

🗓️ This Week In AI Research (21-27 December 25)
The top 10 AI research papers that you must know about this week.


1. Attention Is Not What You Need
This research paper challenges the assumption that self-attention is necessary for strong sequence modeling and reasoning.
It explains multi-head attention as a form of tensor lifting, where hidden vectors are mapped into a high-dimensional space of pairwise interactions, and learning proceeds by constraining this lifted tensor via gradient descent.
This approach is powerful but difficult to interpret.
As an alternative, the authors propose an attention-free method based on Grassmann flows, where token representations are compressed, local token pairs are modeled as low-rank geometric subspaces, and the results are mixed back using simple gating.
Experiments show that these models come within 10–15% of Transformer performance on WikiText-2 and slightly outperform Transformer heads on the SNLI natural language inference task, while scaling linearly with sequence length and offering a more structured, geometry-based view of reasoning.

Read more about this research using this link.
2.QuarkAudio Technical Report
This research paper from Alibaba introduces QuarkAudio, a unified, decoder-only, autoregressive language model framework designed to handle a wide range of audio processing and generation tasks.
At the core of QuarkAudio lies H-Codec, a high-fidelity discrete audio tokenizer that integrates self-supervised learning (SSL) representation within the audio tokenization and reconstruction process.
The framework supports speech restoration, speaker extraction, speech separation, voice conversion, language-guided audio source separation, and free-form audio editing via natural language.
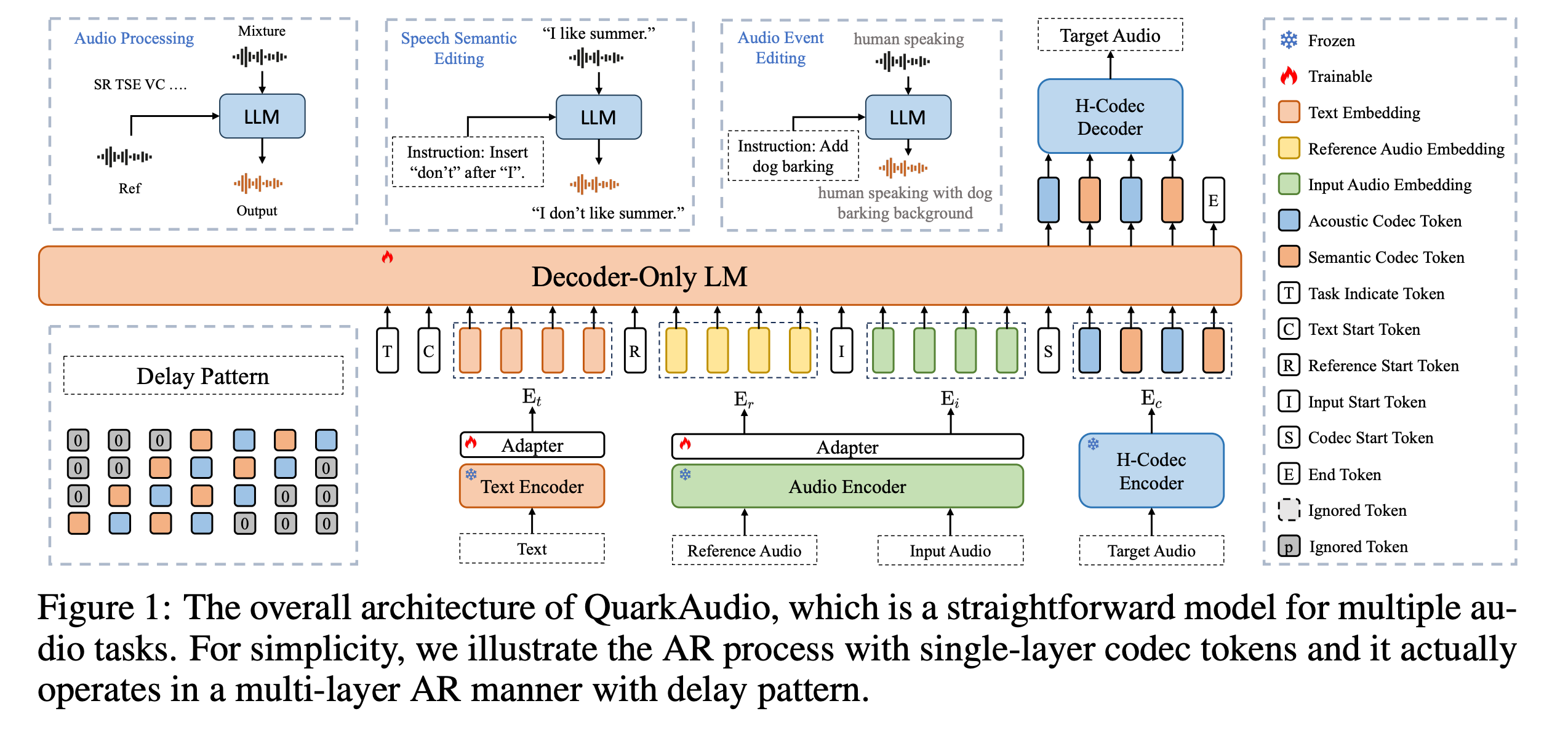
Experiments show that H-Codec achieves strong reconstruction quality at low frame rates, and QuarkAudio performs competitively with state-of-the-art task-specific and multi-task systems.
