

🗓️ This Week In AI Research (1-7 February 26)
The top 10 AI research papers that you must know about this week.


Before we begin, I have an exciting offer for you that is only valid for the next 24 hours!
Grab a flat 50% discount on the annual membership of Into AI today.
👉 Upgrade here, lock in the discount, and use ‘Into AI’ as your unfair advantage:
1. GPT-5.3-Codex
OpenAI launched GPT-5.3-Codex, its most powerful agentic coding model to date.
The model combines the coding performance of GPT-5.2-Codex with the reasoning and professional knowledge of GPT-5.2 in one system. It runs about 25% faster than the previous version and excels in industry benchmarks, such as SWE-Bench Pro and Terminal-Bench.
It can handle long, multi-step tasks that involve research, tool use, debugging, deployment, and complex execution.
And unlike the earlier versions, GPT-5.3-Codex not only writes and reviews code but also acts as an interactive collaborator throughout the software lifecycle and other knowledge work.
One of the most interesting aspects is that the Codex team used early versions of GPT-5.3-Codex to debug its own training, manage its own deployment, and analyze test results and evaluations, making it the first OpenAI model to help create itself.
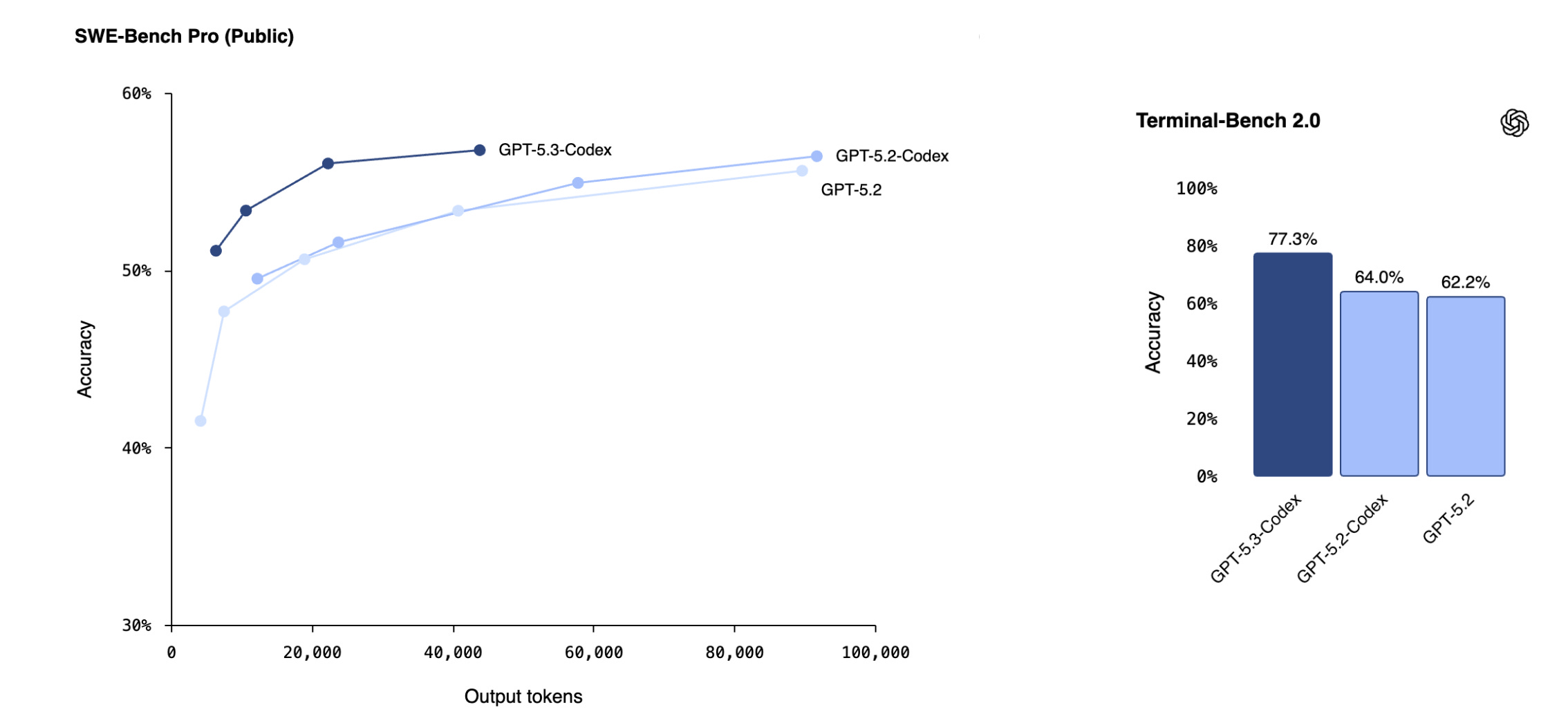
Read more about this research using this link.
