

Learn to train deep learning models on multiple GPUs
Part 1: Understand Distributed Data Parallel in depth, visually

We have long ago moved away from training production-grade deep learning models on a single machine.
Today, large deep learning models such as LLMs are usually trained for months on distributed clusters with multiple GPUs. This is because a single machine usually lacks the memory and computing power needed to process massive training datasets and train a model.
For example, Llama 3.1 models were pre-trained on around 15 trillion data tokens and required a total of 39.3M GPU hours of computation on NVIDIA H100-80GB GPUs. That’s a big number!

{kind=link}
In this two-part lesson, we will learn about an algorithm called Distributed Data Parallel (DDP), and then get our hands dirty by writing some PyTorch code to train a model across multiple GPUs using it.
Let’s begin!
Btw, I’m running a 50% off sale on the annual subscription to ‘Into AI’, valid ONLY for the next 2 days.
Claim your discount NOW and get access to articles like these, and so much more:
But first, what is Distributed Data Parallel (DDP)?
Distributed data parallel (DDP) is a popular algorithm for training models across multiple GPUs.
The algorithm uses Data parallelism, which means splitting the training dataset across multiple GPUs so each GPU processes a different portion of it in parallel during model training.
Here are the steps that take place in DDP:
The model is first replicated on each GPU along with a copy of the optimizer.
The training dataset is split across GPUs using DistributedSampler, which ensures that each GPU trains on a unique data subset/ batch per epoch.
Each GPU runs a forward pass on its subset of the training dataset to calculate loss, and stores the activations
Each GPU runs a backward pass using the activations and loss, and computes gradients
All GPUs communicate and share their calculated gradients with each other
The gradients are averaged across the GPUs using an algorithm called AllReduce
Averaged gradients are communicated back to each GPU
Each GPU updates its copy of model weights using the averaged gradients. As each GPU starts with the same model weights and updates them using the same averaged gradients, all the resulting model copies remain in sync with other GPUs.
The next batch of training data is loaded, and the cycle repeats from step 3 till the training epoch ends.
In case of training for multiple epochs, the entire training dataset is reshuffled using DistributedSampler and is iterated over again.
Once all training epochs end, the trained model is returned.
DDP makes the training process even more efficient by running steps 4 and 5 at the same time.
