

This Week In AI Research (12-18 April 26) 🗓️
The top 10 AI research papers that you must know about this week.


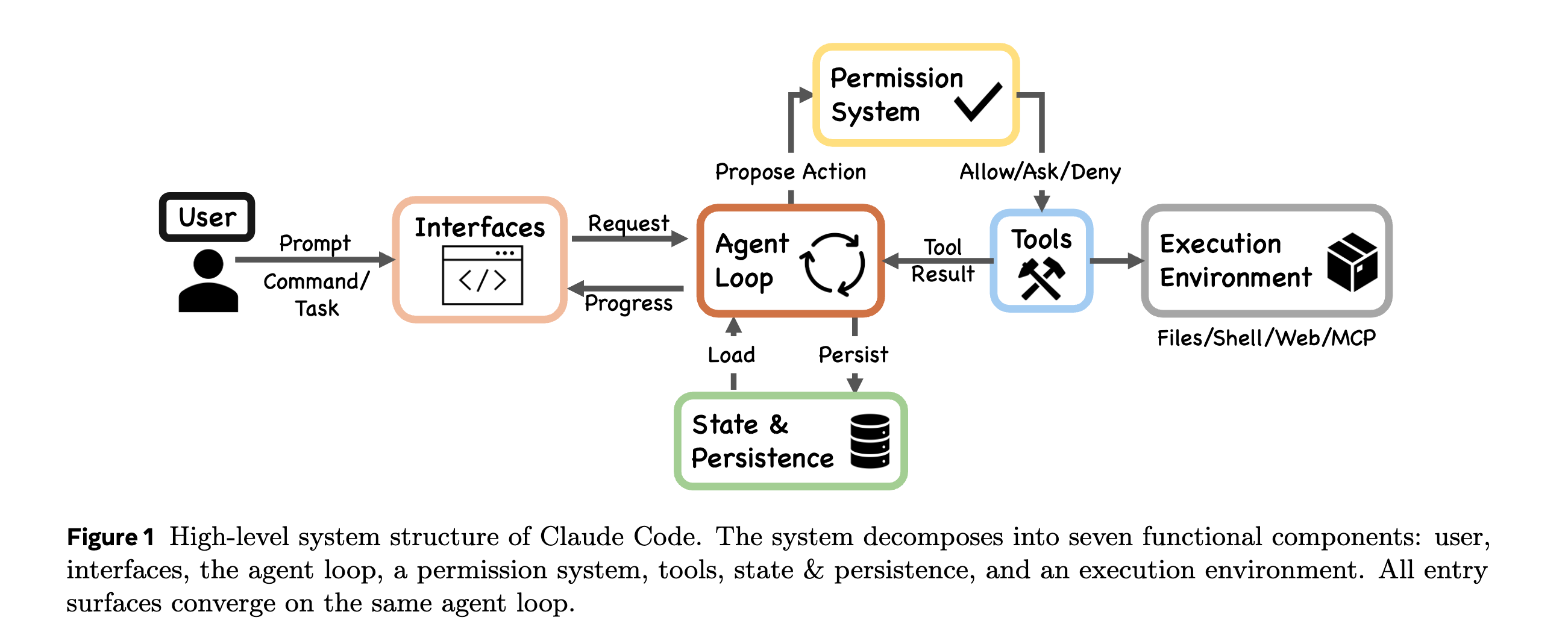
1. Dive into Claude Code
This research paper describes the architecture of Claude Code by analyzing its publicly available TypeScript source code and comparing it with the open-source OpenClaw.
At its core, Claude Code is a simple while-loop that calls the model, runs tools, and repeats. Its impressive capabilities come from the systems built around this loop:
A permission system with seven modes and an ML-based classifier
A five-layer compaction pipeline for context management
Four extensibility mechanisms (MCP, plugins, skills, and hooks)
A subagent delegation and orchestration mechanism
Append-oriented session storage
Read more about this research paper using this link.
2. Gemini Robotics-ER 1.6
This blog post introduces Google DeepMind’s Gemini Robotics-ER 1.6, an upgraded AI model that helps robots better understand and reason about the physical world.
It improves spatial awareness, multi-camera scene understanding, and task completion detection. The model also adds useful capabilities, such as reading gauges, thermometers, and industrial instruments, which are particularly beneficial for inspection robots like Boston Dynamics’ Spot.
Additionally, the model enables safer decisions regarding physical constraints, such as avoiding unsafe objects or tasks. This positions it as a step toward more autonomous robots that can operate reliably in real-world environments.
Read more about this release using this link.
