

This Week In AI Research (21-30 June 26) 🗓️
The top 10 research papers of this week: GPT‑5.6, Claude Sonnet 5, Meta's real‑time brain‑to‑text decoder, a 35B model that beats trillion‑parameter LLMs, and more.

✨ Before we begin, I want to introduce you to a wonderful book called “30 Agents Every AI Engineer Must Build”.

This book guides you through 30 real-world agent architectures, covering the core building blocks of perception, memory, reasoning, and planning, and teaches you LangChain and LangGraph to create agents across finance, legal, healthcare, and more.
It also helps you learn how to deploy, evaluate, and guard your agents to ensure that they perform well in production. Grab your copy today using the link below.
10. Accurate Decoding of Natural Sentences from Non-Invasive Brain Recordings
This research introduces Brain2Qwerty v2, an AI model that can decode natural sentences a person is typing from their magnetoencephalography (MEG) recordings in real time.
The model has an average word error rate of 39%, and for the best participant, it can accurately decode half of the sentences with one word error or less.
The model’s accuracy also improves log-linearly with more data. This means that increasing the number of recordings could close the gap with surgically implanted brain-computer interfaces, reaching accuracy levels that were once believed to be possible only with implants.
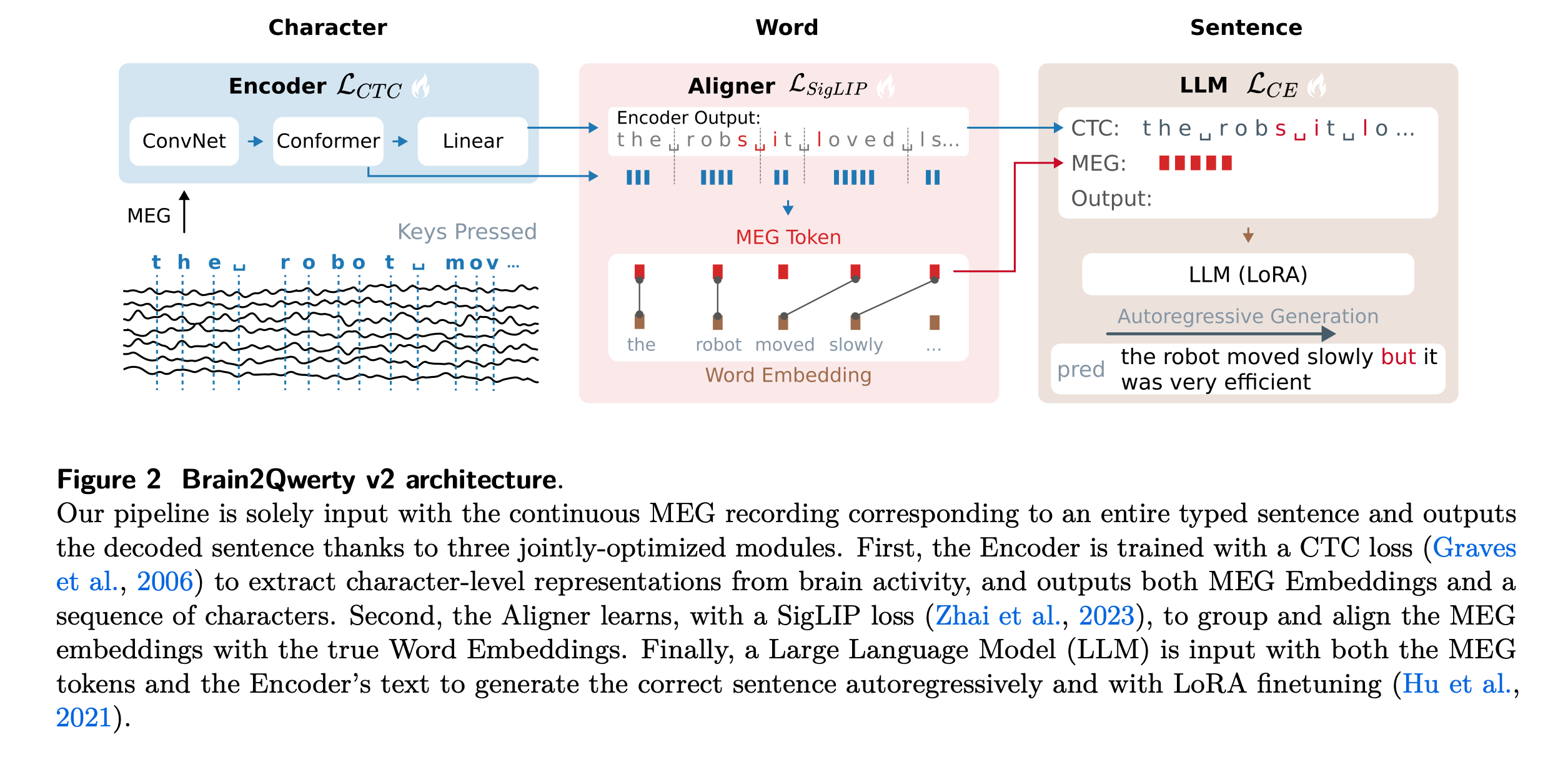
Read more about this research using this link.
9. GPT‑5.6 Sol
OpenAI released its GPT‑5.6 series with three models:
Sol (flagship model)
Terra (balanced model for everyday work)
Luna (a fast and affordable model)
Among these, GPT‑5.6 Sol is the strongest model for tough agentic work such as coding, scientific analysis, biological workflows, cybersecurity, and long-horizon tool use.
For coding workflows, GPT‑5.6 Sol sets a new state of the art on Terminal‑Bench 2.1.
