

Using Cheaper Reasoning Models Is Probably Costing You More!
Relying on API costs is a big mistake that you must avoid making when running an LLM in production.

API costs are among the biggest factors when selecting a reasoning LLM for an application.
While one might think it is obvious that a model with a lower unit token price will have a lower total cost for any workload, what if I told you this assumption is completely wrong?
A model with lower API pricing can cost much more than a model with higher API pricing!
A recent paper published on this “Price Reversal phenomenon” tested 8 reasoning LLMs across 9 benchmarks. It found that for roughly one in five model-pair comparisons, the cheaper-listed model ended up costing more in practice.
Look at the following example, where one chooses GPT-5 Mini over Claude Haiku 4.5 due to its listed lower price, only to find out that it is 43% more expensive on their workload!
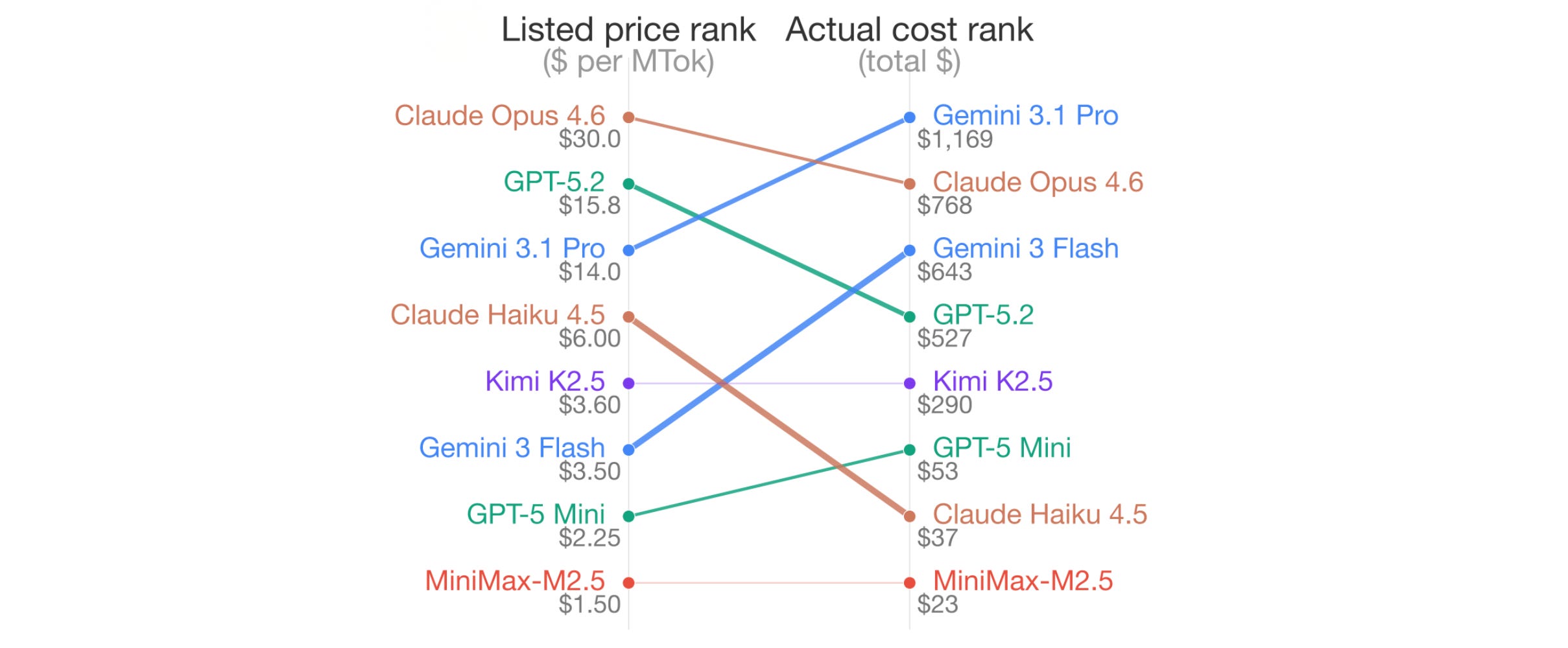
Another striking finding is that Gemini 3 Flash’s list price is $3.5 per 1 million tokens, which is 78% cheaper than GPT-5.2’s $15.75 per 1 million tokens.
