

🗓️ This Week In AI Research (28th Dec 25 to 3rd Jan 26)
The top 10(+1) AI research papers that you must know about this week.

Before we begin, I wanted to give a quick update that the subscription pricing for Into AI will double starting next week.
However, if you act before this week ends, you can still secure the existing annual rate of just $50 for access to valuable posts from the newsletter about everything in AI to keep you ahead of the curve.
For anyone who’s been considering becoming a paid subscriber, don’t miss out on locking in this rate.
1. mHC: Manifold-Constrained Hyper-Connections
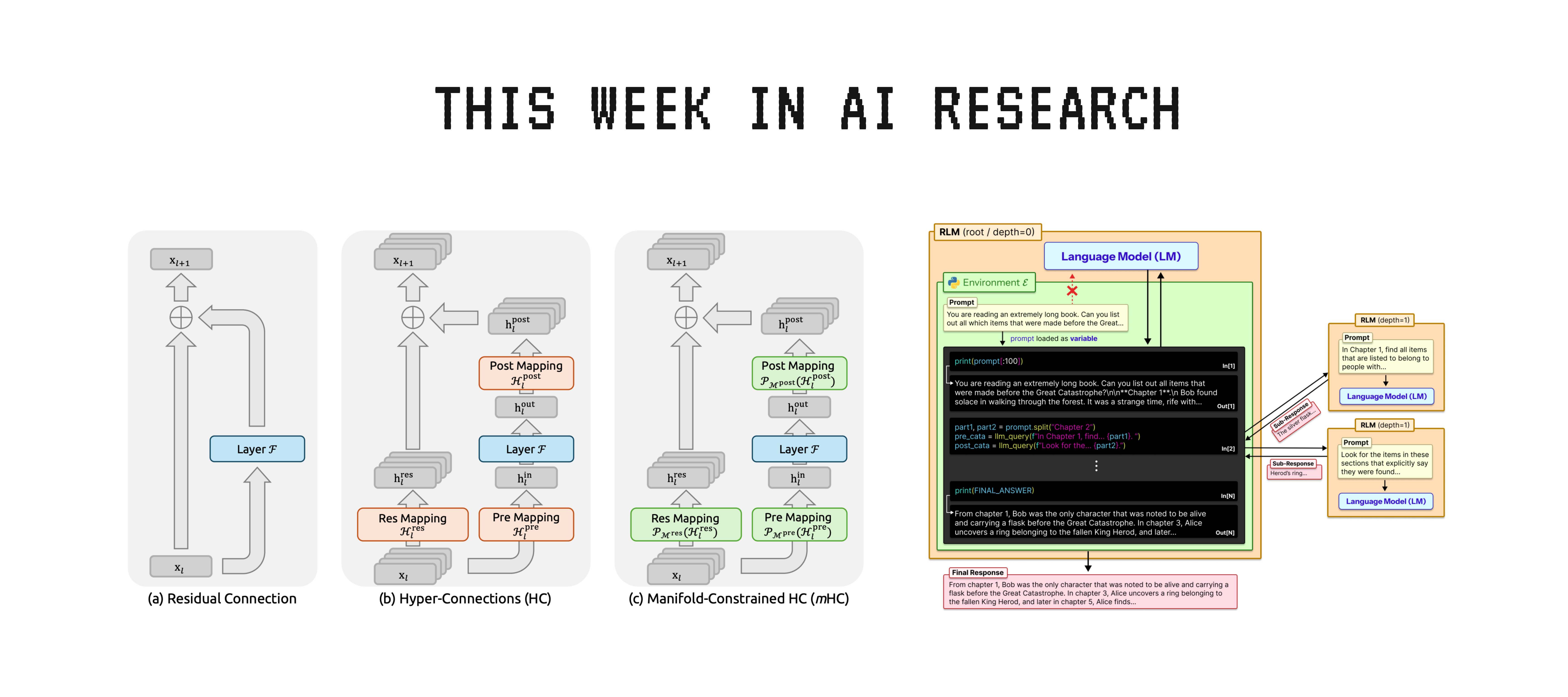
This paper from DeepSeek proposes Manifold-Constrained Hyper-Connections (mHC), an improved version of Hyper-Connections that is much more stable and efficient.
Although Hyper-Connections significantly improve the performance of neural networks through the introduction of increased connectivity in the residual paths, they disrupt the identity mapping that is responsible for the ease of training of residual networks.
mHC addresses this problem by mapping the increased residual space onto a manifold such that the identity mapping is preserved.
Empirical experiments show that mHC is effective for large-scale training, providing clear performance gains and better scalability.
Read more about this research using this link.