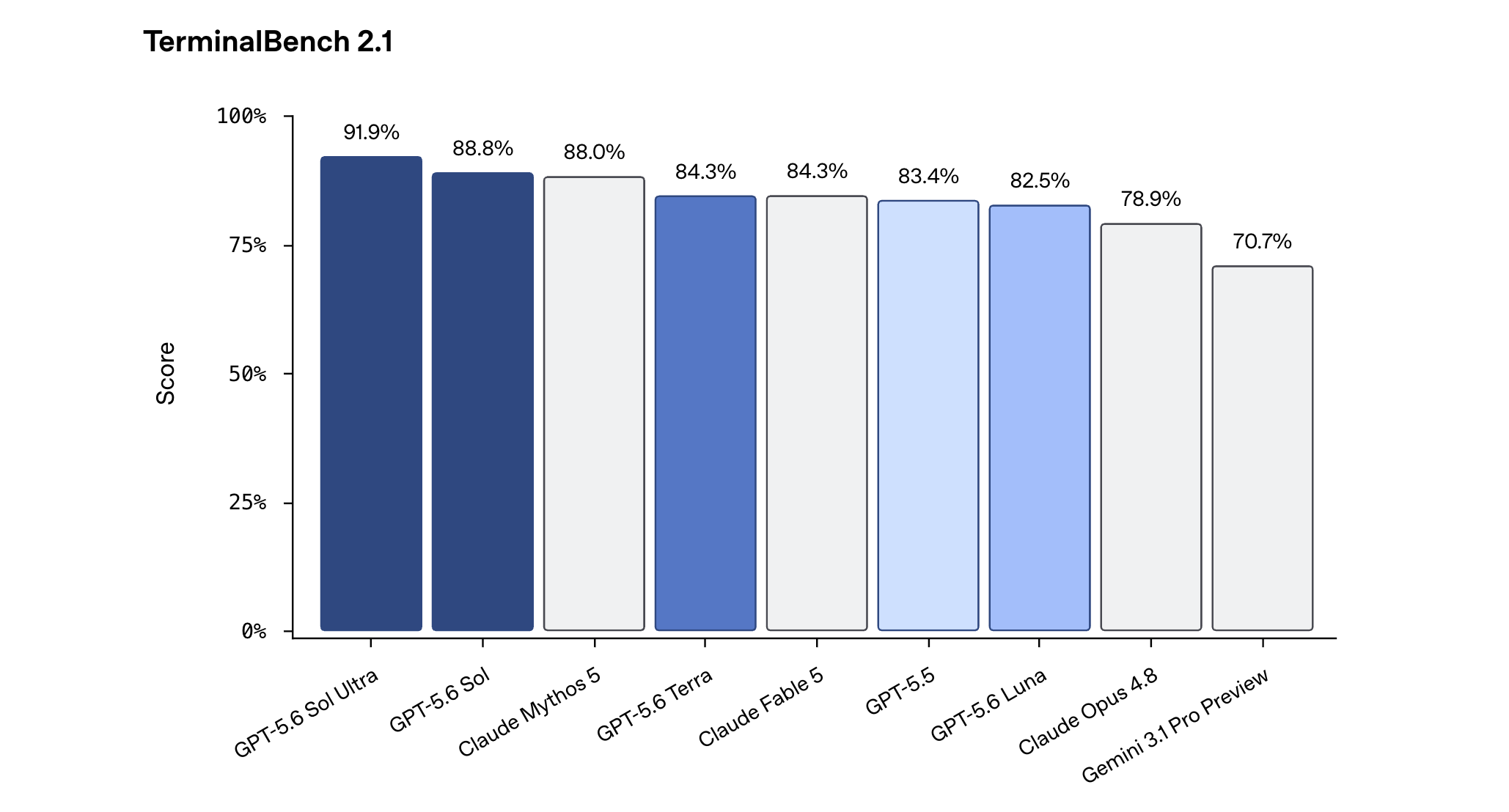
It also performs competitively with Mythos Preview using only a third of the output tokens on ExploitBench.
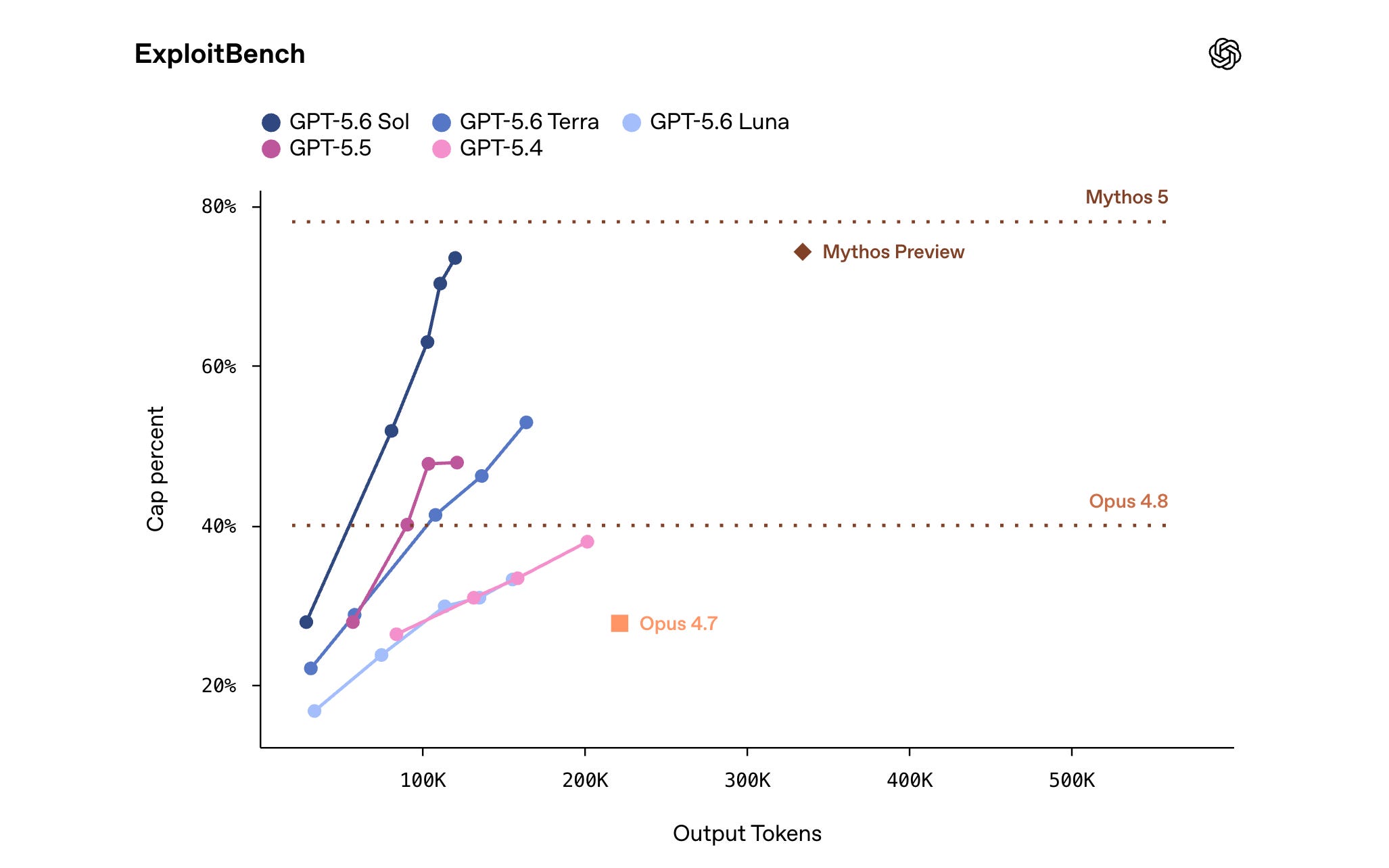
Read more about this release using this link.
