

This Week In AI Research (14-20 June 26) 🗓️
The top 10 AI research papers that you must know about this week.

✨ Before we begin, I want to introduce you to a wonderful book called ‘RAG from First Principles’.
While most developers can spin up a RAG pipeline in an afternoon using LangChain or LlamaIndex, very few understand its internals well and know how to fix it when things go wrong.

‘RAG from First Principles’ takes the RAG stack apart layer by layer and teaches you about ingestion, chunking, embeddings, vector indexes, hybrid search, reranking, and evaluation.
Each chapter answers the questions practitioners actually hit in production, building from data import all the way to GraphRAG, Agentic RAG, and Modular RAG.
By the end, you’ll be able to optimize, debug, and extend your RAG systems with confidence and not guesswork.
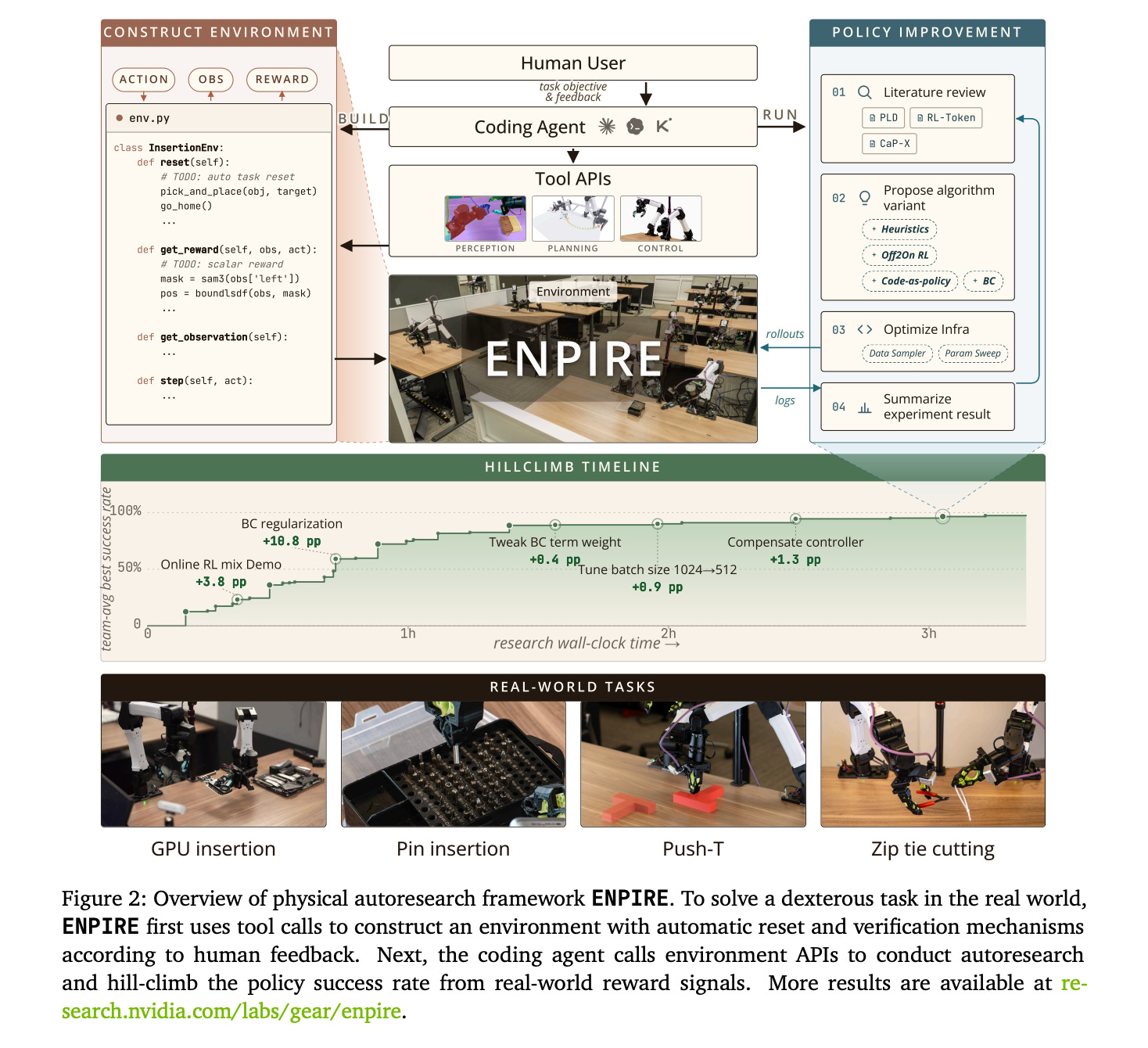
10. ENPIRE: Agentic Robot Policy Self-Improvement in the Real World
This research from NVIDIA introduces ENPIRE, a framework for coding agents that enables them to autonomously improve robot policies in real-world settings.