Read more about this research using this link.
Before we move forward, I want to introduce you to the Visual Tech Bundle.
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books.
This includes Dharmesh Shah, the co-founder and CEO of HubSpot.
Why not give them a try?
3. Sophia: A Persistent Agent Framework of Artificial Life
Authors of this research paper argue that current LLM-based agents, while strong at perception (System 1) and deliberation (System 2), lack a persistent meta-layer to maintain identity, verify reasoning, and align short-term actions with long-term goals.
To address this, they introduce System 3, a higher-level layer focused on self-monitoring, narrative identity, and long-term adaptation.
They bring this idea to life with Sophia, a persistent agent that can wrap around any existing LLM-based agent. Sophia adds memory, self- and user-modeling, guided thought search, and a simple reward system, allowing the agent to learn from its own past, explain its behavior, and improve over time.
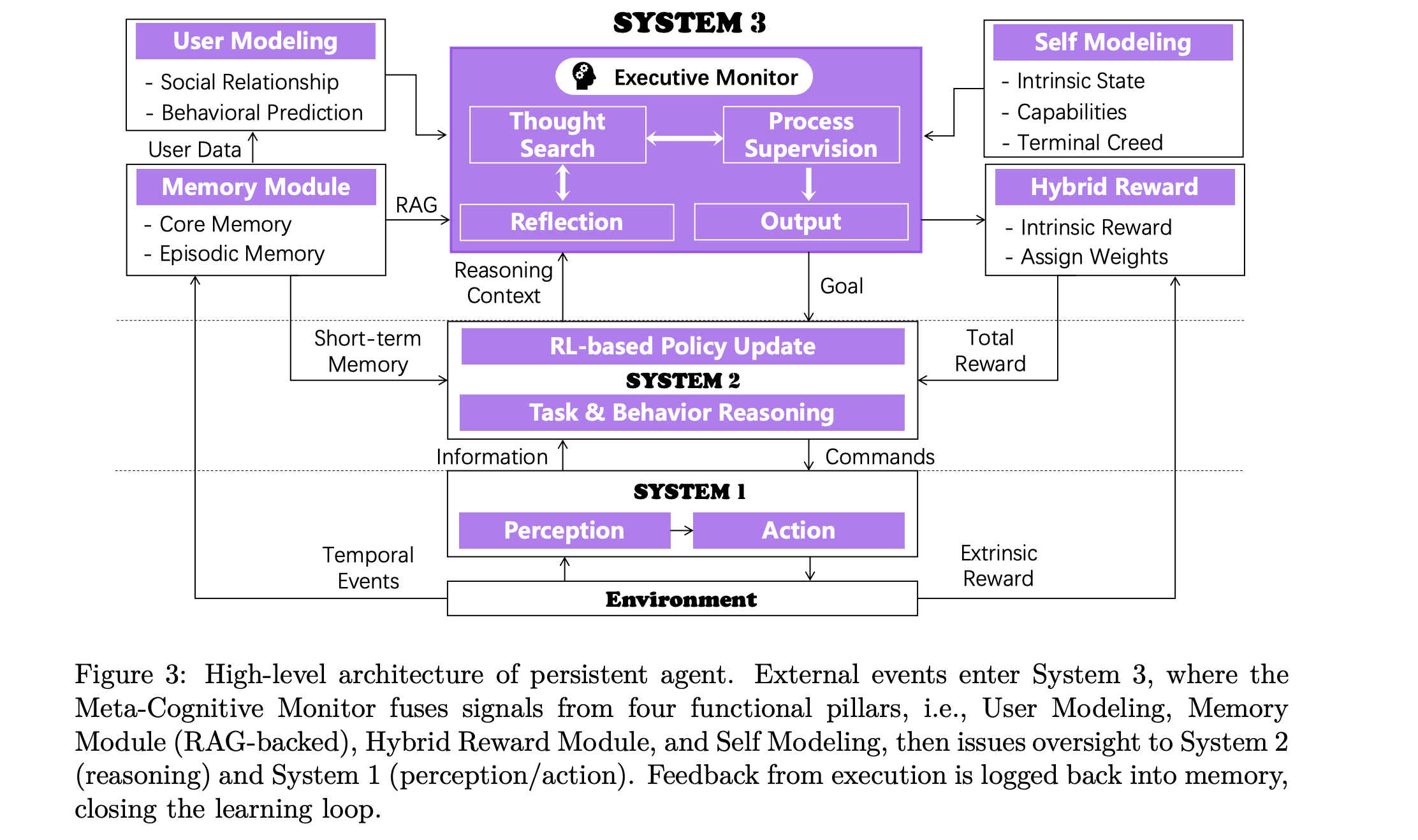
Although largely conceptual, a small prototype shows that System 3 reduces the number of reasoning steps by 80% for repeated tasks and improves success rates on high-complexity tasks by 40%.
Overall, the paper offers a grounded and psychologically inspired path toward artificial life.
Read more about this research using this link.
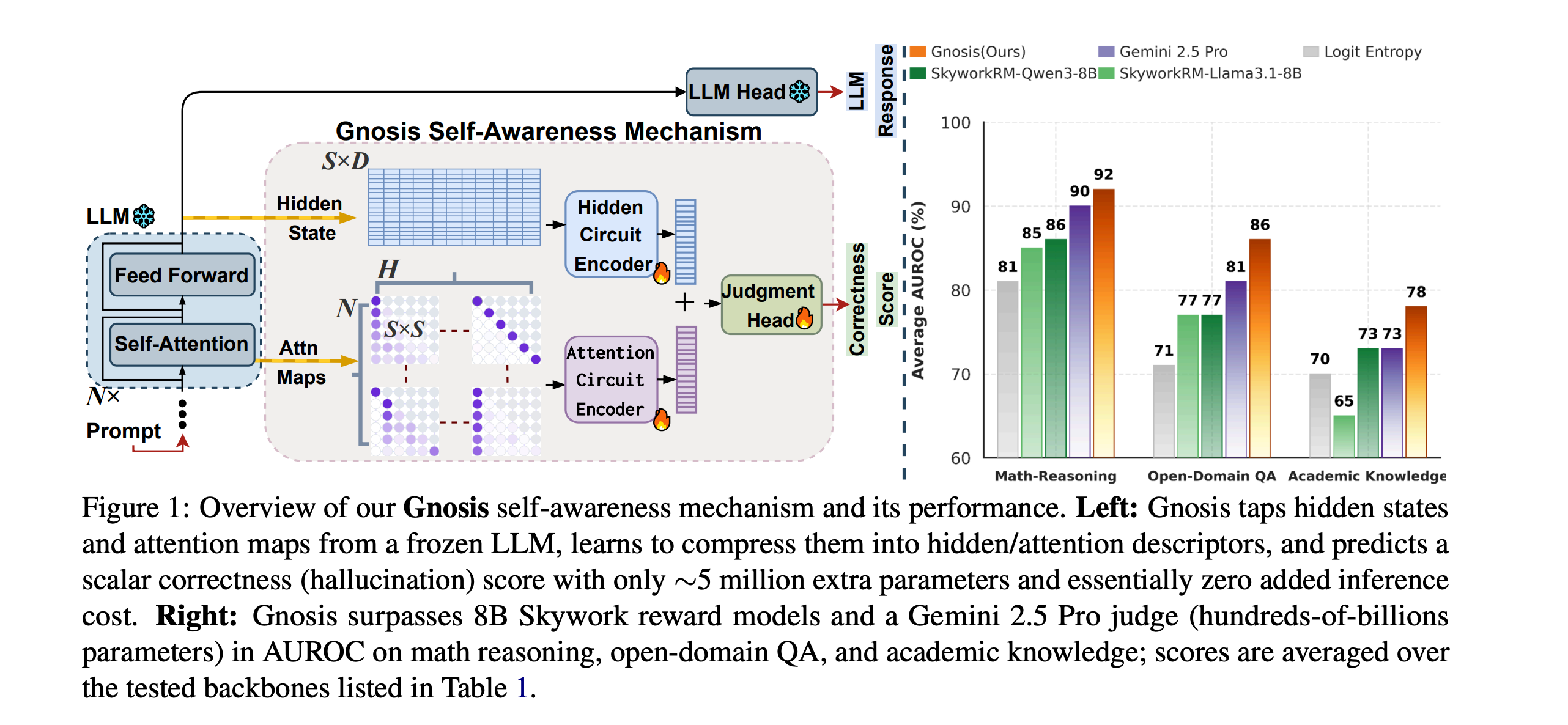
4. Can LLMs Predict Their Own Failures? Self-Awareness via Internal Circuits
This research paper explores whether LLMs can predict their own mistakes without external critics.
It introduces Gnosis, a lightweight self-awareness module that enables frozen LLMs to perform intrinsic self-verification by decoding signals from hidden states and attention patterns.
Gnosis passively observes internal traces, compresses them into compact descriptors, and uses them to judge whether a generation is likely correct, adding only about 5 million parameters and working independently of sequence length.