2. Recursive Language Models
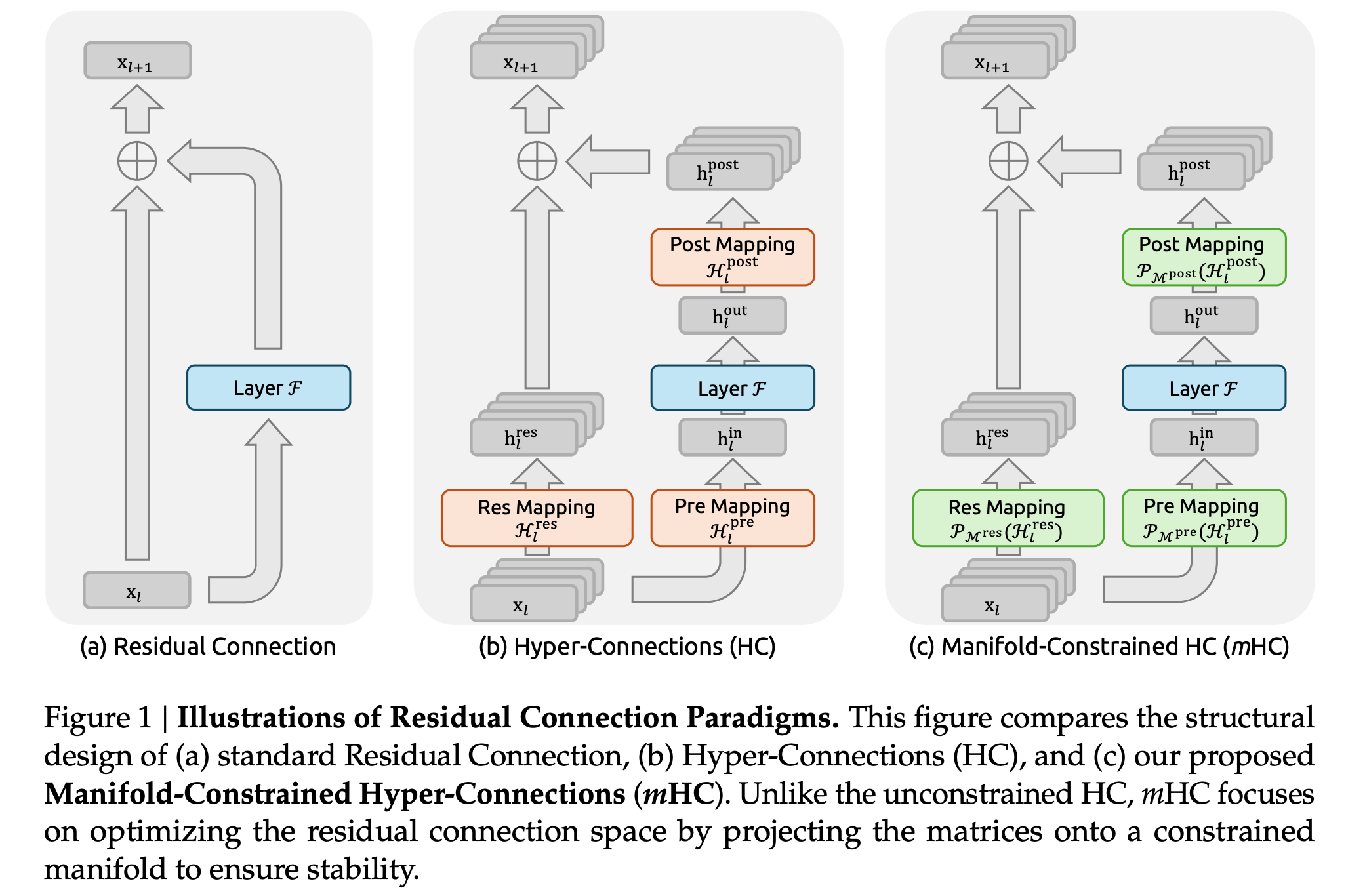
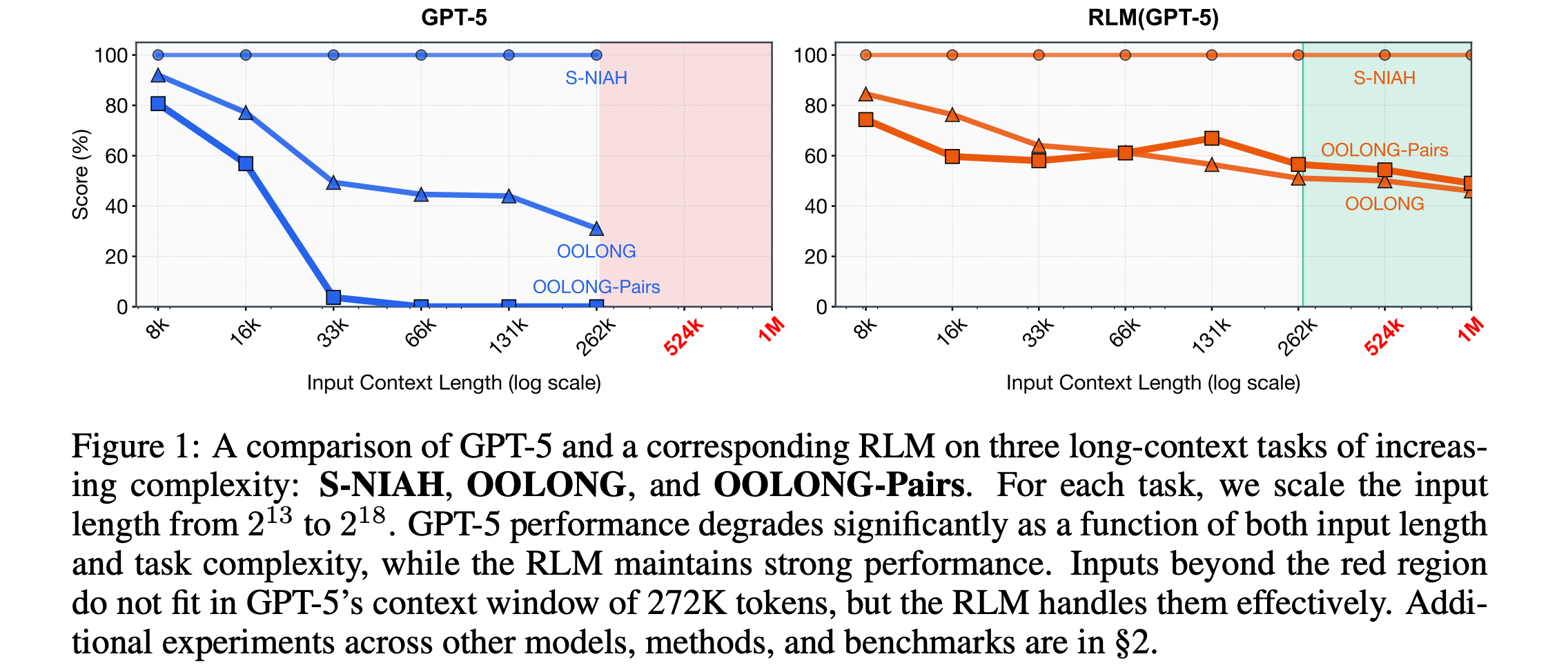
This research paper from MIT presents Recursive Language Models, a method that enables LLMs to handle extremely long prompts during inference without the need to increase their context window.
Instead of processing the entire input at once, the model treats long prompts as an external environment, allowing it to programmatically examine, decompose, and recursively call itself on snippets of the prompt.
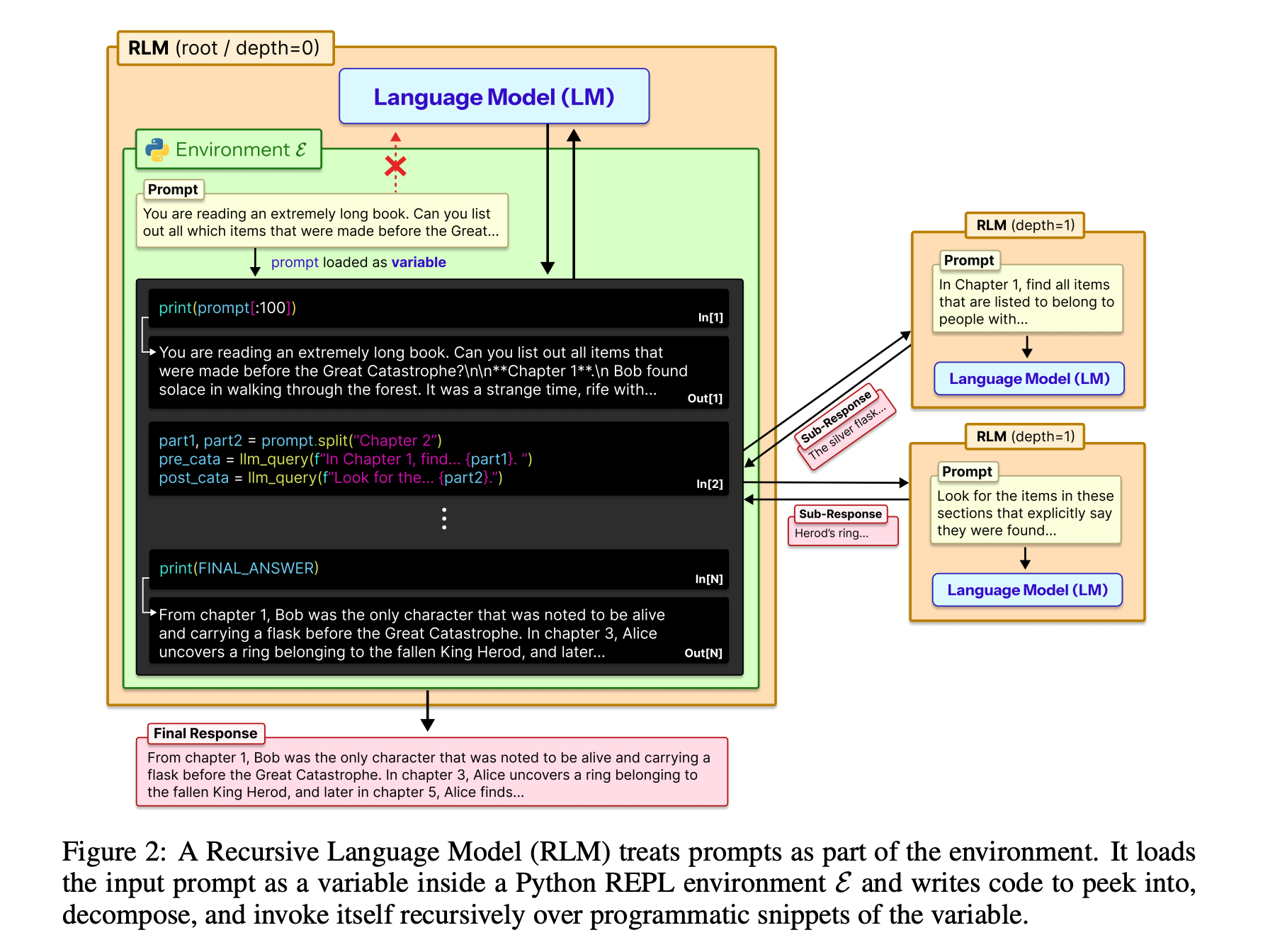
This approach allows LLMs to process inputs up to 100 times longer than their usual context length, significantly enhancing performance on long-context tasks and surpassing previous methods at similar or lower inference costs.
Read more about this research paper using this link.
3. Scaling Open-Ended Reasoning To Predict the Future
This research paper explores how LLMs can be used for forecasting in high-stakes and uncertain decision-making contexts.
It introduces OpenForesight, a large synthetic dataset composed of open-ended forecasting questions derived from historical news.
The authors develop Qwen3 thinking models that use retrieval and reinforcement learning with an improved reward function, while carefully avoiding future information leakage by relying solely on an offline news corpus.
