

Build Grouped Query Attention (GQA) From Scratch
Learn to implement Grouped Query Attention (GQA) from scratch, the de facto standard for modern LLMs like Llama, Mistral, GPT-OSS, and Qwen.


🎁 Here's your 25% off the annual membership. Unlock every lesson in the newsletter and accelerate your AI engineering career. Claim your discount now!
In the previous lessons on 'Into AI’, we learned to implement Self-attention and progressively updated it to reach Causal Multi-head Self-attention (MHA), which is used in LLMs like GPT-2.



MHA is a powerful architectural component that enables LLMs to process tokens in parallel, making fast autoregressive text generation possible. But it comes with high memory costs and latency.
We then learned how to build Multi-Query Attention (MQA), an efficient variant of MHA that significantly reduces memory usage and speeds up inference.

It’s now time to improve the architecture further and learn to build Grouped Query Attention (GQA).
What is Grouped Query Attention (GQA)?
In the conventional attention or Multi-Head Attention (MHA), each head has its own Q, K, and V vectors.
In Multi-Query Attention (MQA), all attention heads share the same key (K) and value (V) vectors, while each head still has its own query (Q) vector.
This reduces the KV cache size and memory requirements, leading to much faster inference.
MQA is fast and efficient, but it isn’t perfect. Because all heads share the same Keys and Values, this reduces the effectiveness of learned representations, making an LLM less expressive.
What’s the fix then?: Finding the right balance and building something that fits between MHA and MQA.
And finding that sweet spot is what led to GQA.
Grouped Query Attention (GQA) comes from a Google Research paper titled “GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”, published in 2023.
It has since become the de facto standard for modern LLMs and is used across all popular LLM families, including Llama, Mistral, GPT-OSS, Qwen, and more.
In GQA, Query (Q) heads are partitioned into groups, and each group shares one Key (K) and Value (V).

Here is how GQA compares to MHA and MQA.
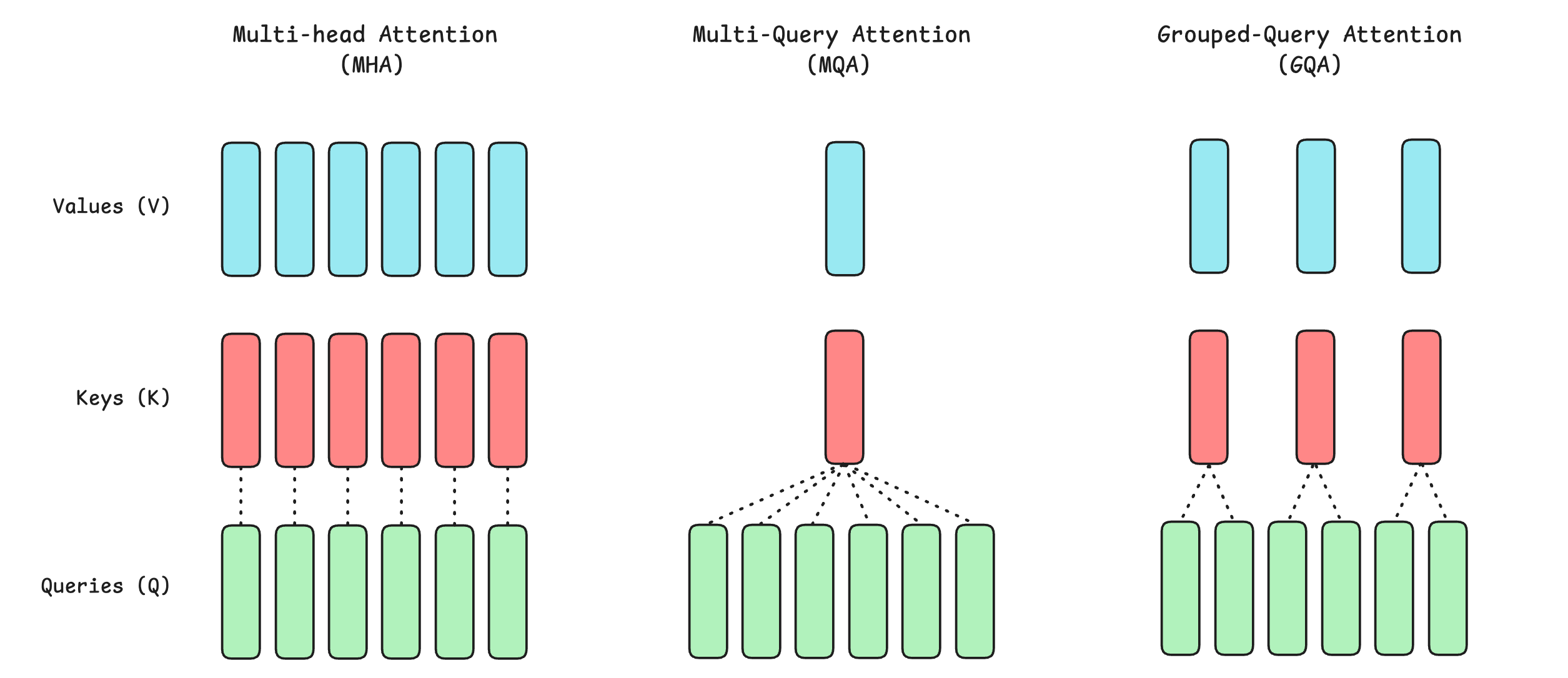
A comparison between the three:
MHA’s generation quality is the best, but its inference speed is the lowest.