In reality, the cost of Gemini 3 Flash is a total of $643, which is 22% higher than GPT-5.2's $527 across all benchmark tasks in the paper.
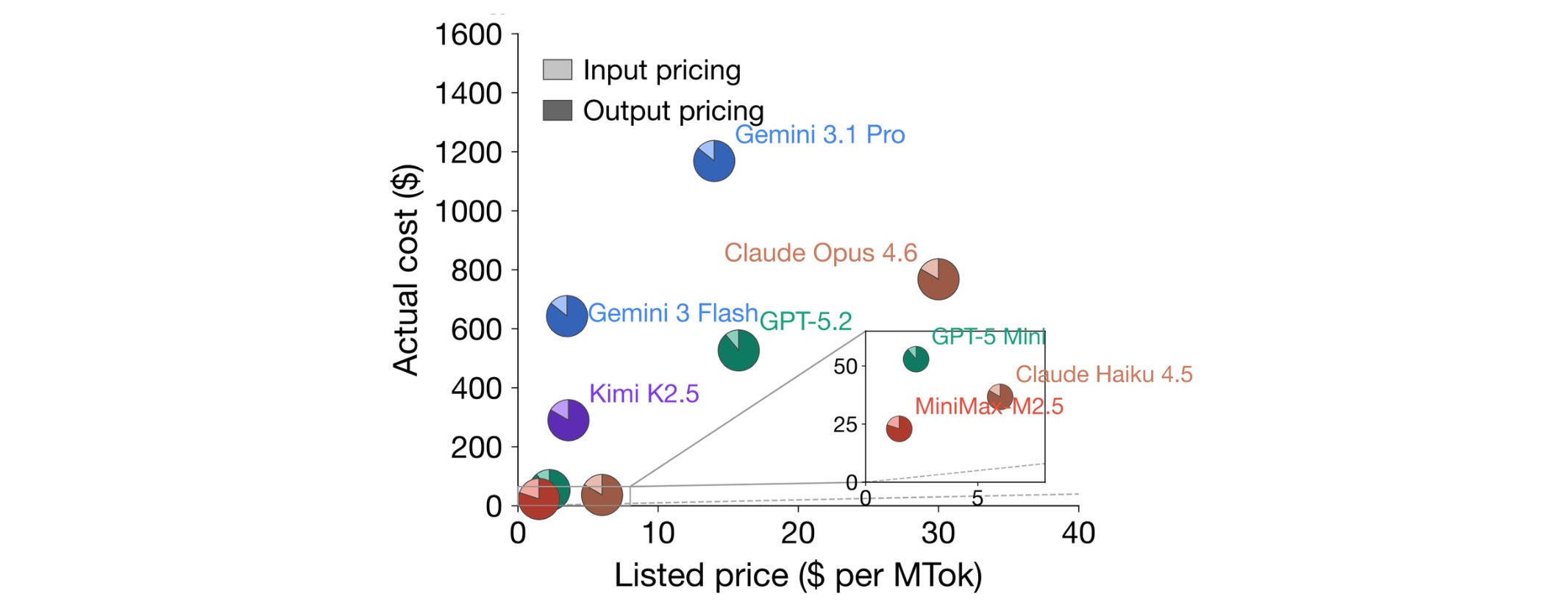
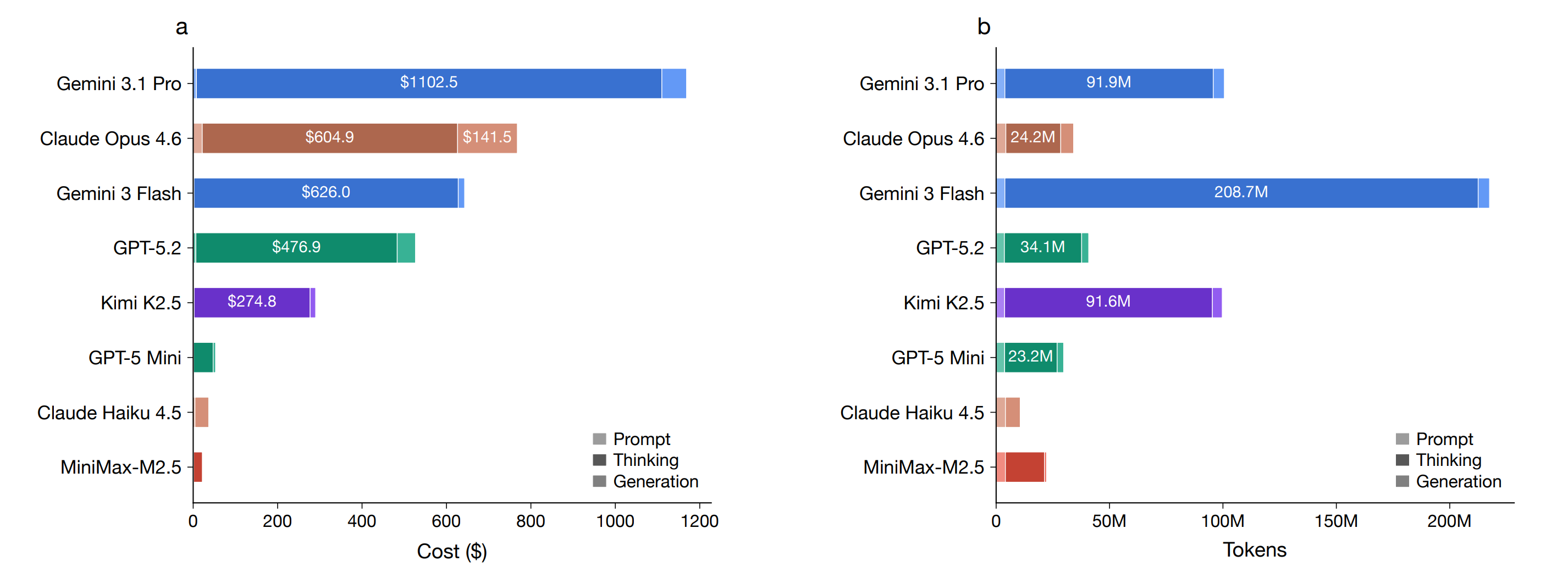
Furthermore, the mismatch between pricing and their actual costs for all models is shown below, with Gemini 3.1 Pro being the most expensive and MiniMax-M2.5 the cheapest overall.
Before we discuss the reason for this, it would be useful to know how model pricing really works and why people often get it wrong.
Are you calculating your model costs wrong?
LLM providers use a pay-as-you-go pricing model. This means that a user pays separately for each query they send to an LLM.
Each time a query is sent to the LLM, the user pays for:
What is sent in (input tokens)
What the model generates (output tokens)
Each of these has a different price per million tokens.