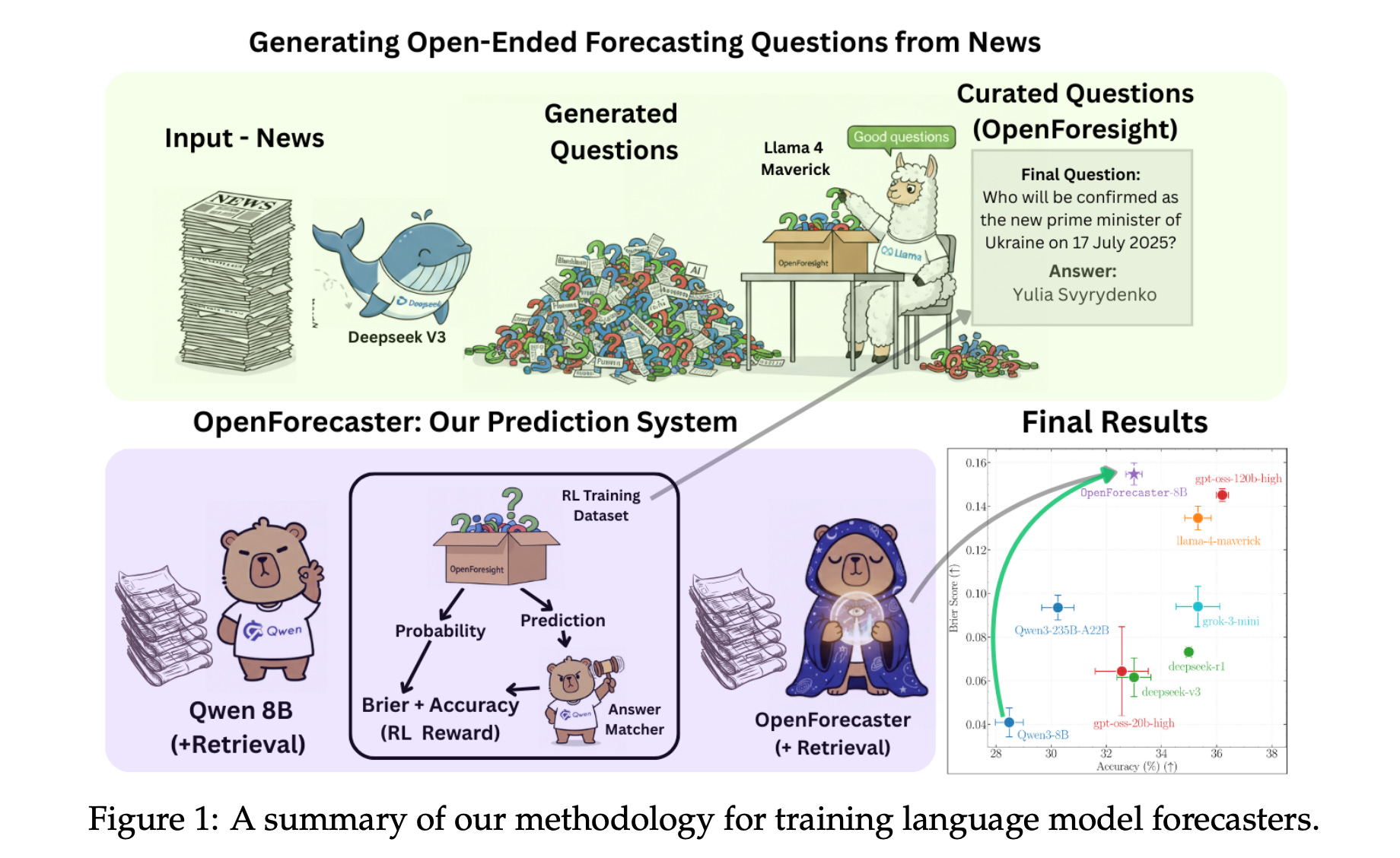
In held-out testing, their specialized model, OpenForecaster-8B, matches the performance of much larger proprietary systems, showing enhancements in accuracy, calibration, and consistency across different benchmarks.
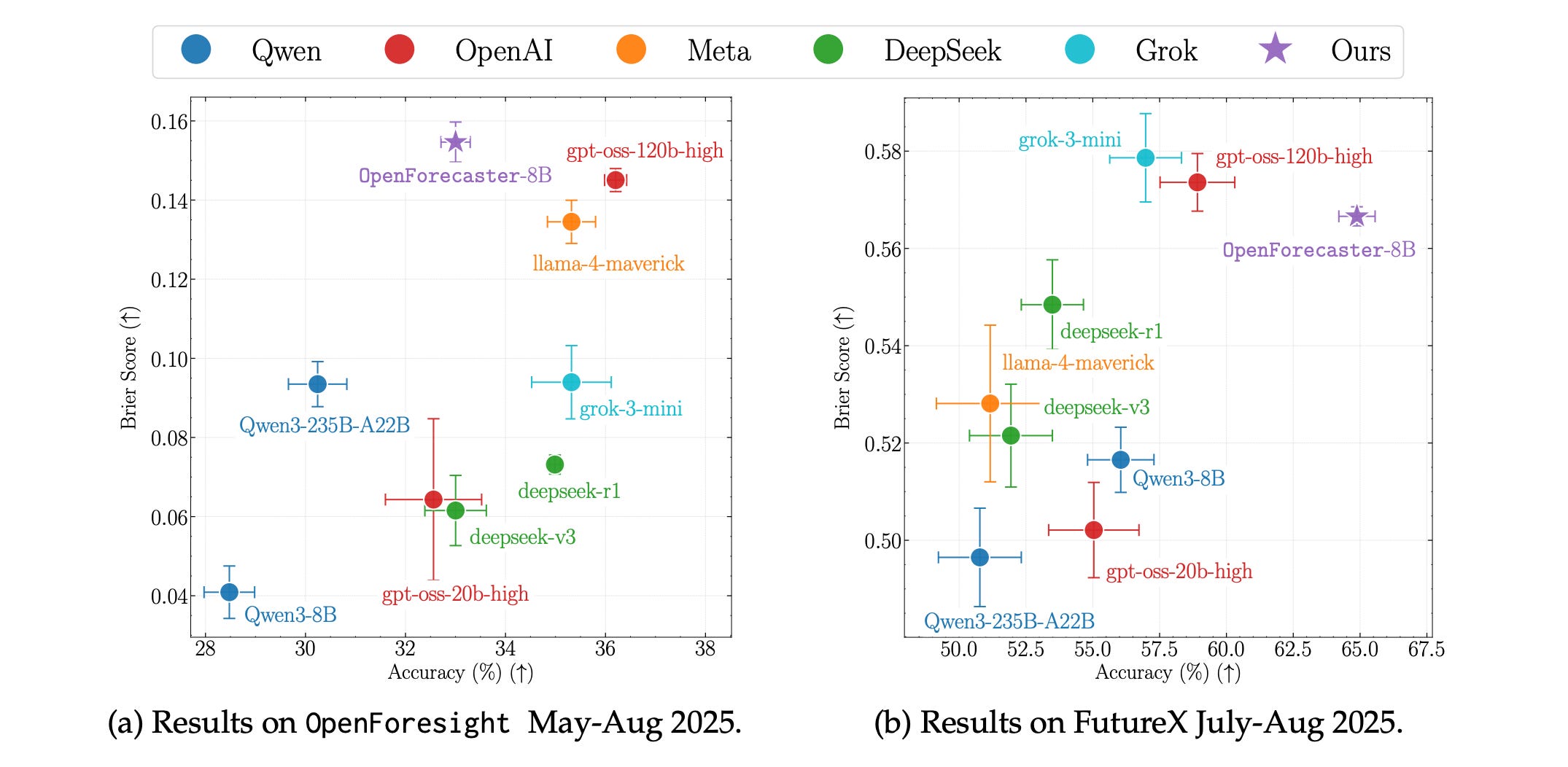
Read more about this research using this link.
A short pause: I want to introduce you to the Visual Tech Bundle.
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books.
This includes Dharmesh Shah, the co-founder and CEO of HubSpot.
Why not give them a try?
4. IQuest Coder Technical Report
This research paper introduces IQuest-Coder-V1, a family of open-weight code-language models trained using a code-flow multi-stage training approach that reflects how software evolves over time, rather than treating code as static text.
The training process combines large-scale pretraining, extended-context mid-training (up to 128,000 tokens) with reasoning and agentic pathways, and a split post-training phase into Thinking (reinforcement learning-based reasoning) and Instruct variants.