8. Sakana Fugu
This research paper introduces Sakana Fugu, a family of orchestrator LLMs trained to understand user queries and dynamically create agentic scaffolds to solve them.
The two models in the Sakana Fugu family are:
Fugu (balances performance with latency for everyday use)
Fugu-Ultra (prioritizes answer quality on the most difficult problems)
Using adaptive scaffolds, these models achieve performance beyond that of any individual LLM agent, and reach SOTA results compared to other publicly accessible models across a wide range of challenging benchmarks (SWE-Bench Pro, Terminal Bench, LiveCodeBench, GPQA-Diamond, Humanity’s Last Exam, and CharXiv Reasoning).
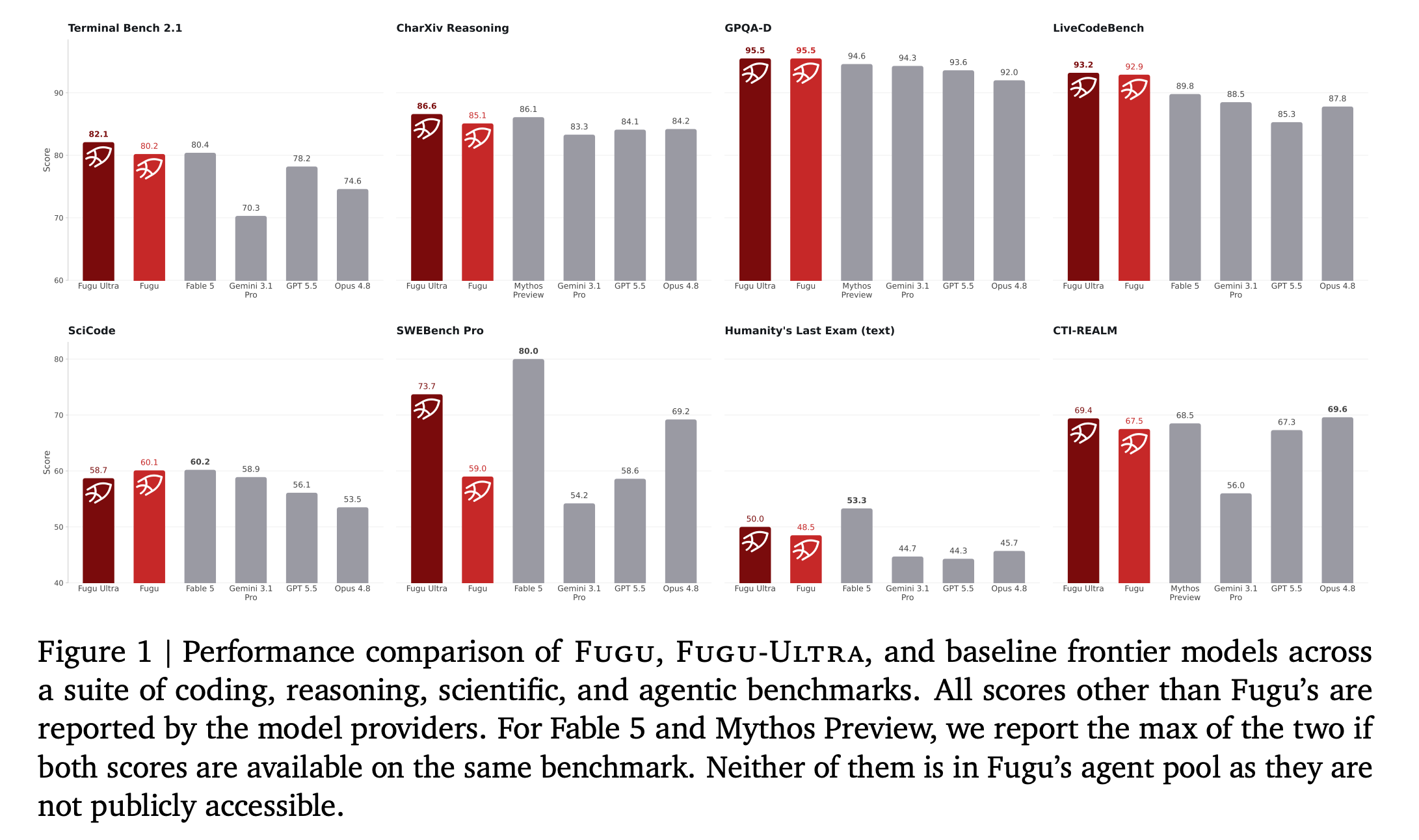
Read more about this research using this link.
7. The Red Queen Gödel Machine
This research paper presents the Red Queen Gödel Machine (RQGM), which is based on the evolutionary insight that species do not optimize against a static environment but adapt as their environments change with them.
Red Queen Gödel Machine (RQGM) is a framework for recursively self-improving agents in which both the agent and its evaluator evolve together rather than relying on a fixed benchmark.
It uses “Controlled utility evolution”, a technique that keeps evaluation constant within each epoch but allows it to change between epochs.

RQGM improves test pass rates compared to previous SOTA by adding an agent-as-a-judge code-review signal while using 1.35×-1.72× fewer tokens because the reviewer is queried only once.
With RQGM, co-evolved scientific paper writing and reviewing agents reach 1.78×–1.86× higher acceptance rates under a diverse agent-as-a-judge panel, while co-evolved Olympiad-level proof writing and grading agents reach 9% higher ground-truth accuracy.