ENPIRE has four core modules:
Environment module (EN) that automatically resets the scene and checks whether a task succeeded
Policy Improvement module (PI) that launches policy refinement
Rollout module (R) that evaluates policies with single or multiple physical robots operating in parallel
Evolution module (E) that lets coding agents analyze logs, consult literature, improve training infrastructure, and algorithm code to fix failures
Using ENPIRE, frontier coding agents can autonomously build a policy that achieves a 99% success rate on challenging dexterous manipulation tasks such as PushT, organizing pins into a pin box, and using a cutter to cut a zip tie.
Read more about this research using this link.
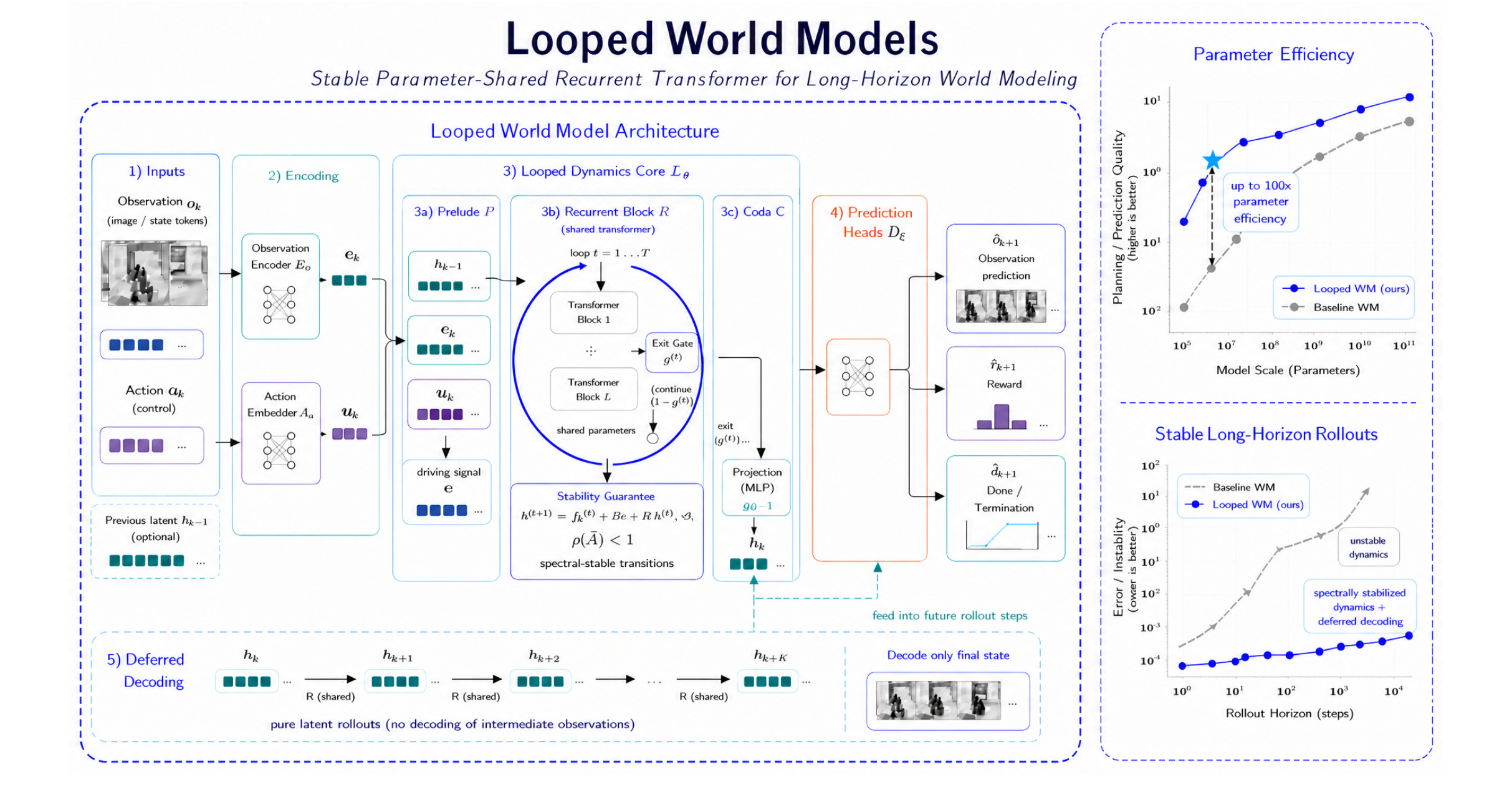
9. Looped World Models
World models today have significant computational requirements to run faithful long-horizon simulations. This makes them expensive to deploy and prone to compounding errors.