An example of the pricing model for OpenAI model APIs is shown below.

For a given query, the cost is the sum of the unit input token and output token prices weighted by the number of input and output tokens, respectively.

This means that the total cost is the sum of:
how long the user prompt is (input tokens)
how long the model’s answer is (output tokens)
If one runs N queries when evaluating a model on a benchmark, the total cost is the sum of the cost of each query.
Since in practice, users often don’t know how many tokens a model will produce before running it, they use a mental shortcut as follows:
Listed price ≈ Input price + Output price
And this is what makes all the difference in price. Let’s learn how.
What’s causing the price mismatch?
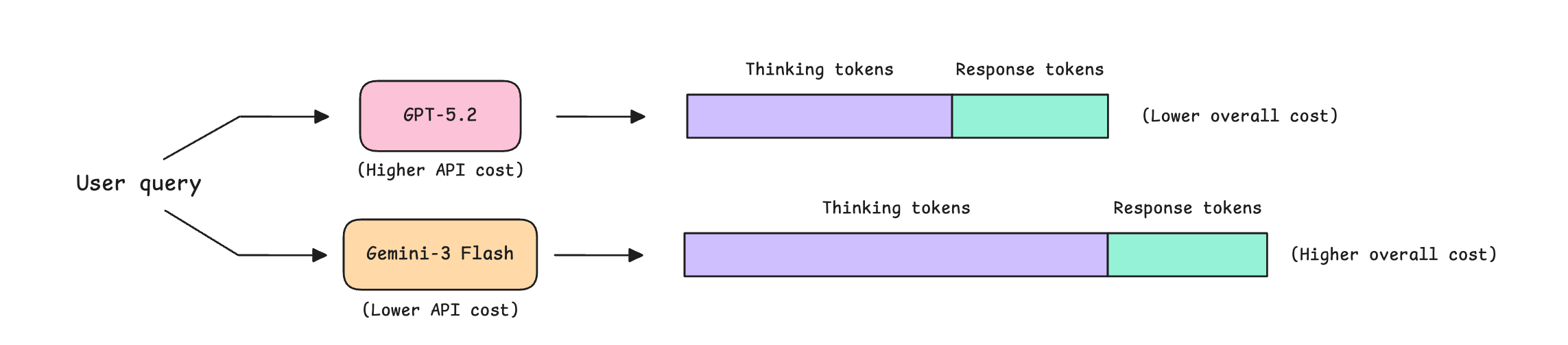
For a given user query, a reasoning LLM outputs a set of reasoning trails (consisting of thinking tokens) and then a final response.

