

This Week In AI Research (1-6 June 26) 🗓️
The top 10 AI research papers that you must know about this week.


10. Dreaming: Better memory for a more helpful ChatGPT
OpenAI released its more capable and scalable system for synthesizing memory in ChatGPT, called Dreaming.
Dreaming is a method used by ChatGPT to automatically curate memories in the background by referencing chat history.
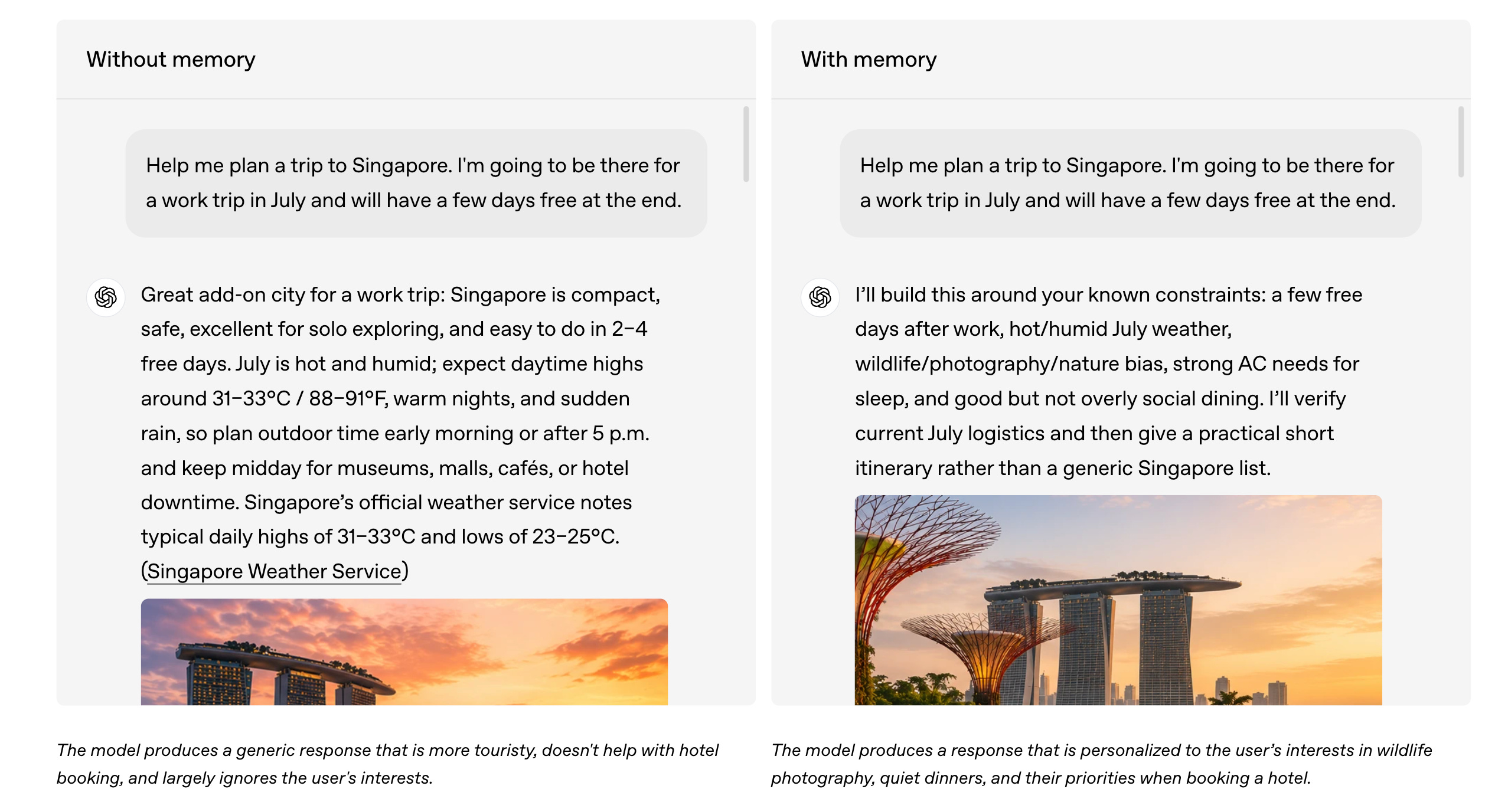
The newly released Dreaming system:
Retains useful user context more effectively
Helps ChatGPT better follow user preferences and constraints
Stays up-to-date as situations change
Users can also review their memories through a summary page, where they can see, update, and correct what ChatGPT remembers about them.

Read more about this release using this link.
Into AI is a reader-supported newsletter. Gain access to deeper, members-only content by becoming a paid subscriber today.
9. MAI-Thinking-1: Building a Hill-Climbing Machine
Microsoft introduced MAI-Thinking-1, a reasoning model built from scratch based on the Latent Mixture-of-Experts architecture with 1T parameters (35B active).
It is the first model developed using the Hill-climbing machine. This is an iterative system for building and improving data pipelines, training infrastructure, RL environments and rewards, evaluation suites, and safety tests, which allows advancing AI while grounding progress around human needs from the ground up.
MAI-Thinking-1 performs strongly among models of similar size on STEM reasoning and coding tasks (52.8% on SWE-Bench Pro, 97.0% on AIME 2025, and 87.7% on LiveCodeBench v6).
