

What makes DeekSeek-V4 so good?
If Uber had used DeepSeek-V4 instead of Claude, their 2026 AI budget would have lasted 7 years rather than only 4 months!


DeepSeek recently released the preview of two models in its V4 series:
DeepSeek-V4-Pro with 1.6T parameters (49B activated during inference)
DeepSeek-V4-Flash with 284B parameters (13B activated during inference)
Both models are Mixtures-of-Experts (MoE) models and support a context length of 1 million tokens.
These models use multiple architectural and optimization updates, with the four main ones being:
A new hybrid Attention architecture that uses Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to reduce the memory bottleneck
Manifold-Constrained Hyper-Connections (mHC) to strengthen conventional residual connections, which improve the stability of signal propagation across the layers while preserving model expressivity
Muon Optimizer for faster convergence and greater training stability
These major updates (alongside many others) make these models highly efficient. DeepSeek-V4-Pro requires only 27% of the single-token inference FLOPs and 10% of the KV cache compared with DeepSeek-V3.2.
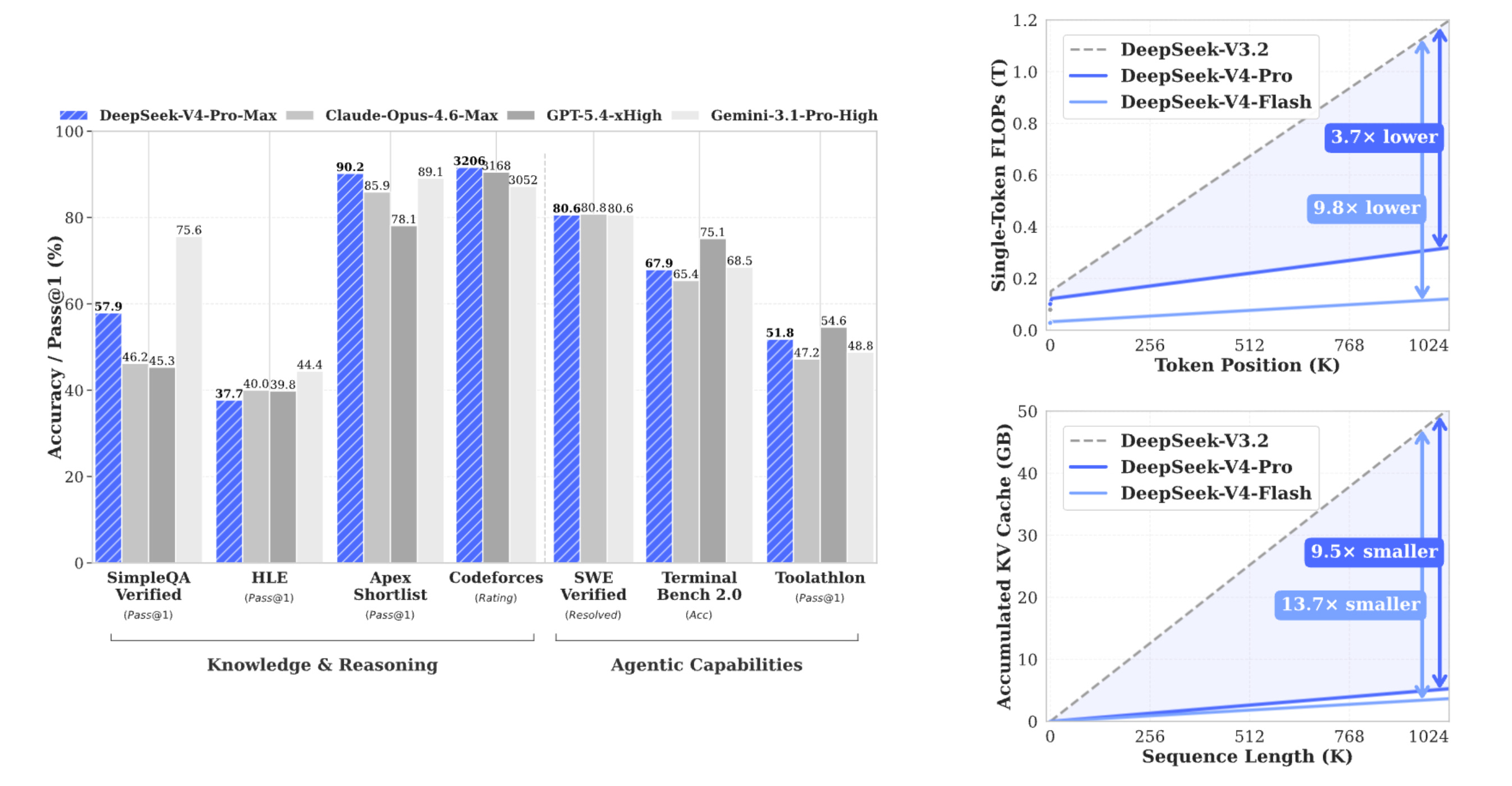
And according to the following post on X, if Uber had used DeepSeek instead of Claude, their 2026 AI budget would have lasted 7 years rather than only 4 months. That’s incredibly efficient!
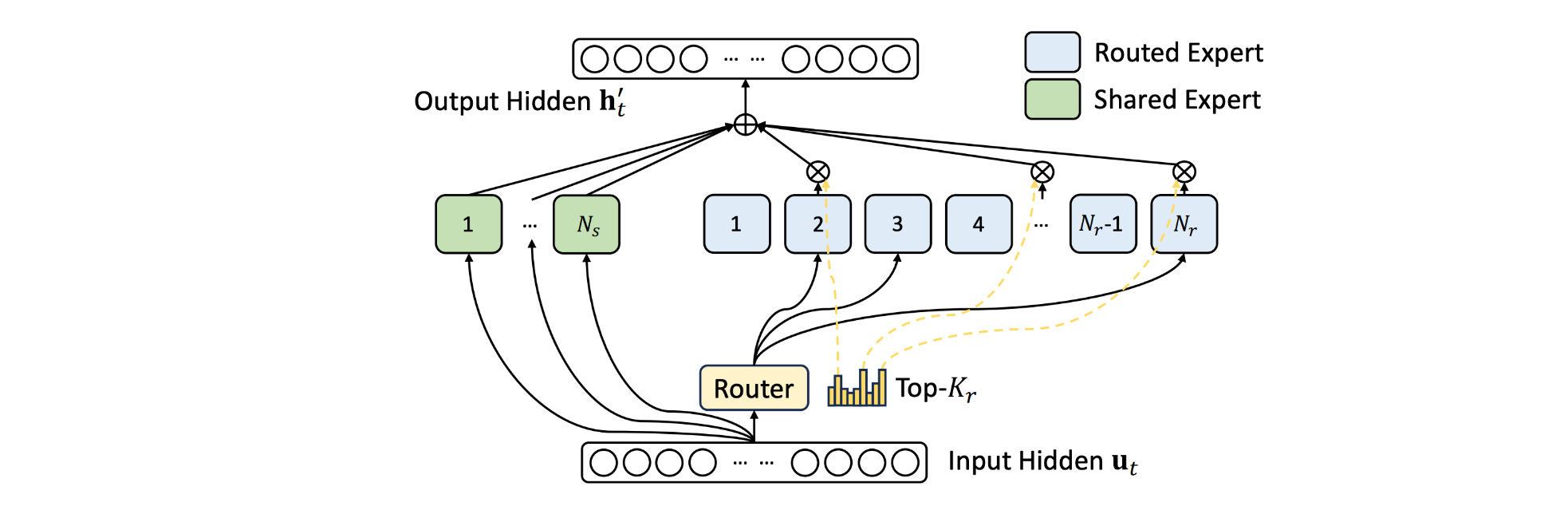
The magic of Mixture-of-Experts
In an LLM, the feed-forward network (FFN) in the Transformer block is often the most computationally demanding and holds the largest number of parameters.
