

🗓️ This Week In AI Research (4-10 Jan 26)
The top 10 AI research papers that you must know about this week.


1. AxiomProver
AxiomProver is an autonomous multi-agent ensemble theorem prover for Lean 4.21, developed by Axiom Math.
It autonomously and fully solved 12 out of 12 problems in Putnam 2025, the world’s hardest college-level math test, using the formal verification language Lean, 8 of which within the exam time.
A repository containing the solutions generated by AxiomProver can be found using this link.
A technical report will follow in the coming days, as per the team.

Read more about this achievement using this link.
Before we move forward, I want to introduce you to the Visual Tech Bundle.
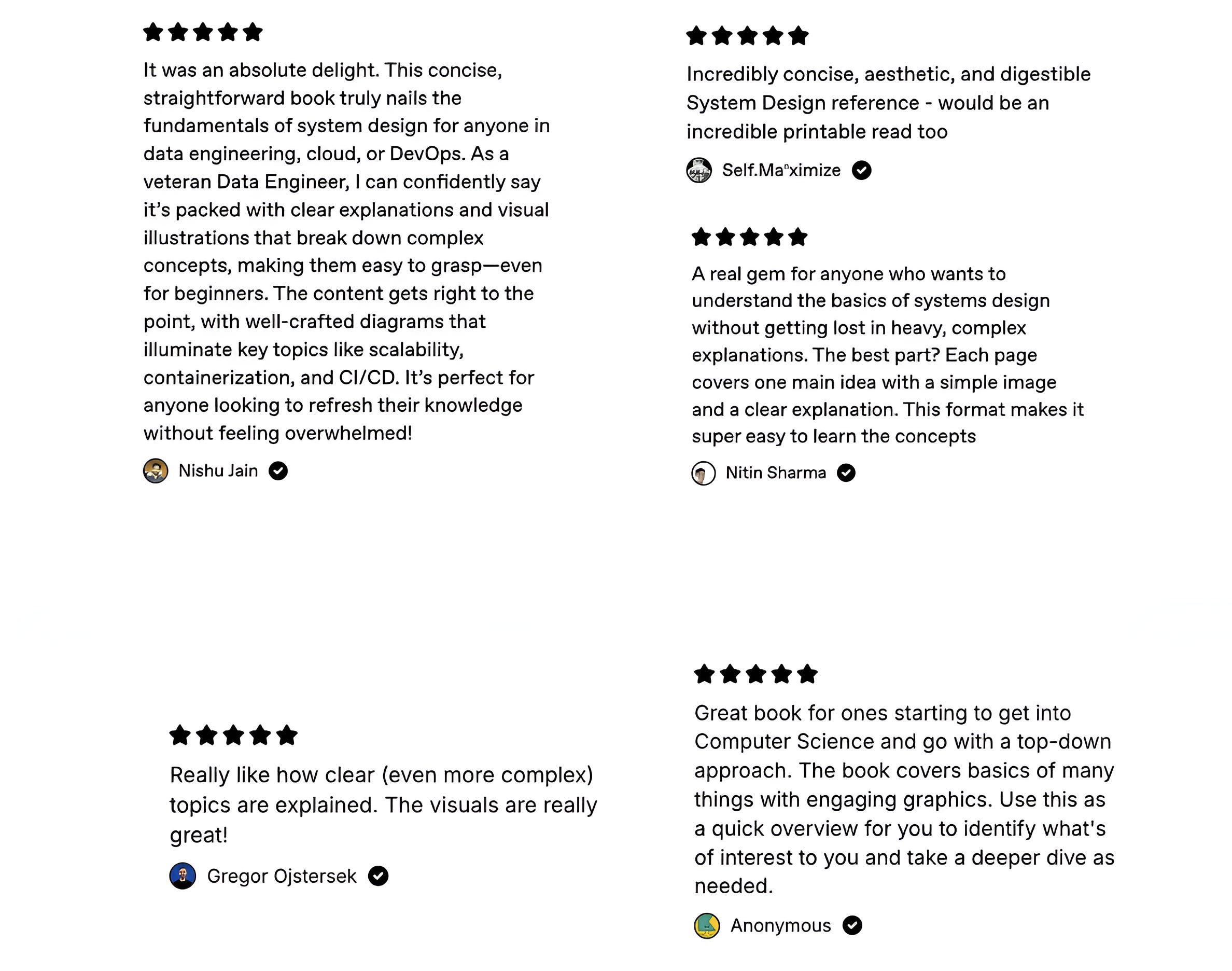
It is a collection of visual guides that explain core AI, LLM, Systems design, and Computer science concepts via image-first lessons.