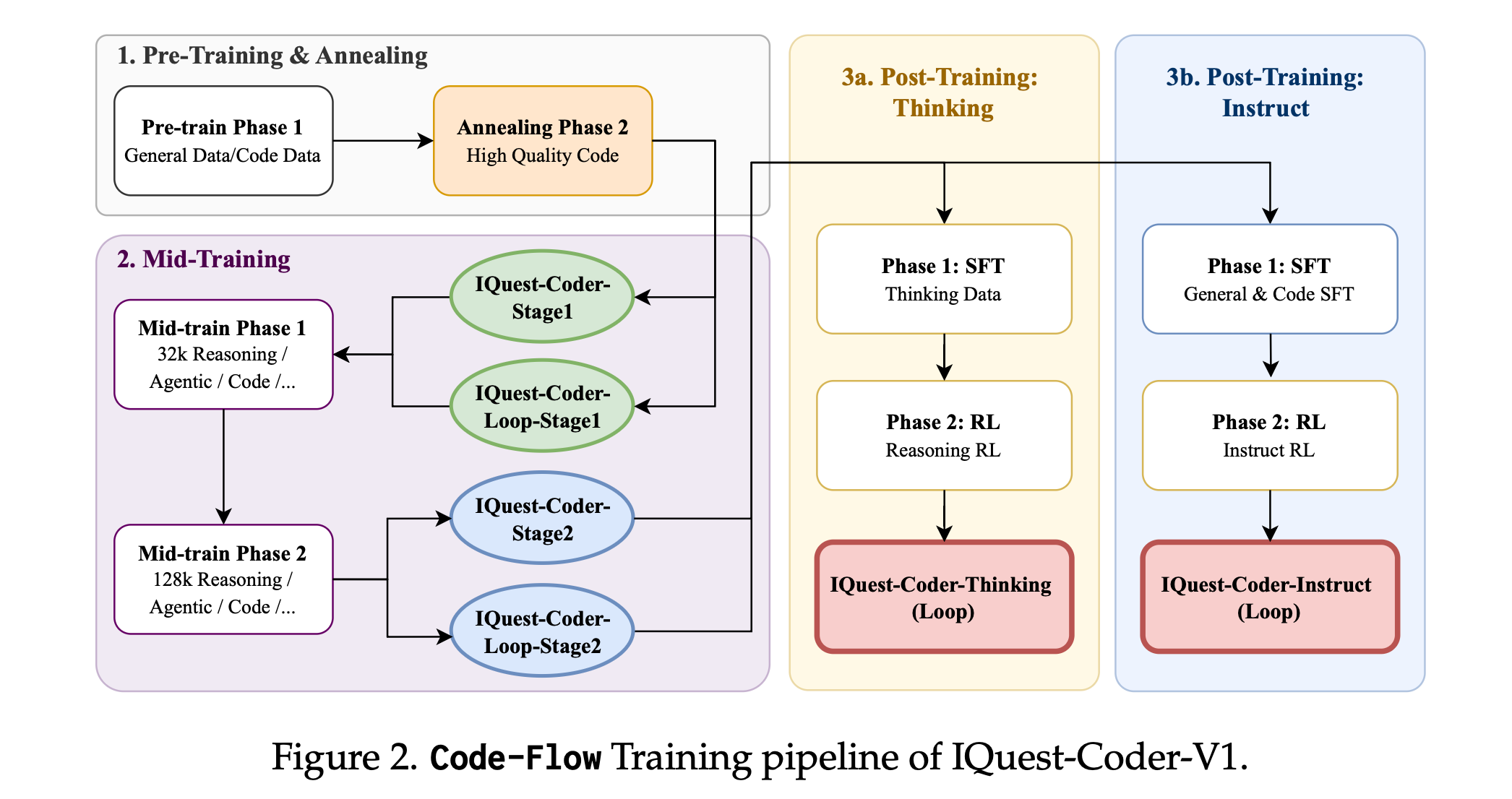
A notable architectural innovation includes LoopCoder, a recurrent transformer that enhances reasoning depth while reducing deployment costs.
Across benchmarks like SWE-Bench, LiveCodeBench, and real-world agentic coding tasks, IQuest-Coder-V1 ranks among the best open models and comes close to proprietary systems, showing strong scalability and practical software engineering abilities.
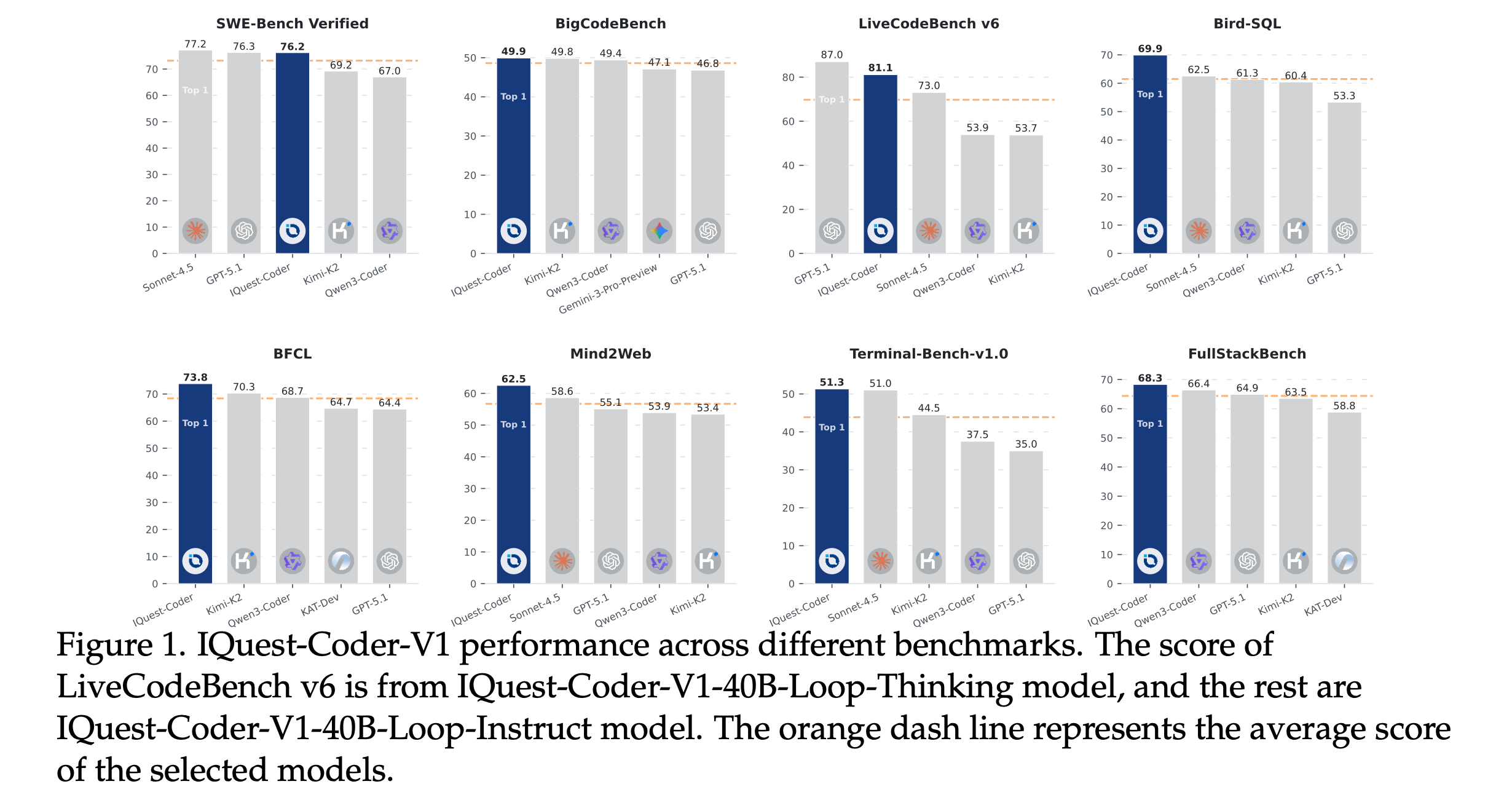
Read more about this research paper using this link.
5. SeedFold: Scaling Biomolecular Structure Prediction
This research paper from ByteDance introduces SeedFold, a scalable biomolecular structure prediction model.
The authors of the research paper:
Identify an effective width-scaling strategy for the Pairformer architecture
Introduce a linear-time triangular attention mechanism to reduce computational cost
Build a large-scale distillation dataset to expand training data
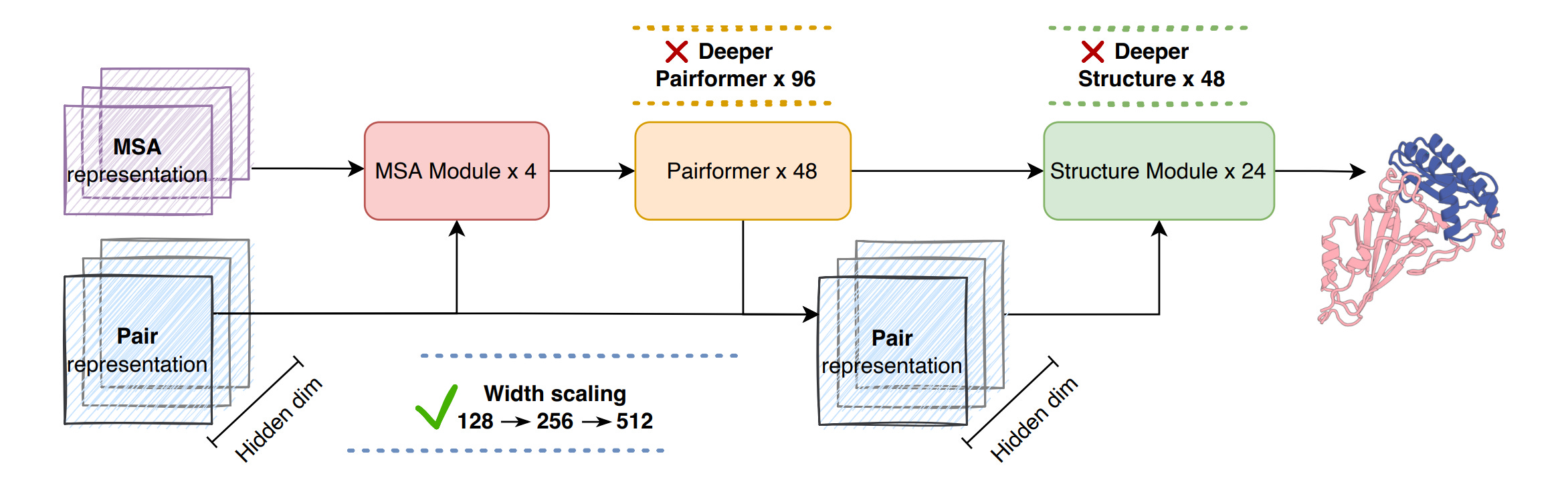
Together, these three advances allow SeedFold to scale efficiently and achieve stronger performance than AlphaFold3 on most protein-related tasks in the FoldBench benchmark.