This research addresses this by introducing Looped World Models (LoopWM), which use looped, parameter-shared transformer blocks to refine latent environment states through repeated internal iterations, rather than adding multiple separate layers.
This leads to ~100× parameter efficiency over conventional approaches with adaptive computation that automatically scales depth to match the complexity of each prediction step.
LoopWM introduces iterative latent depth as a new scaling dimension for world simulation, rather than increasing model size or training data.
Read more about this research using this link.
8. Surpassing Frontier Performance with Fusion
This research from OpenRouter introduces Fusion, an approach that allows selecting a panel of participant models alongside a judge model. It then sends a prompt to multiple participant models in parallel and uses the judge model to combine their answers into a single stronger response.
The results show that:
Panels of models consistently outperform individual models
Frontier panels can achieve beyond-frontier performance
Panels of budget models can beat frontier models and get close to frontier panel performance
Two notable examples from the results are:
Fable 5 + GPT-5.5 scores 69% on OpenRouter’s DRACO deep-research benchmark, while Fable 5 alone scores 65.3% on this benchmark.
A budget panel of Gemini 3 Flash, Kimi K2.6, and DeepSeek V4 Pro outperforms GPT-5.5 and Opus 4.8. It also scores within 1% of Fable 5’s score while costing half as much.
Although highly performant, it must be noted that this method is slower, costlier, and not a drop-in replacement for coding or long-horizon agents.

Read more about this method using this link.
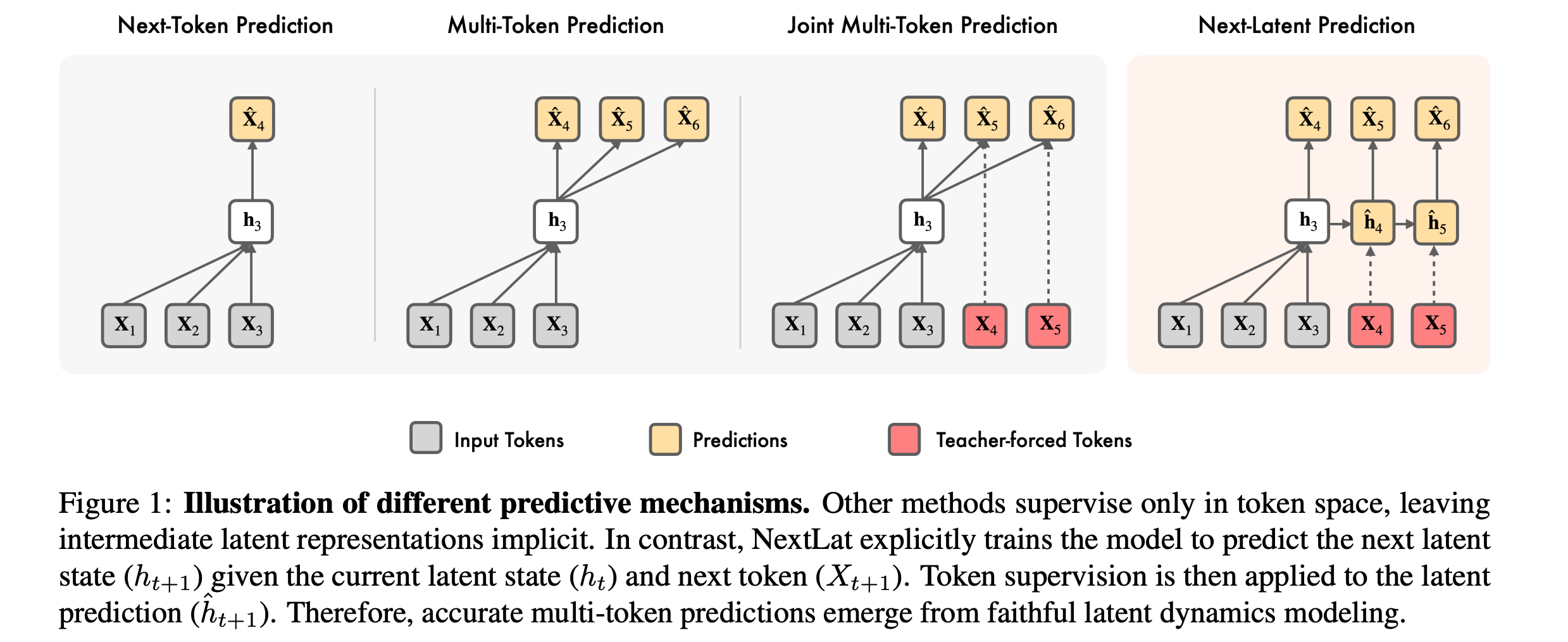
7. Next-Latent Prediction Transformers Learn Compact World Models
This research paper introduces NextLatent Prediction (NextLat), which adds a self-supervised next-latent prediction loss to transformers, helping them learn latent representations that predict the next latent state given the next token.
These latest representations form “belief states”, which are compressed information about the history necessary to predict the future (compact internal world models).
Across benchmarks in world modeling, reasoning, planning, and language modeling, NextLat leads to significant gains over standard next-token prediction and other baselines in downstream accuracy, representation compression, and lookahead planning.
It also enables variable-length self-speculative decoding, improving inference by up to 3.3× in language modeling.
Read more about this research paper using this link.