Across tasks such as math reasoning, open-domain QA, and knowledge benchmarks with frozen backbones from 1.7 B to 20 B parameters, Gnosis consistently beats strong internal baselines and large external judges in both accuracy and calibration.
It even generalizes zero-shot to partial outputs, enabling early detection of failing generations.
Read more about this research using this link.
5. Parallel Token Prediction for Language Models
This research paper introduces Parallel Token Prediction (PTP), a framework for parallel sequence generation in language models.
Traditional autoregressive decoding is slow because each token depends on the previous one. In contrast, PTP incorporates sampling into the model itself, allowing several tokens to be predicted in a single forward pass without assuming independence.

The authors prove that PTP can represent any autoregressive sequence distribution and can be trained either by distilling an existing model or via inverse autoregressive training without a teacher.
In experiments, PTP achieves state-of-the-art speculative decoding performance on Vicuna-7B by accepting more than 4 tokens per step, showing that long sequence generation with reduced latency is possible without losing modeling power.
Read more about this research using this link.
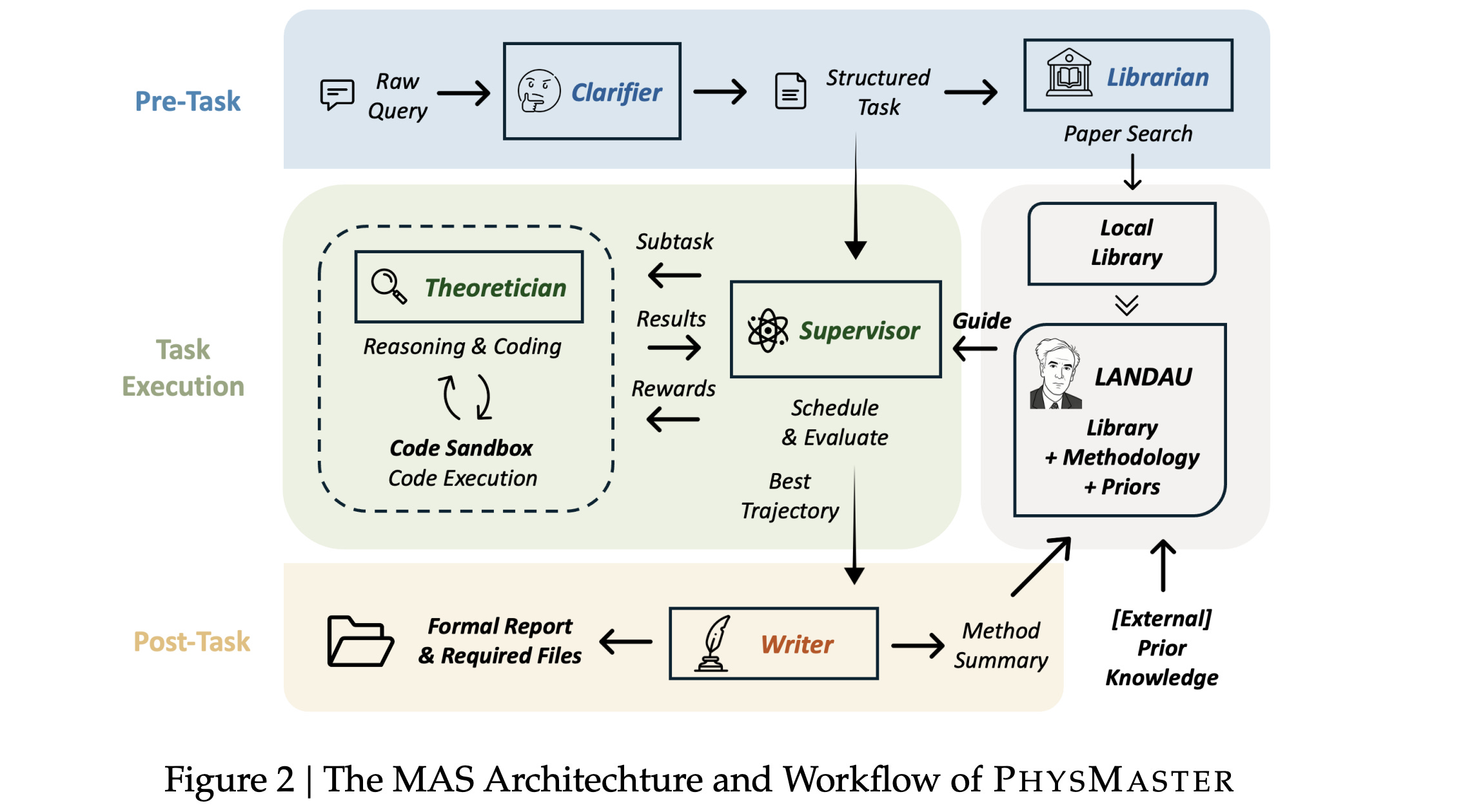
6. PhysMaster: Building an Autonomous AI Physicist for Theoretical and Computational Physics Research
This research paper presents PhysMaster, an autonomous AI designed to function like a theoretical and computational physicist, capable of open-ended scientific research rather than just retrieval or narrow tasks.
It combines an LLM’s reasoning ability with numerical computation and a structured knowledge store called LANDAU (Layered Academic Data Universe), which keeps track of prior work, reliable methods, and past results.
Across several areas of physics, PhysMaster accelerates time-consuming research workflows, automates hypothesis testing, and even explores open-ended scientific problems on its own.