This is why a dense feed-forward network is frequently replaced by a Mixture-of-Experts (MoE) feed-forward network. Mixture-of-Experts network improves computational efficiency by activating only a subset of expert modules during inference.
DeepSeek models from V2 onwards (including V4) use DeepSeekMoE, which splits the FFN into many smaller experts and routes each token to only a few of them (Routed Experts), while keeping some experts active for all tokens (Shared Experts). This significantly reduces its computational cost.
But given that V4 supports a 1M-token context window (compared to V3.2’s 128K), the attention mechanism becomes a significant bottleneck at inference.
This is where the new attention architecture innovated by DeepSeek-V4 shines! V4 models use a hybrid attention mechanism combining:
Compressed Sparse Attention (CSA)
Heavily Compressed Attention (HCA)
To understand how these attention mechanisms work and improve V4's efficiency so well, we will have to understand them from the ground up. Let’s start with the very basics and build from there, step by step.
What is Attention?
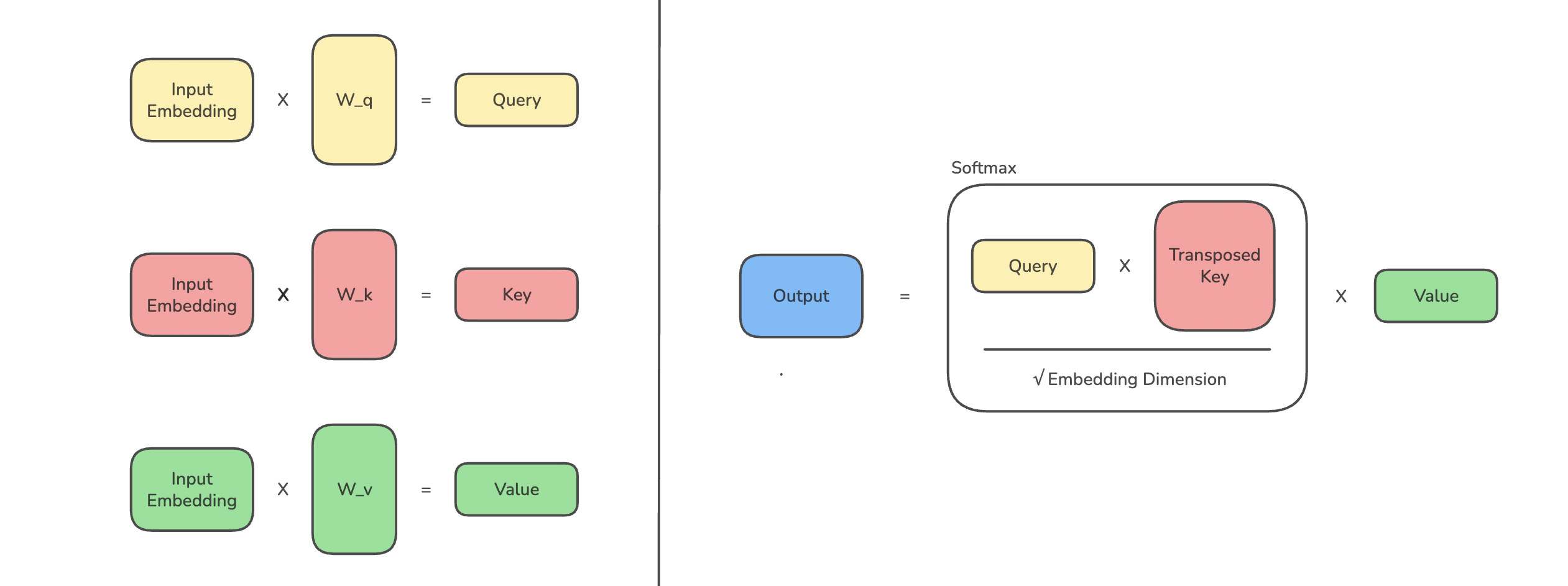
The (Self) Attention mechanism in a Transformer-based LLM helps the model understand how each word/ token relates to every other word/ token in a text sequence.