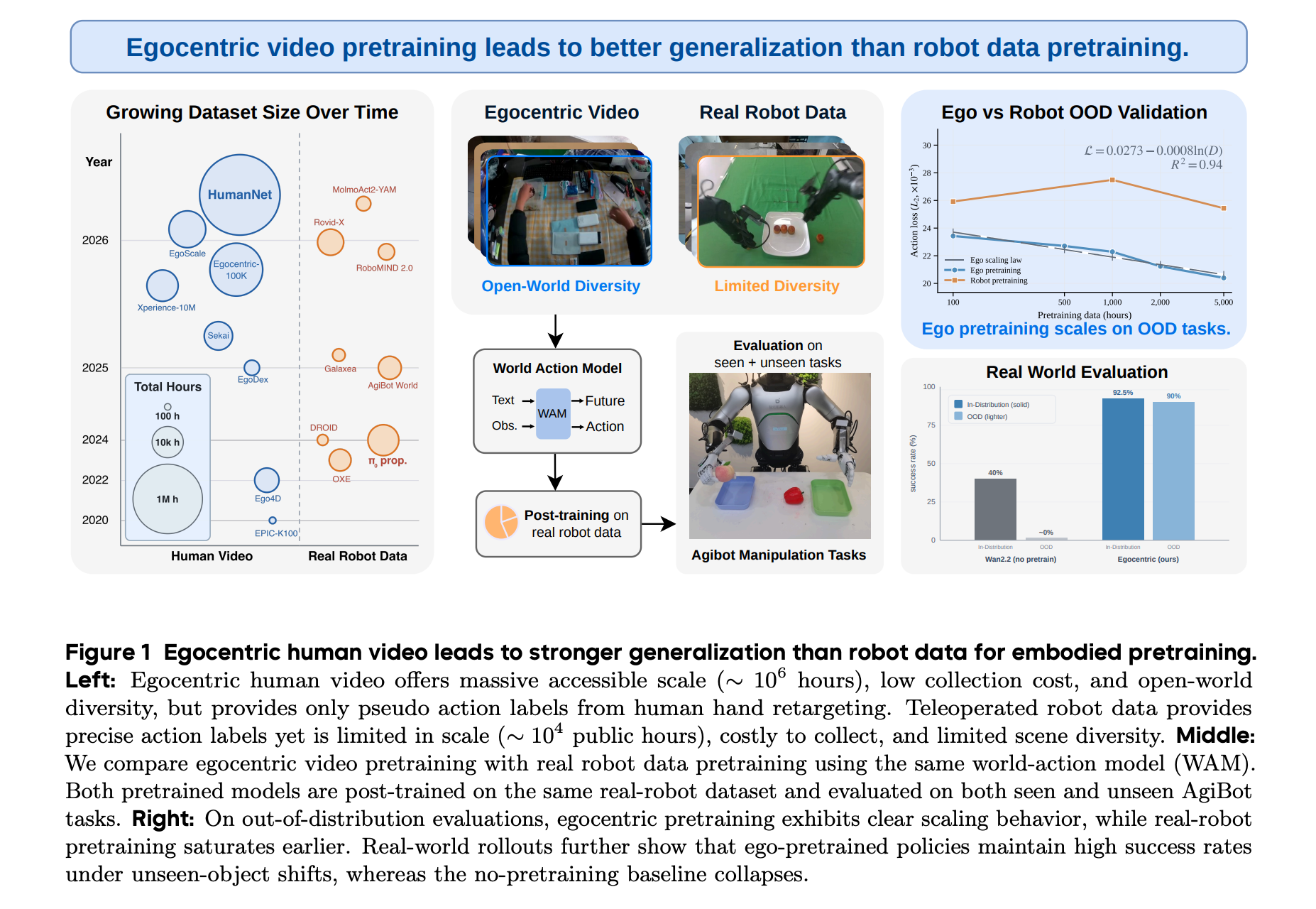
6. HumanScale: Egocentric Human Video Can Outperform Real-Robot Data for Embodied Pretraining
This research paper presents a systematic study that compares egocentric human video with teleoperated real-robot trajectories as pretraining data for embodied robot foundation models.
Human egocentric data is not only scalable, substantially lower-cost, and more diverse than teleoperated real-robot data, but under fixed pretraining, post-training, and validation protocols, it also leads to superior performance.
With the same amount of pretraining data, models pretrained on egocentric data achieve:
24% lower validation loss on real-robot action prediction,
52.5% higher success rates on in-distribution real-robot task execution
90% higher success rates on out-of-distribution real-robot task execution
This suggests that the best approach to training an embodied foundation model is to pretrain on egocentric human video to learn diverse world representations, then adapt using a small amount of labeled real-robot data for action-space alignment.
Read more about this research using this link.
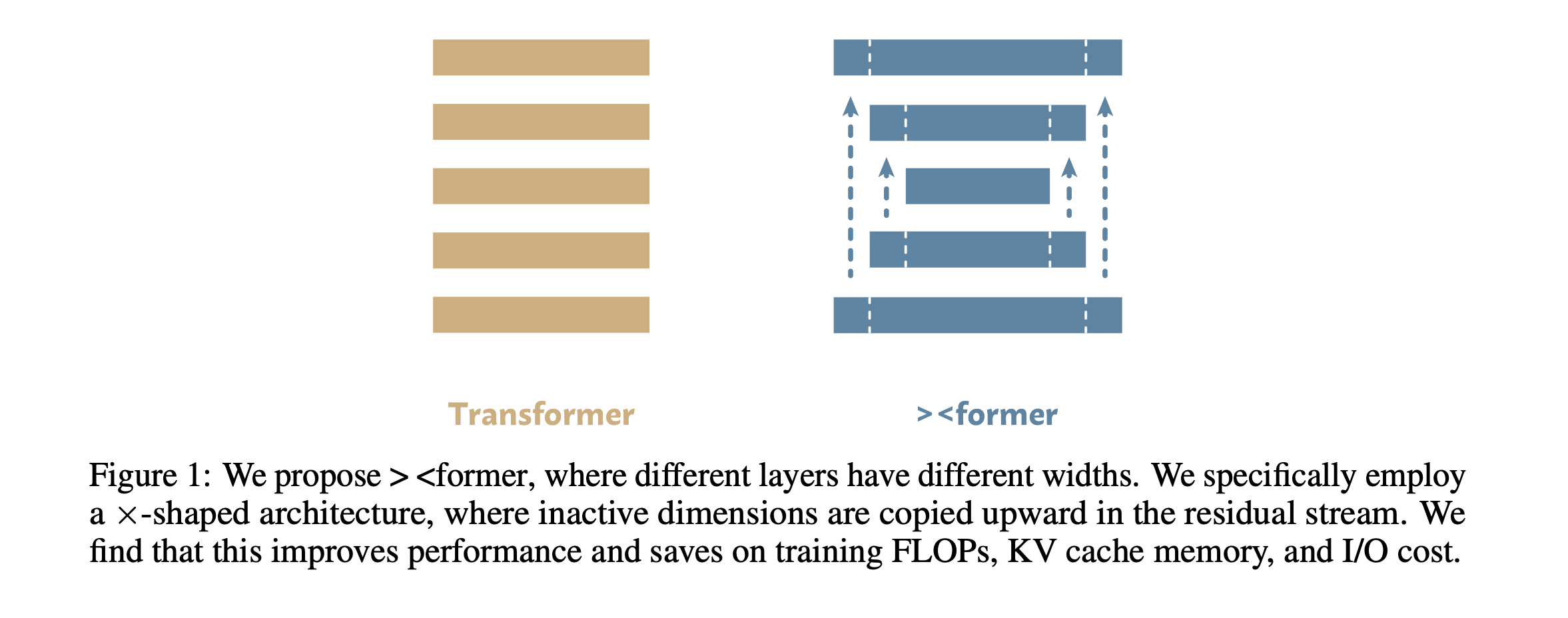
5. Variable-Width Transformers
Standard Transformers use the same width for all layers. This means that each layer has the same number of parameters and compute budget, even though they might have different functions and computational needs in language modeling.
This research paper from MIT changes this by introducing an X-shaped Transformer called the “>< former”, in which the early and late layers remain wide, while the middle layers are narrower.
This approach works surprisingly well and outperforms parameter-matched standard Transformers (ranging from 200M to 3B parameters) in terms of language modeling loss and on most downstream tasks.
This architecture also requires fewer overall FLOPs (a 22% reduction) and smaller KV cache memory and I/O costs (a 15% reduction).
Read more about this research using this link.
4. Kimi K2.7 Code
Moonshot AI released Kimi K2.7 Code, its new open-source agentic model that is optimized for long-horizon software engineering tasks.
It is a 1T-parameter MoE model with 32B active parameters and uses MLA attention and the MoonViT vision encoder.
It improves over K2.6 on multiple coding and agent benchmarks, has better instruction-following capabilities in long contexts, uses about 30% fewer thinking tokens, and supports a 256K context window.
Alongside this, its performance is close to that of GPT-5.5 and Claude Opus 4.8 on many benchmarks while it is roughly 5-7x cheaper to run.

Read more about this release using this link.