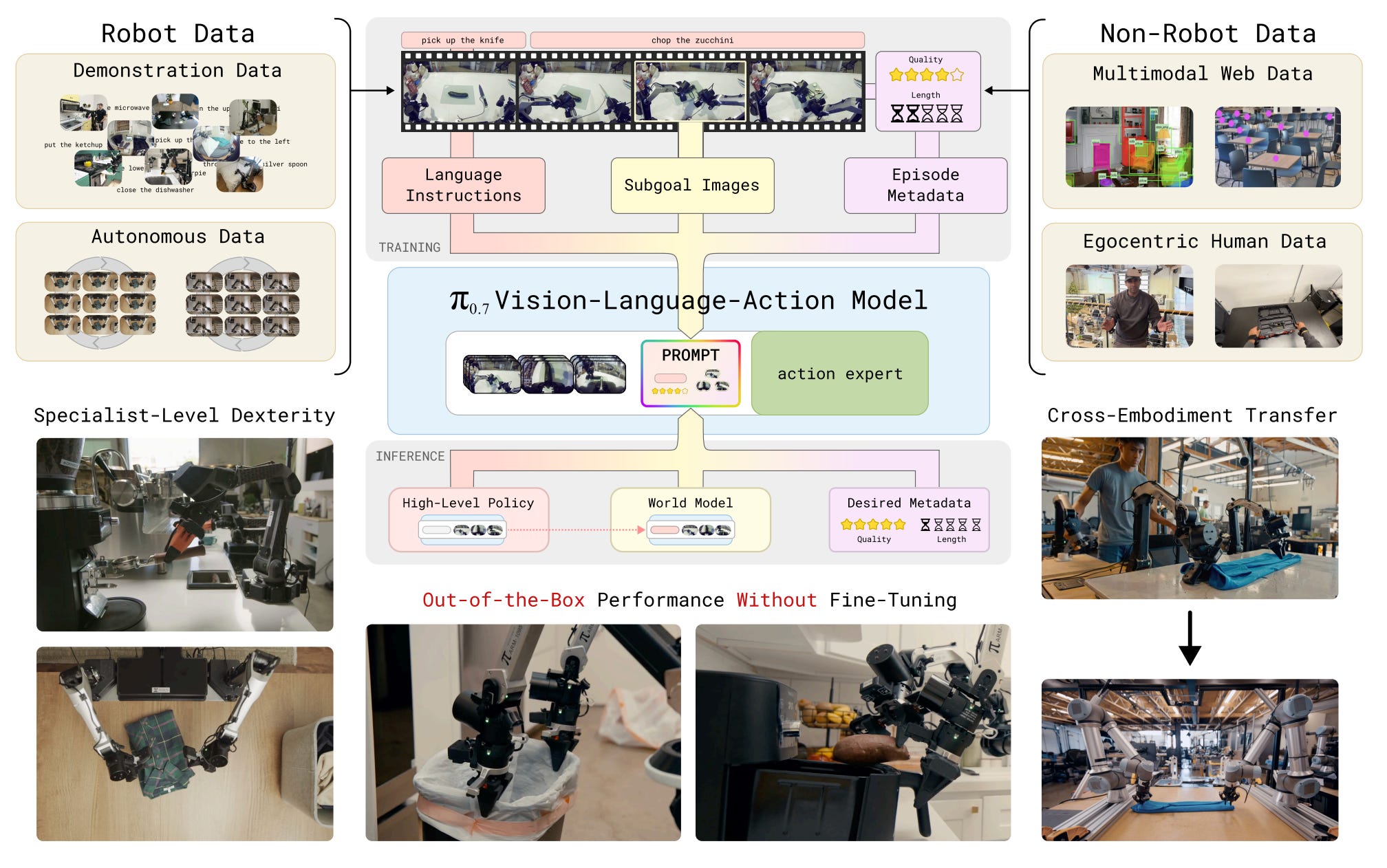
3. π 0.7: a Steerable Generalist Robotic Foundation Model with Emergent Capabilities
This research paper introduces π₀.₇, a general-purpose robotic foundation model from Physical Intelligence that equips robots with strong out-of-the-box capabilities across a range of tasks without requiring retraining for specific jobs.
The main idea behind π₀.₇ is to use diverse context conditioning during training. Instead of relying solely on language commands, the model also incorporates richer context, such as subgoal images, task metadata, control modes, and demonstrations, enabling it to adapt its behavior and strategy effectively.