2. Claude Opus 4.6
Anthropic has released Claude Opus 4.6, its most capable model to date.
Opus 4.6 performs exceptionally well in coding, planning, and long-term tasks, and is more reliable with large codebases and complex workflows, with a stronger ability to find and fix its own mistakes.
Additionally, it introduces a 1-million-token context window (in beta), which improves its understanding of longer contexts.
On benchmarks, Opus 4.6:
Scores 2nd on Terminal-Bench 2.0 for agentic coding, only next to GPT-5.3-Codex
Tops Humanity’s Last Exam for complex reasoning
Performs best on GDPval-AA for economically valuable knowledge work
Ranks highest on BrowseComp for finding hard-to-locate information online
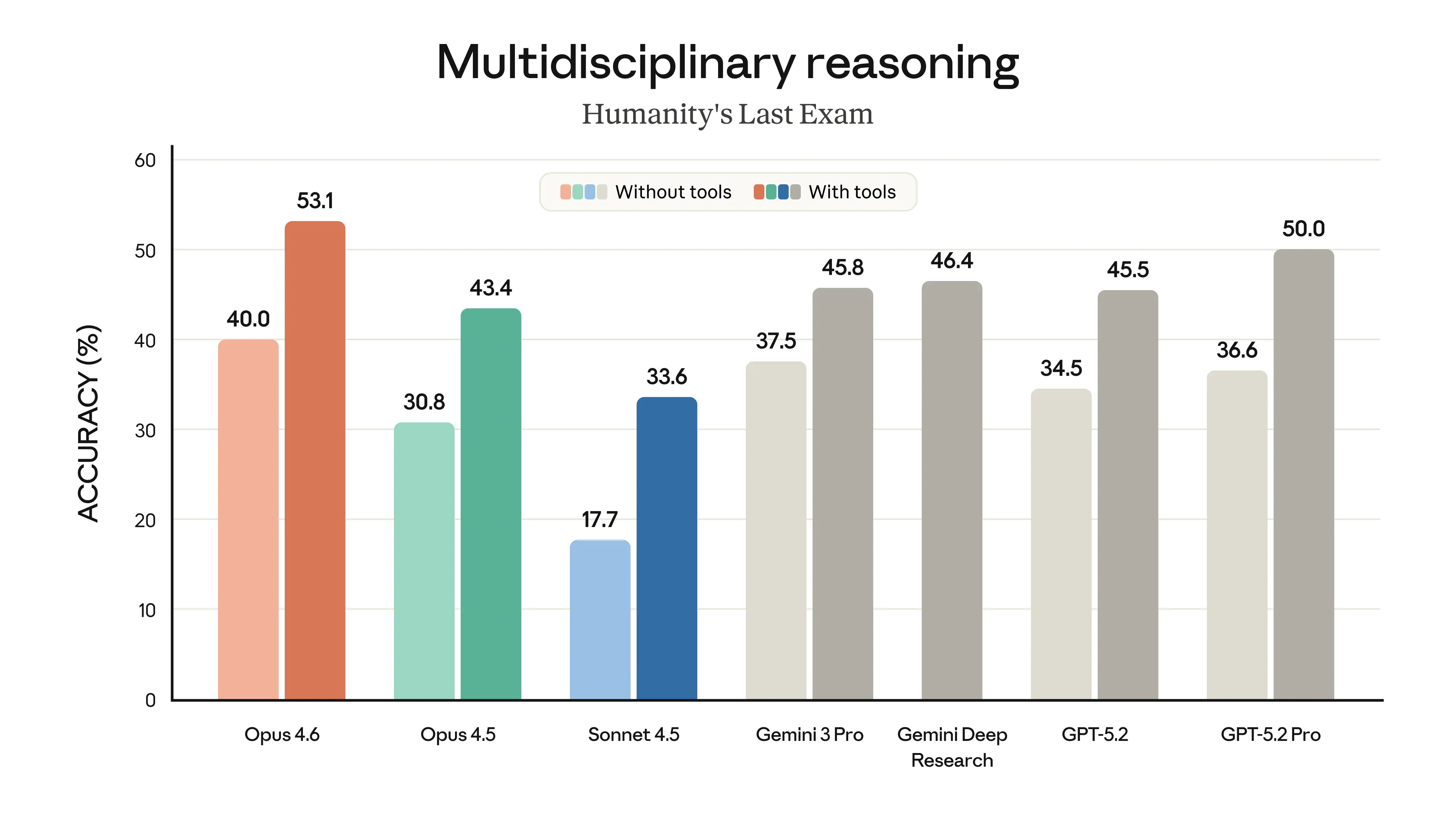
Opus 4.6 can assist with research and financial analysis, create documents, work with spreadsheets and presentations, and multitask autonomously.
Despite these advancements, it maintains strong safety and alignment standards that meet the highest industry standards.
Read more about this research using this link.
3. Qwen3-Coder-Next
Alibaba’s Qwen team introduced its new open-weight AI coding model called Qwen3-Coder-Next, built specifically for agentic coding tasks and local development workflows.
This model uses an 80B-parameter Mixture-of-Experts (MoE) architecture and activates only about 3B parameters during inference, making it efficient and cost-effective.

Despite using so few parameters, it delivers high performance on real-world coding challenges, including long-horizon reasoning, complex tool use, and recovery from execution failures.

Read more about this research using this link.
4. OpenAI Frontier
OpenAI has launched OpenAI Frontier, a new platform for businesses to build, deploy, manage, and govern AI agents.
This platform connects agents with company data and tools, such as CRM systems, data warehouses, and internal apps, and provides shared context, onboarding, feedback loops, permissions, and governance.
It also allows agents to automate complex tasks, including data analysis, software engineering, and operations.
Frontier supports both agents built on OpenAI technology and third-party agents, aims to reduce fragmentation (Agent sprawl), and helps companies use AI effectively within their existing systems.

Read more about it using this link.
5. Voxtral-transcribe-2
Mistral AI released Voxtral Transcribe 2 family of speech-to-text models that includes the following:
Voxtral Mini Transcribe V2: For batch audio transcription
Voxtral Realtime: For live, ultra-low latency streaming (that transcribes at the speed of sound)
Voxtral Mini Transcribe V2 is a batch speech-to-text model designed to transcribe pre-recorded audio, with a focus on accuracy and a detailed transcript structure.
It includes speaker diarization (who spoke when), word-level timestamps, strong noise robustness, and context biasing (better handling of names and domain jargon).
Voxtral Mini Transcribe V2 achieves the lowest word error rate at the lowest price point in the industry ($0.003/min).