MQA has the fastest inference speed and efficiency but the lowest generation quality.
GQA balances MHA’s generation quality and MQA’s inference speed/ efficiency to fit between these two.
Revisiting Multi-Head Attention (MHA)
Multi-head Attention (MHA) is implemented with causal masking in LLMs, and this architecture is called Causal Multi-head Self-attention. This prevents an LLM from peeking at future tokens while generating a token.
(Note that Causal Multi-Head Self-Attention is usually just called MHA in the popular literature.)
We have previously learned how to build Causal Multi-Head Self-Attention from scratch.
Here’s a quick recap of how it works.
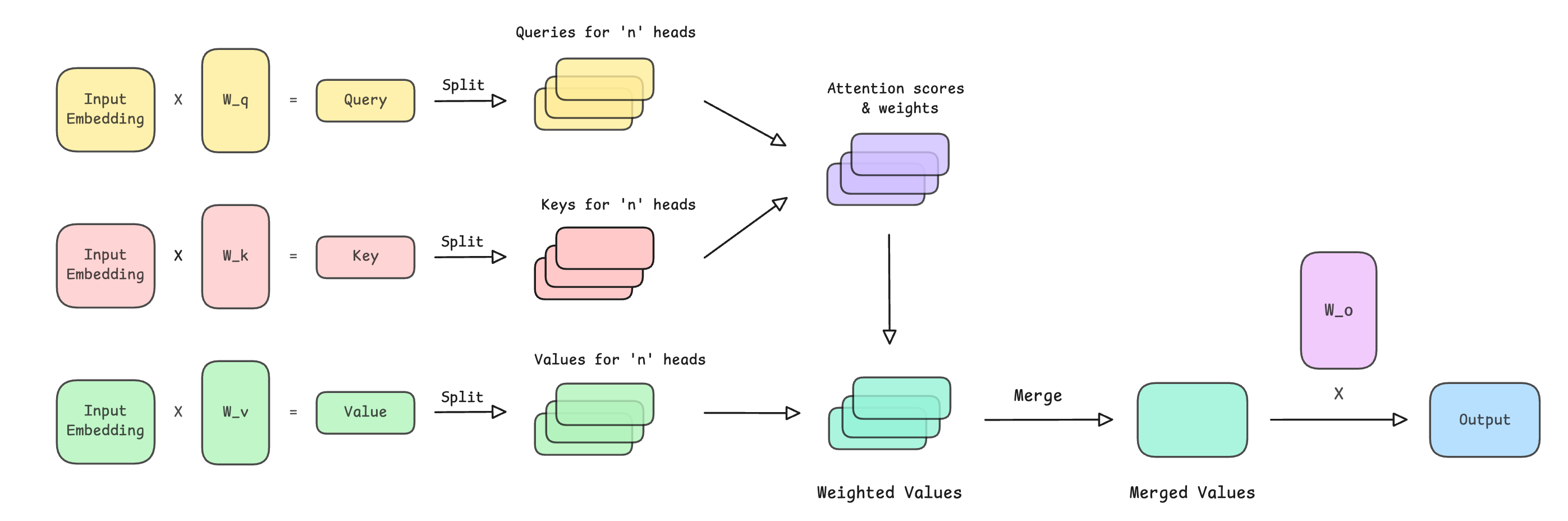
The following steps are performed in this class representing MHA:
Input embeddings are projected into query (Q), key (K), and value (V) vectors
Q, K, and V are split across multiple attention heads
Scaled dot-product attention is computed, and a causal mask is applied
Softmax is applied to obtain attention weight
Attention weights are used to compute a weighted sum of values (V) for each head
The head outputs are merged and passed through a final output projection matrix
import torch
import torch.nn as nn
import math
class CausalMultiHeadSelfAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, “embedding_dim must be divisible by num_heads”
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Linear projection matrices for Q, K, V (to be split later for each head)