Read more about this research using this link.
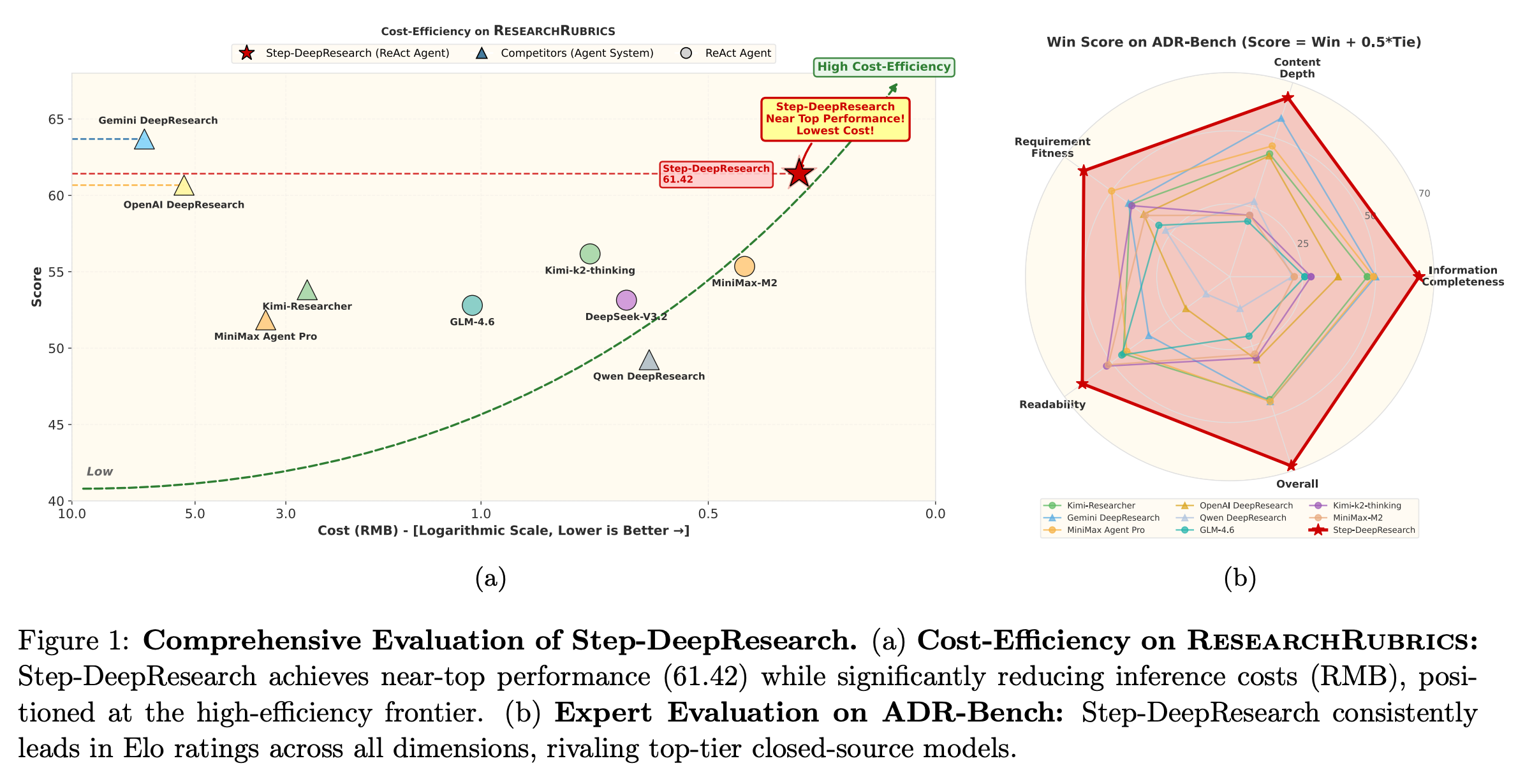
7. Step-DeepResearch Technical Report
This research introduces Step-DeepResearch, a cost-effective, end-to-end agent designed for realistic deep research tasks, including planning, long-term information gathering, cross-checking sources, and writing structured reports.
The authors use a progressive training pipeline that teaches the agent core research skills step by step, combining supervised learning and reinforcement learning with checklist-style evaluation.
They also introduce ADR-Bench, a new benchmark focused on realistic research scenarios.
Despite using a relatively small 32B model, Step-DeepResearch performs competitively with much larger systems (like OpenAI and Gemini DeepResearch) on research benchmarks, showing that strong training and agent design can matter as much as model size for deep research capabilities.
Read more about this research using this link.