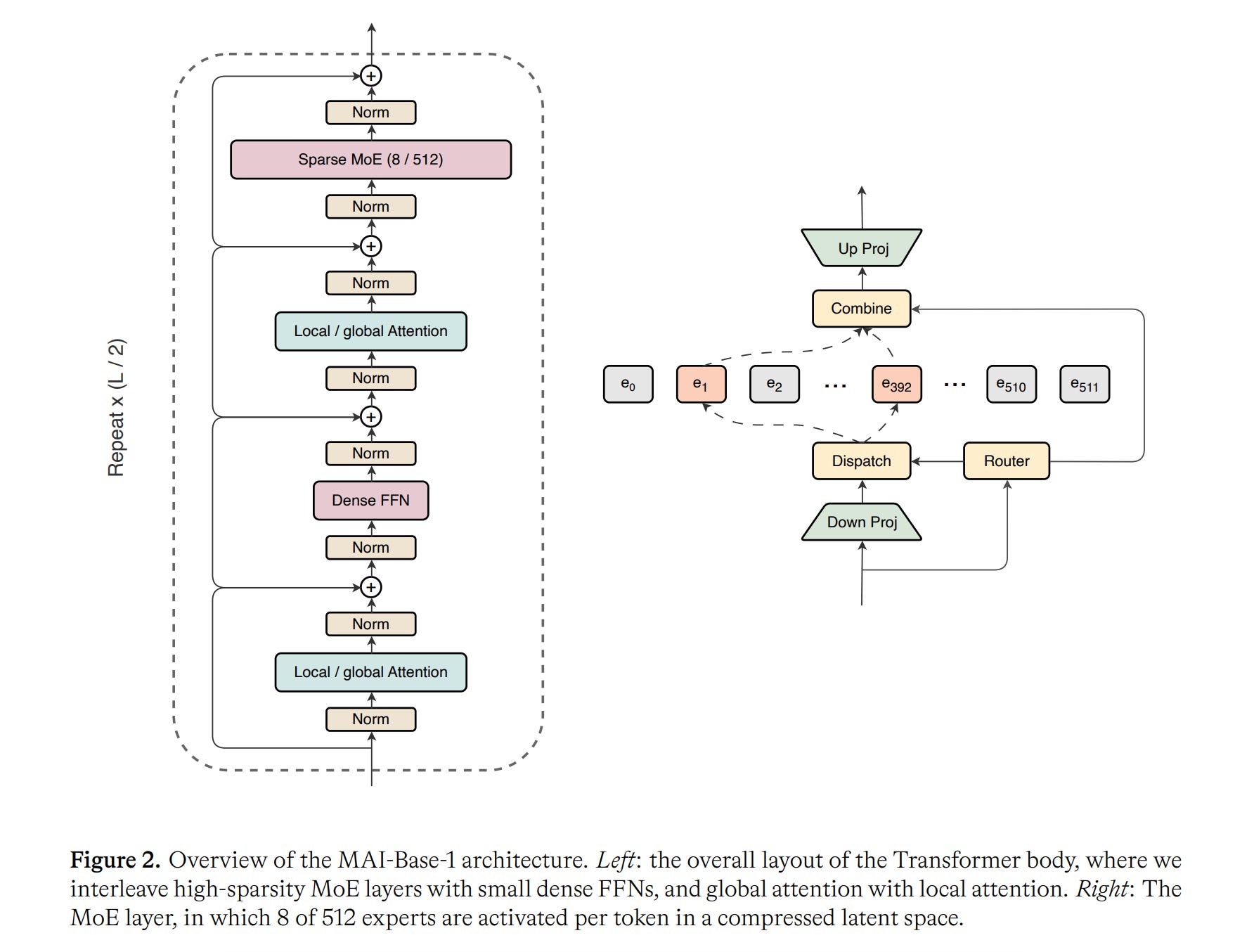
Read more about this research paper using this link.
8. Benchmark Everything Everywhere All at Once
This paper introduces the Benchmark Agent, a fully autonomous agentic system for building benchmarks. This system can orchestrate a complete benchmark construction pipeline, from user query analysis and subtask design to data annotation and quality control.
Evaluations with multiple experiments (human evaluation, LLM-as-a-judge assessment, and consistency checks) show that Benchmark Agent can generate high-quality benchmarks across text, multimodal, audio, image, and domain-specific reasoning tasks with minimal human involvement.

Read more about this research paper using this link.
7. Audio Interaction Model
This research paper introduces Audio-Interaction, a single model that unifies offline audio tasks (such as speech recognition, translation, and audio Q&A) with real-time streaming tasks (such as live voice chat and proactive response).
The model operates using an always-on ‘perceive-decide-respond’ loop, continuously listening to sound, the environment, and instructions, and deciding when to respond based on streaming semantics. The model can manage real-time ASR, streaming audio instruction following, voice dialogue, and proactive help.

To make this Audio Interaction model possible, researchers use Soundflow, an end-to-end framework for streaming-native data construction, comprehension-aware training, and asynchronous low-latency inference.