In experiments, π₀.₇ demonstrates broad generalization. It can handle unseen kitchens, fold laundry without prior training on new robot bodies, and even operate an espresso machine with performance levels comparable to those of specialized reinforcement-learning systems.
Read more about this research paper using this link.
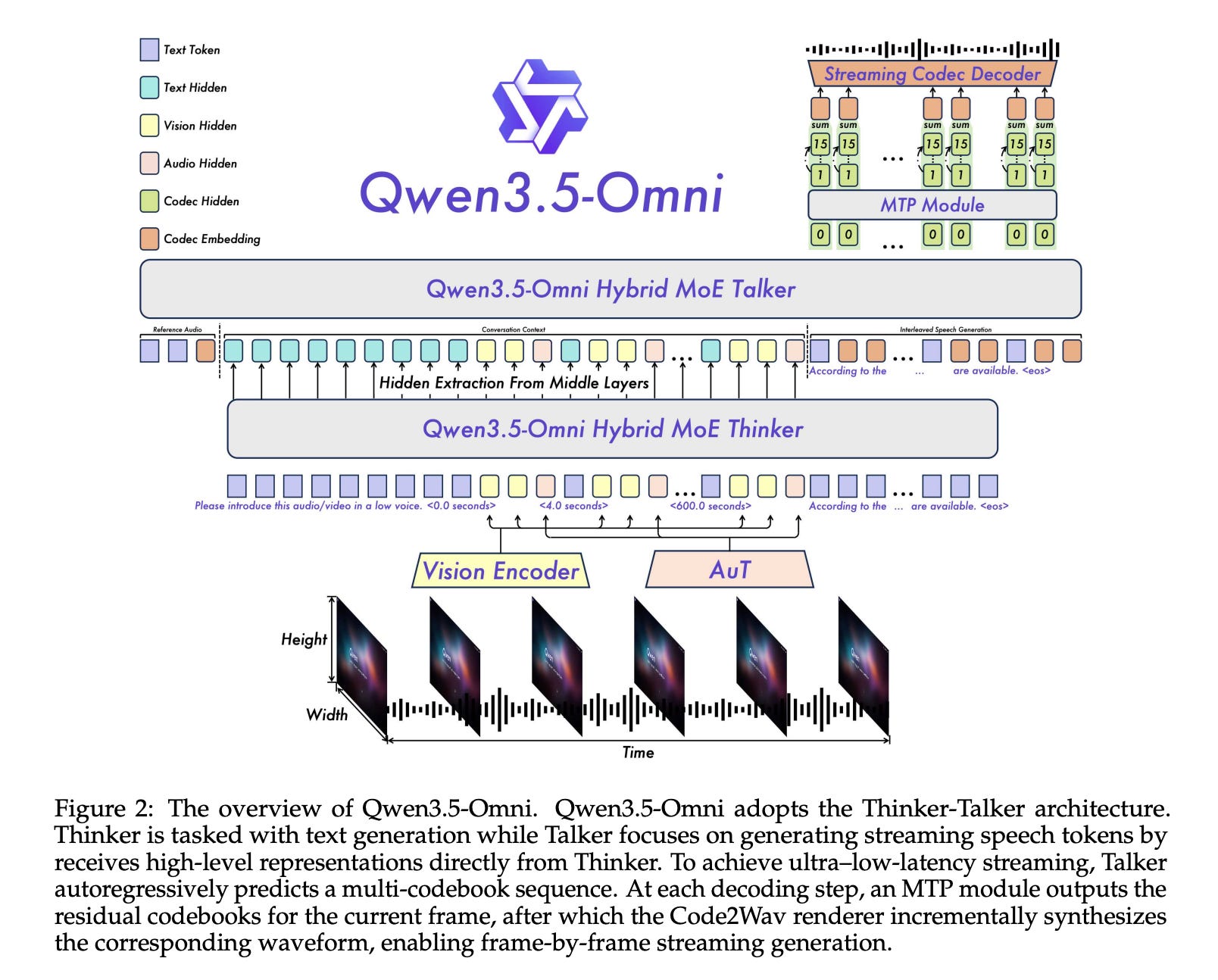
4. Qwen3.5-Omni
This research paper presents Qwen3.5-Omni, Alibaba’s new multimodal model for handling text, images, audio, and video.
The model comes with hundreds of billions of parameters and a 256k-token context window, and was trained on large text-image collections and over 100 million hours of audio-visual data.
Qwen3.5-Omni uses a Hybrid Attention Mixture-of-Experts design for reasoning and response generation, which improves efficiency on long multimodal sequences. It can process over 10 hours of audio and about 400 seconds of 720p video in a single session.