Others are already loving these books.
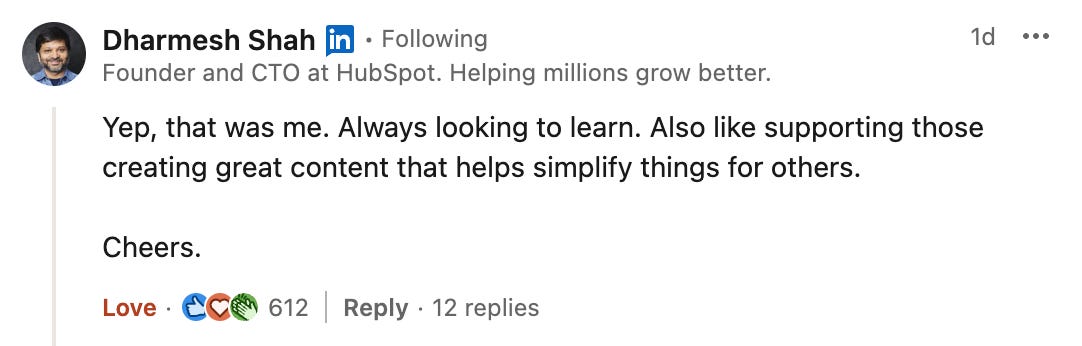
This includes Dharmesh Shah, the co-founder and CEO of HubSpot.
Why not give them a try?
2. A Survey on Agent-as-a-Judge
Evaluation is shifting from “LLM-as-a-Judge” to “Agent-as-a-Judge.”
As tasks grow more complex, single-pass LLM judges become less reliable because of bias, shallow reasoning, and no real-world verification.
The authors of this research paper propose using agentic judges that rely on planning, tools, memory, and collaboration among multiple agents to deliver more trustworthy evaluations.
The paper presents a classification of this change, reviews current systems and applications, and highlights key challenges and future research directions.

Read more about this research using this link.
3. GDPO: Group reward-Decoupled Normalization Policy Optimization for Multi-reward RL Optimization
This research paper from Nvidia presents a new RL policy optimization algorithm called Group reward-Decoupled Normalization Policy Optimization (GDPO).
GDPO addresses a major issue in GRPO for multi-reward RL.
GRPO collapses different rollout rewards into identical advantage values when used under a multi-reward setting, weakening learning and sometimes causing training to fail.
GDPO tackles this by normalizing each reward separately. This approach keeps their differences intact and creates a stronger training signal.
GDPO offers better stability and consistently performs better than GRPO in tool use, math reasoning, and coding tasks, measured by both correctness and adherence to constraints.

Read more about this research using this link.
4. Extracting Books From Production Language Models
This research paper from Stanford shows that copyrighted books can be extracted nearly word-for-word from major production LLMs, despite safety measures.
The authors develop a two-stage extraction method, starting with an initial probe (sometimes using Best-of-N jailbreaks), followed by iterative continuation prompts to attempt to extract the book.
They evaluate four production LLMs: Claude 3.7 Sonnet, GPT-4.1, Gemini 2.5 Pro, and Grok 3, and measure extraction success using a score computed from a block-based approximation of the longest common substring (nv-recall).
They find that large portions of text can be recovered from these LLMs (e.g., >95% nv-recall for jailbroken Claude Sonnet and high recall for others without jailbreaks).
This highlights that memorized training data can still be accessed, even with current safeguards, which raises ongoing copyright and privacy concerns.

Read more about this research paper using this link.
5. Learning Latent Action World Models In The Wild
This research from Meta presents world models that can learn action representations directly from real-world videos without needing action labels.
Traditional world models require labeled actions, which are hard to scale beyond simulations.
The authors train latent action spaces using “in-the-wild” videos and show that continuous, but constrained latent actions better capture complex behaviors than vector-quantized alternatives.
Additionally, a controller can map known actions into this latent space, helping with planning and achieving similar performance to action-conditioned baselines.
This approach makes action modeling more scalable for real-world agents.