Given the embedding of each token:
It is first projected into Query (Q), Key (K), and Value (V) vectors.
The query vector is compared (technically via the dot product) with keys generated from itself and from previous tokens. This comparison produces attention scores that measure how closely the tokens are related to this one.
The scores are scaled, masked to block a token from attending to future tokens, passed through softmax, and then used to compute a weighted sum of the value vectors.
This weighted sum is the token’s context-aware representation, called Masked and Scaled Dot-Product Self-Attention.
Since every token is attending to itself and all the previous tokens, for an input sequence length of N, the attention mechanism processing it has an O(N2) computational complexity. This quadratic complexity isn’t ideal when processing long text sequences.
What is Multi-head Attention?
To improve performance, instead of performing attention operations once, these are done several times in parallel using different learned projections of the same token embeddings.
Each unit of attention calculation in this case is called a Head, and the mechanism is called Multi-head Attention (MHA).
Each attention head has its own Query, Key, and Value projections, and each head computes masked self-attention independently. The outputs of all heads are then concatenated into a single representation.
The use of multiple heads helps capture different kinds of semantic relationships between the tokens.
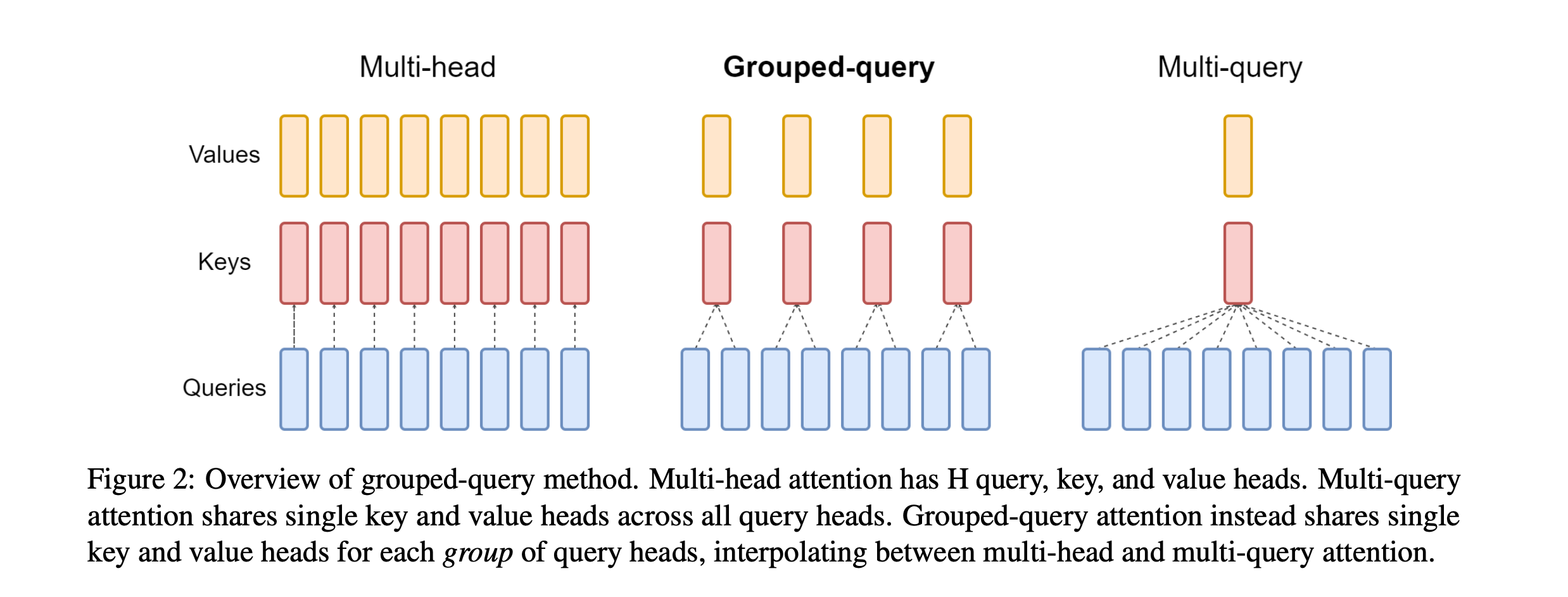
There are two efficient types of MHA that reduce the number of Key/Value projections stored and used during inference. These are:
Multi-Query Attention (MQA), where each attention head has its own Query, but all Query heads share the same Key and Value.