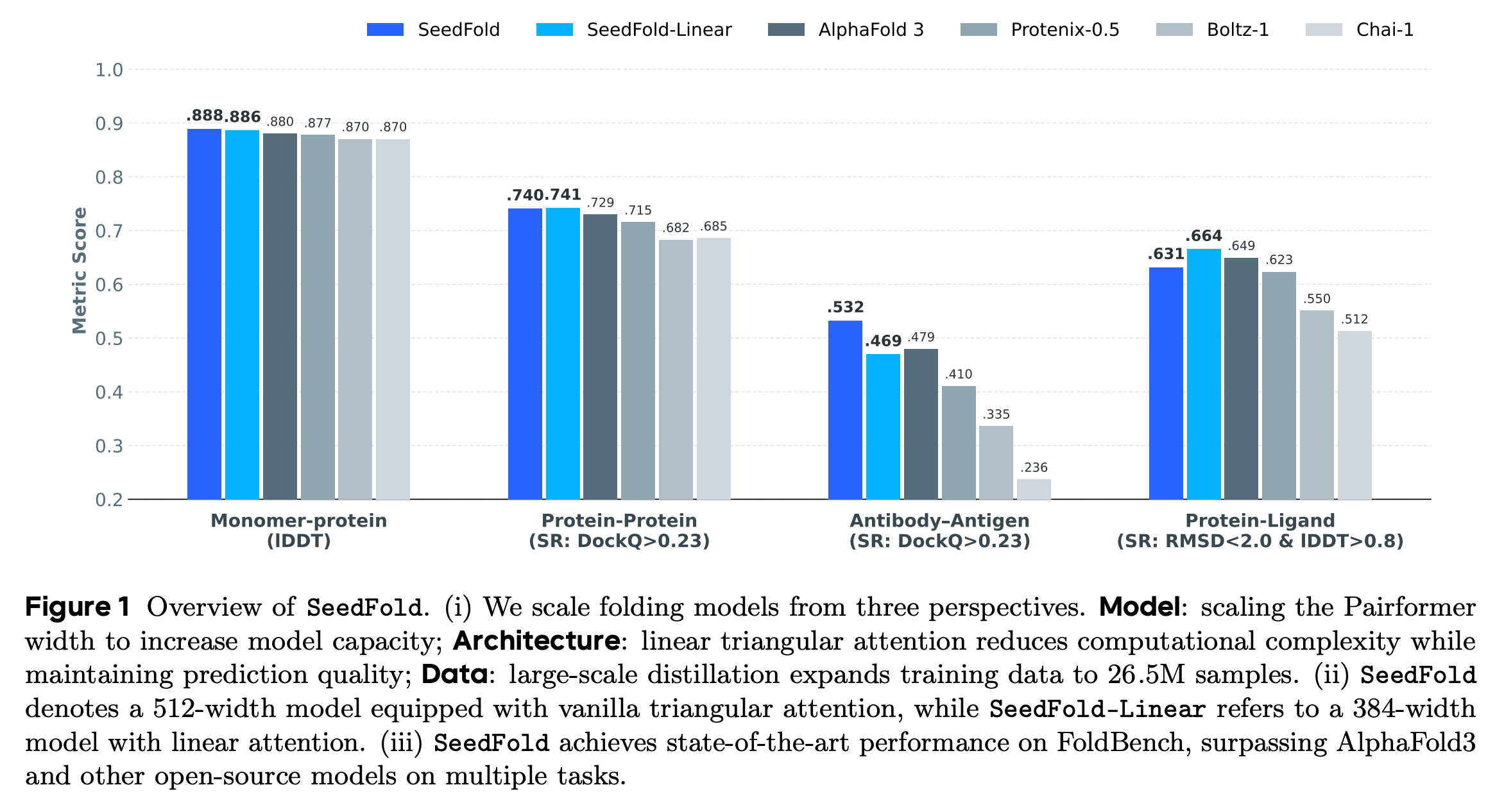
Read more about this research paper using this link.
6.SeedProteo: Accurate De Novo All-Atom Design of Protein Binders
This research paper from ByteDance introduces SeedProteo, a diffusion-based model for de novo all-atom protein design.
The model is built by adapting a state-of-the-art folding architecture into a generative design framework with effective self-conditioning.
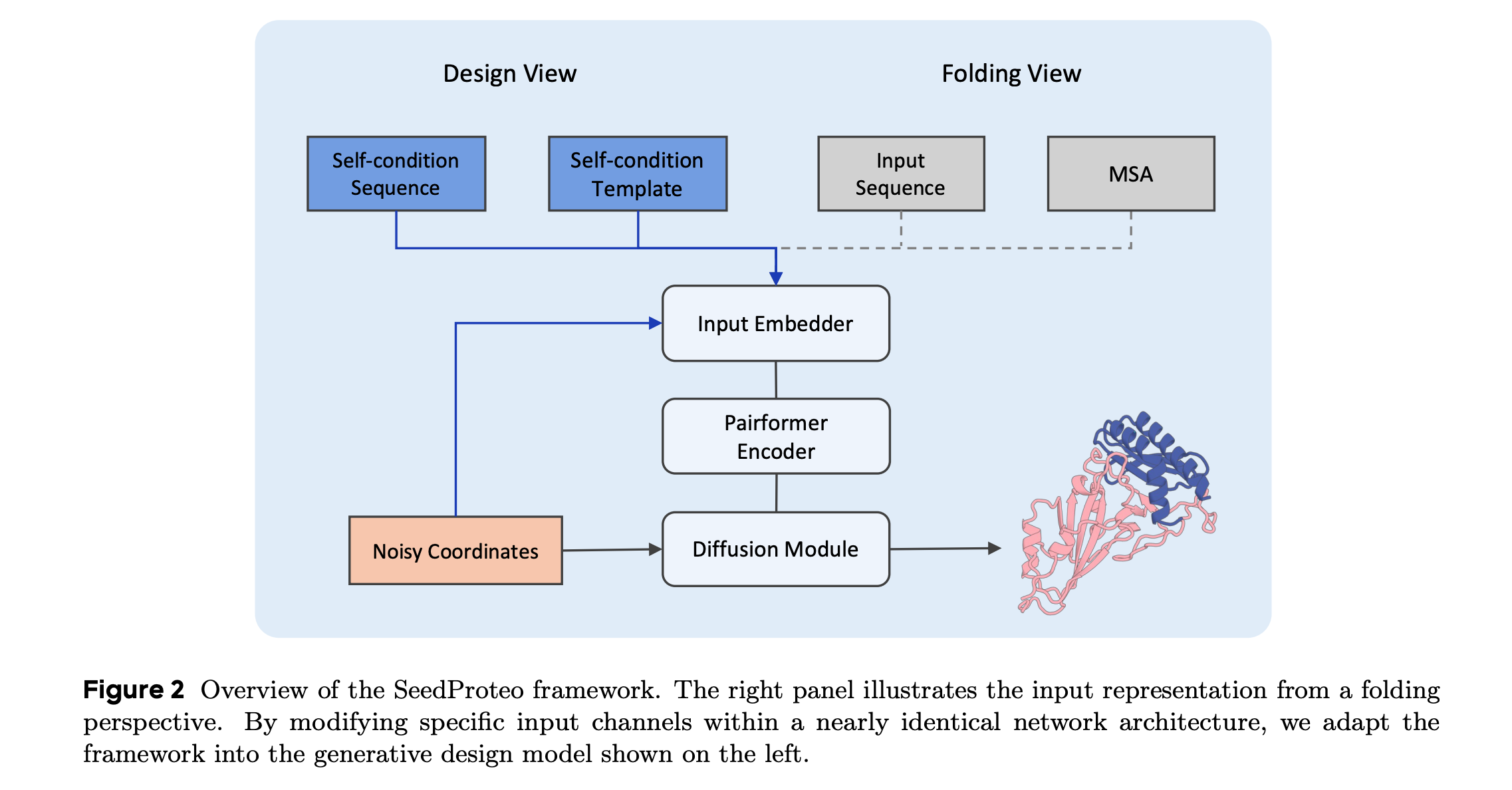
In benchmarks, SeedProteo excels at unconditional generation, generalizing much better to long sequences and producing more complex, structurally diversified proteins.
For binder design, it achieves state-of-the-art results amongst open-source methods, including top in-silico success rates, structural diversity, and novelty.