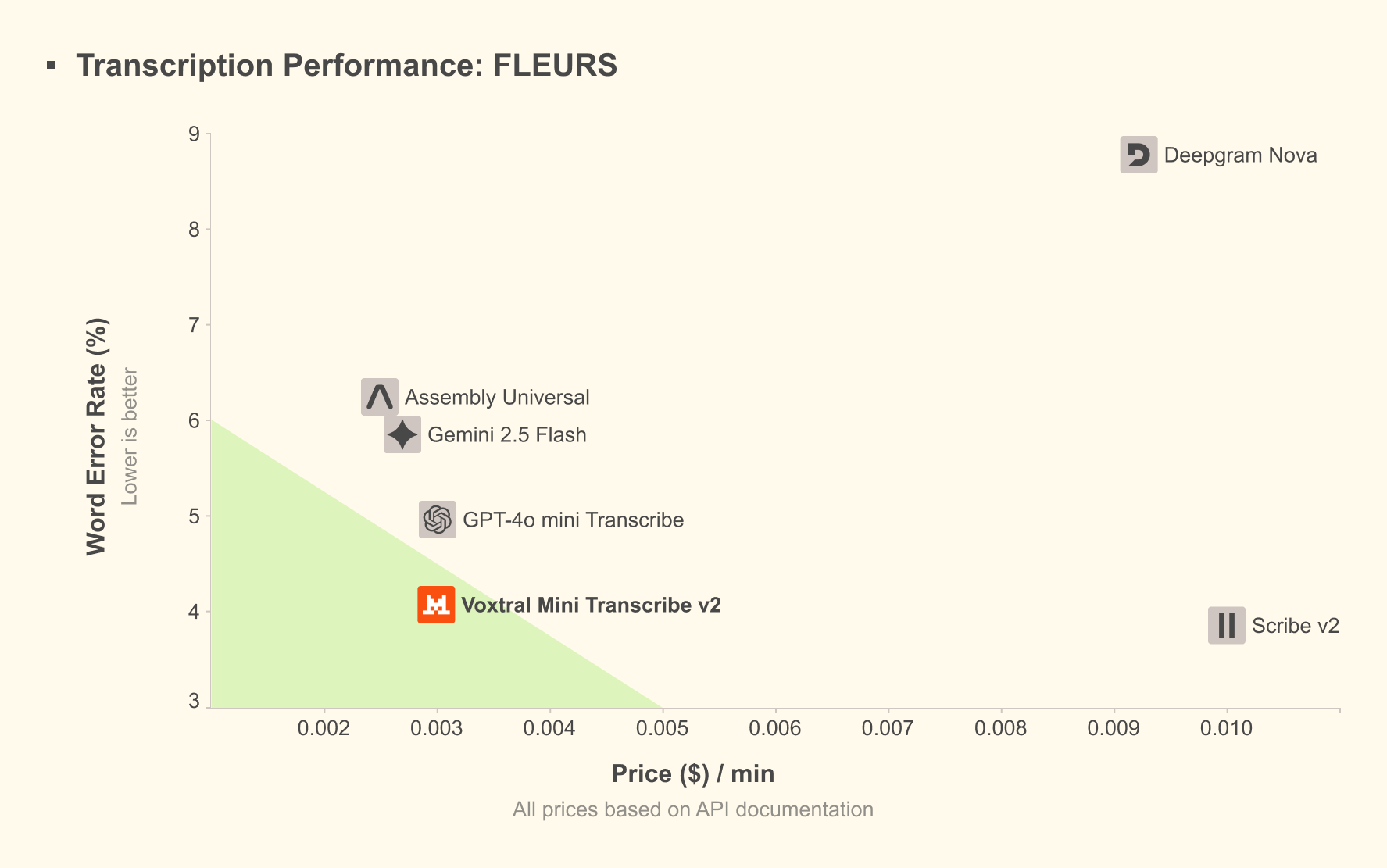
Voxtral Realtime is a live, streaming speech-to-text model, designed for ultra-low-latency transcription (sub-200 ms).