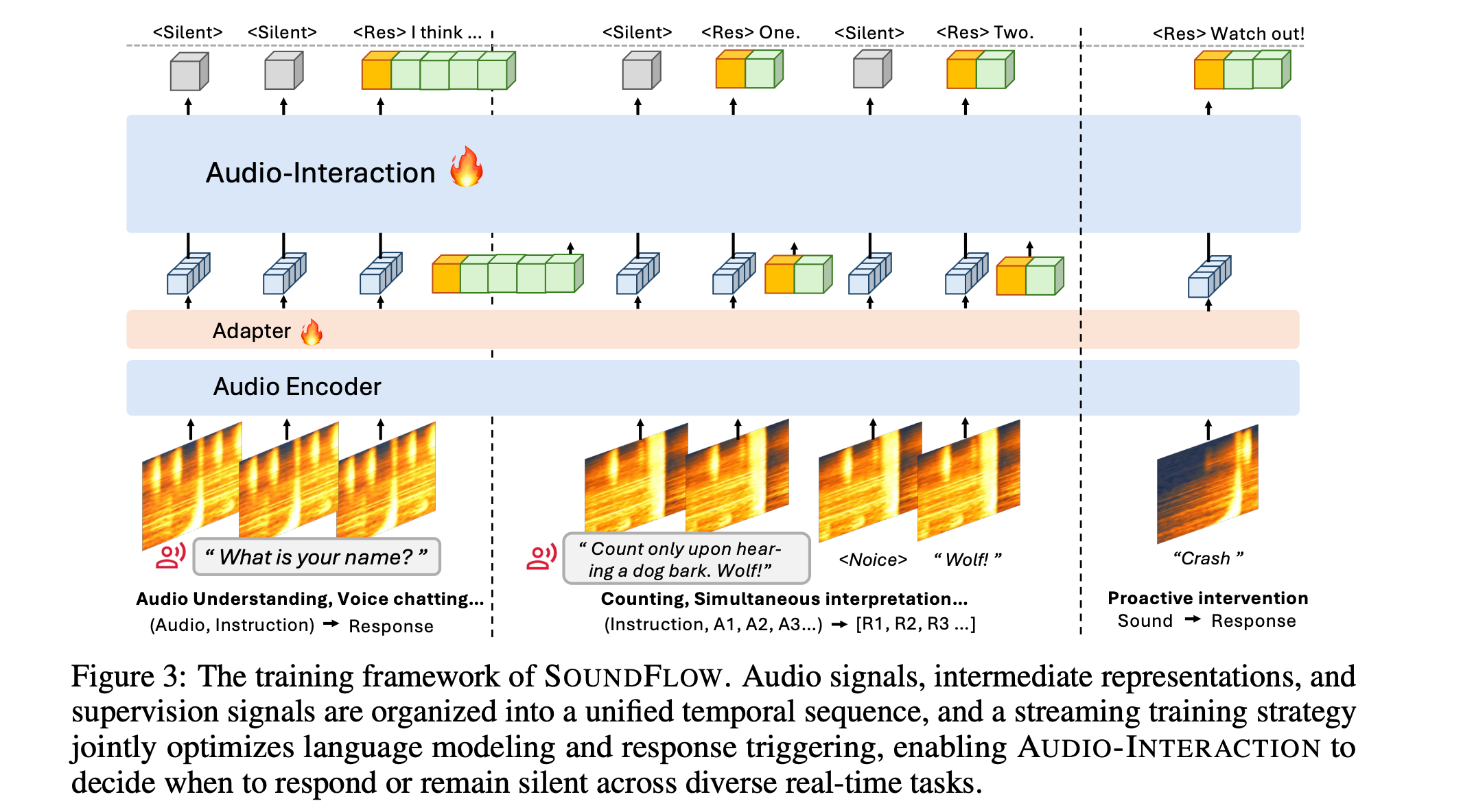
Across 8 benchmarks, Audio-Interaction has competitive performance on mainstream audio tasks while offering capabilities previously inaccessible to Large Audio Language Models (LALMs).
Read more about this research paper using this link.
6. Reasoning Structure of Large Language Models
LLMs are usually evaluated using metrics such as final-answer accuracy or token count, but even with identical scores, these models can have fundamentally different reasoning structures.
This research paper addresses this problem by introducing a scalable logic-puzzle benchmark and a pipeline that converts unstructured reasoning traces into verifiable reasoning graphs of claims and dependencies, whose topology can be quantitatively analyzed.
Building on this, a reasoning-efficiency metric is defined to quantify the concentration of the model’s logical flow. This acts as a practical tool for diagnosing failure modes and comparing how reasoning scales with puzzle difficulty.
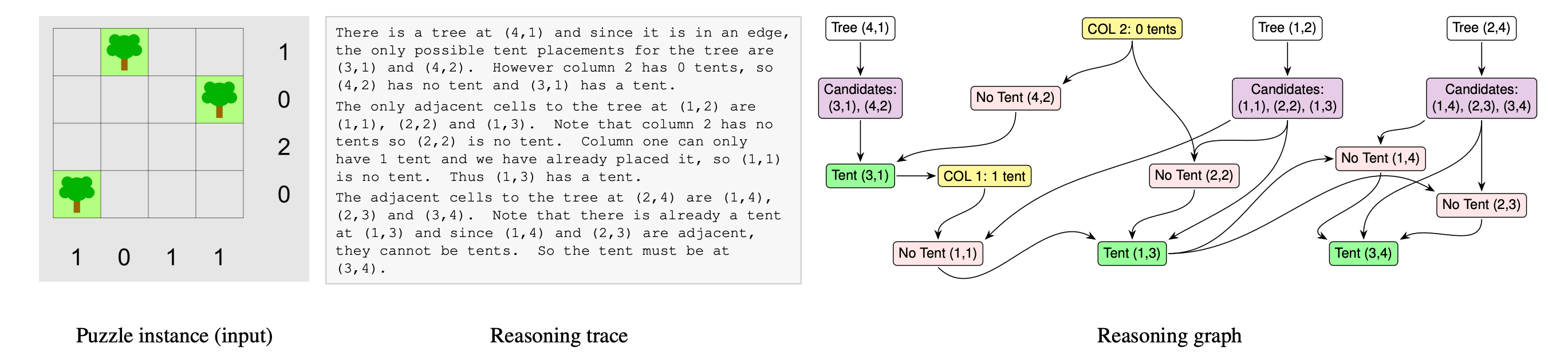
Read more about this research paper using this link.