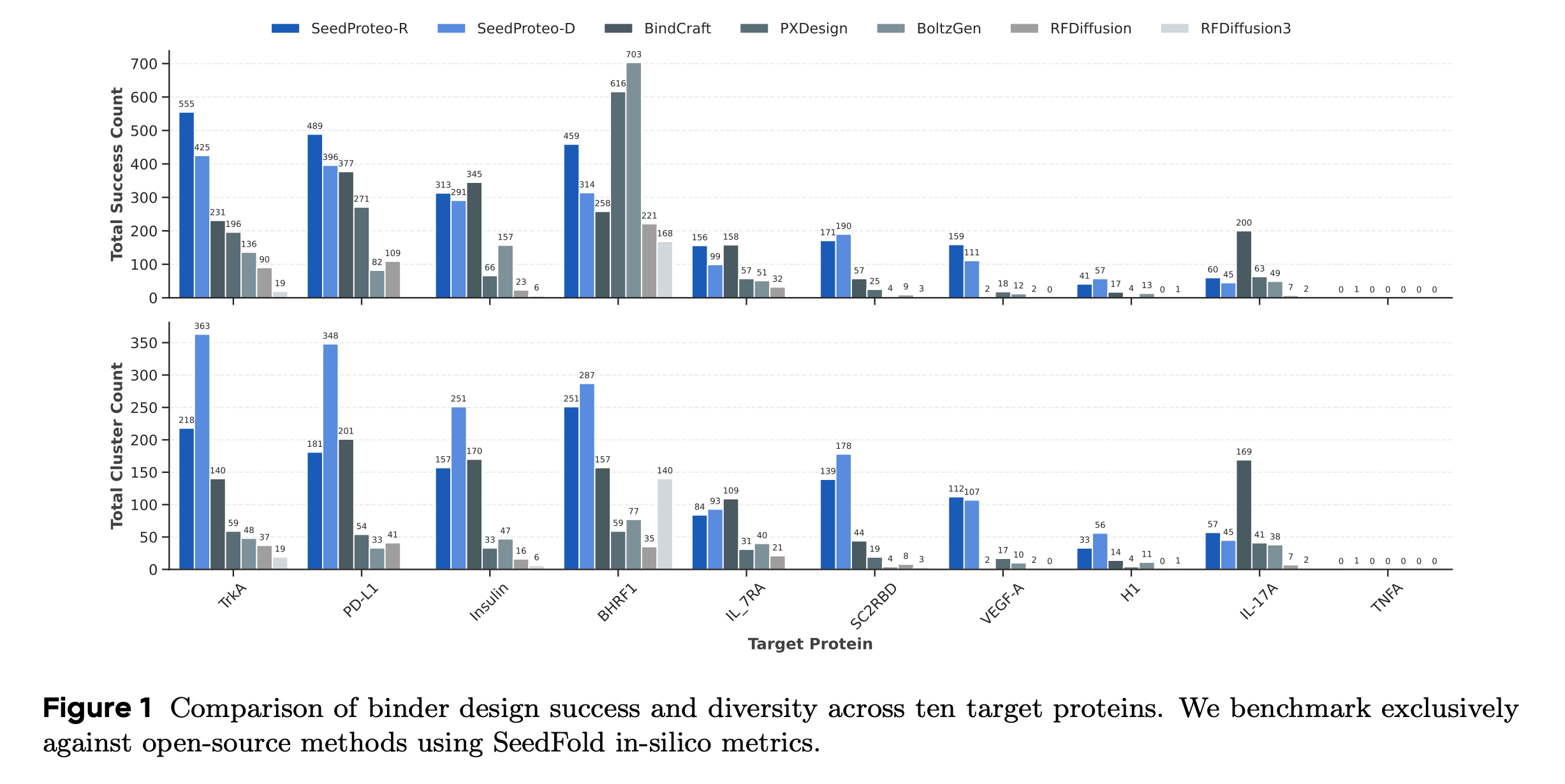
Read more about this research paper using this link.
7. Nested Learning: The Illusion of Deep Learning Architecture
This research paper from Google Research presents Nested Learning (NL), a new learning framework that views a machine learning model as a set of nested or multi-level optimization problems, each with its own context and update frequency.
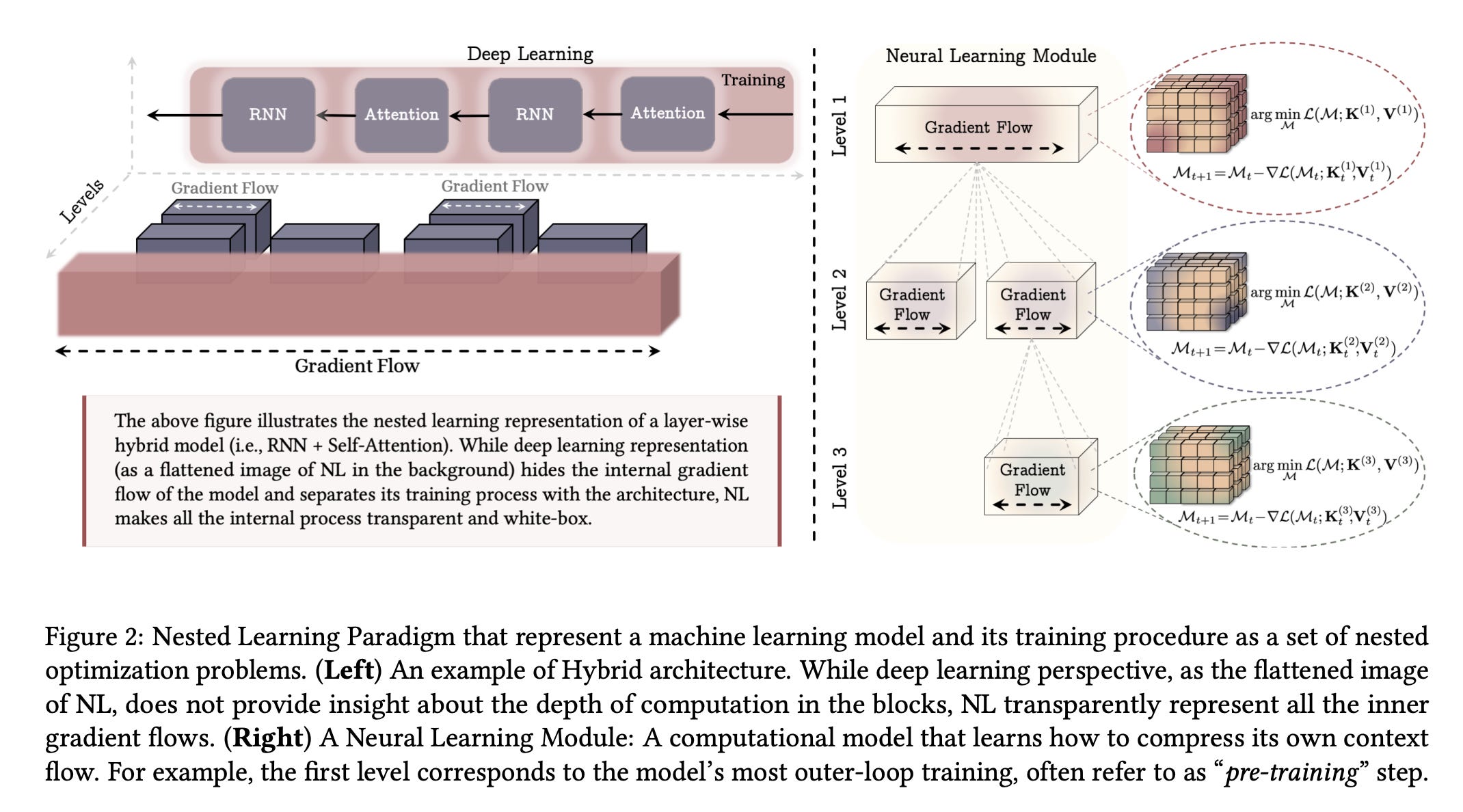
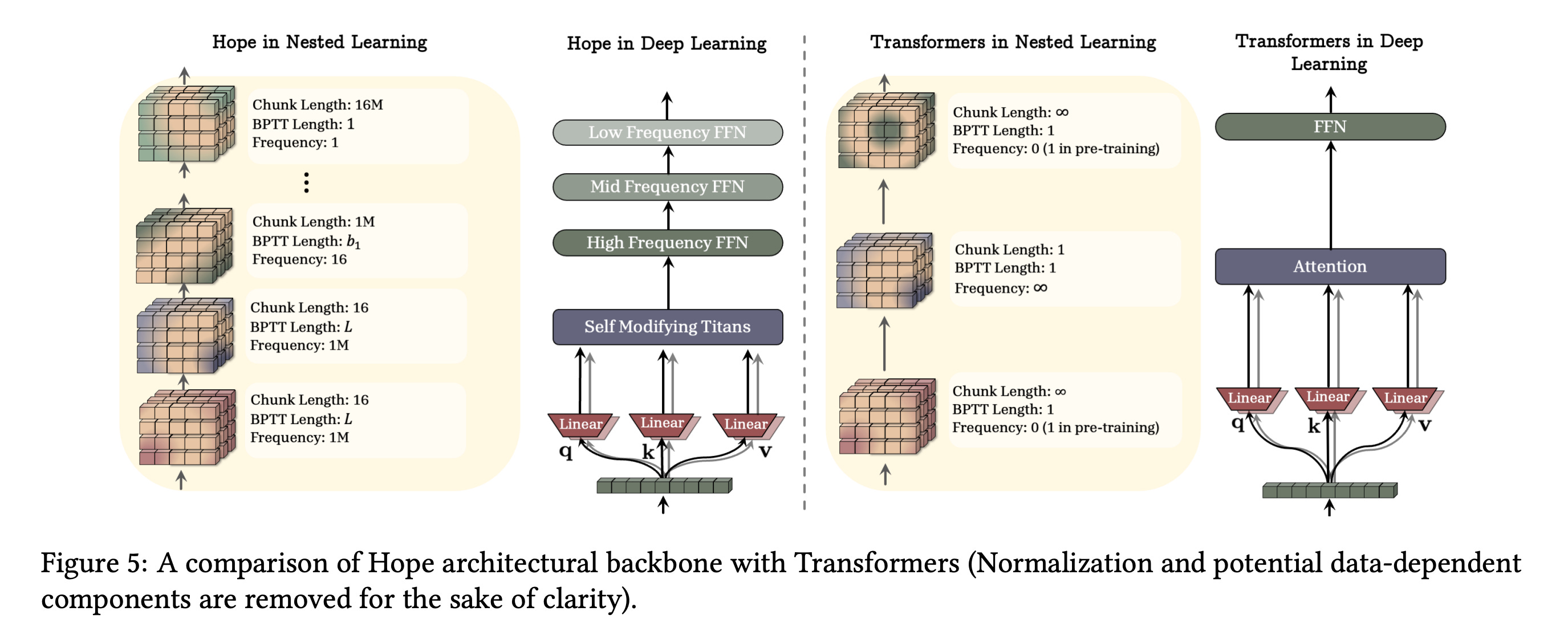
Building on this idea, the authors show that:
Common optimizers like SGD and Adam act as associative memory modules
Propose more expressive optimizers with deeper memory
Introduce a self-modifying learning module that learns its own update rules
Present a continuum memory system that generalizes the traditional viewpoint of long-term/short-term memory
Together, these ideas form HOPE, a continual learning module that shows promising results in language modeling, knowledge integration, few-shot generalization, continual learning, and long-context reasoning.
