “He is playing football”
During training to generate the word “playing”, the model can learn to predict it from both past words (“He” and “is”) and future words (“football”).
This isn’t what we want because this means the model is learning to cheat during text generation by looking ahead.
At test time (during inference/text generation), since the model has no access to future tokens (since it hasn’t generated them yet), it can’t use the cheating strategy it has learned, leading it to fail poorly.
Therefore, we need to train the model to mimic the actual generation process, where tokens are produced sequentially without knowledge of the future.
When training to generate the sentence “He is playing football”:
At “He”, the model should only see “He”
At “is”, the model should only see “he” and “is”
At “playing”, the model should only see “he”, “is”, and “playing”
At “football”, the model should see all previous words
This is made possible using the Causal or Masked Multi-Head Self-Attention, where each position in the input sequence can attend only to previous positions and itself, not to future positions. In other words, the future positions are “masked”.
Revisiting Multi-head Attention
Let’s go back to what we had built in the previous lesson on Multi-head Self-attention.
import torch.nn as nn
import math
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, “embedding_dim must be divisible by num_heads”
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Linear projections for Q, K, V (to be split later for each head)
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_k = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_v = nn.Linear(embedding_dim, embedding_dim, bias = False)
# Linear projection to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias = False)
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1,2)
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1,2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# Split them into multiple heads
Q = self._split_heads(Q)
K = self._split_heads(K)
V = self._split_heads(V)
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
# Scale and apply softmax to get attention weights
attn_scores = attn_scores / math.sqrt(self.head_dim)
attn_weights = torch.softmax(attn_scores, dim = -1)
# Multiply attention weights by values (V)
weighted_values = attn_weights @ V
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Final output
output = self.W_o(merged_heads_output)
return outputThis class called MultiHeadSelfAttention does the following:
Projects input into Query (Q), Key (K), Value (V) representations
Splits Q, K, V across multiple parallel attention heads
Each head independently computes attention scores
Each head uses those scores to create weighted combinations of its values
Merges all head outputs back together and projects to the final output
Extending To Causal Multi-head Attention
To convert Multi-Head Self-Attention (MHA) to Causal Multi-Head Self-Attention, we use a triangular mask on the attention scores to prevent the model from attending to future positions during text generation.
The mask is created using the torch.tril method, which generates a lower triangular matrix with 1s on and below the diagonal, and 0s above.
The positions with 0s (above the diagonal) represent future positions that should be masked out.
This mask is applied using masked_fill method to set all future positions (where mask == 0) to -inf in the attention scores.
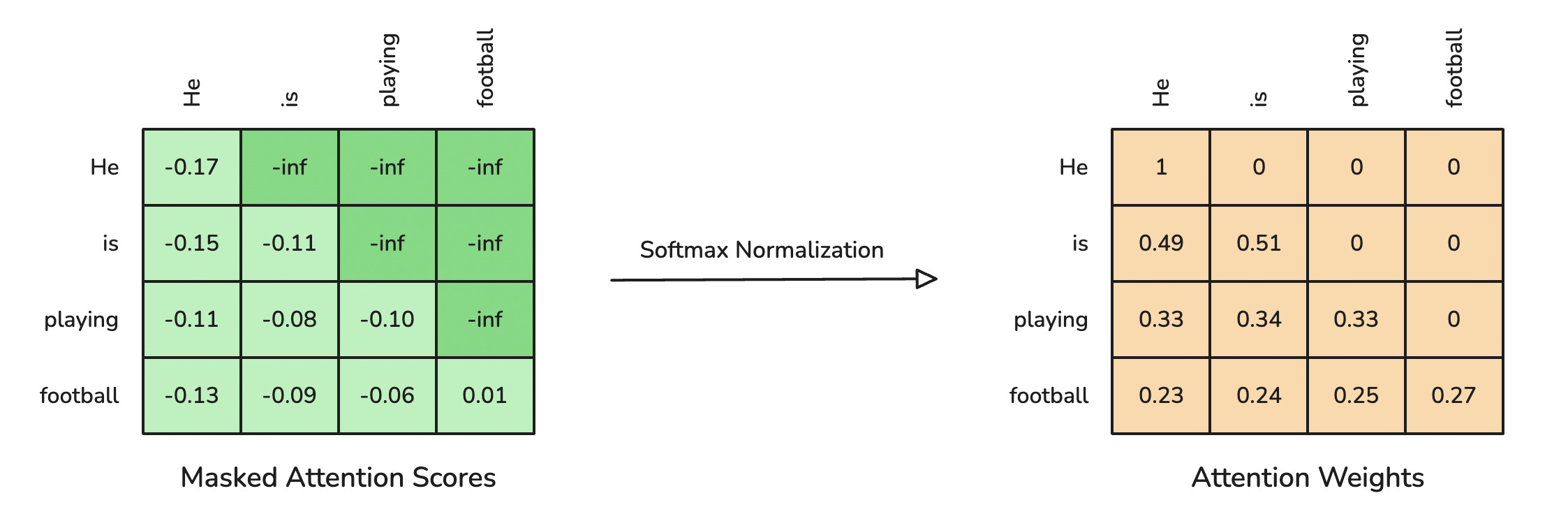
Softmax normalization finally converts -inf values to 0. This means setting the attention weights for future tokens to 0.