Read more about this research using this link.
6. From Entropy to Epiplexity: Rethinking Information for Computationally Bounded Intelligence
This research paper proposes a new measure called Epiplexity to quantify the learnable information in data for real (computationally bounded) learners.
Traditional information theory (Shannon entropy, Kolmogorov complexity) assumes unlimited compute and thus fails to explain modern phenomena like how models extract structure from data or why data ordering matters.
Epiplexity identifies the important content that a bounded learner can actually use, distinguishing it from random unpredictability.
The authors demonstrate that using this framework, deterministic computation can generate useful information, the order of data impacts how easily it can be learned, and likelihood modeling can generate richer representations than what exists in the original data.
They also present practical methods for estimating epiplexity, which relates to downstream performance and provides guidance on data selection and transformation to enhance generalization.

Read more about this research paper using this link.
7. Constitutional Classifiers++: Efficient Production-Grade Defenses against Universal Jailbreaks
This research paper presents Constitutional Classifiers++, a more efficient and reliable jailbreak defense system for LLMs.
It builds on earlier Constitutional classifier methods by:
Developing exchange classifiers that assess model outputs within the full conversational context
Employing a two-stage classifier cascade that uses light-weight classifiers to screen traffic at a low cost and escalates only suspicious cases to more expensive classifiers
Training efficient linear probe classifiers and combining them with external classifiers to make the system both more robust and cheaper to run
These techniques together cut computational costs by about 40 times and maintain very low refusal rates of around 0.05% in production traffic.
Extensive red-teaming, totaling about 1,700 hours, demonstrates strong resistance to universal jailbreaks, with no attack consistently overcoming the defense.

Read more about this research using this link.
8. RelayLLM: Efficient Reasoning via Collaborative Decoding
This research paper presents RelayLLM, a method that improves reasoning by combining small and large language models at the token level.
Instead of sending entire queries to a large model, RelayLLM allows a small model to act as a controller that only calls the larger model when necessary for critical tokens, which significantly cuts down on computation.
A two-stage training method, consisting of warm-up and Group Relative Policy Optimization (GRPO), teaches the small model when to seek assistance.

In six benchmarks, RelayLLM narrows the performance gap between the two models while using the large model for only about 1.07% of tokens, resulting in roughly a 98.2% reduction in costs compared to performance-matched random routers.

Read more about this research using this link.
9. CoV: Chain-of-View Prompting for Spatial Reasoning
This research paper presents Chain-of-View (CoV) prompting, a training-free, test-time method that makes a vision-language model (VLM) into an active spatial reasoner for answering questions in 3D environments.
Standard VLMs can only handle a fixed set of input views, which limits their ability to perform complex spatial reasoning.
CoV solves this issue by using a View Selection agent to pick relevant frames. It then adjusts viewpoints through reasoning and discrete camera actions to collect the context needed for answering questions.

When tested on multiple benchmarks, CoV significantly boosts spatial reasoning performance. For instance, it shows an improvement of 11.56% on LLM-Match and achieves strong results on ScanQA and SQA3D, all without requiring extra training.
Read more about this research using this link.
10. SimpleMem: Efficient Lifelong Memory for LLM Agents
This research paper introduces SimpleMem, an effective lifelong memory system for LLM-based agents.
Current methods either keep full interaction histories, which is unnecessary, or depend on expensive reasoning to eliminate noise.
SimpleMem solves this with a three-stage pipeline that improves how memory is used and retrieved, comprising:
Semantic Structured Compression, which uses entropy-aware filtering to turn unstructured interactions into compact, multi-view indexed memory units
Recursive Memory Consolidation, an asynchronous process that combines related units into higher-level abstract representations to cut down on redundancy.
Adaptive Query-Aware Retrieval, which dynamically adjusts the retrieval scope based on query complexity to create precise context efficiently.

In benchmarks, SimpleMem improves accuracy with an approximate 26.4% F1 score improvement. At the same time, it reduces inference-time token usage by nearly 30 times. This creates a strong balance between performance and efficiency for long-term agent interaction.

Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
If you want to get even more value from this publication, become a paid subscriber and unlock all posts, such as:




You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