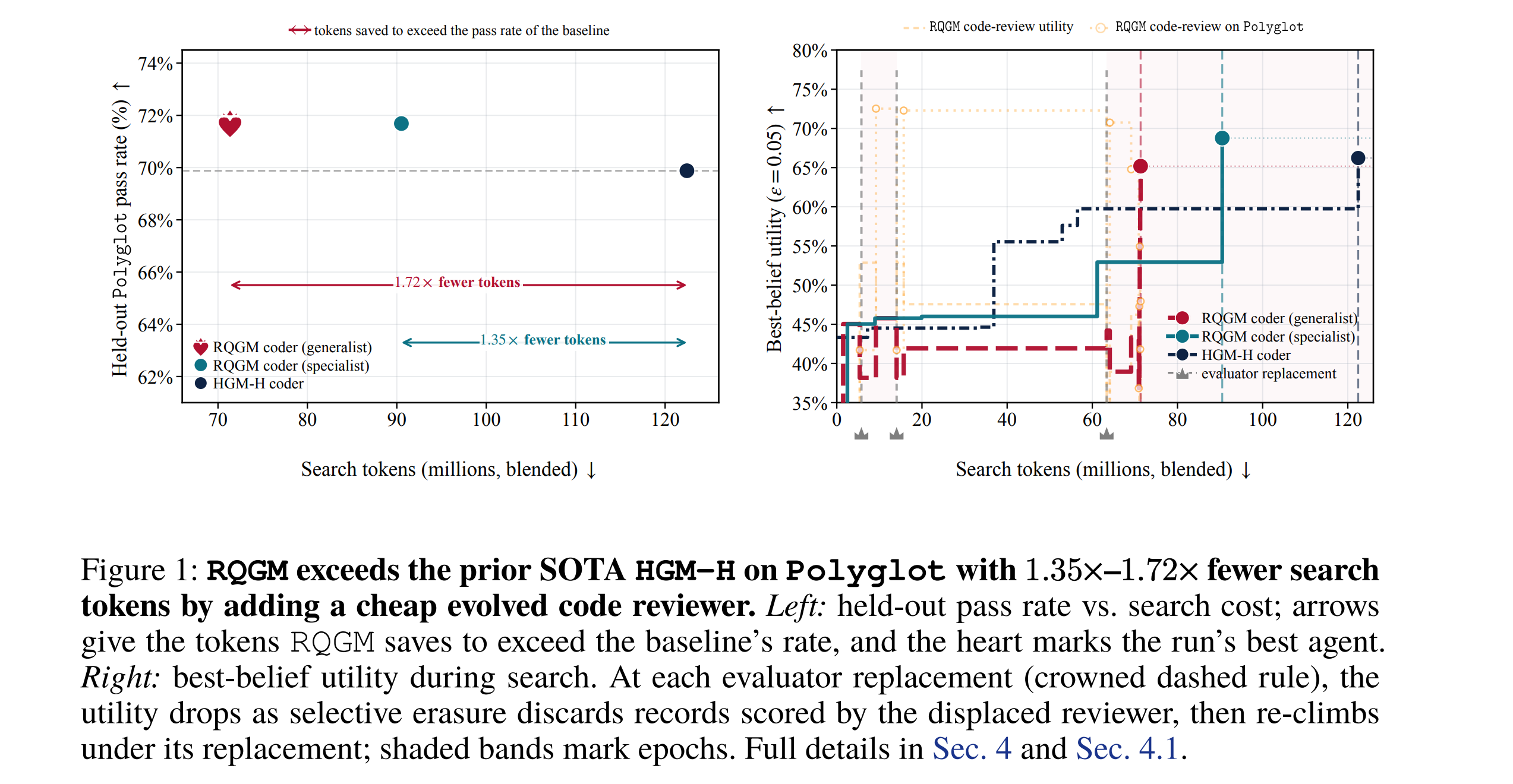
Read more about this research using this link.
6. OCR 4
Mistral released OCR 4, which they claim to be the best OCR model to date.
Instead of just turning a document into text, OCR 4:
Returns bounding boxes around text items
Classifies each box into titles, tables, equations, signatures, and more
Tells how sure it is about each extraction (inline confidence scores)
The model also:
Supports 170 languages across 10 language groups
Is small enough to run in a single container for fully self-hosted deployments
Costs $2-5 per 1,000 processed pages
OCR 4 has a 72% average win rate across all leading OCR systems in blind human evaluations and achieves top scores on OlmOCRBench (85.20) and OmniDocBench (93.07).
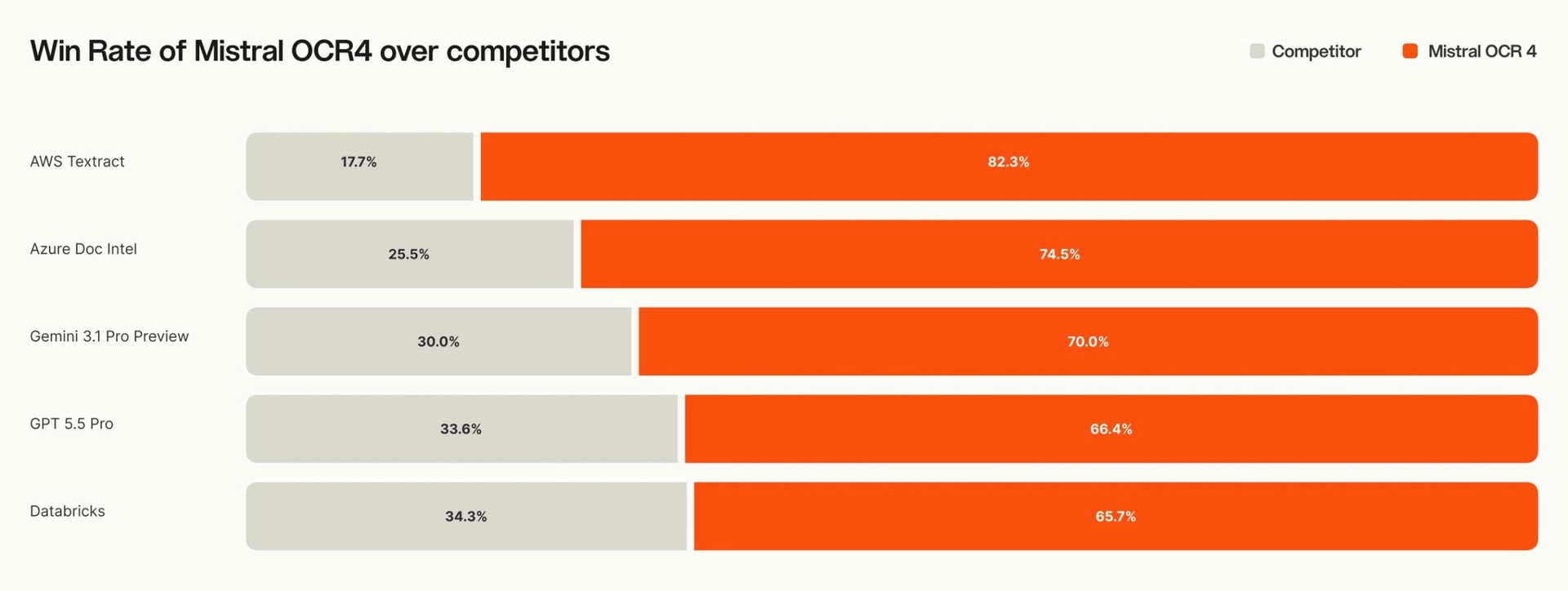
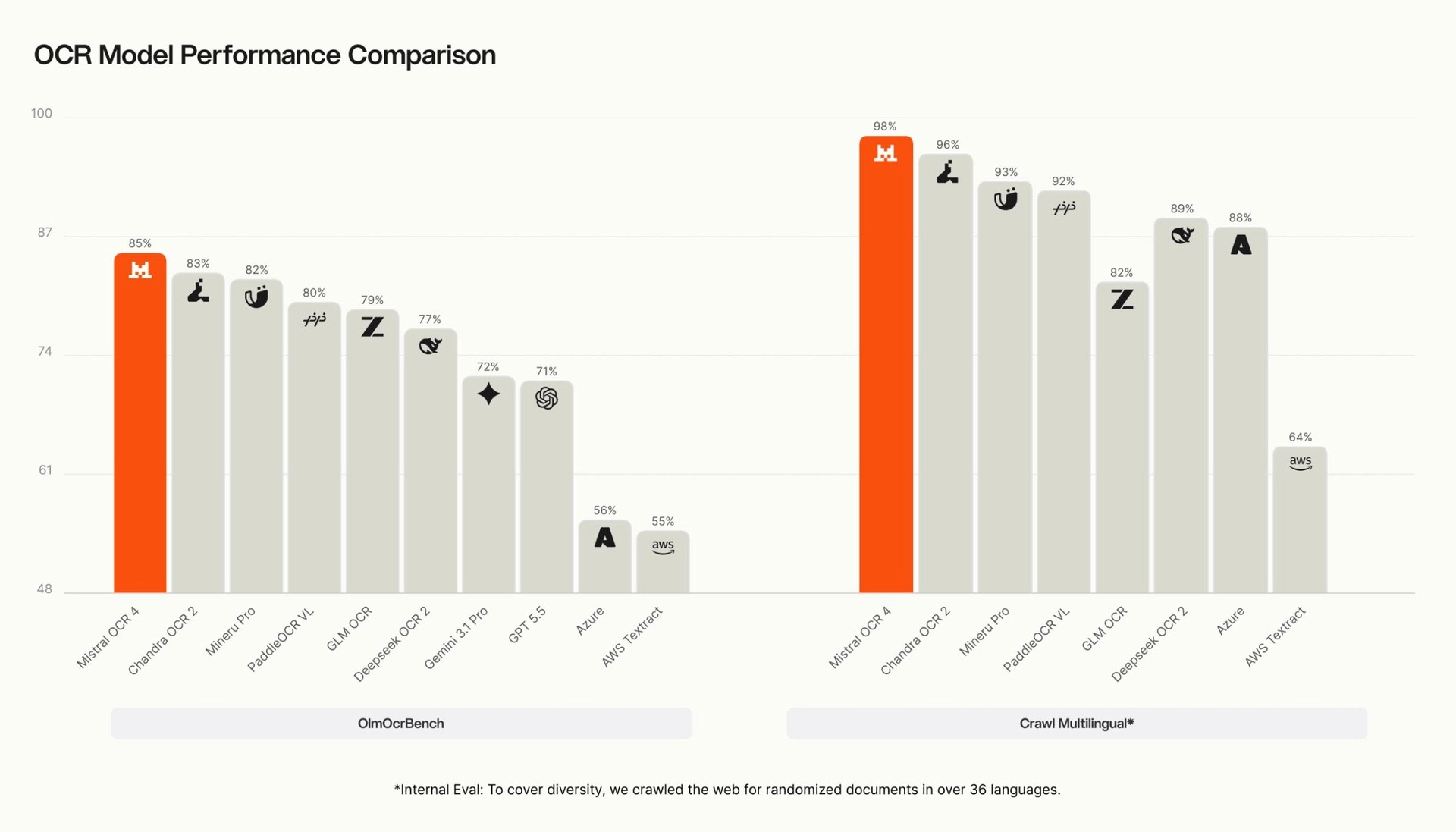
Read more about this release using this link.
5. MOPD: Multi-Teacher On-Policy Distillation for Capability Integration in LLM Post-Training
This research presents Multi-teacher On-Policy Distillation (MOPD), a post-training method that combines the capabilities of multiple domain RL-trained teacher models into one student model.
The method first RL trains separate domain-expert/teacher models. Then, it distills them into the student using the student’s own on-policy rollouts. This eliminates exposure bias and gives a denser optimization signal than off-policy finetuning.
On Qwen3-30B-A3B, MOPD outperforms Mix-RL, Cascade RL, Off-Policy Finetune, and Param-Merge baselines, while inheriting nearly all of each teacher’s specialized capability.
It also enables parallel training of domain teachers, followed by merging their strengths into a single deployable model.
MOPD has been used in the post-training of MiMo-V2-Flash, a powerful, efficient, and ultra-fast foundation language model that particularly excels in reasoning, coding, and agentic scenarios.