We implement these changes in the forward method of the CausalMultiHeadSelfAttention class.
We also add print statements to visualise the causal mask and the attention scores before and after applying the causal mask and softmax.
import torch
import torch.nn as nn
import math
class CausalMultiHeadSelfAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, “embedding_dim must be divisible by num_heads”
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Linear projections for Q, K, V (to be split later for each head)
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_k = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_v = nn.Linear(embedding_dim, embedding_dim, bias = False)
# Linear projection to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias = False)
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1,2)
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1,2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# Split them into multiple heads
Q = self._split_heads(Q)
K = self._split_heads(K)
V = self._split_heads(V)
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
# Scale
attn_scores = attn_scores / math.sqrt(self.head_dim)
print(”Attention scores before applying causal mask:\n\n”, attn_scores)
# Apply causal mask (prevent attending to future positions)
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device)) # Create lower triangular matrix
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length) # Add batch and head dimensions
print(”Causal mask:\n”, causal_mask)
attn_scores = attn_scores.masked_fill(causal_mask == 0, float(’-inf’)) # Mask out future positions by setting their scores to -inf
print(”Attention scores after applying causal mask:\n\n”, attn_scores)
# Apply softmax to get attention weights
attn_weights = torch.softmax(attn_scores, dim = -1)
print(”Attention weights after applying causal mask and softmax to Attention scores:\n\n”, attn_weights)
# Multiply attention weights by values (V)
weighted_values = attn_weights @ V
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Final output
output = self.W_o(merged_heads_output)
return outputLet’s use this to process input embeddings.
# Input embeddings
batch_size = 1
sequence_length = 4
embedding_dim = 6
# Create embeddings for a batch
input_embeddings = torch.rand(batch_size, sequence_length, embedding_dim)
# Set number of heads
NUM_HEADS = 3
# Initialize Causal Multi-Head Self-Attention
causal_mha = CausalMultiHeadSelfAttention(embedding_dim, num_heads = NUM_HEADS)
# Forward pass
output = causal_mha(input_embeddings)Here is what happens internally.