Grouped-Query Attention (GQA), where Queries are split into groups, and each group of Query heads shares one Key and Value head.
Both MQA and GQA make inference faster and cheaper, but at the expense of generation quality.
Attention mechanisms are made much more efficient using a KV cache.
KV cache to the rescue
Note that at each step of text generation/ inference, we need to calculate the K and V vectors for all previous tokens.
How about we store the Key and Value vectors from previous tokens, and reuse them later? That’s exactly what a KV cache does.
When using a KV cache:
For each generated token, we store its K and V vectors in the cache.
Then, in the next token generation step, we compute only the new token’s Q, K, and V.
Next, we reuse the cached KV of previous tokens, with the new token’s Q attending to both the cached KV and its newly calculated KV. This saves on lots of compute during inference.
Towards Multi-head Latent Attention
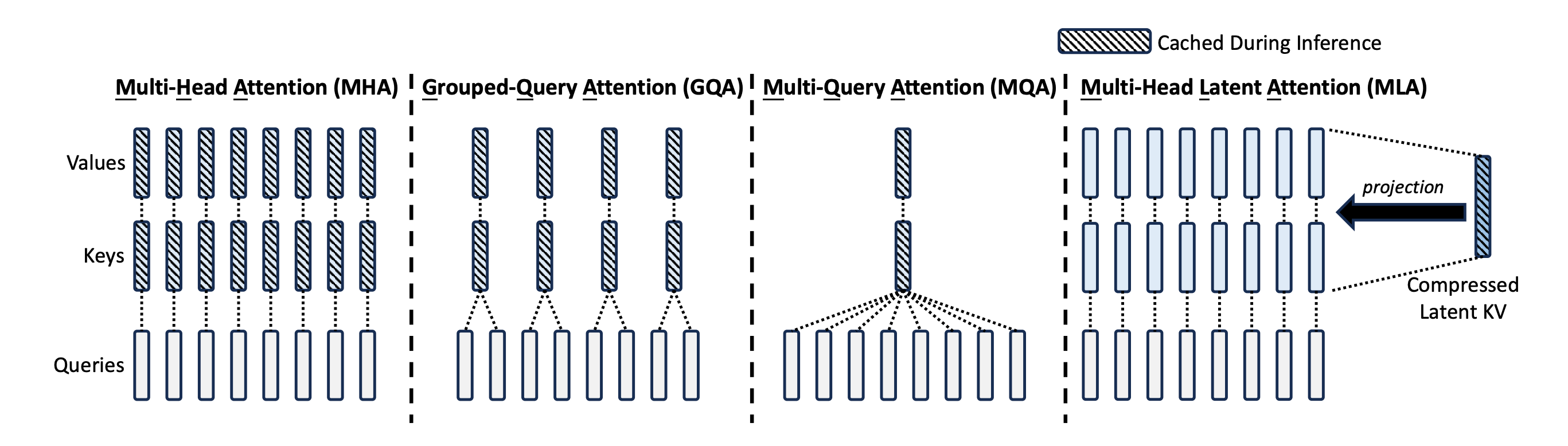
Released in 2024, DeepSeek-V2 introduced an efficient version of attention called Multi-head Latent Attention (MLA) that improves KV cache by not caching full Keys and Values. Instead, it stores a much smaller latent representation (one latent KV entry per token) and reconstructs the full KV information from it when needed.