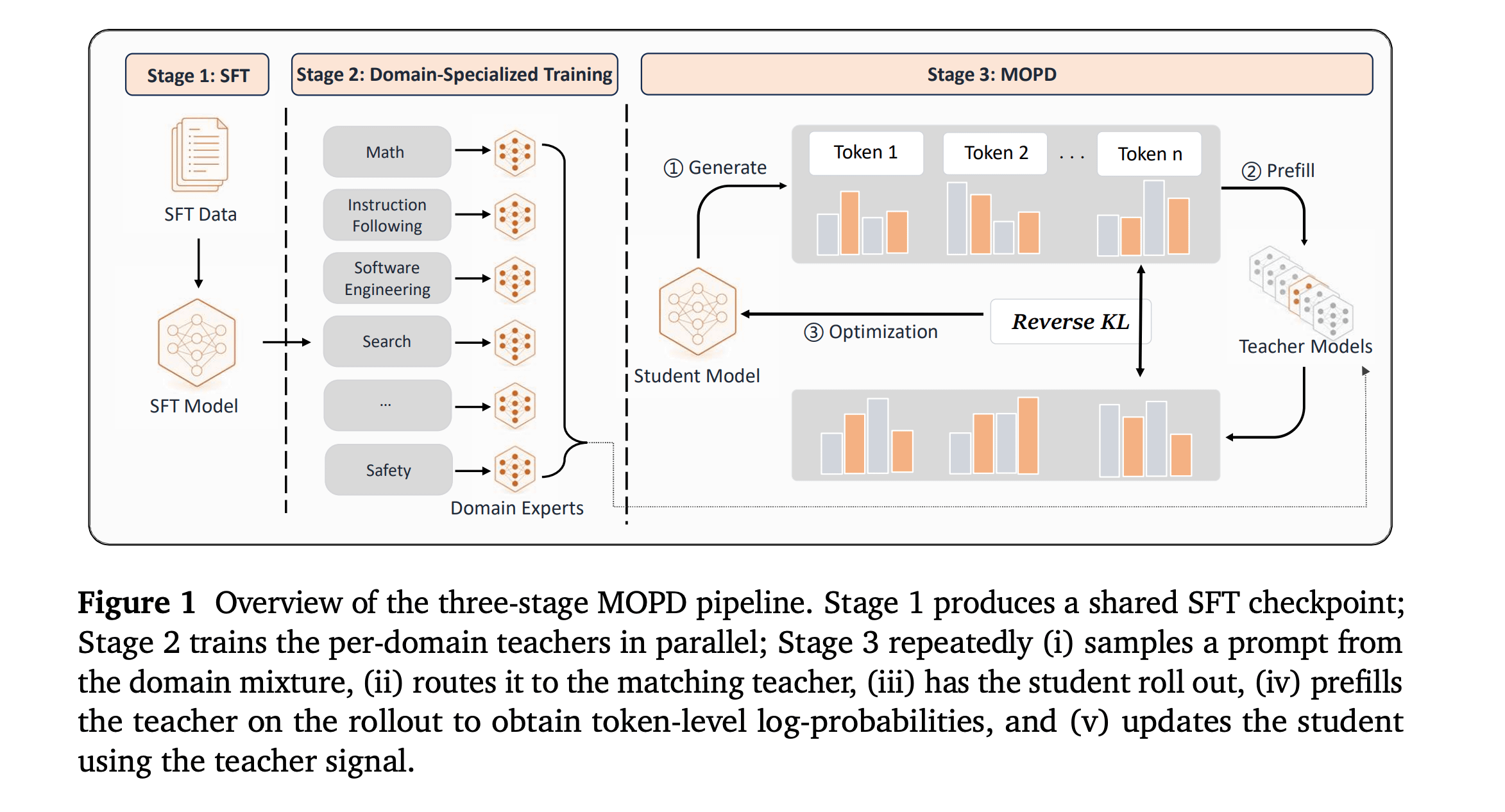
Read more about this research using this link.
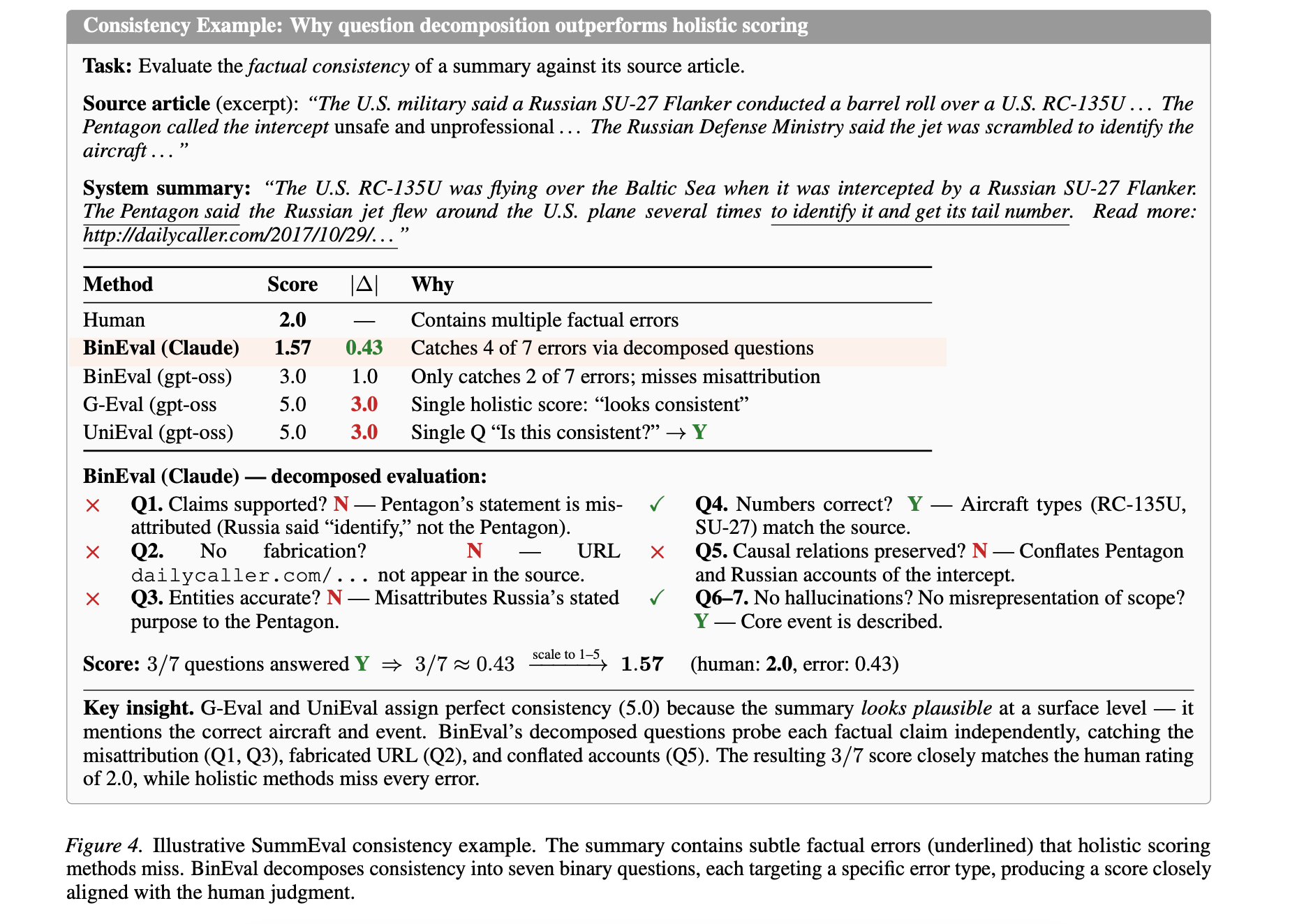
4. Ask, Don’t Judge: Binary Questions for Interpretable LLM Evaluation and Self-Improvement
This research paper presents BINEVAL, an alternative to “LLM-as-a-judge” scoring, which often produces opaque scores that are hard to debug.