This makes it suitable for real-time voice agents and for supporting key features such as timestamps, speaker separation, and stability in noisy real-world audio environments.
Voxtral Realtime is available as open source under the Apache 2.0 license and is efficient enough to be deployable on edge devices for privacy-first applications.
Read more about it using this link.
6. World Action Models are Zero-shot Policies
This research by NVIDIA presents DreamZero, a 14B-parameter World Action Model (WAM) built upon a pretrained video diffusion backbone and designed for robot control.
DreamZero learns to predict future world states and corresponding actions as part of the same model. This allows it to generalize zero-shot to new tasks and environments better than existing VLA models, which struggle with unseen physical motions (over 2× improvement in task progress in unseen scenarios).
It works in real time and can quickly adapt to a new robot using about 30 minutes of play data. This demonstrates its strong cross-embodiment transfer and robustness without needing repetitive demonstrations.
Read more about this research using this link.
7. Kona 1.0
Logical Intelligence presents an Energy-Based Reasoning Model (EBRM) called Kona 1.0 that can solve hard Sudoku puzzles, showing that EBMs can handle constraint-satisfaction problems much better than standard LLMs.
Kona does not generate solutions one token at a time. Instead, it evaluates entire candidate solutions against all constraints at once, assigning a low energy score to valid grids and using gradient-based adjustments to fix any violations.
In their benchmark, Kona solved 96.2% of puzzles in about 313 milliseconds, while leading LLMs like GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro only solved around 2% before timing out or failing.
This shows that LLMs’ autoregressive design makes them poorly suited to reasoning on spatial tasks, whereas energy-based models can reason holistically and efficiently revise partial solutions to these problems.
Read more about this research using this link.
Try out the demo yourself using this link.
8. Mining Generalizable Activation Function
This research from Google DeepMind presents four novel activation functions discovered using an evolutionary search powered by AlphaEvolve.
These activation functions are:
GELU-Sinc-Perturbation