The issue is that different models produce very different amounts of thinking tokens for the same tasks. And since these thinking tokens account for the majority of output tokens, they drive the majority of actual cost.
You might think that these differences in thinking token production might be small, but here is an example that is going to blow your mind.
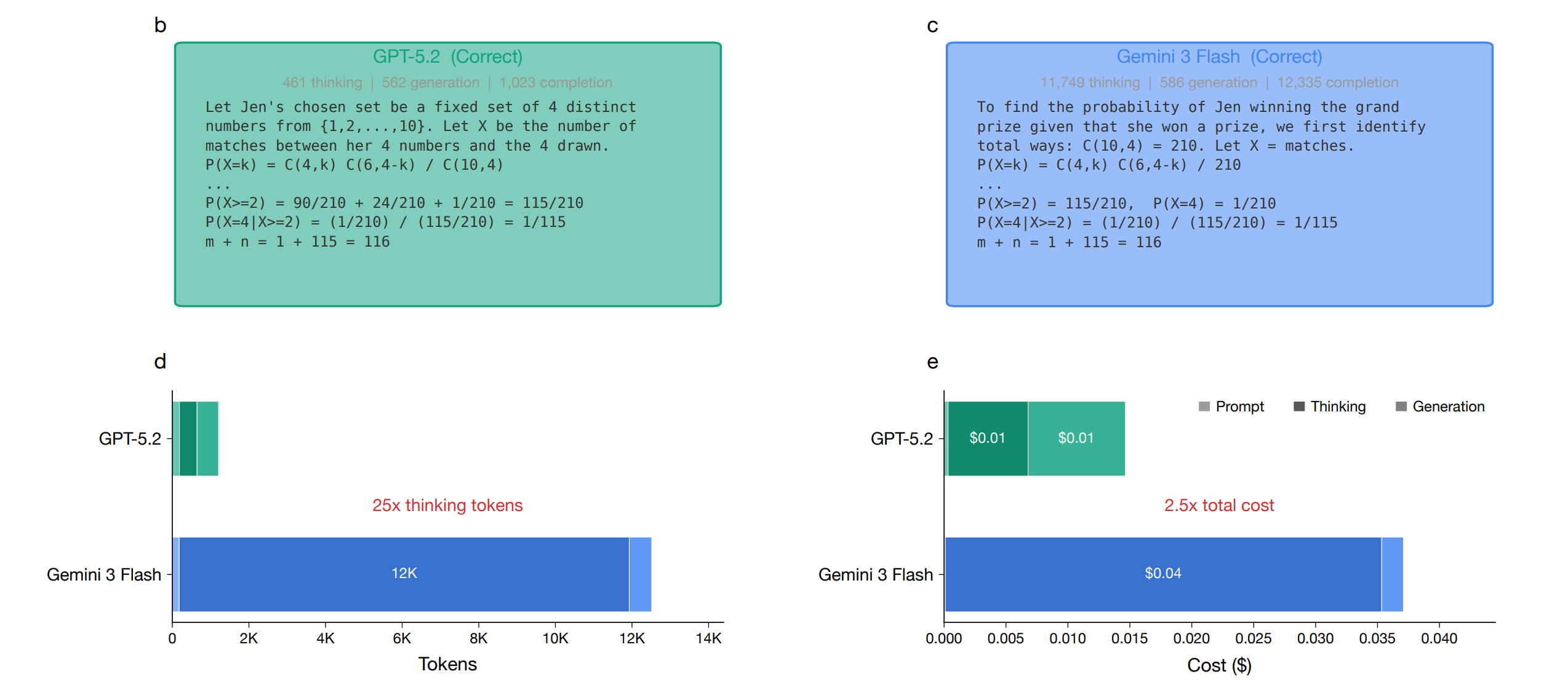
Given an AIME 2025 question, both GPT-5.2 and Gemini 3 Flash are asked to solve it using a similar approach. Although both arrive at the correct answer but:
GPT-5.2 produces only 461 thinking tokens
Gemini 3 Flash produces over 11,000 tokens
Even though Gemini 3 Flash has a lower per-token price than GPT-5.2, the 25x gap in thinking token generation results in a 2.5× higher actual cost to solve this question!