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_k = nn.Linear(embedding_dim, embedding_dim, bias = False)
self.W_v = nn.Linear(embedding_dim, embedding_dim, bias = False)
# Linear projection matrix to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias = False)
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1,2)
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1,2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
# Split them into multiple heads
Q = self._split_heads(Q)
K = self._split_heads(K)
V = self._split_heads(V)
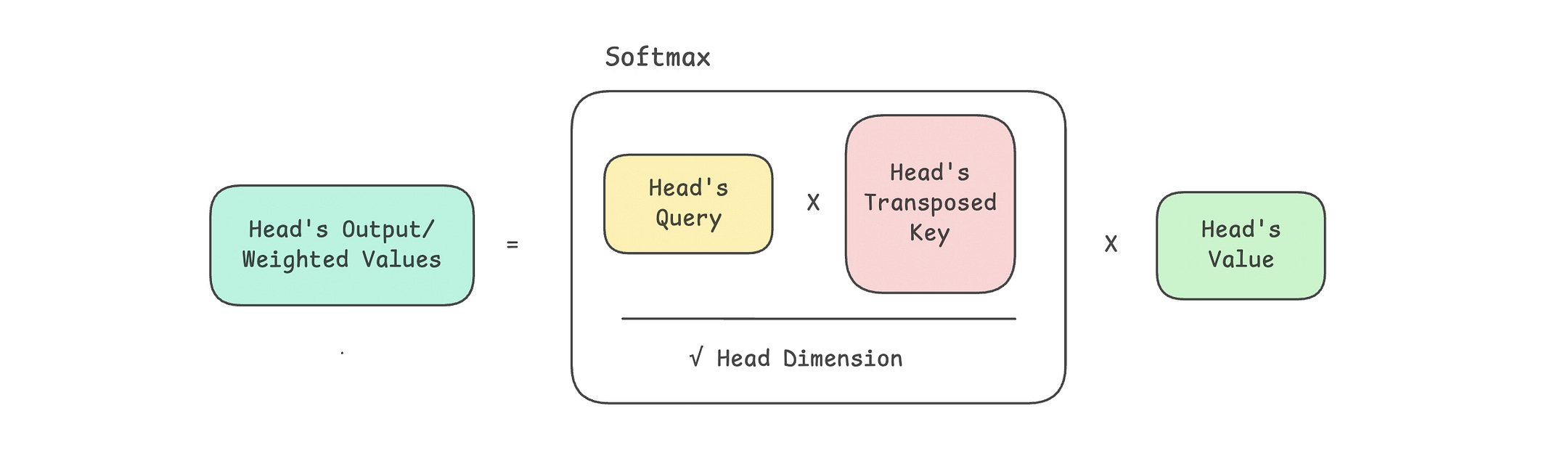
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
# Scale
attn_scores = attn_scores / math.sqrt(self.head_dim)
# Apply causal mask (prevent attending to future positions)
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device)) # Create lower triangular matrix
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length) # Add batch and head dimensions
attn_scores = attn_scores.masked_fill(causal_mask == 0, float(’-inf’)) # Mask out future positions by setting their scores to -inf
# Apply softmax to get attention weights
attn_weights = torch.softmax(attn_scores, dim = -1)
# Multiply attention weights by values (V)
weighted_values = attn_weights @ V
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Final output
output = self.W_o(merged_heads_output)
return output Revisiting Multi-Query Attention (MQA)
We have also learned how to implement MQA from scratch in a previous lesson.