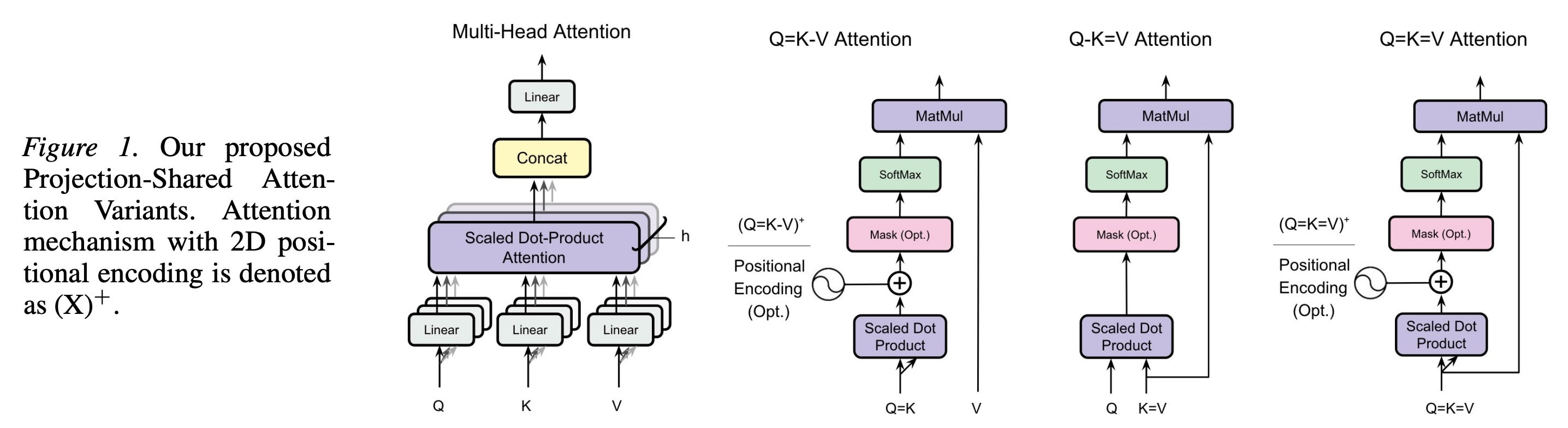
5. Do Transformers Need Three Projections?
This research paper examines whether the standard Transformer attention really needs separate query, key, and value projections.
This is done by comparing three types of shared projections:
Q-K=V (Shared key-value)
Q=K-V (Shared query-key)
Q=K=V (Fully shared single projection)
Experiments across synthetic tasks, vision, and language modeling show that Transformers with shared projections perform on par with, or occasionally better than, the standard Transformer.
In language modeling, shared key-value projection (Q-K=V) achieves a 50% KV cache reduction with only a 3.1% increase in perplexity.
These transformers also preserve attention directionality because keys and values can share similar representation spaces and attention operates in a low-rank regime.