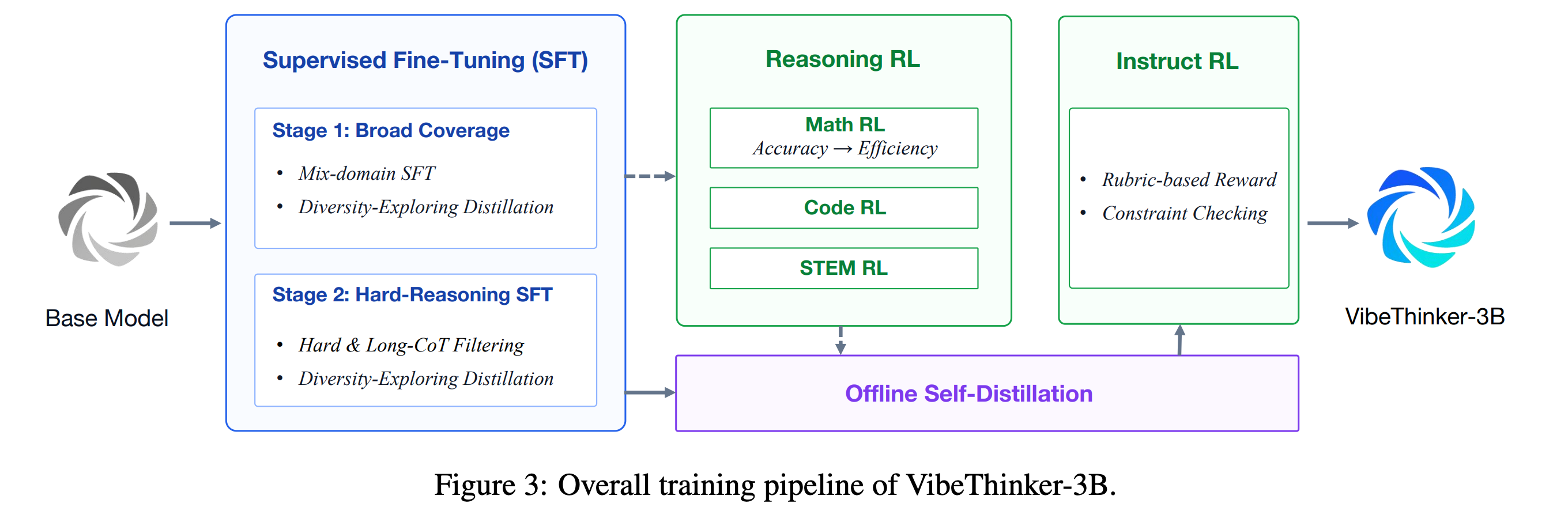
3. VibeThinker-3B
This research paper from Weibo introduces VibeThinker-3B, a 3B-parameter dense reasoning model that achieves performance comparable to that of large frontier models on math and coding tasks.
The model is post-trained using Qwen2.5-Coder-3B as the base model, using several techniques such as:
Curriculum-based two-stage SFT: Training first on broad reasoning/dialogue data, then progressively harder long-horizon math/code/STEM examples
Multi-domain RLVR using MGPO: Training across math, coding, and STEM examples using the MGPO algorithm. MaxEnt-Guided Policy Optimization (MGPO) helps the model explore different reasoning paths near its current capability, then amplifies the paths that produce verifiably correct answers.
Offline Self-Distillation: Collecting the best reasoning traces from the model’s own RL-specialized checkpoints and distilling them back into a single 3B model
Instruct RL: Training the model to follow user instructions and stick to output formats and user constraints reliably without losing reasoning gains
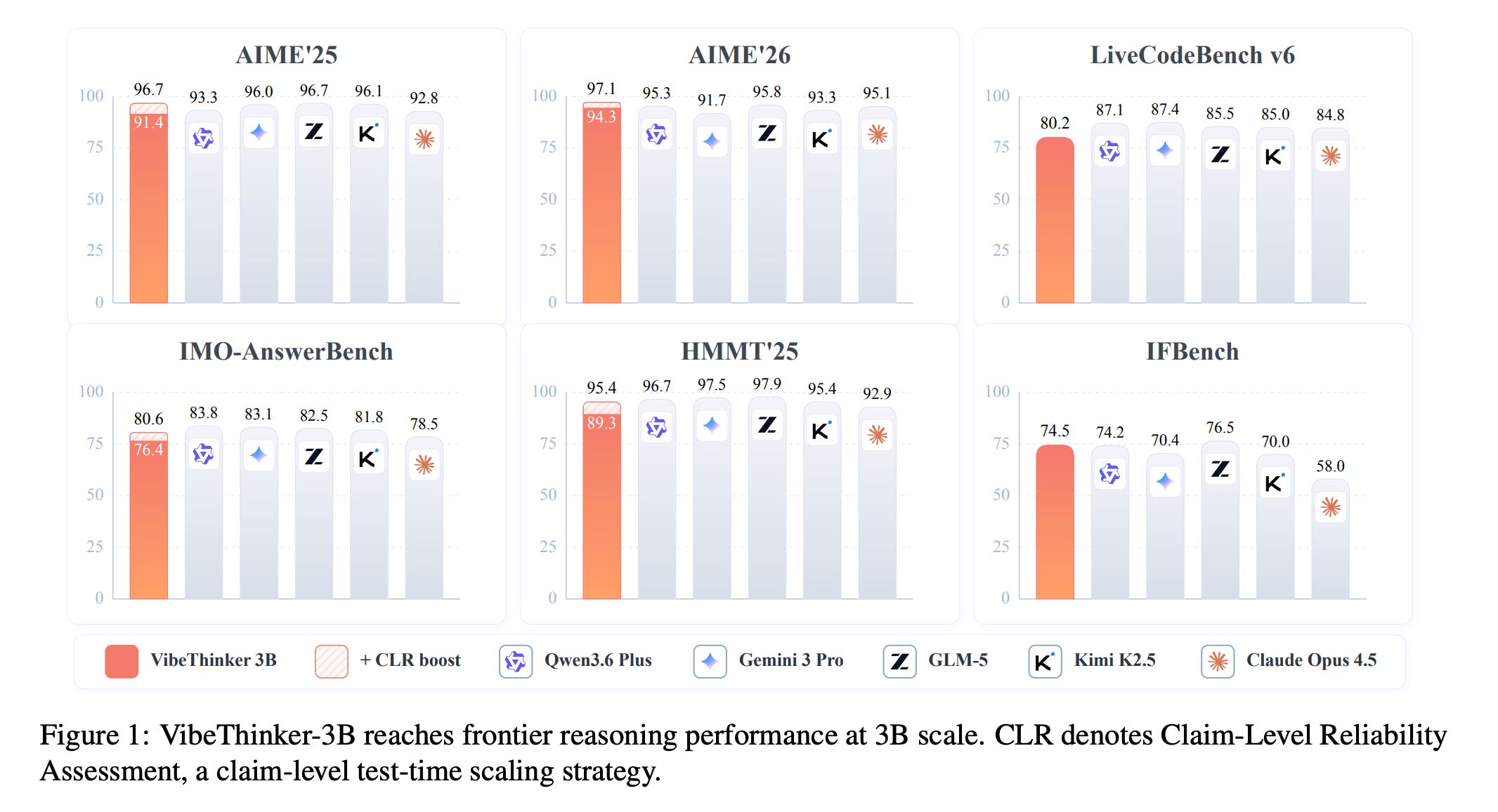
The model scores 94.3% on AIME26 (97.1% with Claim-level Reliability), 80.2% Pass@1 on LiveCodeBench v6, and achieves a 96.1% acceptance rate on recent unseen LeetCode contests.
Read more about this research using this link.
2. GLM-5.2
Z.ai introduced GLM-5.2, its open MIT-licensed flagship model for long-horizon coding and agent tasks.
The model:
Has a 1M-token context window