This reduces the memory required to store the full KV cache, making the inference much faster. MLA is therefore also used in the later model, DeepSeek-V3.
Check out the following illustration to see how MLA compares to the other attention variants.
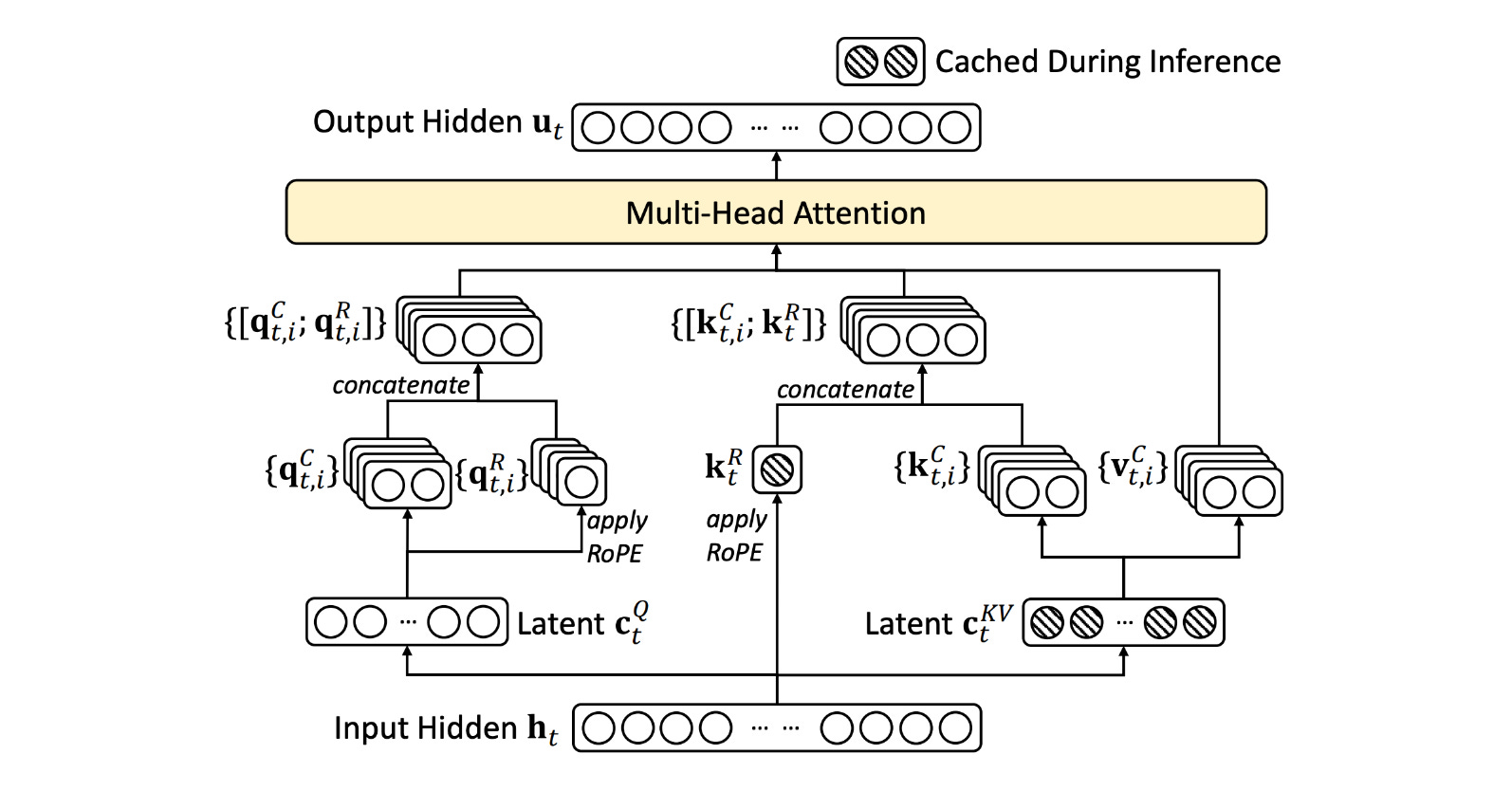
The complete architecture of MLA with the latent KV representation is shown below. I have also written a deep dive post on how it works, which you can read here.