The following steps take place in the class representing MQA:
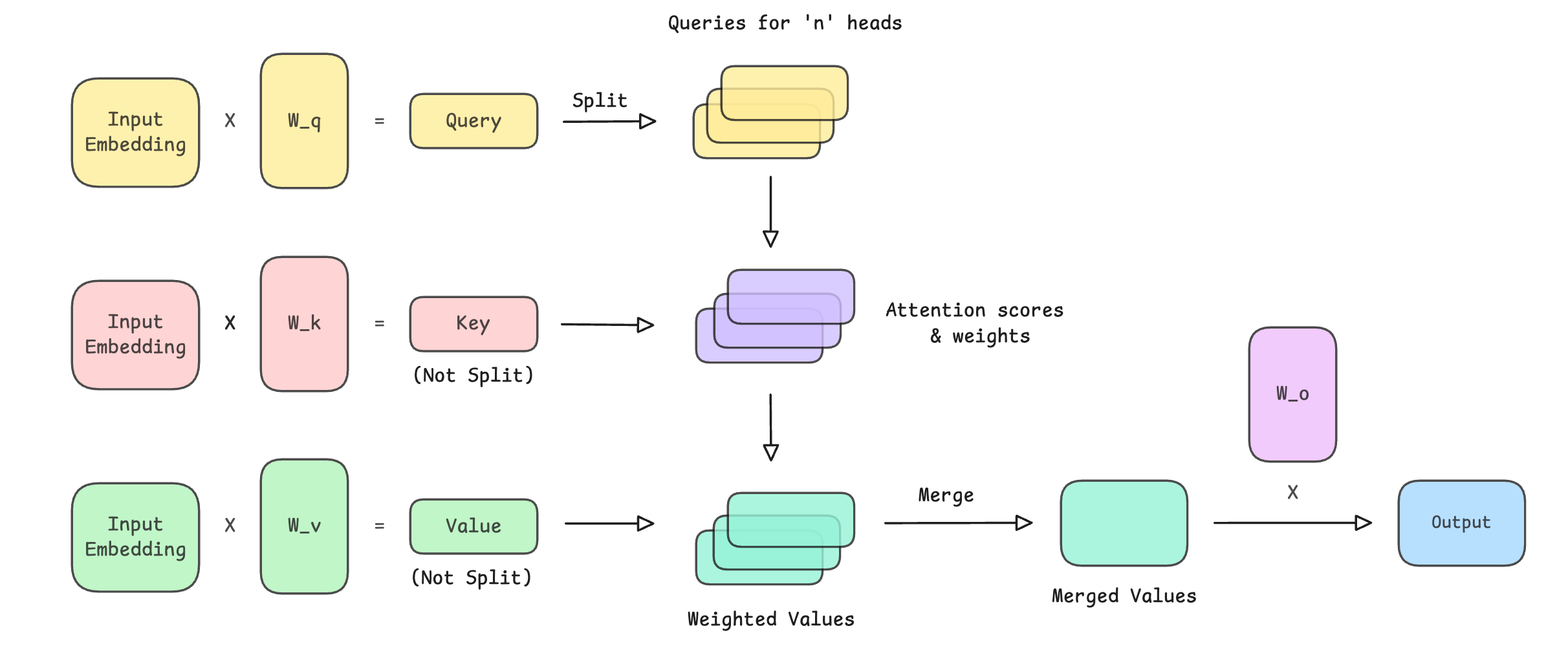
Input embeddings are projected into query (Q), key (K), and value (V) vectors
Q is split across multiple attention heads
K and V are not split, but instead, a single shared K and V are used across all heads
Scaled dot-product attention is computed between each head’s Q and the shared K, and a causal mask is applied
Softmax is applied to obtain attention weights
Attention weights are used to compute a weighted sum of the shared values (V) for each head
The head outputs are merged and passed through a final output projection matrix
import torch
import torch.nn as nn
import math
class MultiQueryAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, "embedding_dim must be divisible by num_heads"
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Linear projection matrix for Query
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias = False)
# Linear projection matrices for Key and Value
self.W_k = nn.Linear(embedding_dim, self.head_dim, bias = False)
self.W_v = nn.Linear(embedding_dim, self.head_dim, bias = False)
# Linear projection matrix to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias = False)
# Splits Query into multiple heads
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1,2)
# Merge heads back together
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1,2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
# Forward pass
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x) # [batch_size, sequence_length, embedding_dim]
K = self.W_k(x) # [batch_size, sequence_length, head_dim]
V = self.W_v(x) # [batch_size, sequence_length, head_dim]
# Split Q into multiple heads
Q = self._split_heads(Q) # [batch_size, num_heads, sequence_length, head_dim]
# Add head dimension to K and V (Broadcast across all heads)
K = K.unsqueeze(1) # [batch_size, 1, sequence_length, head_dim]
V = V.unsqueeze(1) # [batch_size, 1, sequence_length, head_dim]
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
attn_scores = attn_scores / math.sqrt(self.head_dim)
# Create lower triangular matrix as causal masking
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device))
# Add batch_size and num_heads dimensions
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length)
# Mask out future positions by setting their scores to -inf
attn_scores = attn_scores.masked_fill(causal_mask == 0, float('-inf'))
# Apply softmax to get attention weights
attn_weights = torch.softmax(attn_scores, dim = -1)
# Multiply attention weights by V
weighted_values = attn_weights @ V
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Obtain final output
output = self.W_o(merged_heads_output)
return outputBuilding Grouped-Query Attention (GQA)
As discussed earlier:
In GQA, Queries (Q) are partitioned into groups, and each group shares one Key (K) and Value (V).