Read more about this research paper using this link.
8. Modeling Language as a Sequence of Thoughts
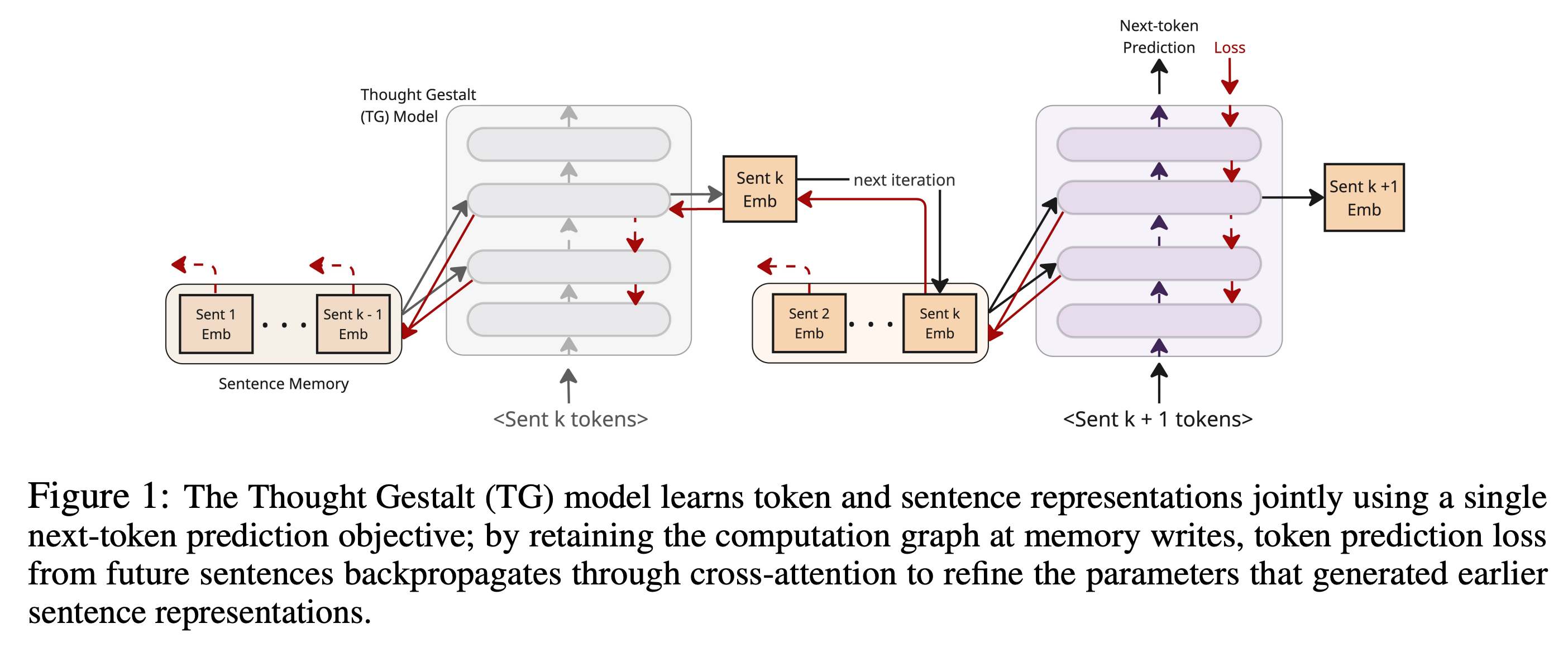
This research paper introduces the Thought Gestalt (TG) model, a recurrent Transformer that models language at two levels of abstraction: tokens and sentence-level “thought” states.
Instead of treating text as a flat stream of tokens, TG generates one sentence at a time while maintaining a memory of compact sentence representations that persist across context, closer to how humans track events.
Shared parameters between token and sentence-level representations allow jointly training both with a single next-token objective, enabling backpropagation to refine earlier sentence states from future tokens.
Experiments show that TG is more data- and parameter-efficient than GPT-2, achieving the same loss with less data and fewer parameters. It also reduces relational errors, such as the reversal curse, thereby improving global consistency in language understanding.
Read more about this research paper using this link.
9. Fantastic Reasoning Behaviors and Where to Find Them
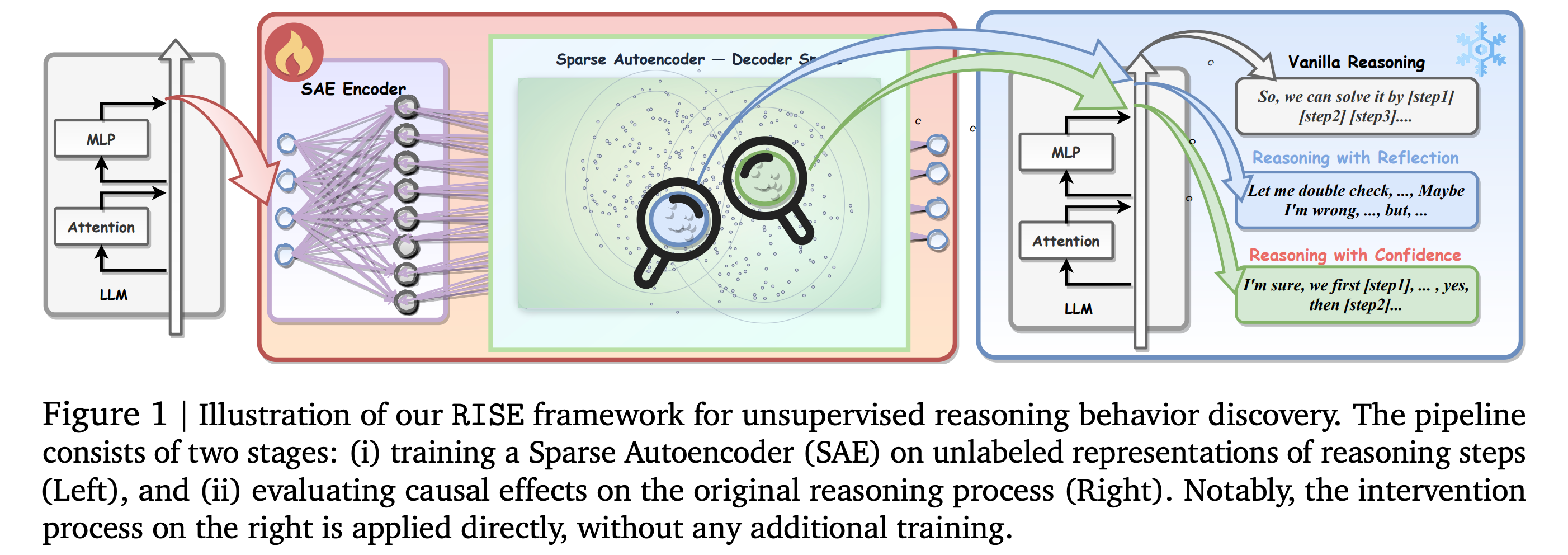
This research paper from Google DeepMind presents RISE (Reasoning behavior Interpretability via Sparse auto-Encoder), an unsupervised method for understanding how LLMs reason internally.