GELUSine
Gaussian-Modulated Tangent Unit (GMTU)
Turbulent Activation Function
These activations consistently outperform ReLU and often GELU, especially on out-of-distribution (OOD) and reasoning-style benchmarks.
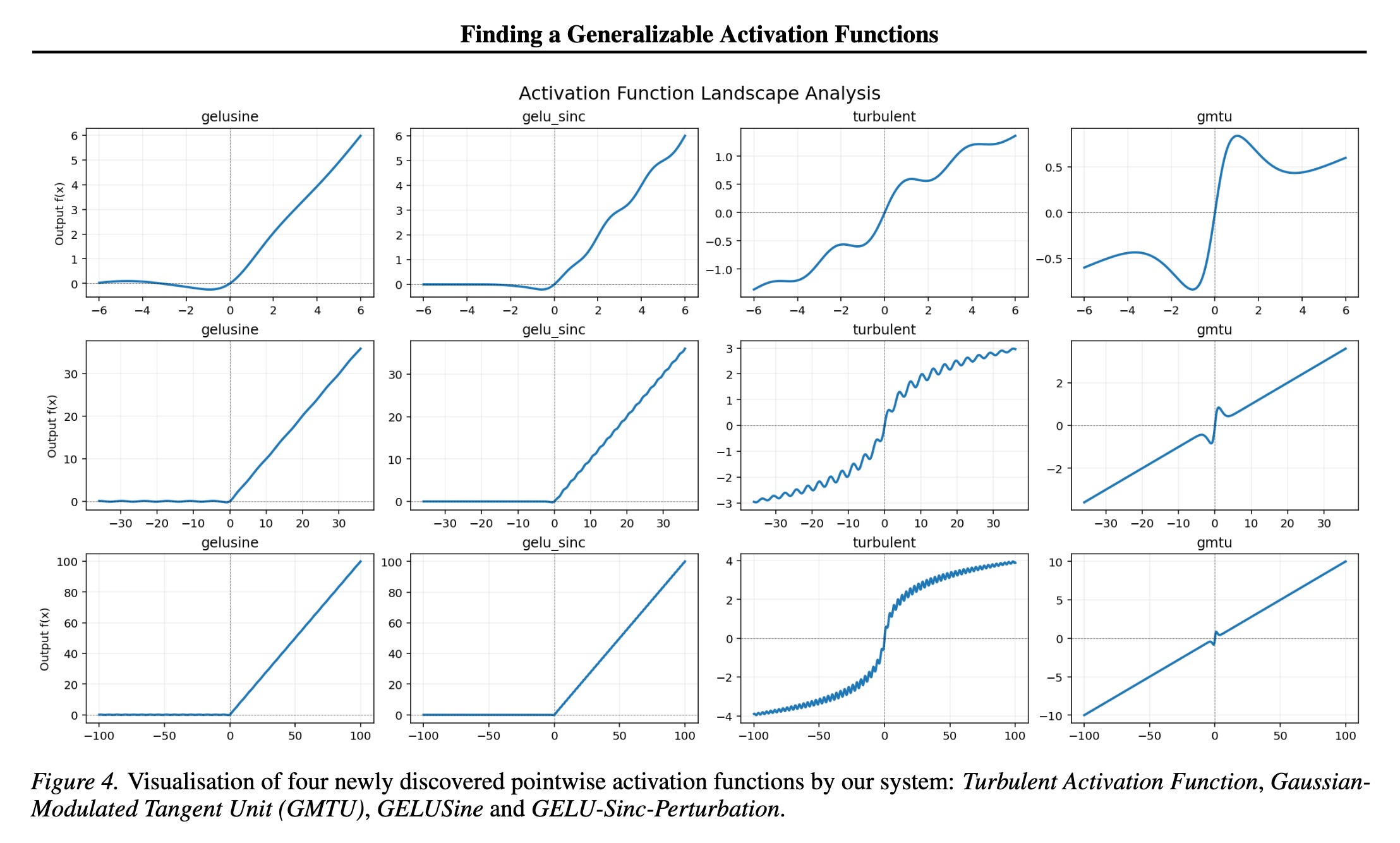
Read more about this research using this link.
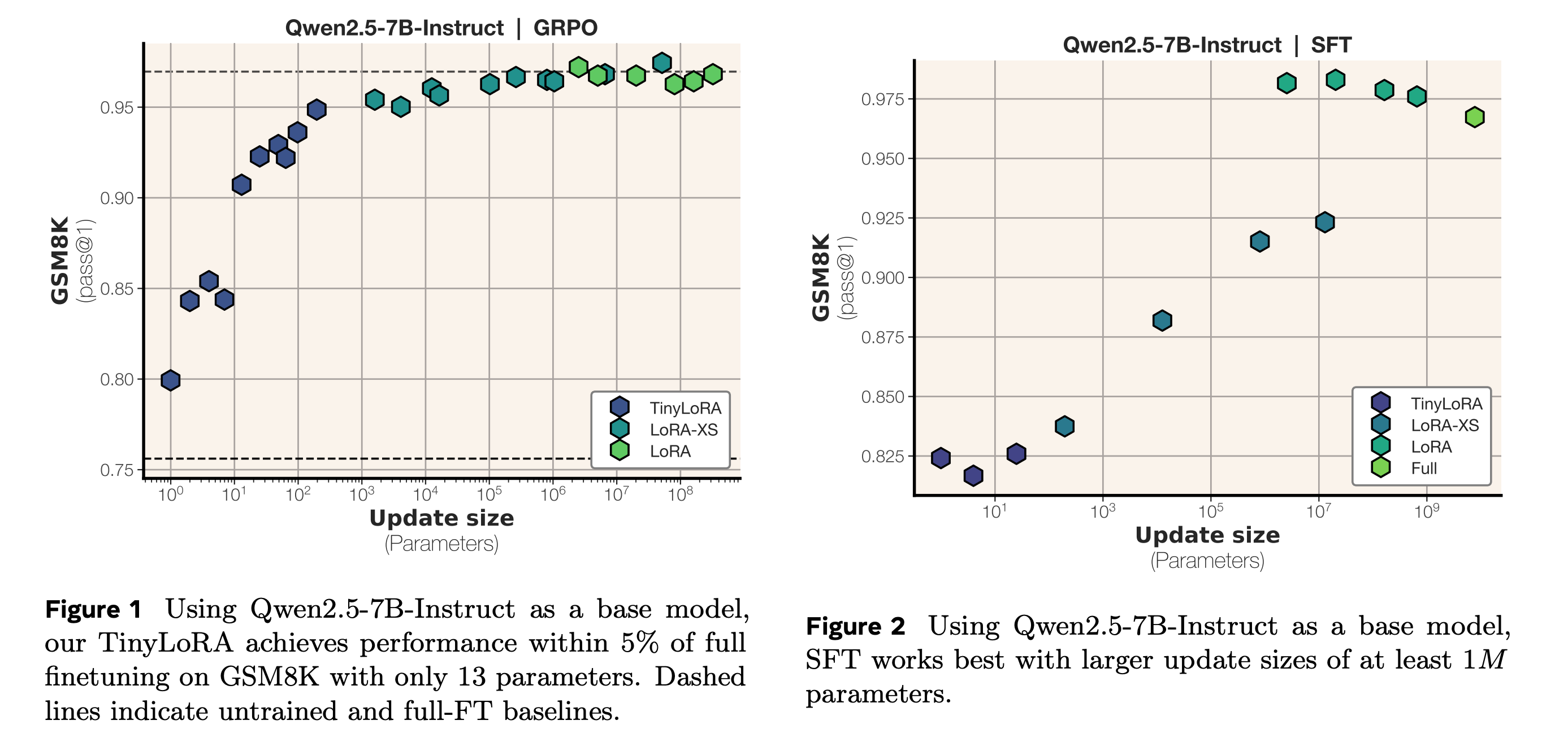
9. Learning to Reason in 13 Parameters
This research from Meta presents TinyLoRA, an extremely low-parameter fine-tuning method for LLMs that enables reasoning with very few trained parameters.
The authors show that applying TinyLoRA to a base model (Qwen-2.5-7B-Instruct) can significantly improve performance on reasoning benchmarks such as GSM8K, achieving about 91% accuracy while training with only 13 parameters.
This trend continues with tougher learning-to-reason benchmarks, including AIME, AMC, and MATH500, recovering around 90% of the full performance gains while using 1000X fewer trainable parameters.
Note that such strong performance was achieved only with RL training. Models trained using SFT required 100-1000x more trainable parameters to achieve the same performance.
Read more about this research using this link.