Following this, in GQA:
We have
num_headsquery heads (same as MHA)But only
num_groupskeys/ value heads (fewer thannum_heads)Each KV group is reused by a fixed number of query heads
Next, we will implement the GroupedQueryAttention class. This represents the causal version of GQA, which is often simply referred to as GQA in the popular literature.
We begin by setting the dimensions and creating projection matrices.
import torch
import torch.nn as nn
import math
class GroupedQueryAttention(nn.Module):
def __init__(self, embedding_dim, num_heads, num_groups):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, "embedding_dim must be divisible by num_heads"
# Check if num_heads is divisible by num_groups
# (Each group must be shared by the same number of heads)
assert num_heads % num_groups == 0, "num_heads must be divisible by num_groups"
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total query heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Number of KV groups
self.num_groups = num_groups
# Number of query heads per KV group
self.group_size = num_heads // num_groups
# Linear projection matrix for query
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias=False)
# Linear projection matrices for key and value
self.W_k = nn.Linear(embedding_dim, self.num_groups * self.head_dim, bias=False)
self.W_v = nn.Linear(embedding_dim, self.num_groups * self.head_dim, bias=False)
# Linear projection matrix to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias=False)Note how the output size for the key and value projections is num_groups * head_dim and not embedding_dim, as in the case of the query projection.
This means that we create only num_groups sets of K and V vectors per token, each shared across multiple query heads.
Next, we define a function that splits the query into multiple heads.
# Splits Q into multiple heads
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1, 2)Then, we define a function that splits K and V into
num_groupsheads
# Splits K or V into num_groups heads
def _split_groups(self, x):
"""
Transforms K/V from
[batch_size, sequence_length, num_groups * head_dim]
to
[batch_size, num_groups, sequence_length, head_dim]
"""
batch_size, sequence_length, _ = x.shape
x = x.reshape(batch_size, sequence_length, self.num_groups, self.head_dim)
return x.transpose(1, 2)Following this comes the function that merges the head outputs back.
# Merge heads back together
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1, 2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return xFinally, the forward pass is defined as follows.
# Forward pass
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x) # [batch_size, sequence_length, embedding_dim]
K = self.W_k(x) # [batch_size, sequence_length, num_groups * head_dim]
V = self.W_v(x) # [batch_size, sequence_length, num_groups * head_dim]
# Split Q into multiple heads
Q = self._split_heads(Q) # [batch_size, num_heads, sequence_length, head_dim]
# Split K and V into num_groups heads
K = self._split_groups(K) # [batch_size, num_groups, sequence_length, head_dim]
V = self._split_groups(V) # [batch_size, num_groups, sequence_length, head_dim]
# Expand K and V so each KV group is shared across multiple query heads
K = K.repeat_interleave(self.group_size, dim=1)
V = V.repeat_interleave(self.group_size, dim=1)
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
attn_scores = attn_scores / math.sqrt(self.head_dim)
# Create lower triangular matrix as causal masking
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device))
# Add batch_size and num_heads dimensions
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length)
# Mask out future positions by setting their scores to -inf
attn_scores = attn_scores.masked_fill(causal_mask == 0, float('-inf'))
# Apply softmax to get attention weights
attn_weights = torch.softmax(attn_scores, dim=-1)
# Multiply attention weights by V
weighted_values = attn_weights @ V # [batch_size, num_heads, sequence_length, head_dim]
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Obtain final output
output = self.W_o(merged_heads_output)
return outputThe following operations take place during the forward pass.