Sliding Window to improve Attention further
Till now, we have learned how:
KV caching helps reduce the compute and memory requirements for attention at inference
Building on this and using a latent representation of the KV cache in MLA helps further reduce the memory requirements
There’s another way to reduce the compute and memory requirements of attention. This is by reducing the number of previous tokens that a token needs to attend to, which brings us to the Sliding window attention (SWA).
It was introduced in the ‘Longformer’ paper in 2020. In SWA, each token attends only to a fixed-size window of previous tokens, rather than all previous ones.
We previously discussed how the full Attention has an O(N2) computational complexity, as every token attends to itself and all the previous tokens, for an input sequence length of N.
With SWA, for an input sequence of N and window size (fixed-sized window of previous tokens that a token attends to) of w, the computational complexity goes down to O(Nw).
Although it is efficient, since each token attends to a window of nearby tokens, some long-range information in language modeling is lost. Hence, it is often used in combination with:
Full attention layers
Global window (where some tokens are allowed to attend to the entire sequence of previous tokens)
SWA can also use a dilated window pattern, where each token attends to nearby previous tokens but skips some positions in a regular pattern. This helps a token attend to more distant previous tokens at roughly the same compute cost.
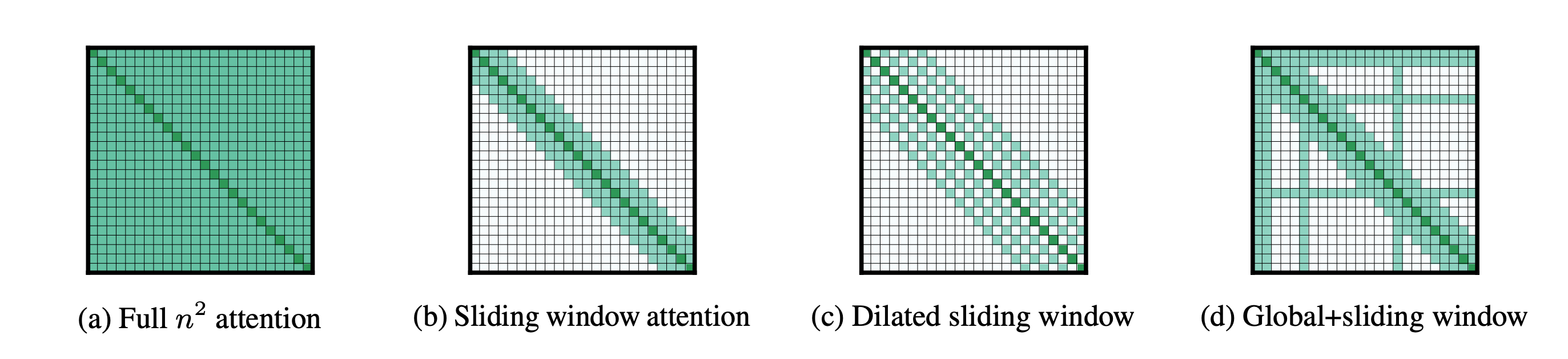
A popular example is the GPT-oss family of models, which uses SWA with a window size of 128 tokens in alternating layers with full attention (GQA with a configuration of 64 query heads and 8 KV heads).
Moving to DeepSeek Sparse Attention