Since projection sharing is complementary to head-sharing (GQA/MQA), combining Q-K=V with GQA-4 and MQA leads to cache reductions of 87.5% and 96.9%, respectively. This has direct, quantifiable benefits for inference memory, which are especially valuable for edge deployment of LLMs.
Read more about this research paper using this link.
4. Nemotron 3 Ultra
NVIDIA introduced its most capable model yet, called Nemotron 3 Ultra. This is a 550B-parameter (55 billion active) Mixture-of-Experts Hybrid Mamba-Attention language model with a 1M-token context window.
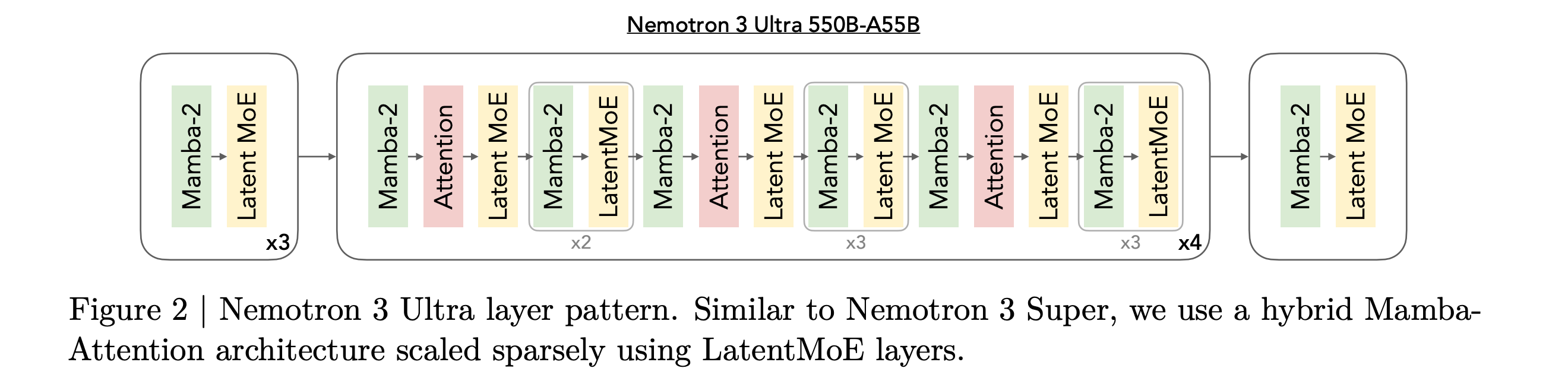
Nemotron 3 Ultra combines multiple key technologies such as:
Latent-MoE architecture
Multi Token Prediction (MTP)
NVFP4 pre-training
Multi-environment RLVR
Multi-teacher On-Policy Distillation (MOPD) for post-training
Reasoning budget control
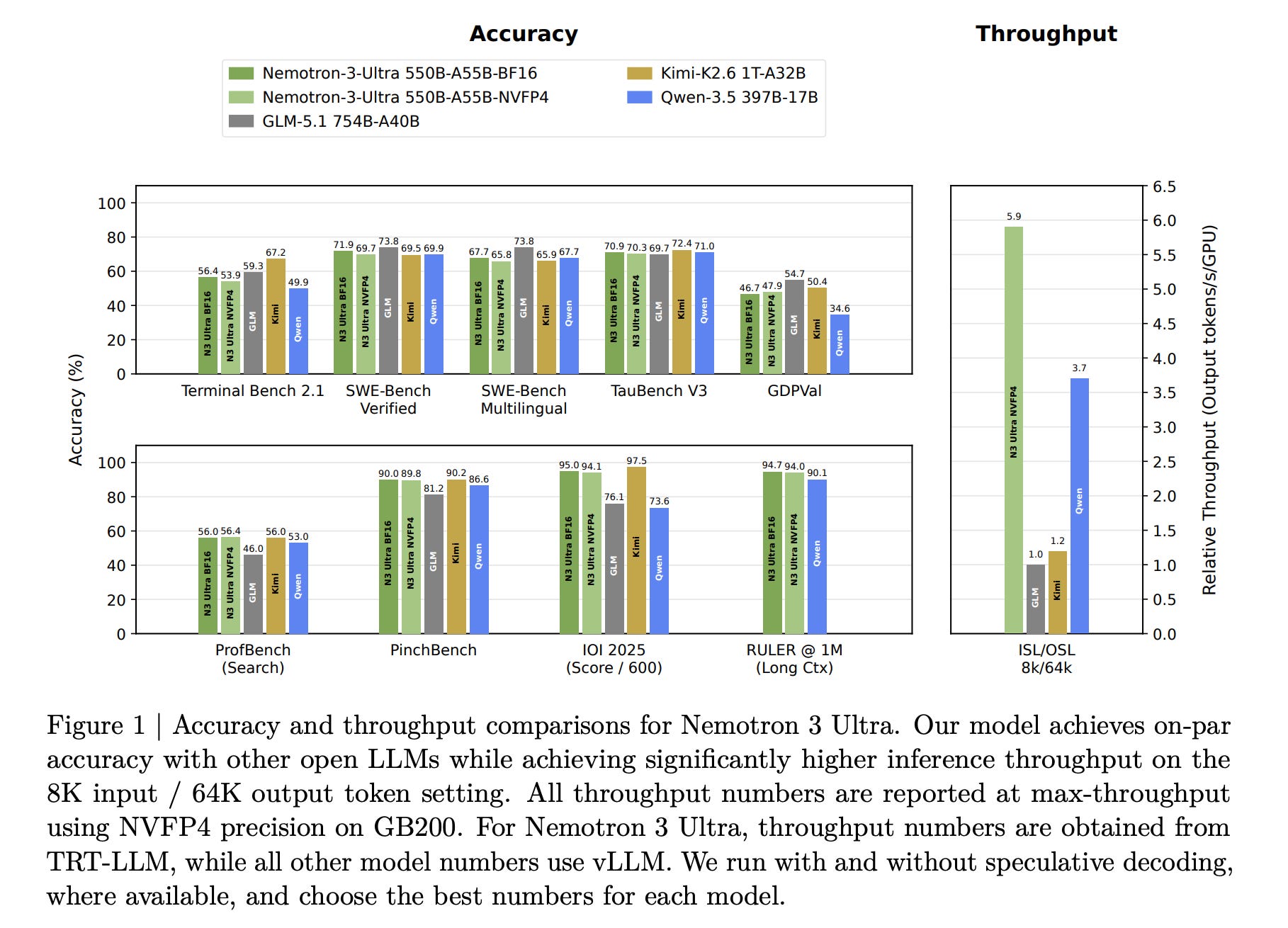
Nemotron 3 Ultra delivers up to 6× higher inference throughput than SOTA publicly available LLMs while achieving similar accuracy, which makes it ideal for long-running autonomous agentic tasks.
Read more about this research paper using this link.