The research paper also introduces ARIA (Adaptive Rate Interleave Alignment), a method that better synchronizes text and speech token streams, resulting in more natural low-latency conversational speech.
Alongside this, the model supports multilingual speech generation in 36 languages, zero-shot voice cloning from short samples, strong temporal video captioning, scene segmentation, and a new capability called “Audio-Visual Vibe Coding”, which enables it to write code directly from spoken and visual instructions.
The top model, Qwen3.5-Omni-Plus, achieves leading results across 215 benchmarks and tasks for audio and audio-visual understanding, reasoning, and interaction. It outperforms Google DeepMind Gemini 3.1 Pro on several audio tasks and matches it on broad audio-visual evaluation.
Read more about this research paper using this link.
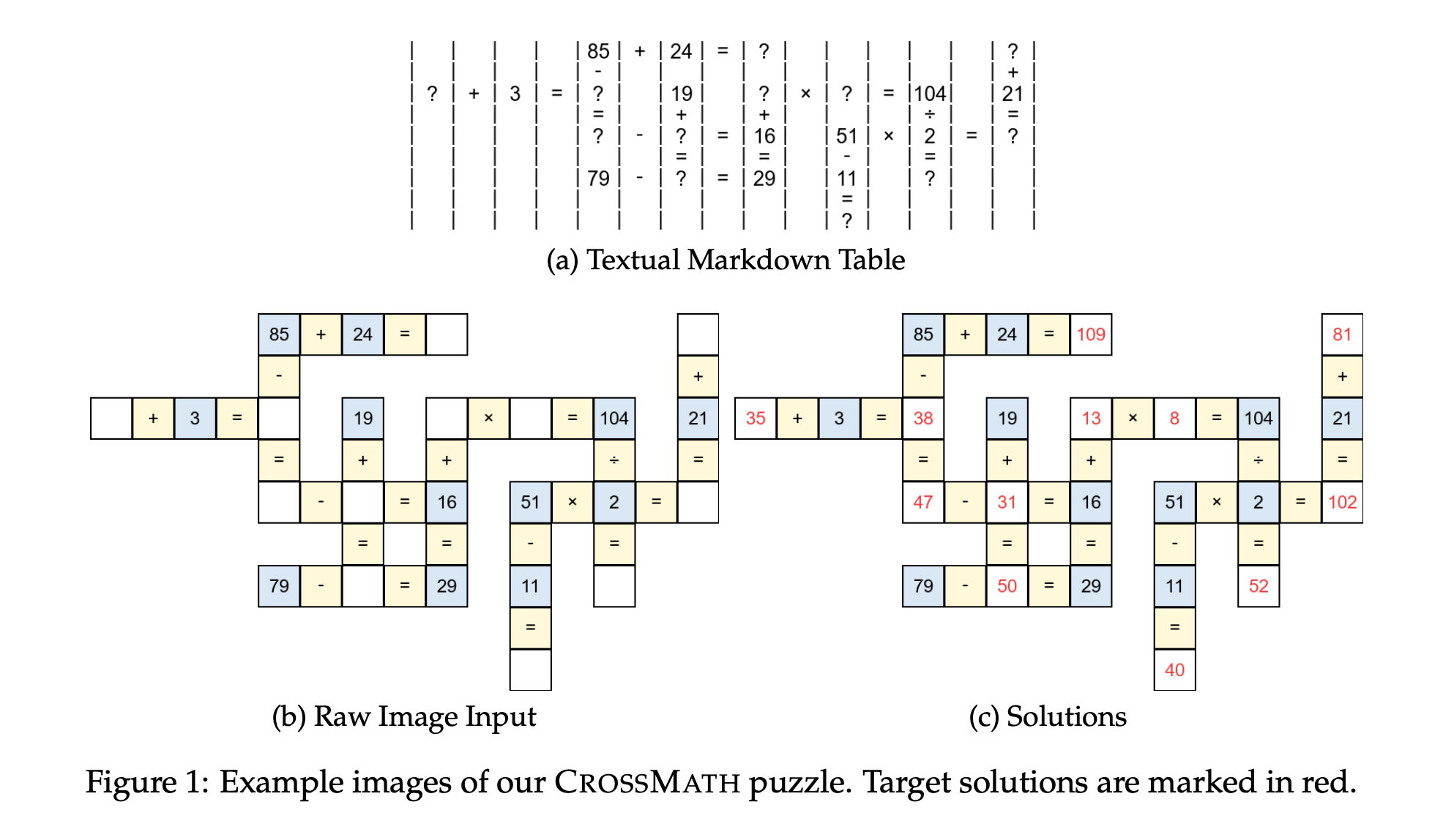
5. Do Vision-Language Models Truly Perform Vision Reasoning?
This research paper introduces CrossMath, a benchmark that tests whether vision-language models actually reason with images or primarily rely on text. Each problem in the benchmark is available in text-only, image-only, and image+text formats, and verified by a human annotator.