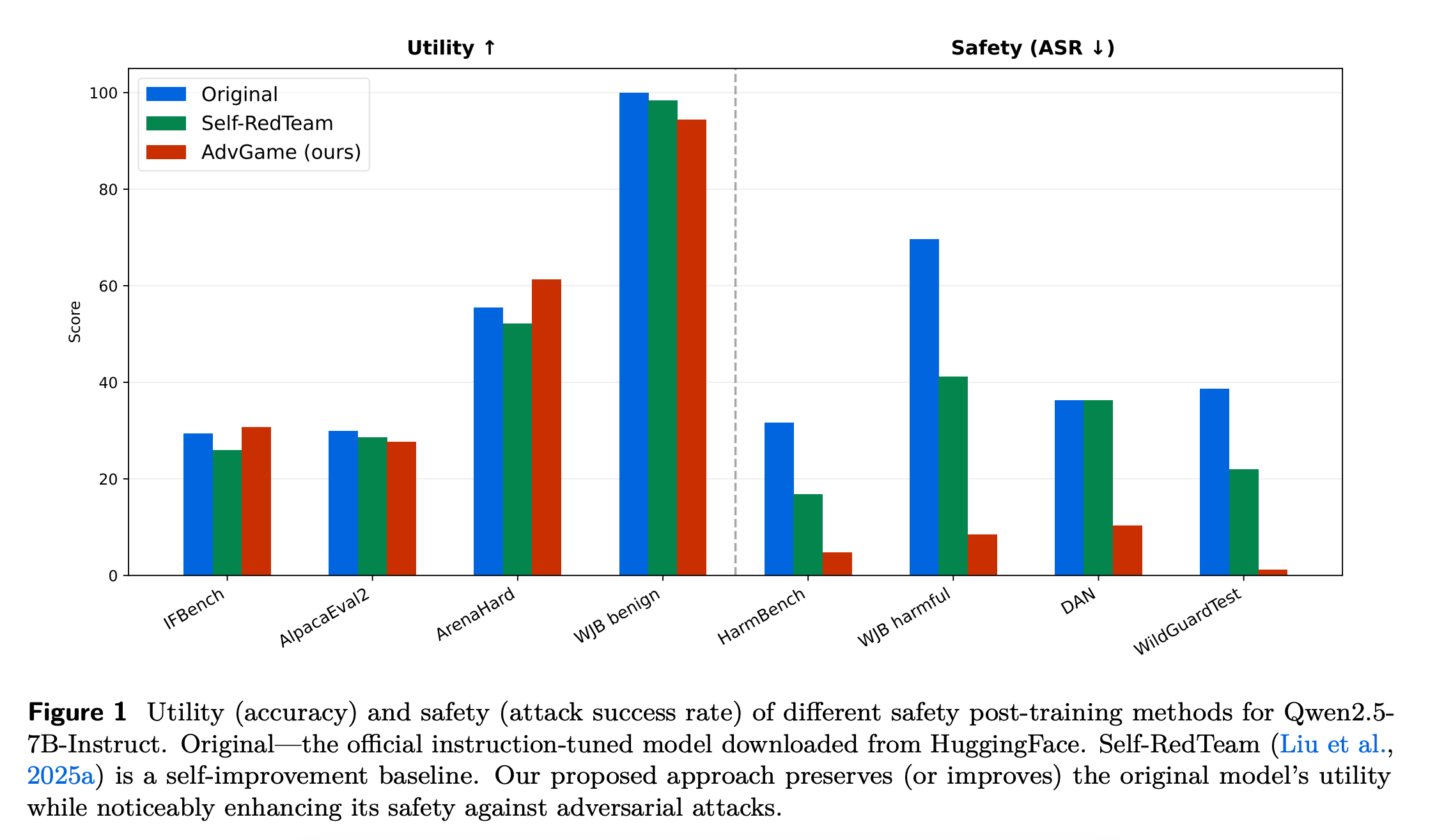
8. Safety Alignment of LMs via Non-cooperative Games
This research from Meta proposes a new way to align language models for safety without sacrificing usefulness by framing safety as a non-zero-sum game between two models: an Attacker LM and a Defender LM.
Instead of the usual cycle of generating adversarial prompts and fine-tuning against them, both models are trained jointly through online reinforcement learning so they continuously adapt to each other’s strategies.
Using the RL recipe called AdvGame, the Defender learns to be more helpful and more resilient to adversarial attacks. At the same time, the Attacker evolves into a strong, built-in red-teaming partner that can continuously stress-test and probe other models.
Read more about this research using this link.
9. MemR³: Memory Retrieval via Reflective Reasoning for LLM Agents
This paper introduces MemR³, a new memory system that helps LLM agents think more reflectively about what they know and what they still need to answer a question.
It uses a router that decides when to retrieve more or proceed to answer, and a global evidence-gap tracker keeps the process transparent and focused.
In experiments on benchmarks such as LoCoMo, MemR³ improves retrieval quality and answer accuracy over strong baselines, offering a plug-and-play way to make existing memory stores more effective.

Read more about this research using this link.
