

Latent Mixture-of-Experts (Latent MoE), Clearly Explained
A lesson on the Latent Mixture-of-Experts (MoE) architecture that powers NVIDIA’s Nemotron-3 and Microsoft's MAI-Thinking-1.

Latent Mixture-of-Experts is increasingly becoming the preferred architecture for powerful LLMs.
It was adapted in NVIDIA’s Nemotron-3 Super and Ultra models, and now Microsoft has built its first in-house reasoning model, called MAI-Thinking-1, using it. All of these models have reported meaningful gains in accuracy without sacrificing inference throughput or latency using this architecture.
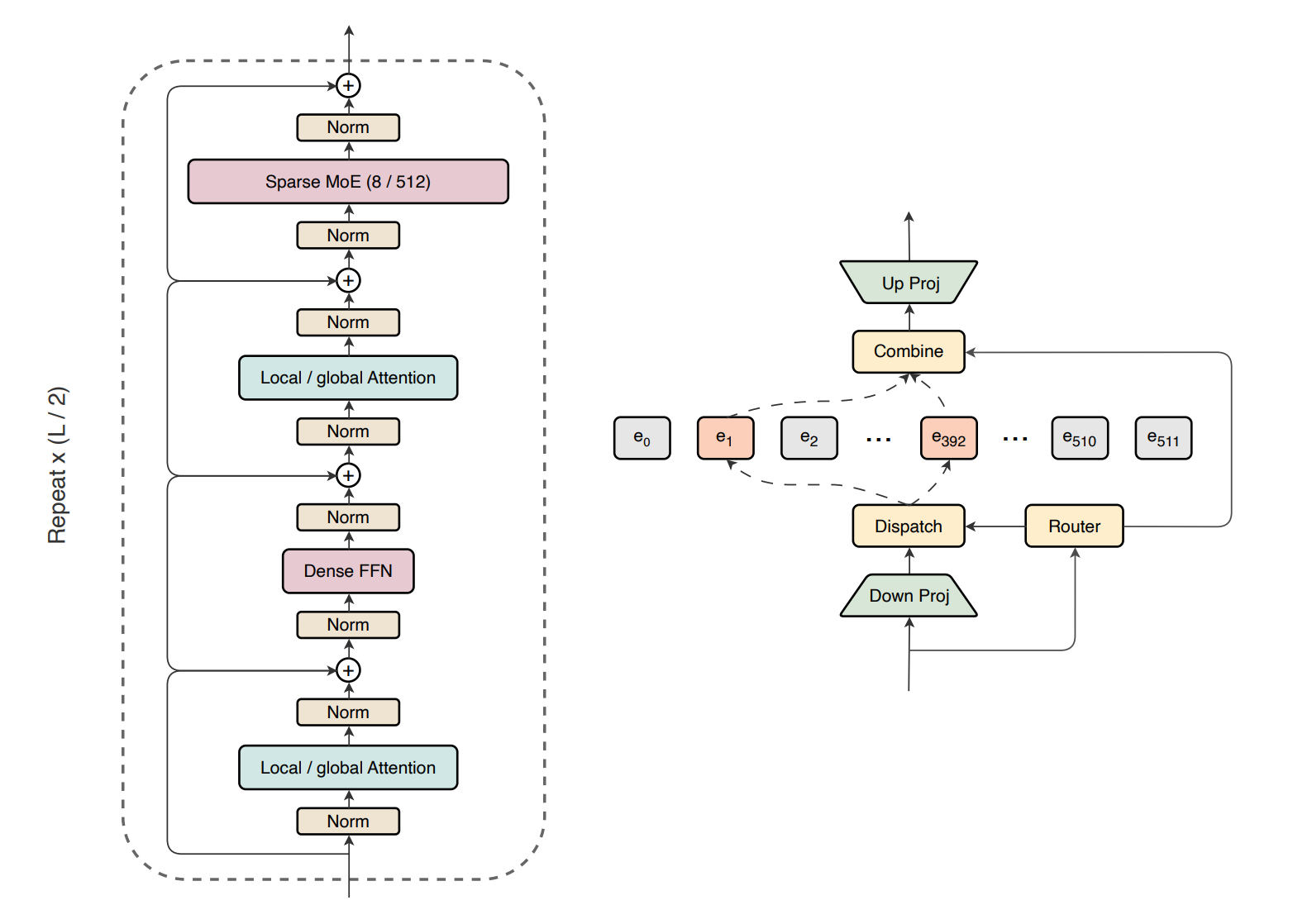
Latent Mixture-of-Experts is an improvement over the popular Mixture-of-Experts (MoE) architecture. Let’s build our foundations by understanding the MoE architecture in depth before we learn about Latent MoE.
What is the MoE architecture?