The authors find that top VLMs perform best on text-only tasks, and adding visual data (image+text) often lowers performance. This suggests that current vision-language models primarily reason through their language components, with limited reliance on visual evidence.
Fine-tuning a VLM on a curated CrossMath training set significantly improves reasoning performance across both text and vision tasks, suggesting that this issue can be partially fixed.
Read more about this research paper using this link.
6. LLM Reasoning Is Latent, Not the Chain of Thought
The author of the research paper compares three explanations for improvements in LLM reasoning:
Hidden internal trajectories
Explicit written reasoning steps
Simply giving the model more sequential compute
Reviewing recent evidence, it is concluded that the strongest current support is for the latent-state perspective, which suggests that models often reason internally and the visible CoT is not always a reliable reflection of that process.
Read more about this research paper using this link.
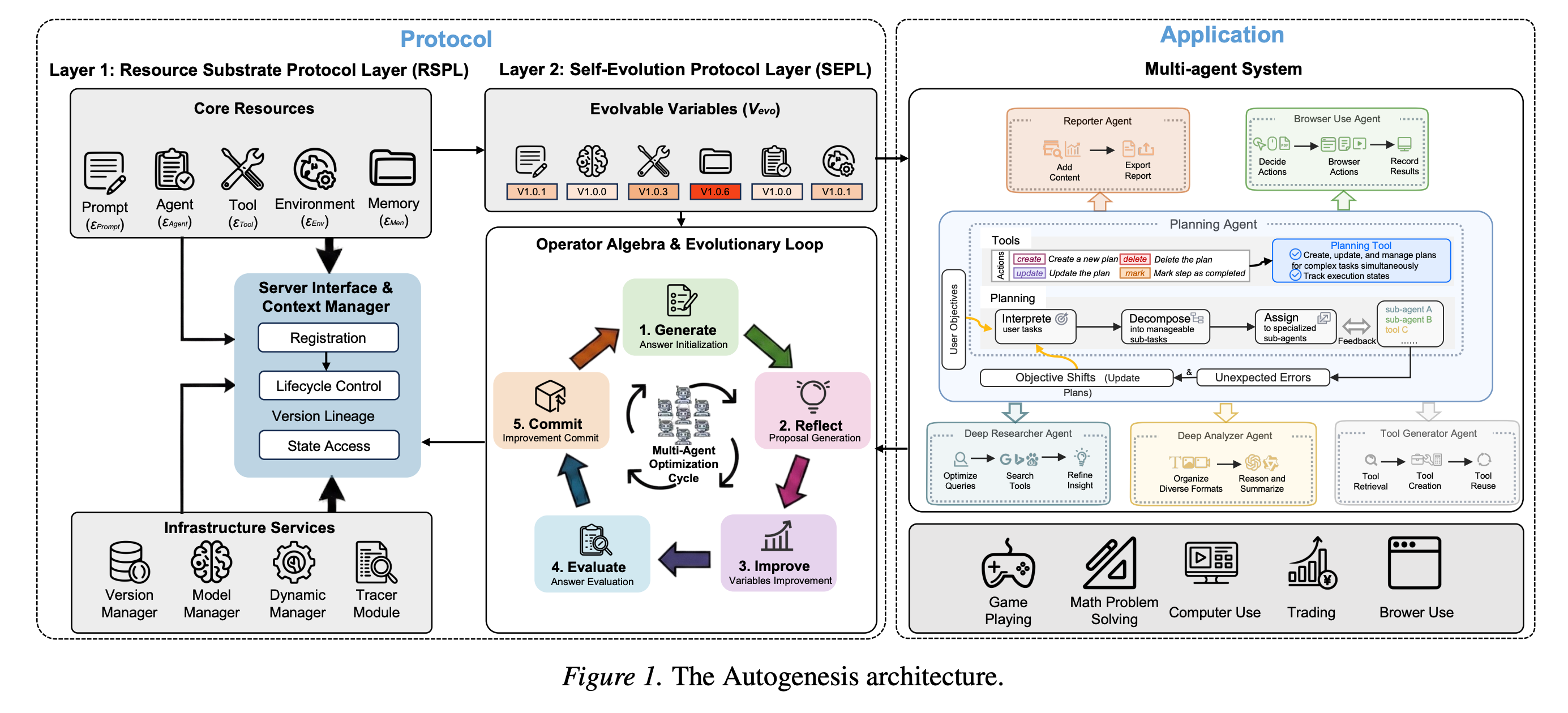
7. Autogenesis: A Self-Evolving Agent Protocol
This research paper introduces the Autogenesis Protocol (AGP), a framework designed for creating self-evolving LLM agent systems that can manage complex, long-term tasks more effectively.