Instead of asking a model to provide one overall score, BINEVAL divides each evaluation criterion into multiple simple yes/no (binary) questions.
Given a task prompt, a meta-prompt generates fine-grained evaluation questions, and an LLM answers them independently for each output. It then scores each of these answers independently and combines them into interpretable, multi-dimensional scores.
This makes it easier to identify which checks failed, such as factual consistency, missing information, relevance, or redundancy.
This question-level feedback can also be used to iteratively improve evaluator prompts for summarization and generation.
Across multiple benchmarks such as SummEval, Topical-Chat, and QAGS, BINEVAL performs as well as or better than strong baselines such as UniEval and G-Eval, with particularly strong results on factual consistency.
Read more about this research using this link.
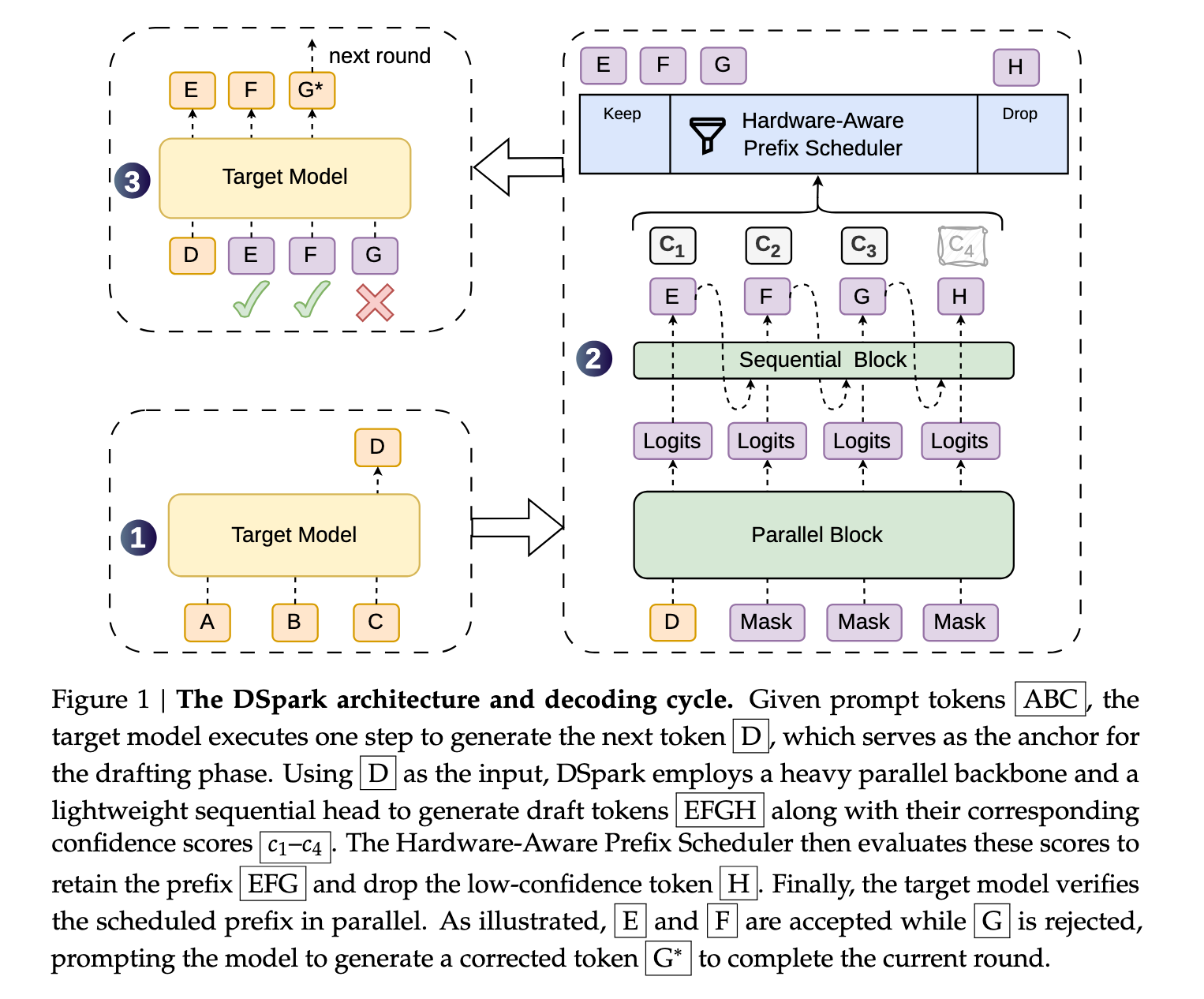
3. DSpark: Confidence-Scheduled Speculative Decoding with Semi-Autoregressive Generation
Speculative Decoding speeds up LLM inference by using a small draft model that suggests tokens while the larger LLM checks them.
While the draft model is fast, it often loses token consistency due to a lack of inter-token dependencies. Also, indiscriminately verifying long drafts wastes compute, severely reducing throughput in high-concurrency serving systems.