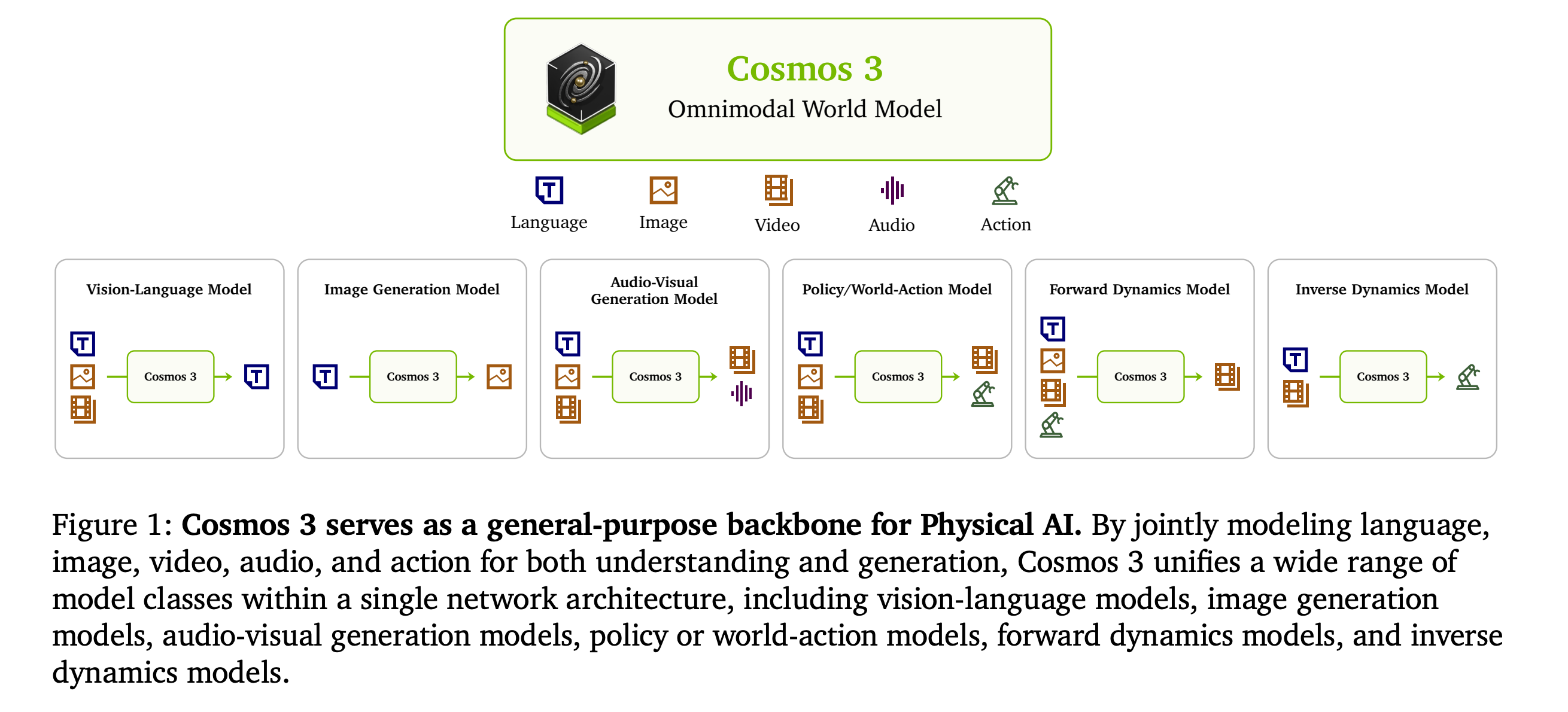
3. Cosmos 3
This research paper introduces Cosmos 3, a family of omnimodal world models by NVIDIA. These models are designed to jointly process and generate language, image, video, audio, and action sequences using a single Mixture-of-Transformers architecture.
The goal of the model is to serve as a general-purpose backbone for physical AI, combining capabilities that are usually split across vision-language models, video generators, world simulators, and robot policy/action models.
Cosmos 3 achieves SOTA results across multiple understanding and generation tasks, and the post-trained Cosmos 3 models are ranked as the best open-source Text-to-Image and Image-to-Video models by Artificial Analysis and the best policy model by RoboArena.