Attention scores before applying causal mask:
tensor([[[[-0.1709, -0.1238, -0.1097, -0.0160],
[-0.1504, -0.1112, -0.1206, -0.0366],
[-0.1133, -0.0847, -0.1012, -0.0372],
[-0.1338, -0.0944, -0.0571, 0.0144]],
[[-0.0170, -0.0124, -0.0392, -0.0688],
[-0.0305, -0.0193, -0.0666, -0.1194],
[-0.0227, -0.0931, -0.1484, -0.1973],
[-0.0014, -0.0808, -0.1032, -0.1154]],
[[-0.0072, -0.0091, -0.0876, -0.0579],
[ 0.0098, 0.0076, -0.1004, -0.0587],
[ 0.0720, 0.0711, -0.0327, 0.0100],
[ 0.1081, 0.1082, 0.0168, 0.0563]]]], grad_fn=<DivBackward0>)
Causal mask:
tensor([[[[1., 0., 0., 0.],
[1., 1., 0., 0.],
[1., 1., 1., 0.],
[1., 1., 1., 1.]]]])Attention scores after applying causal mask:
tensor([[[[-0.1709, -inf, -inf, -inf],
[-0.1504, -0.1112, -inf, -inf],
[-0.1133, -0.0847, -0.1012, -inf],
[-0.1338, -0.0944, -0.0571, 0.0144]],
[[-0.0170, -inf, -inf, -inf],
[-0.0305, -0.0193, -inf, -inf],
[-0.0227, -0.0931, -0.1484, -inf],
[-0.0014, -0.0808, -0.1032, -0.1154]],
[[-0.0072, -inf, -inf, -inf],
[ 0.0098, 0.0076, -inf, -inf],
[ 0.0720, 0.0711, -0.0327, -inf],
[ 0.1081, 0.1082, 0.0168, 0.0563]]]],
grad_fn=<MaskedFillBackward0>)Attention weights after applying causal mask and softmax to Attention scores:
tensor([[[[1.0000, 0.0000, 0.0000, 0.0000],
[0.4902, 0.5098, 0.0000, 0.0000],
[0.3288, 0.3384, 0.3328, 0.0000],
[0.2337, 0.2431, 0.2523, 0.2710]],
[[1.0000, 0.0000, 0.0000, 0.0000],
[0.4972, 0.5028, 0.0000, 0.0000],
[0.3554, 0.3312, 0.3134, 0.0000],
[0.2689, 0.2484, 0.2429, 0.2399]],
[[1.0000, 0.0000, 0.0000, 0.0000],
[0.5006, 0.4994, 0.0000, 0.0000],
[0.3449, 0.3446, 0.3106, 0.0000],