LLMs based on the Mixture-of-Experts (MoE) architecture contain multiple small feed-forward networks (called Experts) instead of a conventional large feed-forward network in their Transformers. These experts handle different tokens by using another network, called a Router, that selects which expert to use for each token.
MoE enables LLMs to scale their parameter count while keeping the compute cost, or the number of Floating-point Operations (FLOPs) per token, fixed. This is because each token is not processed by all experts in the model as in conventional dense LLMs.
In an MoE LLM with ‘N’ experts, the router directs each token towards only the top-K selected experts, so the active parameter count (which determines FLOPs) stays fixed while the total parameter count of the model (which stores knowledge) can grow enormously.
A great example of an MoE LLM is DeepSeek-V4-Pro, which has 1.6 trillion parameters, but only 49 billion are activated per token during inference.
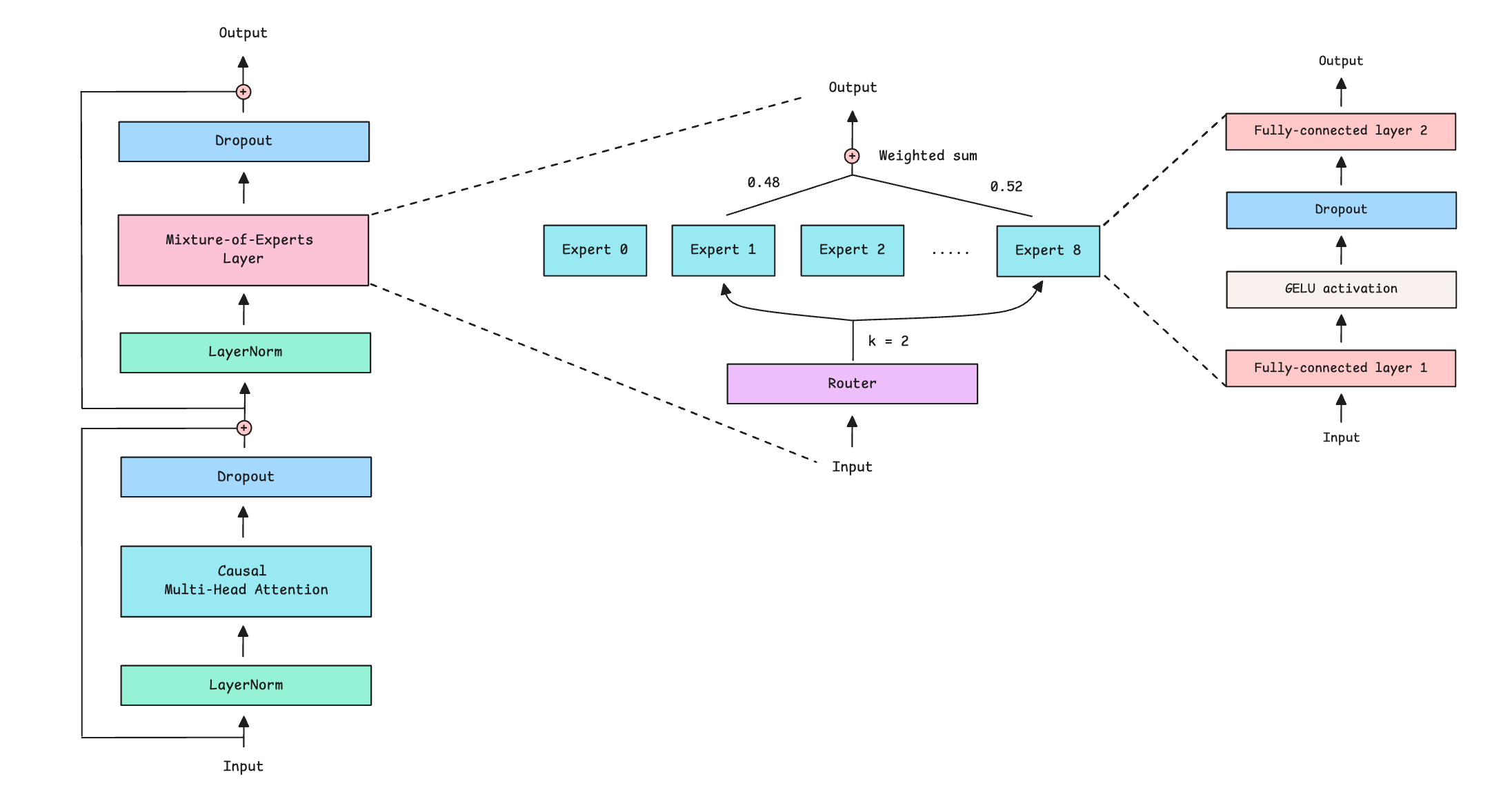
What works best for Mixture-of-Experts models
1. Memory bandwidth is the real bottleneck for small batches
Consider the following Roofline plot, which shows the maximum performance a workload can achieve as a function of its arithmetic intensity (how much computation is performed per byte of data moved in memory). This plot tells where the workload is limited by memory bandwidth or by compute.