Read more about this research paper using this link.
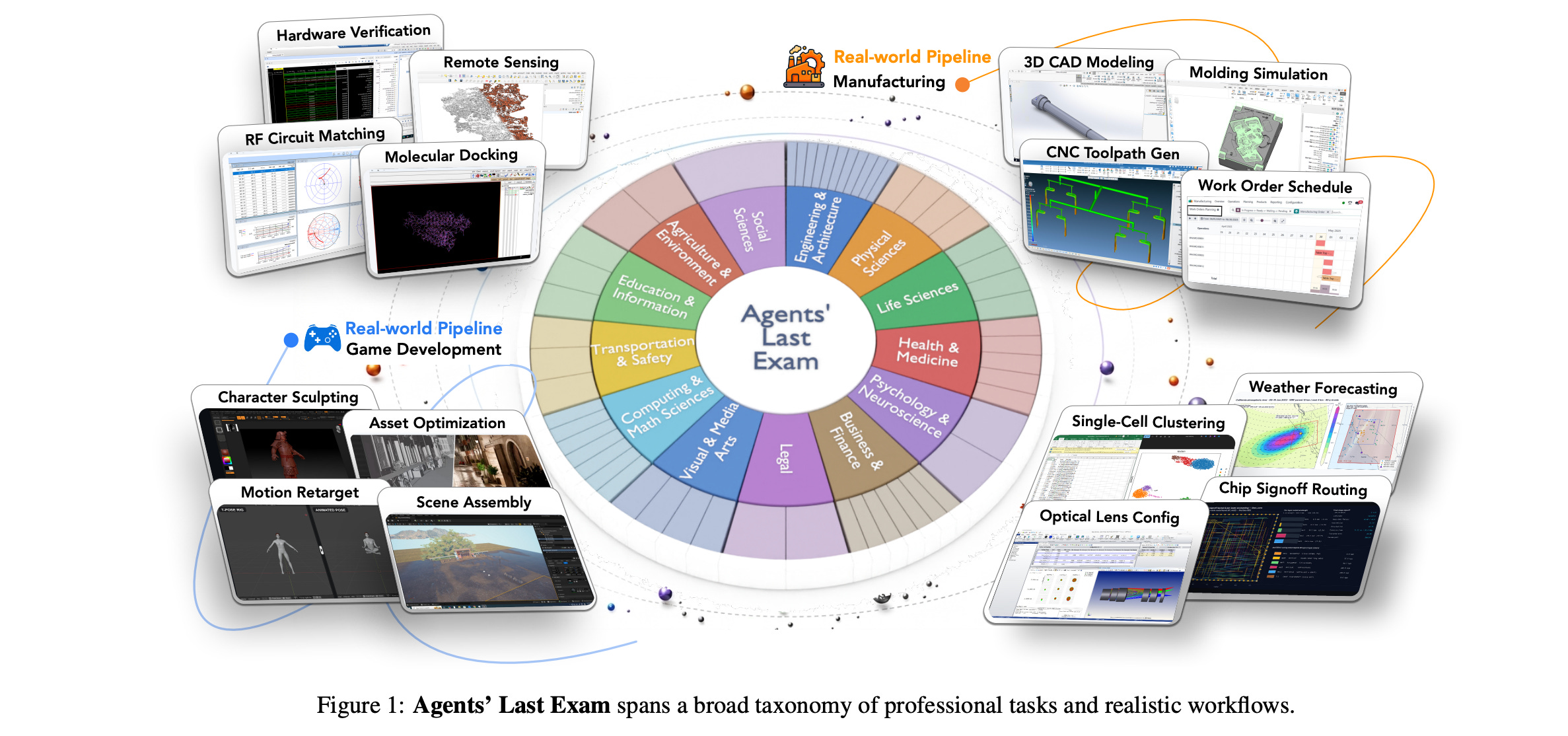
2. Agents’ Last Exam
This research paper introduces Agents’ Last Exam (ALE), a benchmark designed to evaluate AI agents on long-horizon, economically valuable, real-world tasks with verifiable outcomes.
Built by 250+ industry experts, it spans 55 targeted sub-industries and includes 1,500+ tasks covering most major fields of professional work performed on a computer.
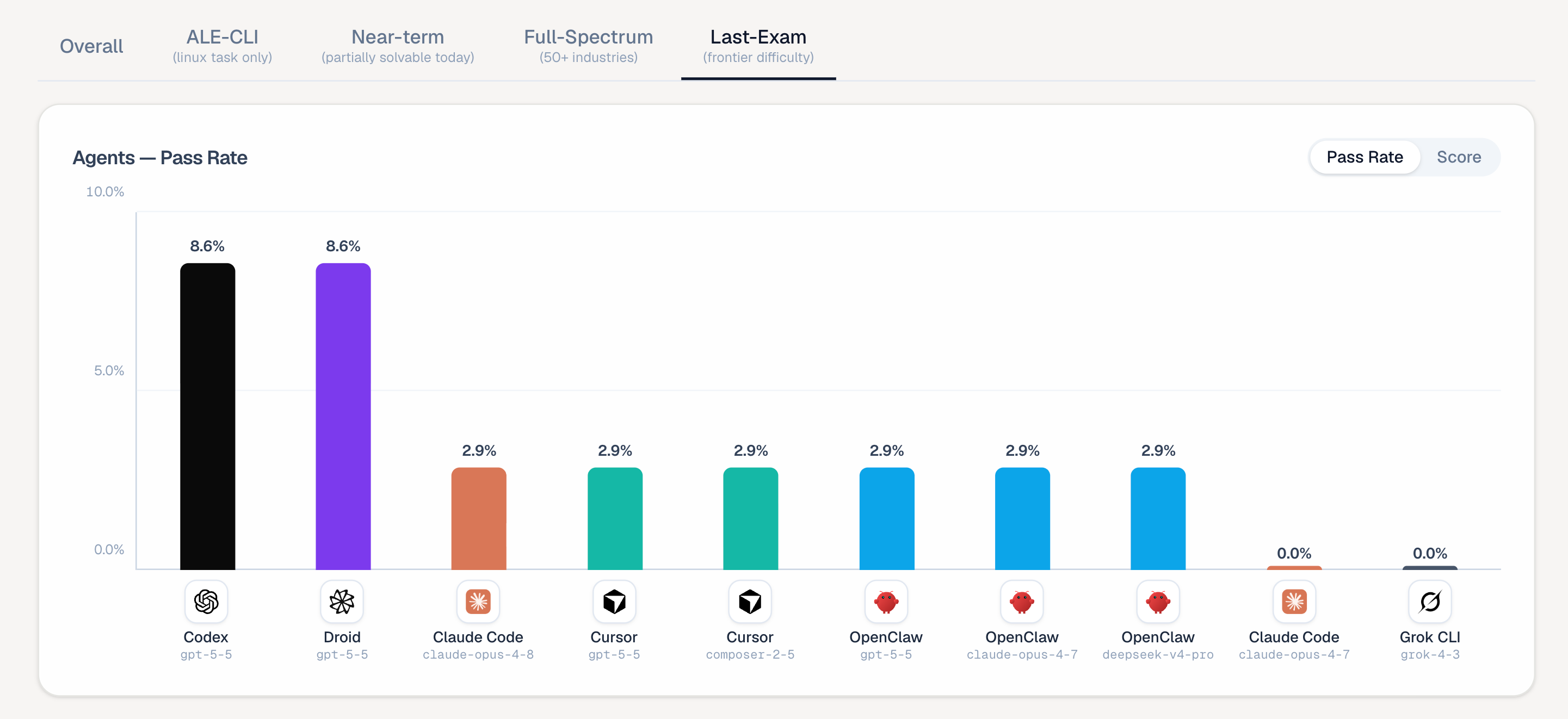
Results show that today’s mainstream agentic models are still far from solving the toughest tasks on this benchmark, with an average full pass rate of only 2.6%.