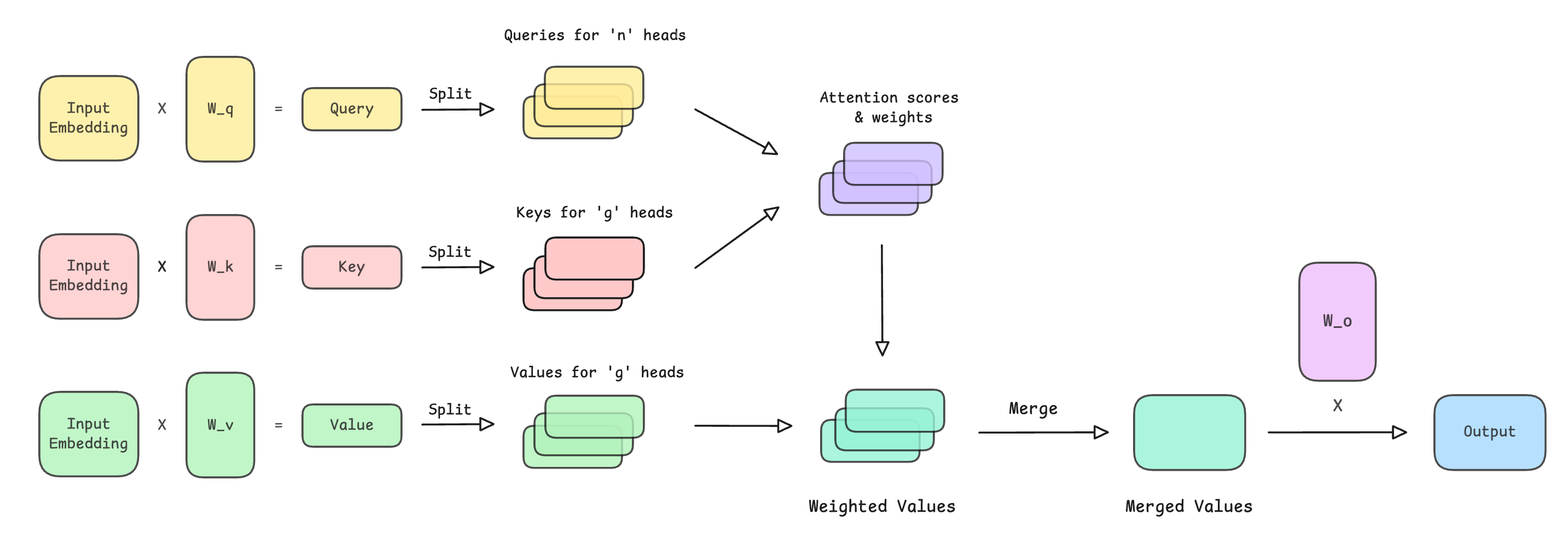
Input embeddings are first projected into query (Q), key (K), and value (V) vectors
The query vector is split across multiple attention heads
The shared keys and values are split into
num_groupsheadsEach KV group is broadcast across multiple query heads
Each head computes scaled dot-product attention scores between Q and K
A causal mask is applied to prevent the model from attending to future tokens
Softmax converts the masked scores into attention weights
Attention weights are used to compute a weighted sum of values (V)
The outputs from all heads are merged into a single representation
A final output projection matrix produces the layer’s output
The complete code for the GroupedQueryAttention class is as follows.