Current agent standards often fall short in areas like lifecycle management, memory and context handling, version tracking, and safe update processes. These gaps result in fragile, single-unit agentic systems.
AGP tackles this issue by distinguishing what changes (such as prompts, tools, agents, memory, and environments) from how those changes occur. It implements a closed-loop method for suggesting, assessing, implementing, and reverting improvements.
The authors also present the Autogenesis System (AGS), a multi-agent setup that generates and improves resources during execution. This system demonstrates consistent improvements over strong baseline models across planning and tool-use benchmarks.
Read more about this research paper using this link.
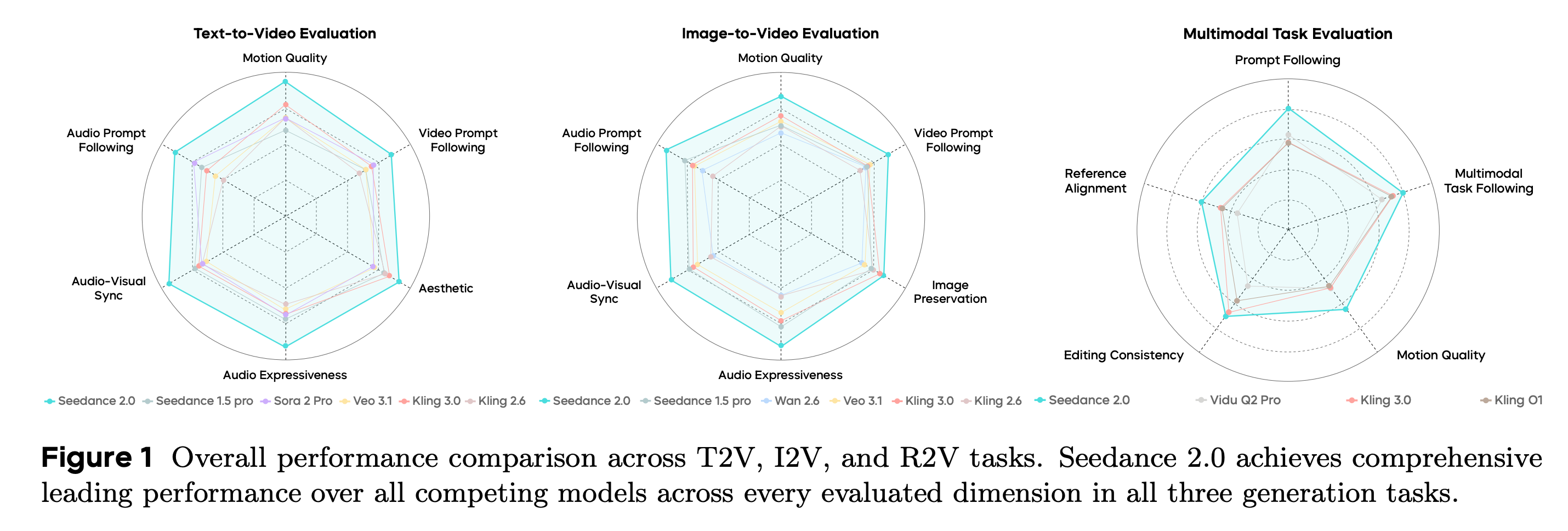
8. Seedance 2.0
This research paper introduces Seedance 2.0, a native multimodal audio-video generation model that creates synchronized content from text, images, audio, or video inputs in a single system.
Compared to earlier versions, it greatly improves video quality and audio realism, with its performance close to that of leading models in expert and public evaluations.
It can generate 4 to 15-second clips at 480p or 720p and also supports various editing and reference inputs, including multiple videos, images, and audio clips.
Additionally, the paper also features a Seedance 2.0 Fast version optimized for low-latency generation.
Read more about this research paper using this link.