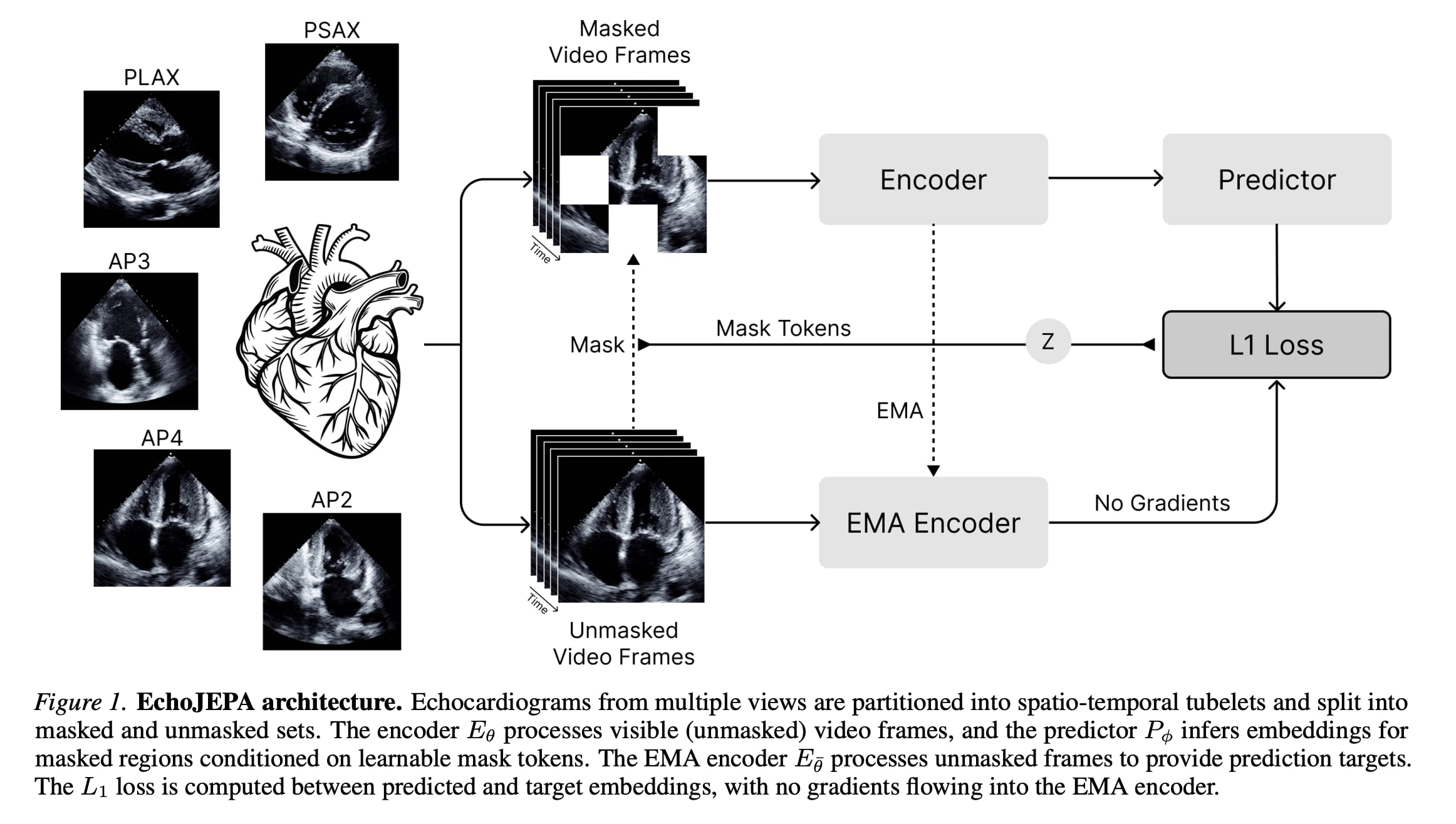
10. EchoJEPA: A Latent Predictive Foundation Model for Echocardiography
This research paper introduces EchoJEPA, a new latent predictive foundation model trained on 18 million echocardiograms from about 300,000 patients, the largest dataset for this type of imaging to date.
The model uses a latent-prediction objective to learn strong anatomical representations that ignore speckle noise and artifacts inherent to ultrasound, thereby improving clinical metrics.
Compared with leading baselines, EchoJEPA achieves about 20% better performance in estimating left ventricular ejection fraction (LVEF) and 17% better performance in estimating right ventricular systolic pressure (RVSP).
Furthermore, it generalizes significantly better under acoustic disturbances and performs well on pediatric data without any fine-tuning.
The research suggests that latent predictive modeling is a promising approach for developing reliable and generalizable medical imaging AI.
Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
Don’t forget to grab your flat 50% discount on the annual membership of Into AI today.
👉 Upgrade here, lock in the discount, and use ‘Into AI’ as your unfair advantage:
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