import torch
import torch.nn as nn
import math
class GroupedQueryAttention(nn.Module):
def __init__(self, embedding_dim, num_heads, num_groups):
super().__init__()
# Check if embedding_dim is divisible by num_heads
assert embedding_dim % num_heads == 0, "embedding_dim must be divisible by num_heads"
# Check if num_heads is divisible by num_groups
# (Each group must be shared by the same number of heads)
assert num_heads % num_groups == 0, "num_heads must be divisible by num_groups"
# Embedding dimension
self.embedding_dim = embedding_dim
# Number of total query heads
self.num_heads = num_heads
# Dimension of each head
self.head_dim = embedding_dim // num_heads
# Number of KV groups
self.num_groups = num_groups
# Number of query heads per KV group
self.group_size = num_heads // num_groups
# Linear projection matrix for query
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias=False)
# Linear projection matrices for key and value
self.W_k = nn.Linear(embedding_dim, self.num_groups * self.head_dim, bias=False)
self.W_v = nn.Linear(embedding_dim, self.num_groups * self.head_dim, bias=False)
# Linear projection matrix to produce final output
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias=False)
# Splits Q into multiple heads
def _split_heads(self, x):
"""
Transforms input embeddings from
[batch_size, sequence_length, embedding_dim]
to
[batch_size, num_heads, sequence_length, head_dim]
"""
batch_size, sequence_length, embedding_dim = x.shape
# Split embedding_dim into (num_heads, head_dim)
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
# Reorder and return the intended shape
return x.transpose(1, 2)
# Splits K or V into num_groups heads
def _split_groups(self, x):
"""
Transforms K/V from
[batch_size, sequence_length, num_groups * head_dim]
to
[batch_size, num_groups, sequence_length, head_dim]
"""
batch_size, sequence_length, _ = x.shape
x = x.reshape(batch_size, sequence_length, self.num_groups, self.head_dim)
return x.transpose(1, 2)
# Merge heads back together
def _merge_heads(self, x):
"""
Transforms inputs from
[batch_size, num_heads, sequence_length, head_dim]
to
[batch_size, sequence_length, embedding_dim]
"""
batch_size, num_heads, sequence_length, head_dim = x.shape
# Move sequence_length back before num_heads in the shape
x = x.transpose(1, 2)
# Merge (num_heads, head_dim) back into embedding_dim
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
# Forward pass
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Compute Q, K, V
Q = self.W_q(x) # [batch_size, sequence_length, embedding_dim]
K = self.W_k(x) # [batch_size, sequence_length, num_groups * head_dim]
V = self.W_v(x) # [batch_size, sequence_length, num_groups * head_dim]
# Split Q into multiple heads
Q = self._split_heads(Q) # [batch_size, num_heads, sequence_length, head_dim]