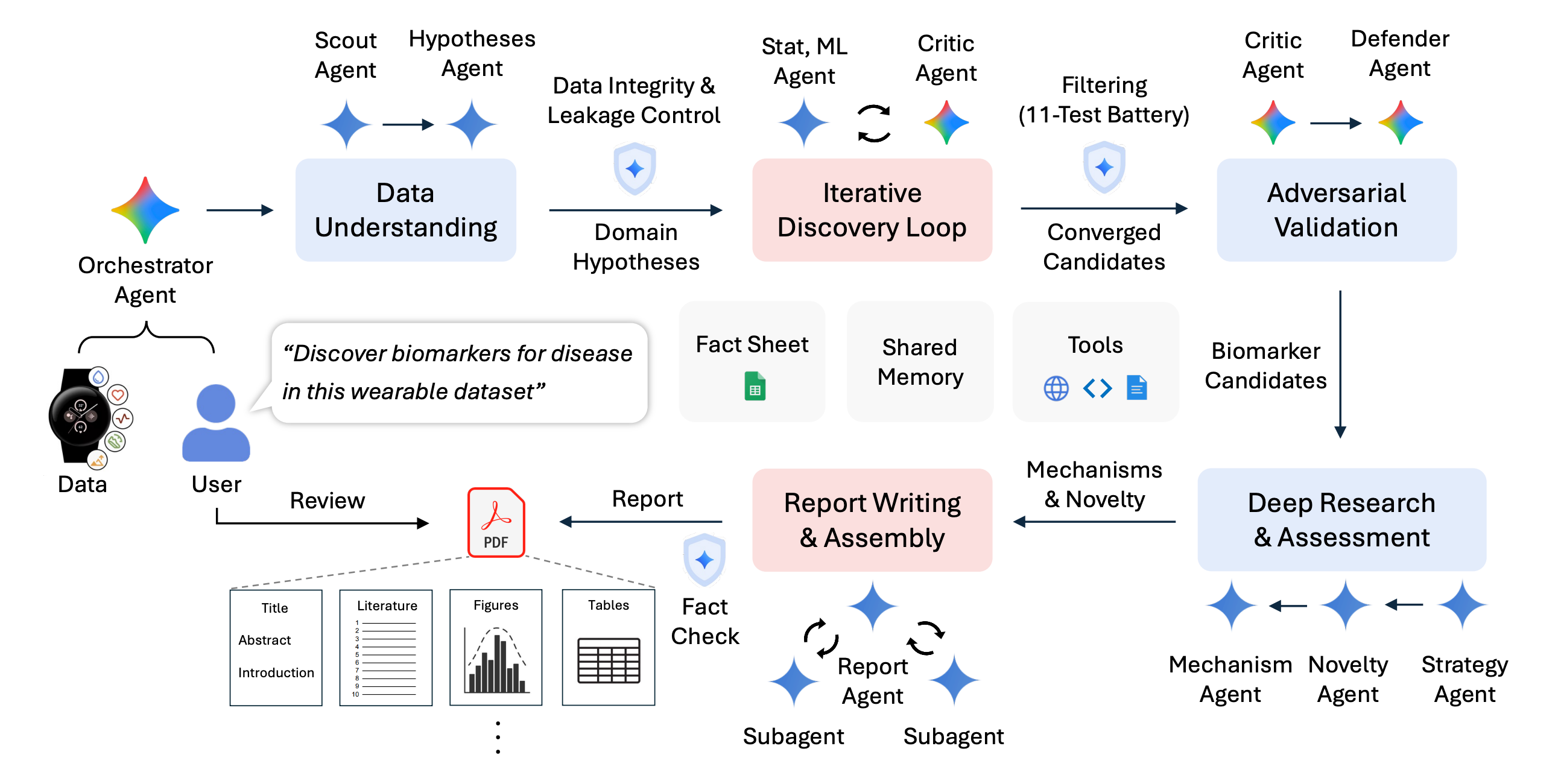
9.CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
This research paper presents CoDaS (AI Co-Data-Scientist), a multi-agent system designed to discover health biomarkers from data collected by wearable devices (sleep patterns, activity levels, and heart rate signals).
It organizes the discovery process as an iterative process that includes generating hypotheses, conducting statistical tests, performing validation, reviewing existing literature, and involving human oversight.
In a study of 9,279 participants, CoDaS identified potential biomarkers for mental health and metabolic conditions, including links between depression and irregular sleep or circadian rhythms, and between insulin resistance and a fitness index based on step counts and resting heart rate.
Read more about this research paper using this link.