How to reliably predict costs then?
Unfortunately, this is a hard problem to solve. This is because:
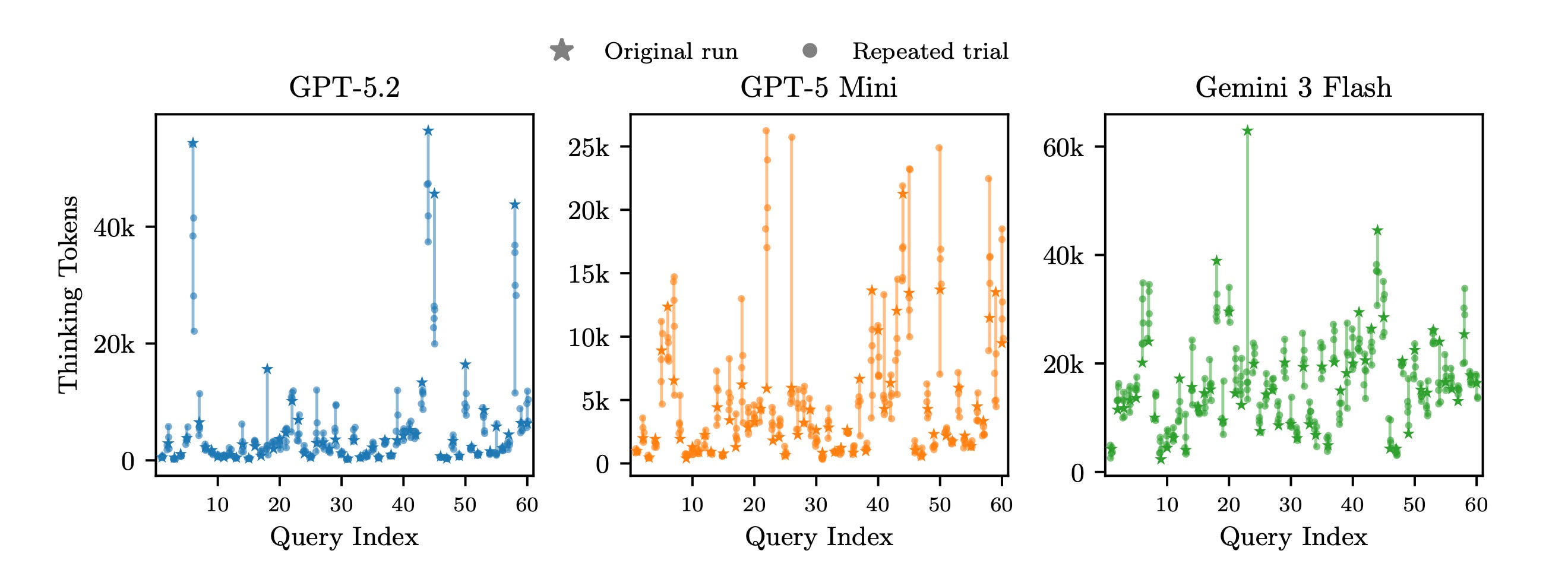
Different models produce different numbers of tokens for the same query/ task
Even the same model can produce largely different numbers of tokens in different runs for the same query/ task
There’s one thing that you can do as a developer, though: You must not pick models blindly based on the listed API price.
The only solution currently is to test different models on your specific queries and measure the actual cost. This is especially true for complex reasoning tasks, where the generation of thinking tokens varies the most.
I hope this helps you save some money on your API costs!
Join the paid tier today to get access to all posts on this newsletter:
and so many more!
Haiku is pretty impressive for well scoped tasks. Like, if you are not lazy and expect and LLM to de everything and really put the effort in design and definition (with opus or sonnet help of course), then haiku guided with rules and standards and templates and go quite far.
Great article!
I think it’s very hard to select one model based on a simple query (can be complex too). Because the query can change over time during the development. I think one way is try to arise an system from “zero to deploy “, and trying to use and compare different models. Just to experiment. It’s hard to imagine how can do that all the time.