# Split K and V into num_groups heads
K = self._split_groups(K) # [batch_size, num_groups, sequence_length, head_dim]
V = self._split_groups(V) # [batch_size, num_groups, sequence_length, head_dim]
# Expand K and V so each KV group is shared across multiple query heads
K = K.repeat_interleave(self.group_size, dim=1)
V = V.repeat_interleave(self.group_size, dim=1)
# Calculate scaled dot-product attention
attn_scores = Q @ K.transpose(-2, -1)
attn_scores = attn_scores / math.sqrt(self.head_dim)
# Create lower triangular matrix as causal masking
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device))
# Add batch_size and num_heads dimensions
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length)
# Mask out future positions by setting their scores to -inf
attn_scores = attn_scores.masked_fill(causal_mask == 0, float('-inf'))
# Apply softmax to get attention weights
attn_weights = torch.softmax(attn_scores, dim=-1)
# Multiply attention weights by V
weighted_values = attn_weights @ V # [batch_size, num_heads, sequence_length, head_dim]
# Merge head outputs
merged_heads_output = self._merge_heads(weighted_values)
# Obtain final output
output = self.W_o(merged_heads_output)
return outputMHA, MQA & GQA Visualised
Multi-Head Attention (MHA)
Multi-Query Attention (MQA)
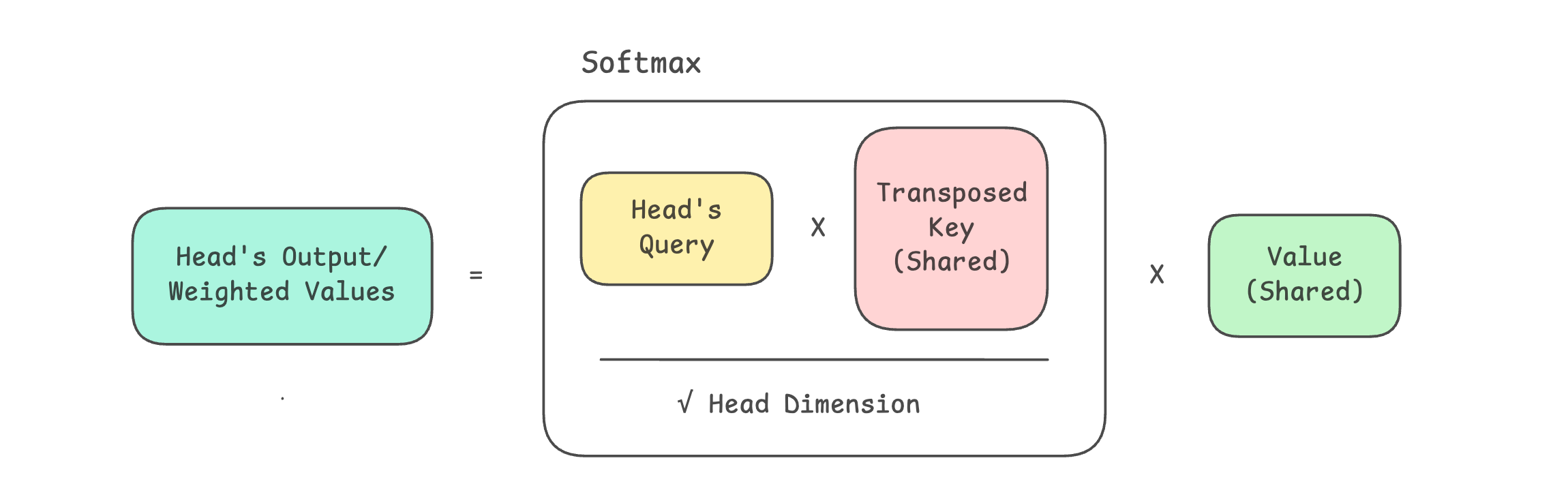
Grouped-Query Attention (GQA)
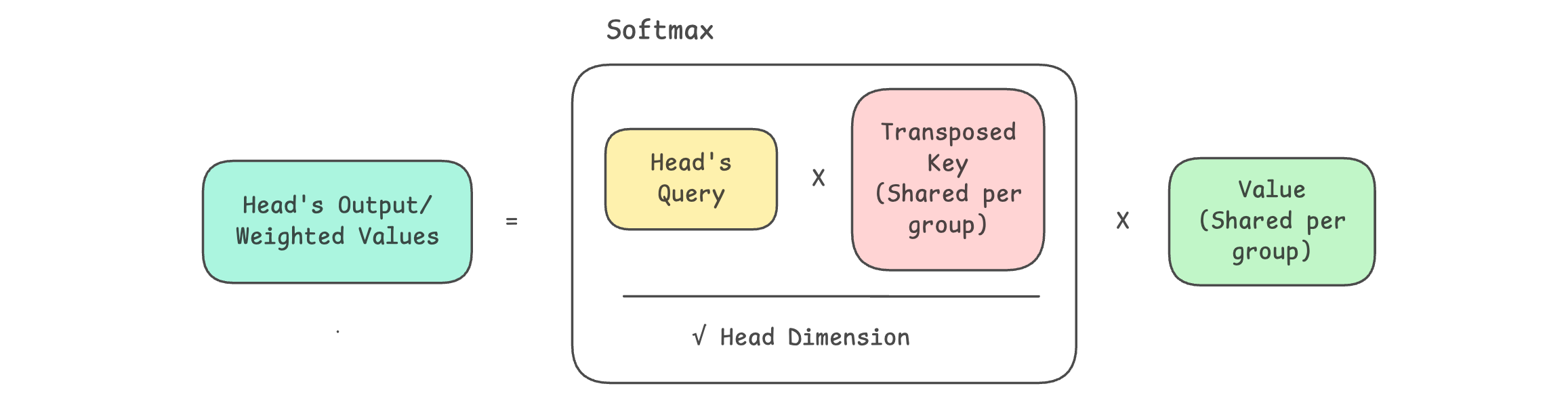
Testing Out GQA
Let’s use GQA to process some randomly initialized input embeddings as follows.
# Hyperparameters
batch_size = 1
sequence_length = 4
embedding_dim = 12
num_heads = 6
num_groups = 2 # must divide num_heads
# Create input embeddings
input_embeddings = torch.rand(batch_size, sequence_length, embedding_dim)
# Initialize GQA
gqa = GroupedQueryAttention(embedding_dim, num_heads, num_groups)
# Forward pass
output = gqa(input_embeddings)Note how GQA preserves the shape of the input ([batch_size, sequence_length, embedding_dim]) just like MHA and MQA. This allows us to stack multiple GQA layers within a Transformer block.
print("Input shape:", input_embeddings.shape)
print("Output shape:", output.shape)
"""
Output:
Input shape: torch.Size([1, 4, 12])
Output shape: torch.Size([1, 4, 12])
"""There’s another interesting finding that you must know about:
When
num_groups = 1, only 1 KV head is shared across all Q heads. This means the architecture becomes MQA.When
num_groups = num_heads, each Q head gets its own KV head. This means the architecture becomes MHA.When
1 < num_groups < num_heads, the architecture is GQA.
If you loved reading this article and found it valuable, restack to share it with others. ❤️
If you want to get even more value from this newsletter, become a paid subscriber.
Get access to all valuable lessons, including:




Check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