It is built using Qwen3-235B-A22B served on NVIDIA GB200 GPUs connected over NVLink.
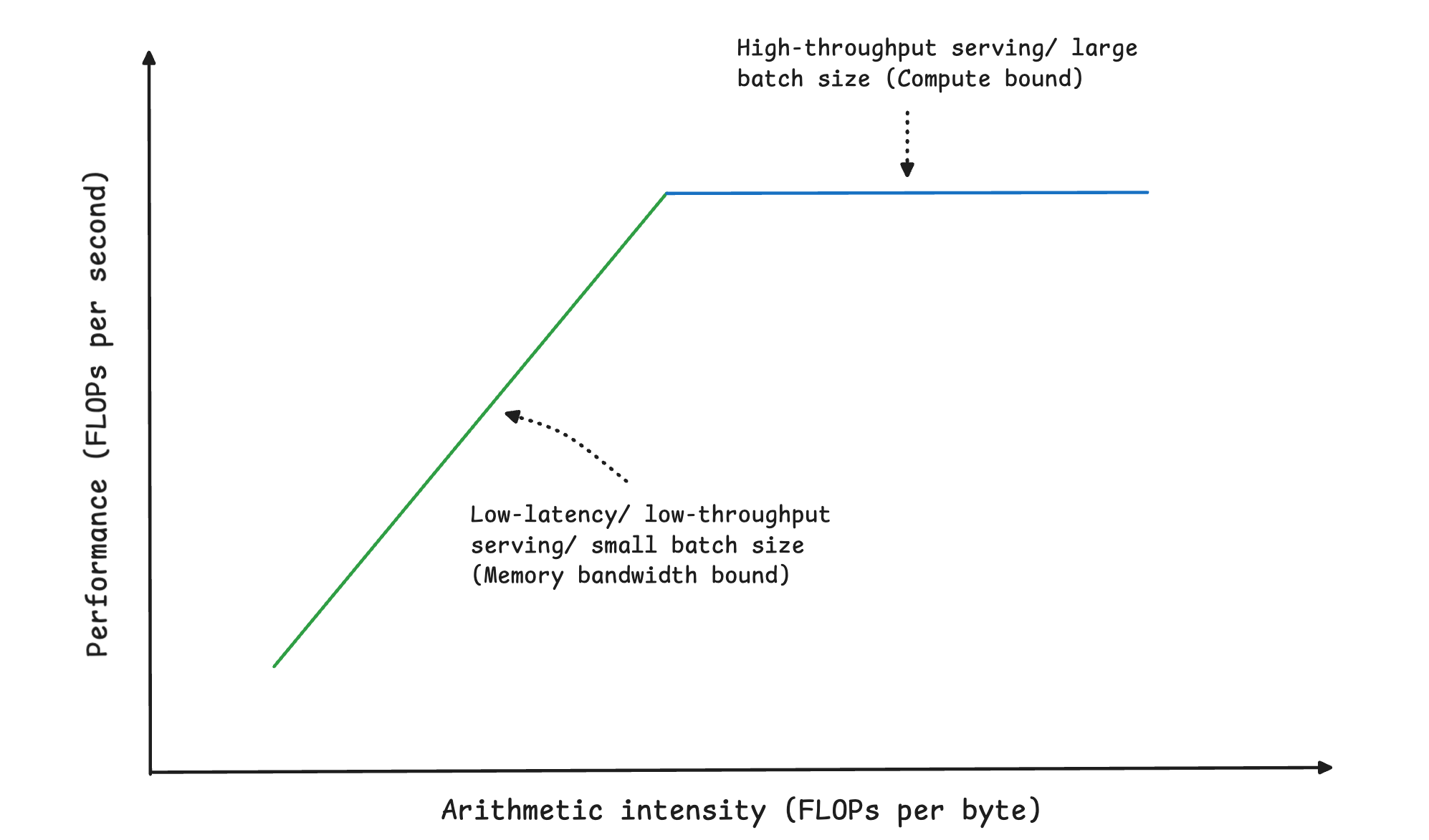
When served in a low-latency setting, such as responding to a small number of requests, often from just one user at a time, the real bottleneck for MoE LLM inference is memory bandwidth rather than compute.
This means that when only a few tokens are being processed by the MoE model, the GPU spends almost all its time loading model parameters from memory rather than performing computations. The GPU compute units sit idle most of the time, waiting for parameters to be loaded.