RISE identifies chain-of-thought reasoning steps at the sentence level and uses their activations to learn sparse autoencoders that identify reasoning vectors (directions in the activation space corresponding to reasoning behaviors) for reflection, backtracking, response length, and confidence.
It shows that these reasoning patterns lie in separable regions in latent space, which can be controlled directly during inference by strengthening or dampening individual vectors, without requiring model retraining.
Read more about this research paper using this link.
10. Evaluating Parameter-Efficient Methods for RLVR
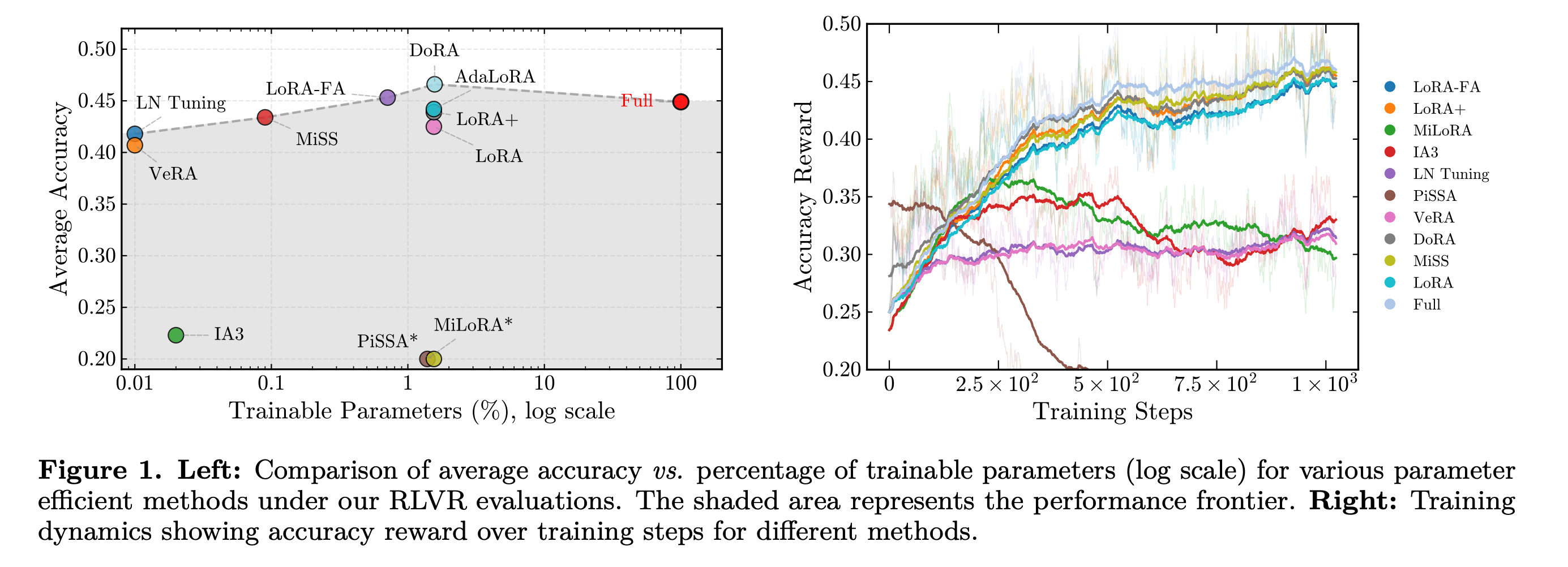
This paper presents the first large-scale study of parameter-efficient fine-tuning (PEFT) methods under Reinforcement Learning with Verifiable Rewards (RLVR).
Evaluating more than a dozen PEFT approaches on DeepSeek-R1-Distill models for mathematical reasoning, the authors show that standard LoRA is not optimal, while structural variants such as DoRA, AdaLoRA, and MiSS consistently perform better than it.
The researchers also identify a spectral collapse issue that causes SVD-based initialization methods (e.g., PiSSA, MiLoRA) to fail under RL, and find that aggressive parameter reduction (e.g., in VeRA, Rank-1) severely limits reasoning capacity.
Read more about this research paper using this link.
Notable Mention: GLM-4.7: Advancing the Coding Capability
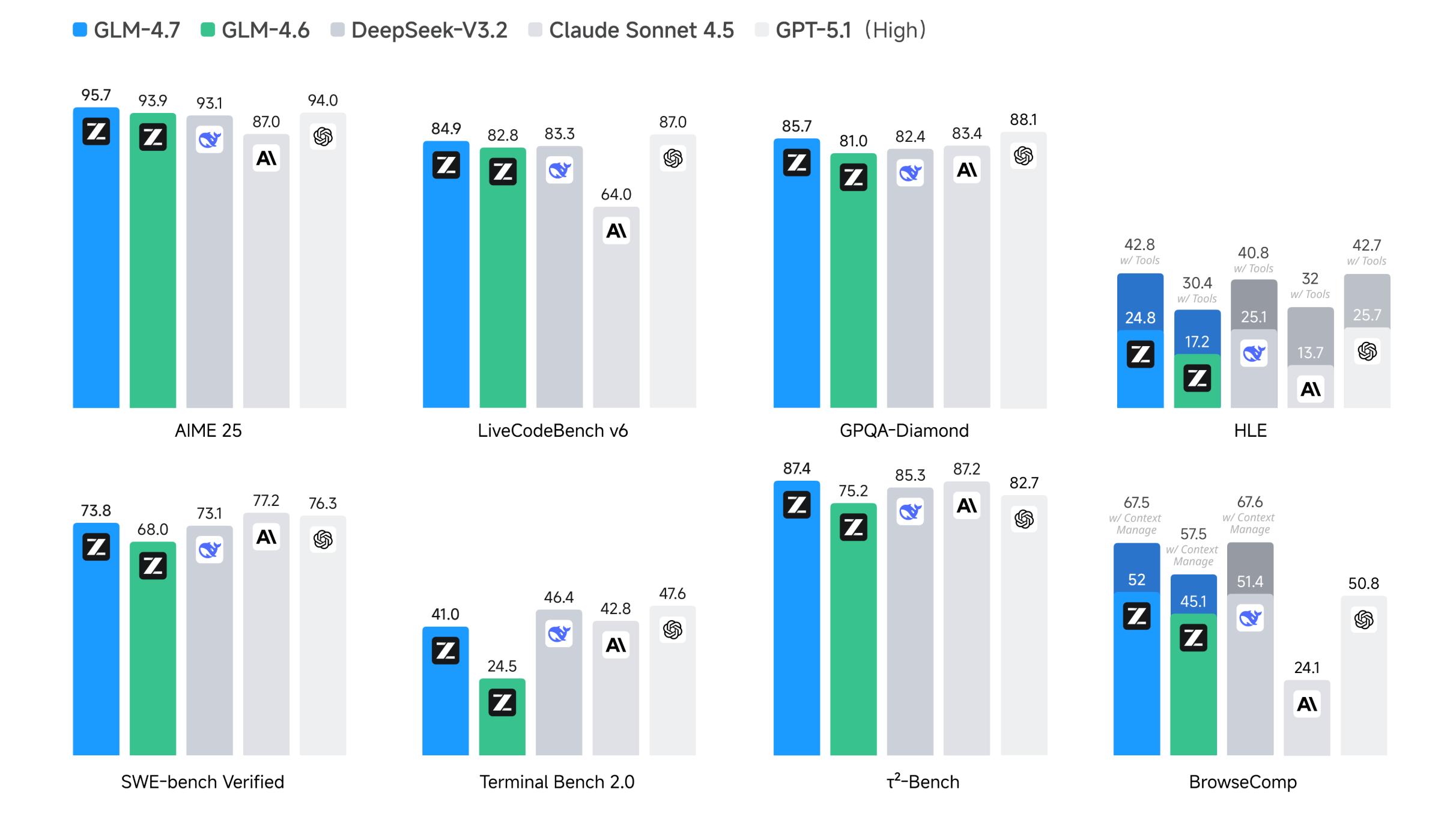
GLM-4.7 is Z.ai’s latest open-weights flagship language model, improving on GLM-4.6 with stronger reasoning, coding, and agentic abilities.
It performs better on multiple software engineering and tool-use benchmarks, and is more reliable on long, multi-step problems.
GLM-4.7 also introduces improved thinking modes for more consistent multi-turn reasoning and supports a 200 K token context window with up to 128 K output tokens for extended conversations and workflows.
Read more about this research paper using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
If you want to get even more value from this publication, become a paid subscriber and unlock all posts, such as:



You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