Rather than serving as a static benchmark, ALE is intended to grow continuously as new workflows and industries are onboarded, making it a tool for measuring real-world agent capability relevant to GDP impact.
Read more about this research paper using this link.
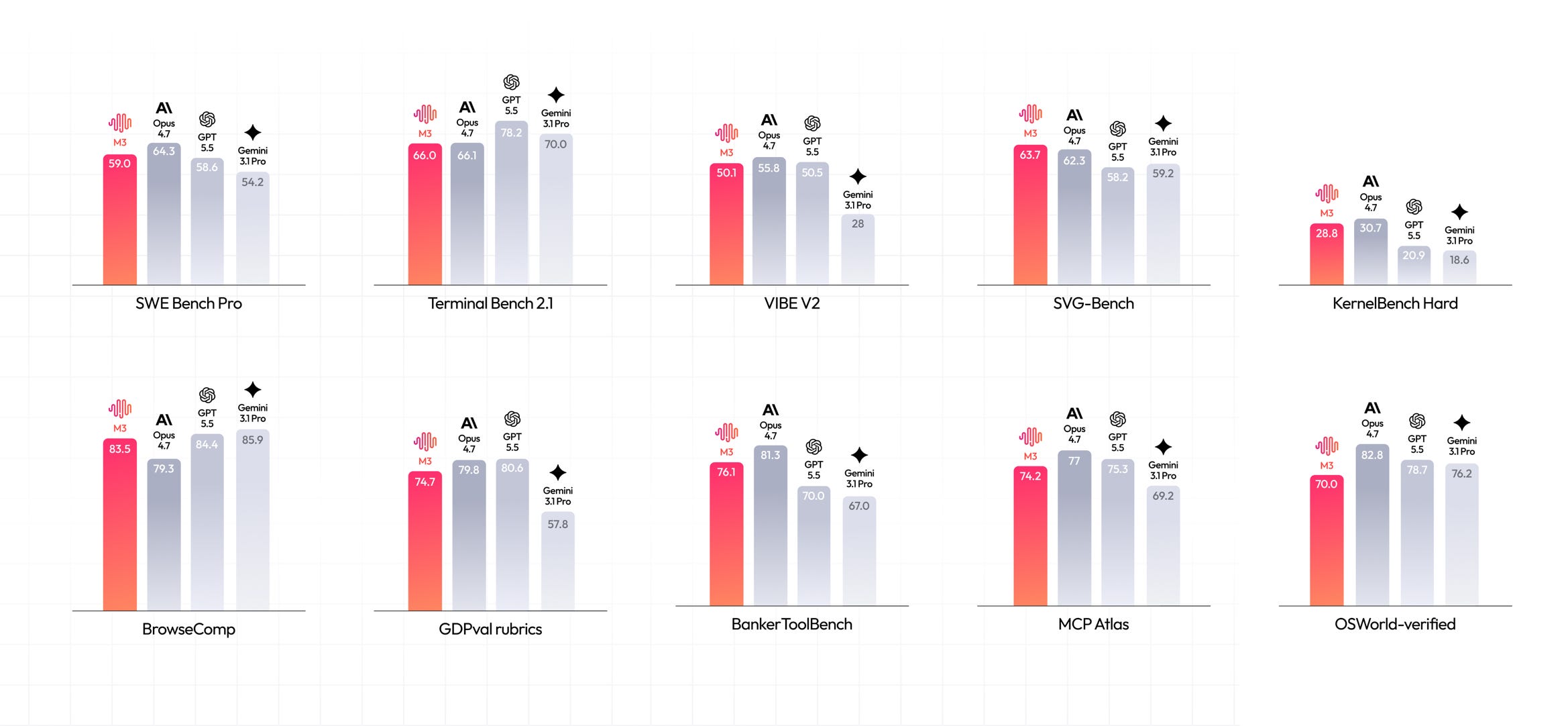
1. MiniMax M3
This blog post introduces MiniMax M3, currently the first and only open-weight model that brings the following three capabilities together:
Frontier-level performance on specialized tasks such as coding and agentic work
Ultra-long context windows of up to 1M tokens
A natively multimodal model that supports image and video input and can operate on a desktop computer
The model uses MiniMax Sparse Attention (MSA), a sparse attention mechanism that enables long-context processing at a much lower per-token compute and large speedups in prefill and decoding.
MiniMax M3 surpasses GPT-5.5 and Gemini 3.1 Pro and approaches Opus 4.7 on SWE-Bench Pro.
On SVG-Bench, an internal benchmark that comprehensively evaluates SVG generation performance, MiniMax M3 surpasses Opus 4.7.
M3 also achieves top scores on Claw-Eval, an end-to-end evaluation framework for autonomous agents, and on OmniDocBench, a multimodal benchmark.
Read more about this release using this link.
This newsletter edition is completely free to read.
If you found it valuable, click the like button ❤️ and consider subscribing for more such content every week.
If you have any questions or suggestions, feel free to leave a comment below.
Into AI is a reader-supported newsletter. Gain access to deeper, members-only content by becoming a paid subscriber today.