[0.2589, 0.2589, 0.2363, 0.2458]]]], grad_fn=<SoftmaxBackward0>)Visual Representation Of Operations
In causal multi-head self-attention, each head independently performs these three steps using its own attention score matrix, with the same causal mask applied across all heads.
Step 1
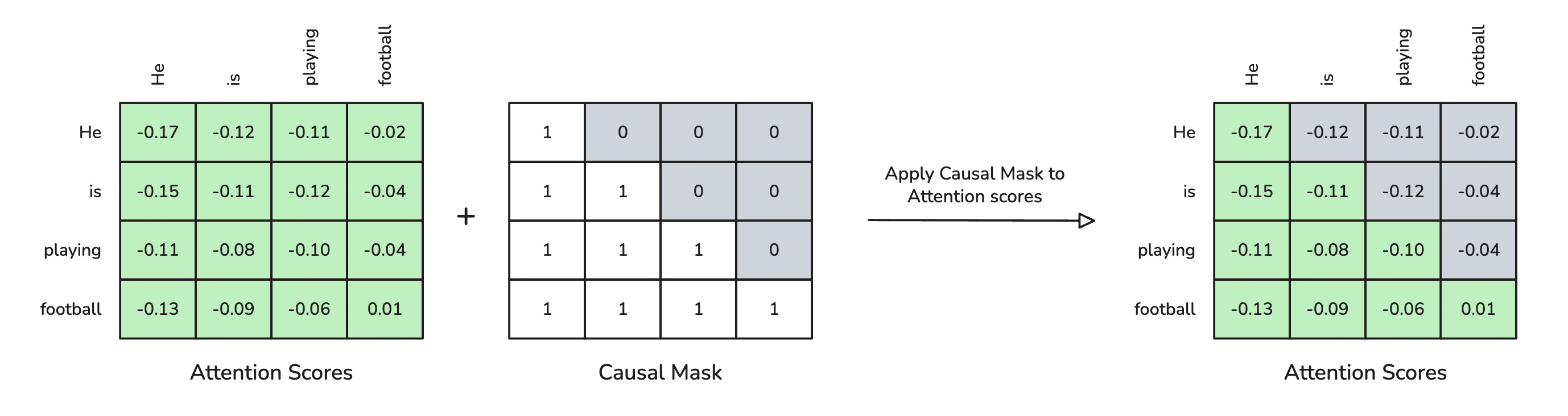
Step 2
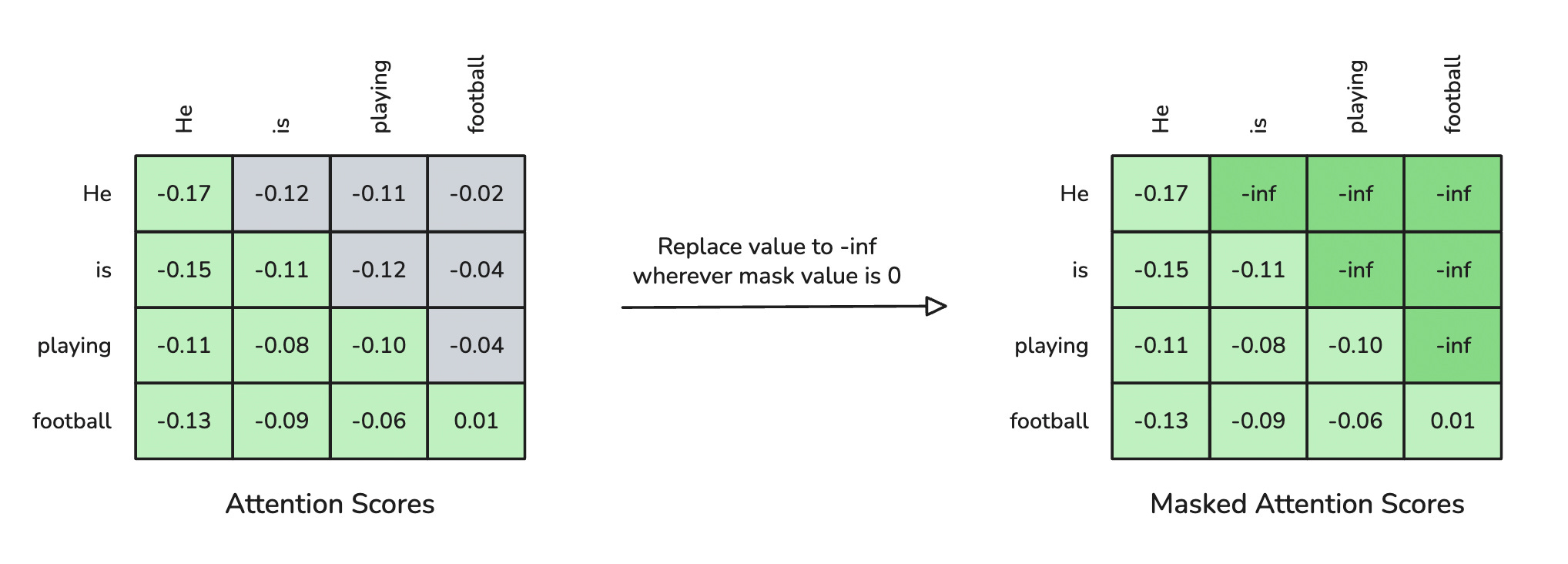
Step 3
Causal Multi-Head Self-Attention also preserves the shape of the input ([batch_size, sequence_length, embedding_dim]). This lets us stack it multiple times together in a Transformer block.
print("Input shape:", input_embeddings.shape)
print("Output shape:", output.shape)
"""
Input shape: torch.Size([1, 4, 6])
Output shape: torch.Size([1, 4, 6])
"""That’s everything for this article. Thanks for reading it!
It is entirely free to read. If you loved reading it, restack and share it with others.
You can read the other articles in this series using the links below.
Building Self-Attention From Scratch: https://intoai.pub/self-attention
What Is Normalization?: https://intoai.pub/normalization
What is Gradient Descent?: https://intoai.pub/p/gradient-descent
K-Nearest Neighbours (KNN): https://intoai.pub/p/knn
Building Multi-Head Self-Attention: https://www.intoai.pub/p/mha
If you want to get even more value from this publication, consider becoming a paid subscriber.
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.

Hey, great read as always, it’s fascinating how you break this down, but I was wondering if you could elabroate a bit on the actual masking implementation that stopps the model from “peeking” at future tokens, as that always strikes me as the clever bit.