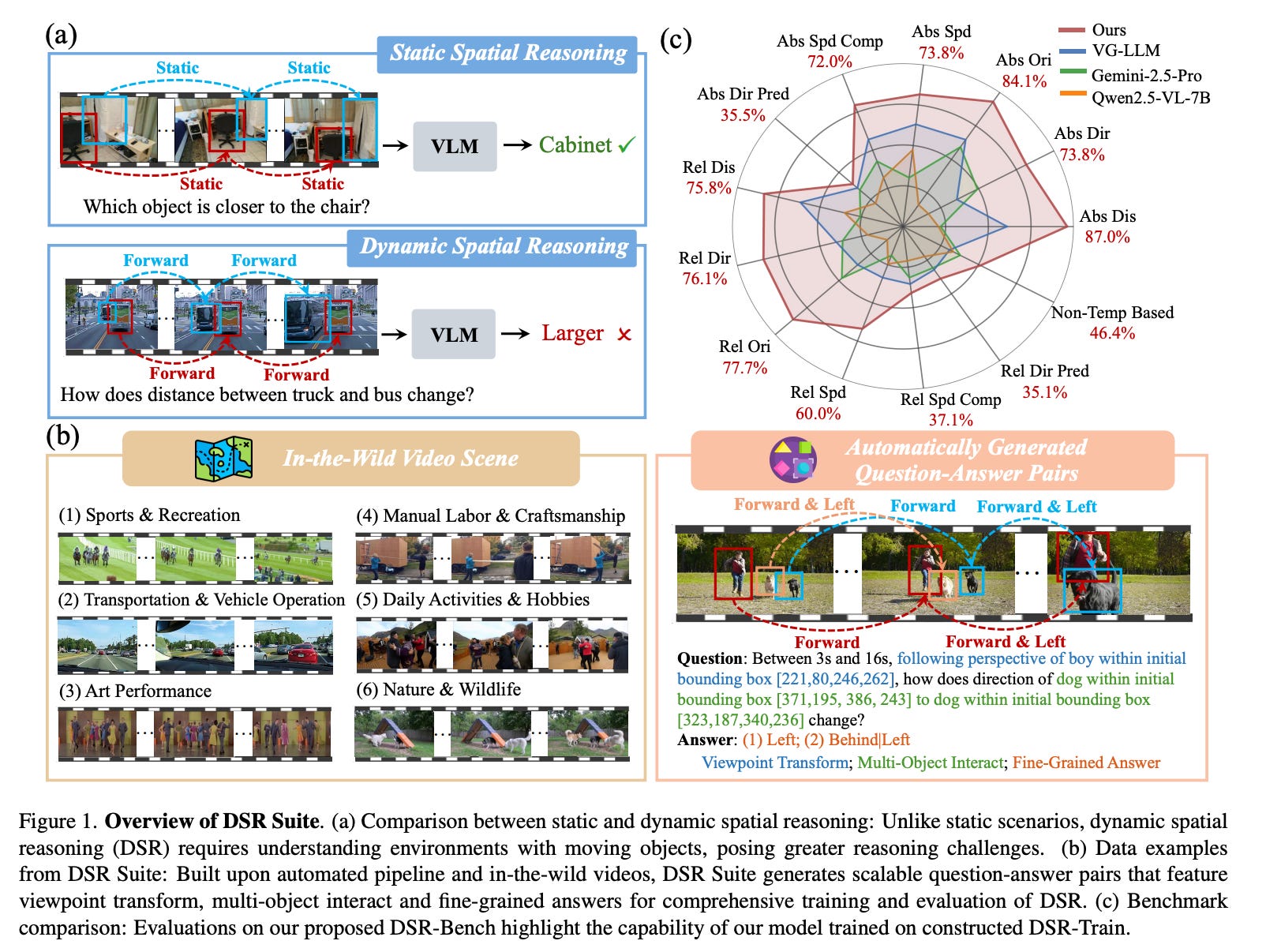
10. Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
Today’s vision-language models (VLMs) understand static scenes well but struggle to reason about how objects change over time in 3D space.
The authors address this by introducing the Dynamic Spatial Reasoning (DSR) Suite, which includes an automated pipeline for generating multiple-choice reasoning questions from real videos, directly capturing motion, geometry, object masks, and trajectories from in-the-wild footage.
They also design a lightweight Geometry Selection Module (GSM) that injects geometric information relevant to each question into VLMs without overwhelming them.
Together, these improve a base model’s ability to reason about object dynamics in 4D (3D space + time) while preserving strong performance on general video understanding benchmarks.
Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
If you want to get even more value from this publication, become a paid subscriber and unlock all posts, such as:



You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