Has stronger coding capabilities with multiple thinking effort levels to balance performance and latency
Uses IndexShare, which reuses the same indexer across every four sparse attention layers, reducing per-token FLOPs by 2.9× at a 1M context length.
MTP layer is also better suited for speculative decoding, increasing the acceptance length by up to 20%.
GLM-5.2 is the strongest open model on several coding and agentic benchmarks, with performance close to frontier models on long-horizon tasks.


Read more about this release using this link.
1. Towards autonomous medical artificial intelligence agents
This research paper introduces MIRA (Medical Intelligence for Reasoning and Action), an autonomous AI agent capable of operating within a sandboxed EHR (Electronic Health Record) environment.
It can:
Take histories
Order and interpret laboratory, imaging, and microbiology tests
Generate differential diagnoses
Formulate treatment plans, including prescribing medications, scheduling surgical procedures, and planning admissions.
On 574 real MIMIC-IV cases across 8 diseases, MIRA achieved 88.9% diagnostic accuracy and, in head-to-head testing, outperformed board-certified physicians (87.8% vs 78.1% accuracy), while showing strong medication safety and alignment with medical guidelines.

Read more about this research using this link.
This newsletter edition is completely free to read. Show your love by liking it, restacking it, and sharing it with others! ❤️
Join the paid tier today to get access to all posts in this newsletter:
and so many more!