It doesn't wait for gradients from all layers to be computed before sharing them. Instead, it sends each layer's gradients to the other GPUs as soon as they're ready, so that communication occurs in parallel with computation.
Understand DDP Visually
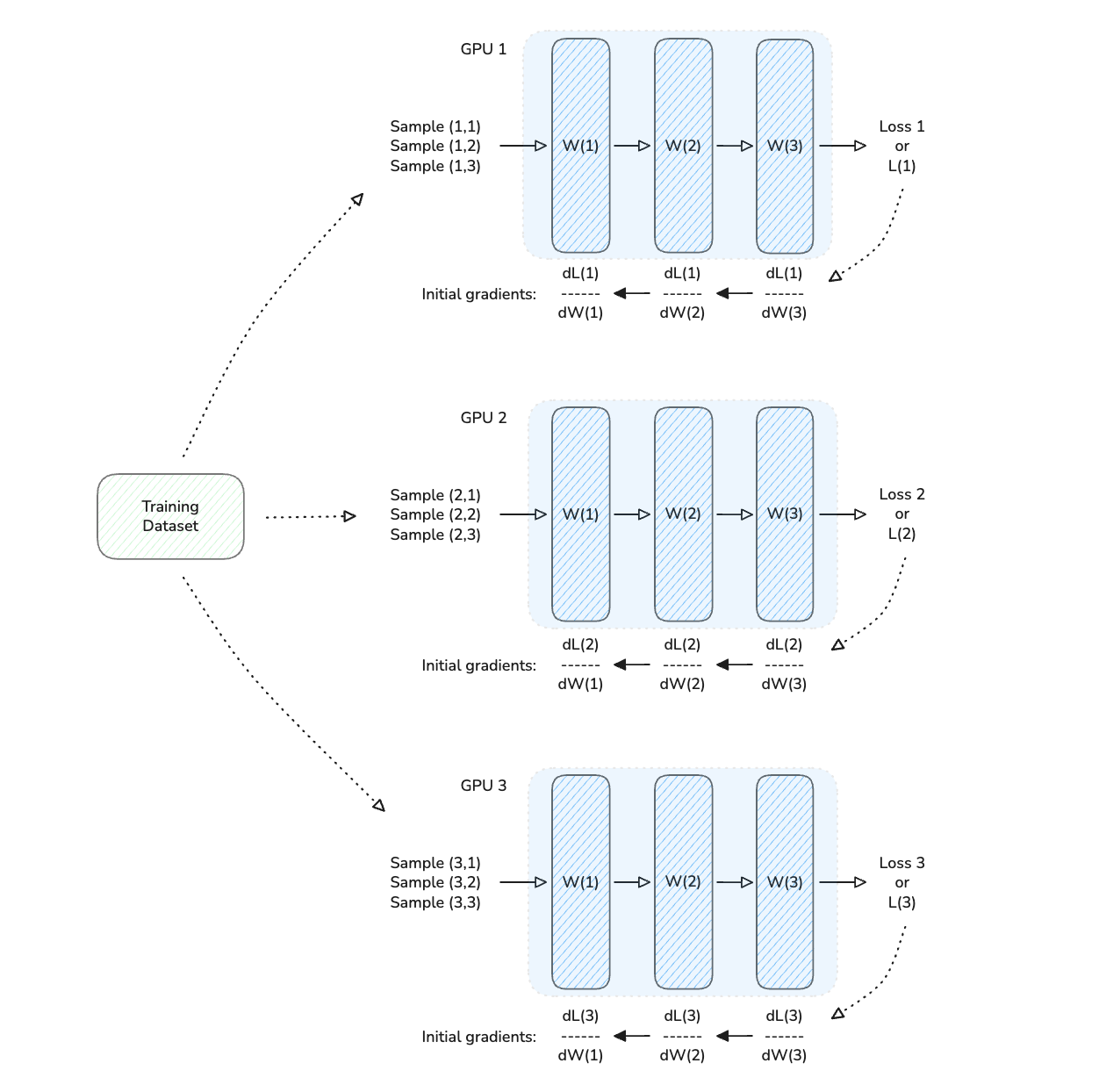
Here is an example of a 3-GPU distributed training setup using DDP.
In the illustrations shown below:
Each GPU starts with its own copy of the model (and optimizer).
Then, each GPU is given different samples/ batch from the training dataset
Each GPU runs a forward and backward pass, computing loss and gradients
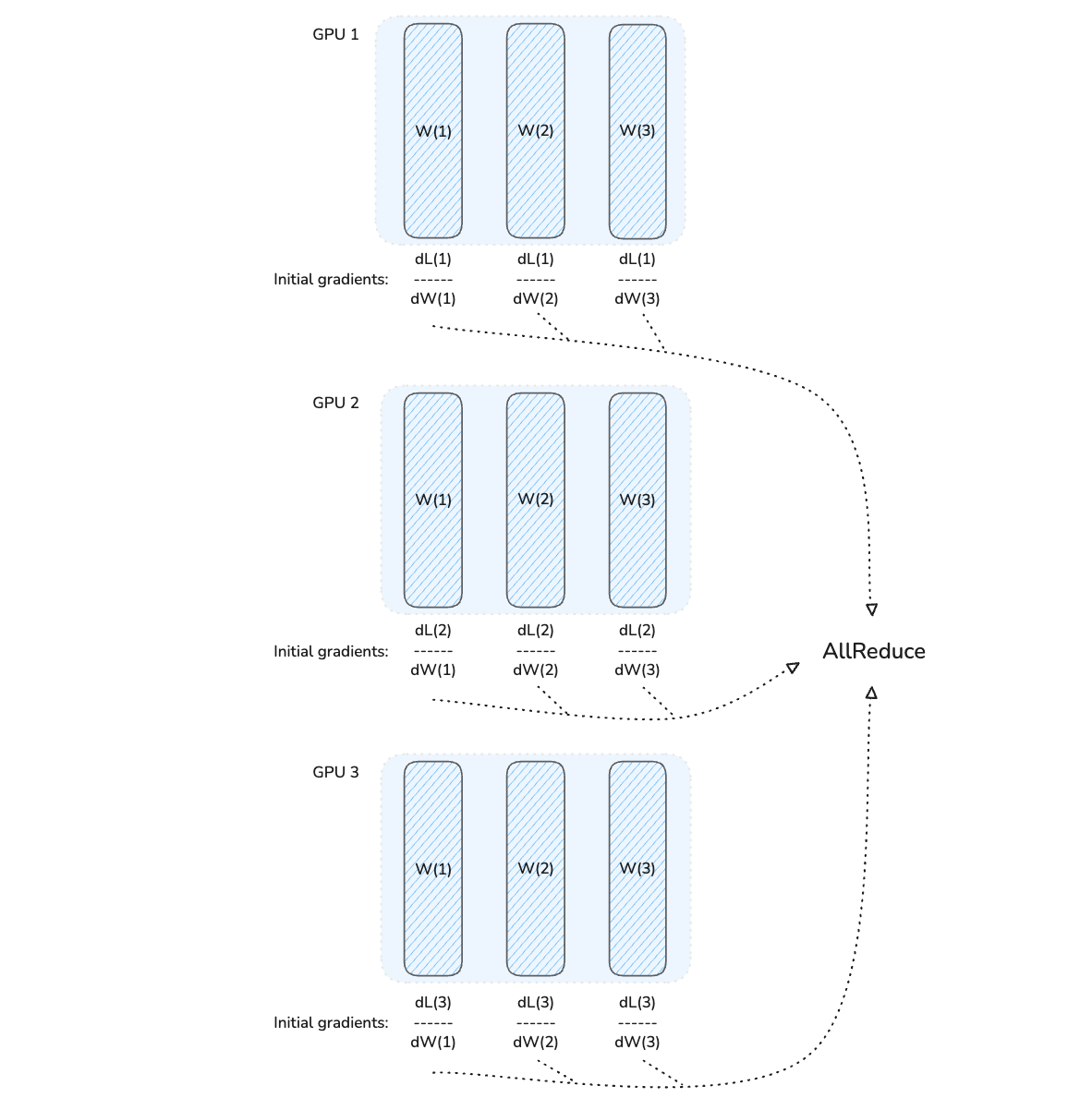
Following this, gradients from all GPUs are aggregated and averaged using the AllReduce operation.
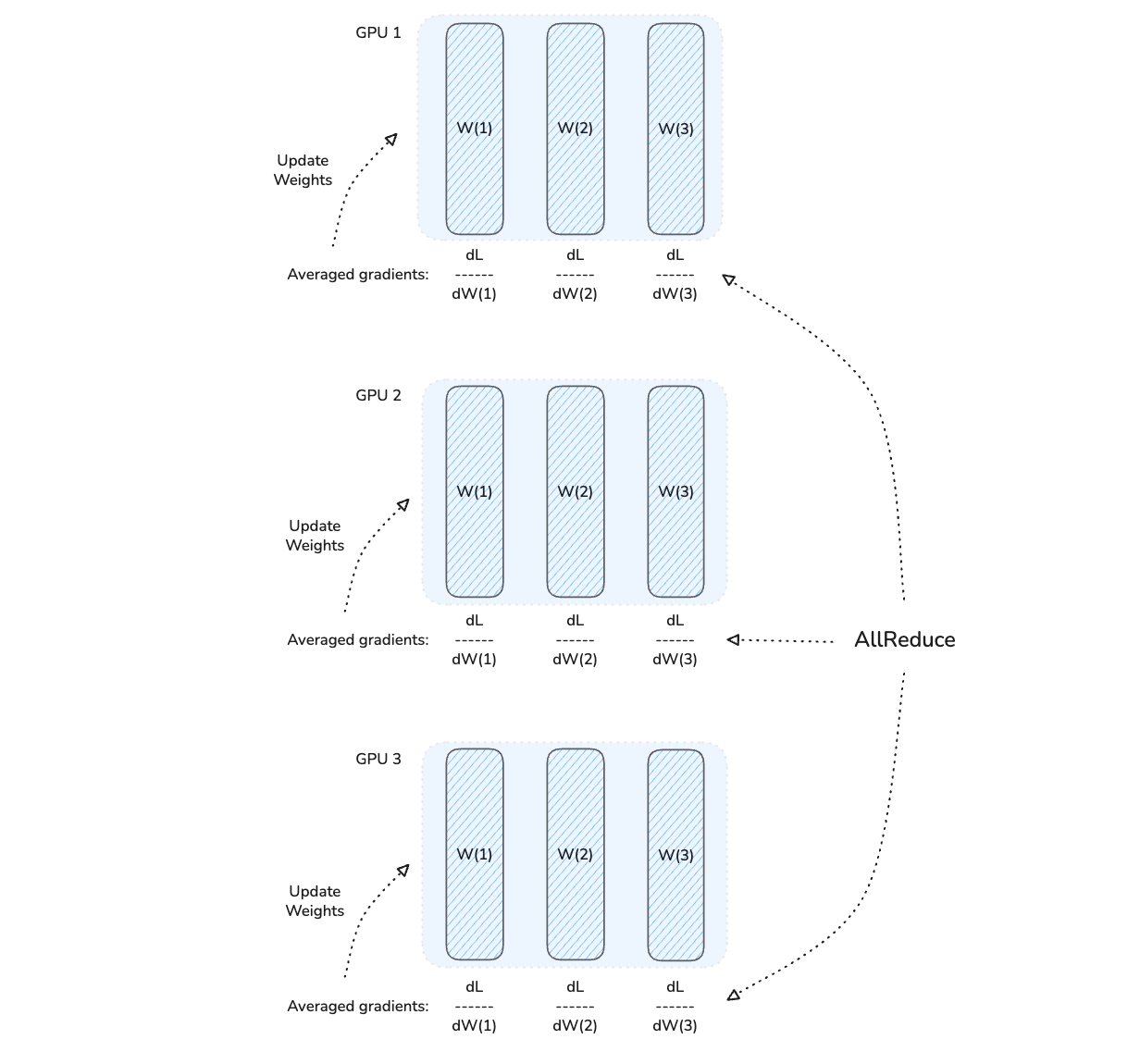
After this step, the averaged gradients are broadcast back to all the GPUs.
Each GPU then updates its copy of model weights using them. This keeps all copies of the model between different GPUs synchronized.
Once the last training epoch ends, the trained model is returned.
But DDP Isn’t Perfect
DDP speeds up and efficiently scales model training, but it is not a one-stop solution to distributed model training.
DDP involves each GPU storing at least:
Model parameters
Optimizer and its state
Model activations after forward pass
Gradients after backward pass
Consider the NVIDIA H100 (80GB) GPU, which is widely used for model training.
If we train an 8B-parameter Llama 3 model on it using the AdamW optimizer, with full-precision training (which means that all numbers used are FP32 or require 4 bytes):
The model parameters will require: 8B × 4 bytes = 32 GB
Gradients will require: 8B × 4 bytes = 32 GB
The AdamW optimizer state (first and second moments) will require: 8B × 4 bytes x 2 = 64 GB
Alongside these, activations will require 10-20 GB, with the use of activation checkpointing
Other unaccounted computation/ communication overheads might require another 2-3 GB
The total requirements of 151 GB far exceed the GPU's VRAM capacity of 80 GB. This means that training such multi-billion-parameter models isn’t possible with DDP.
This is when we move towards using Model Parallelism techniques, which involve splitting model parameters across multiple GPUs. This is a topic of future lessons in the newsletter.
In the next part of this lesson on DDP, we will learn how to train a deep learning model using it on free-to-use cloud GPUs.
If you loved reading it and found it valuable, restack to share it with others. ❤️
Don’t forget to grab your 50% off sale on the annual subscription to ‘Into AI’, valid ONLY for the next 2 days.