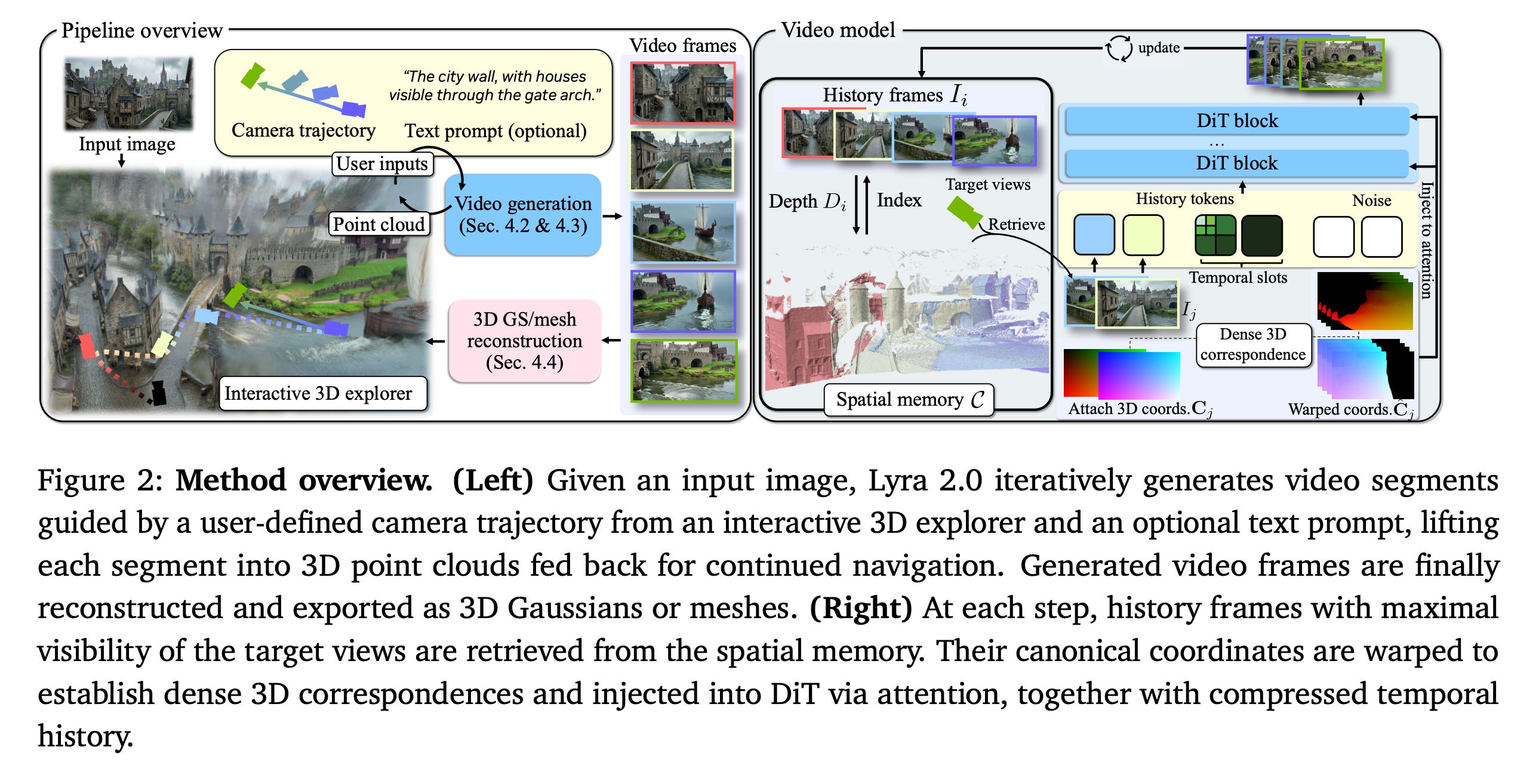
10. Lyra 2.0: Explorable Generative 3D Worlds
This research paper introduces Lyra 2.0, a system that creates persistent, explorable 3D worlds. It starts by making camera-controlled walkthrough videos and then turns these into real-time 3D scenes.
The main challenge in generating worlds is maintaining consistency across large environments over long paths. Current video models often struggle with spatial forgetting, which means they lose track of previously seen areas, and with temporal drifting, where errors build up over time.
Lyra 2.0 solves this problem by using recovered 3D geometry to access relevant past views and training the model to fix its own degraded outputs. This leads to longer, more coherent scene generation and allows for the creation of high-quality AI-generated worlds for gaming, simulation, and robotics.
Read more about this research paper using this link.
Share this article with others and earn some referral rewards. ❤️
Join the paid tier today to get access to all posts on this newsletter:
and so many more!
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