This research paper proposes DSpark, a speculative decoding framework that combines high-throughput parallel generation with adaptive, load-aware verification.
DSpark uses:
A semi-autoregressive architecture that adds a lightweight sequential dependency module to introduce intra-block dependency modeling and reduce suffix decay.
Confidence-scheduled verification to dynamically decide how many draft tokens to verify for each request based on the chance that the prefix will survive and the current throughput profile of the serving engine
DSpark substantially improves the accepted length compared to SOTA autoregressive and parallel drafters across multiple offline benchmarks.
When deployed within the DeepSeek-V4 serving system under live user traffic, DSpark successfully reduces verification waste. It improves per-user generation speeds by 60-85% at matched throughput levels compared to the established production baseline (MTP-1).
By preventing severe throughput degradation under strict interactivity constraints, it also enables performance tiers that were previously unattainable, shifting the Pareto frontier of the DeepSeek-V4 serving system.
Read more about this research using this link.
2. Claude Sonnet 5
Anthropic released Claude Sonnet 5, their most agentic Sonnet model yet. The model is well suited for coding, tool use, browser and terminal workflows, long-running agentic workflows, and professional knowledge work.
The model substantially outperforms Sonnet 4.6 across multiple domains, and its performance is close to that of Claude Opus 4.8 on many benchmarks, but at a lower price.

It also has lower rates of hallucination, sycophancy, and unwanted behaviors compared to Sonnet 4.6, has better resistance to prompt injection, and comes with cyber safeguards that detect and block dangerous cyber activity in real time.

Read more about this release using this link.
1. Reaching Trillion-Parameter Performance with a 35B Agent
This research introduces Agents-A1, a 35B Mixture-of-Experts agentic model that achieves performance comparable to trillion-parameter models by expanding the agent horizon rather than model size/ parameters.
The authors build a long-horizon knowledge-action infrastructure that connects external knowledge, actions, observations, and verifier outcomes to produce agentic trajectories averaging 45K tokens.
Based on these, Agents-A1 is trained in three stages:
Full-domain supervised fine-tuning to align the base model with broad agentic behaviors
Domain-level teacher models to capture specialized skills in each domain
Multi-teacher domain-routed on-policy distillation to improve knowledge transfer efficiency across different domains and combine six different domains into a single deployable student model
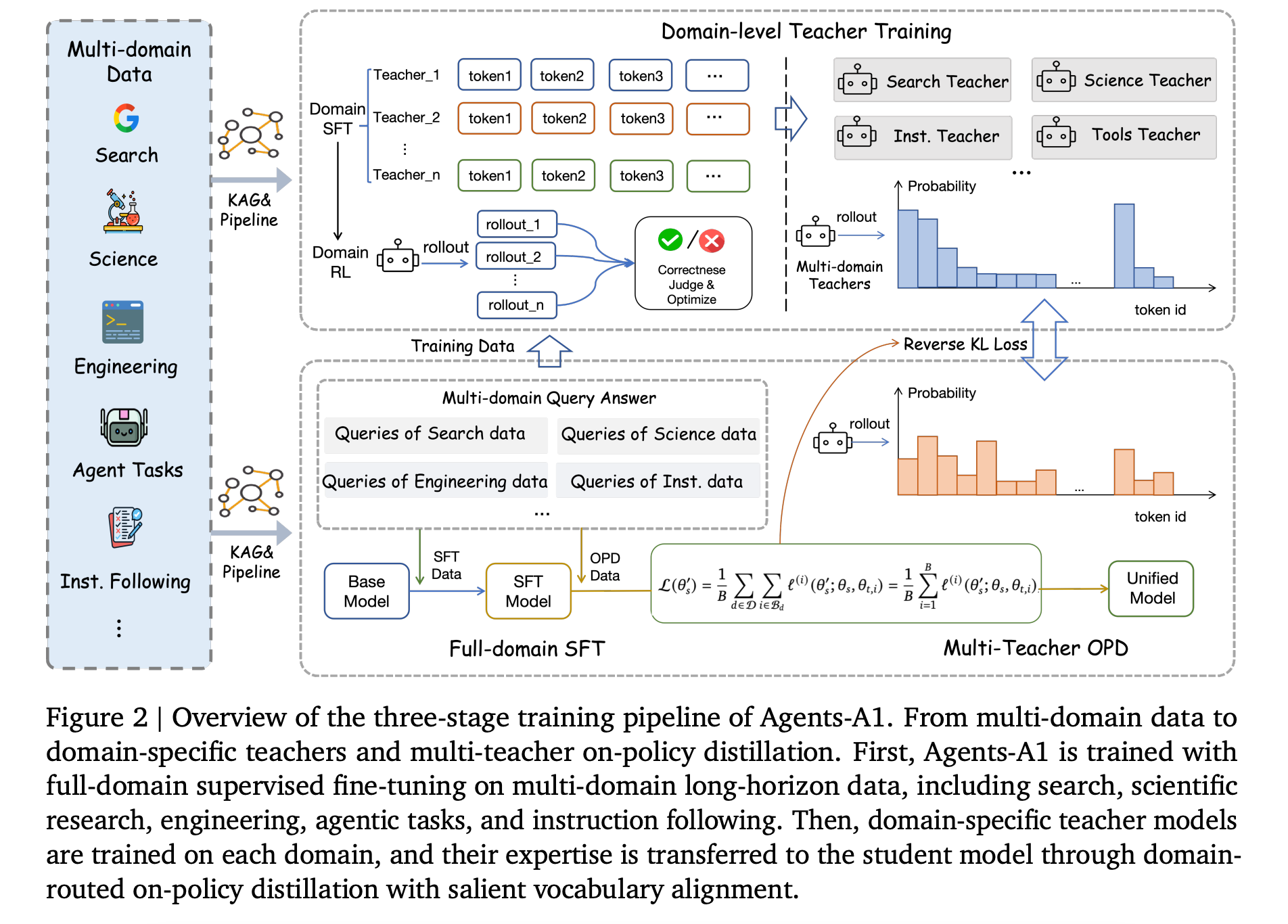
The resulting model achieves strong performance on long-horizon agent benchmarks compared with 1T-parameter models such as Kimi-K2.6 and DeepSeek-V4-Pro.

Read more about this research using this link.
This newsletter edition is completely free to read. Show your love by liking it, restacking it, and sharing it with others! ❤️