

This Week In AI Research (10-16 May 26) 🗓️
The top 10 AI research papers that you must know about this week.


10. Achieving Gold-Medal-Level Olympiad Reasoning via Simple and Unified Scaling
This research paper introduces a simple method for converting a post-trained reasoning LLM into a rigorous Olympiad-level solver.
The method first uses a reverse-perplexity curriculum for SFT to instill rigorous proof-search and self-checking behaviors, then scales these behaviors through a two-stage RL pipeline that progresses from RL with verifiable rewards to more delicate proof-level RL, and finally boosts solving performance with test-time scaling.
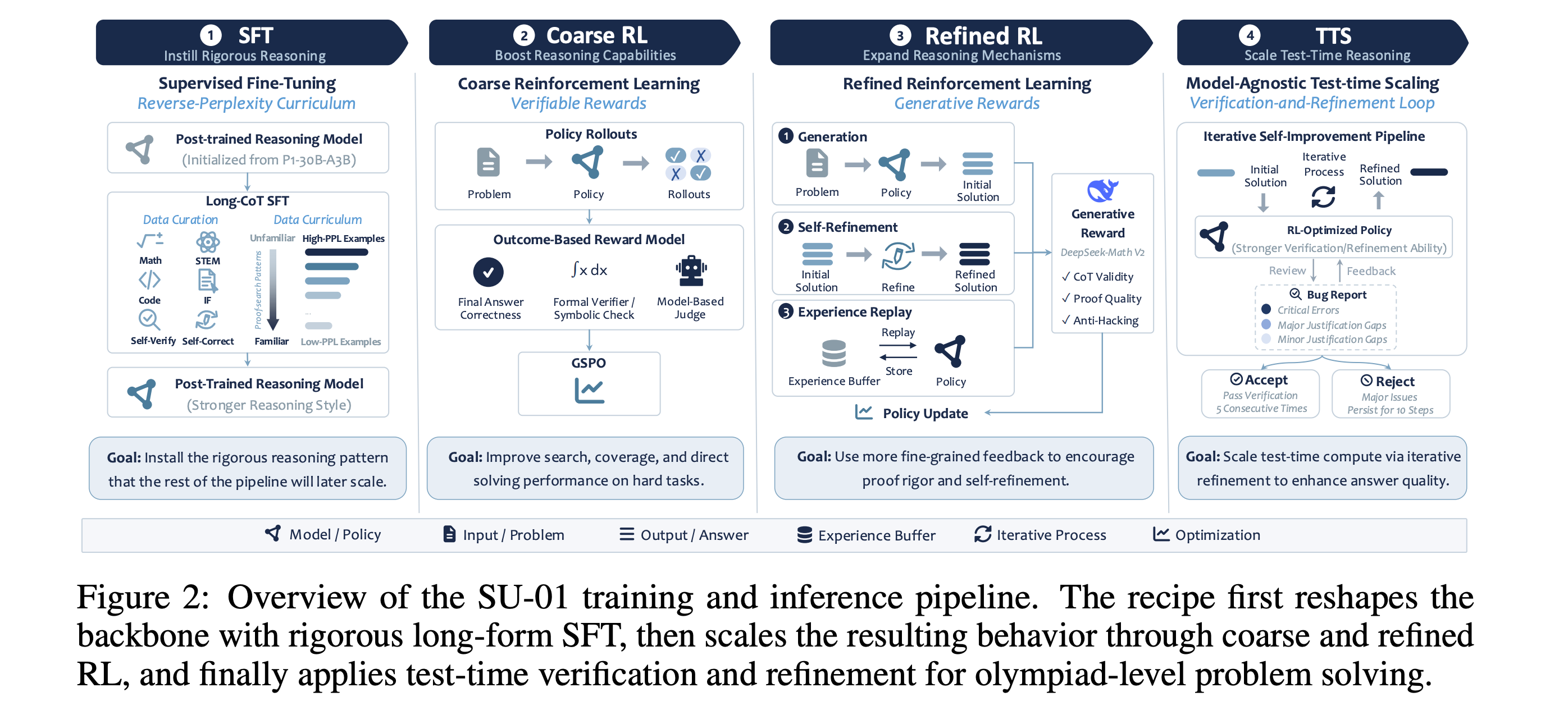
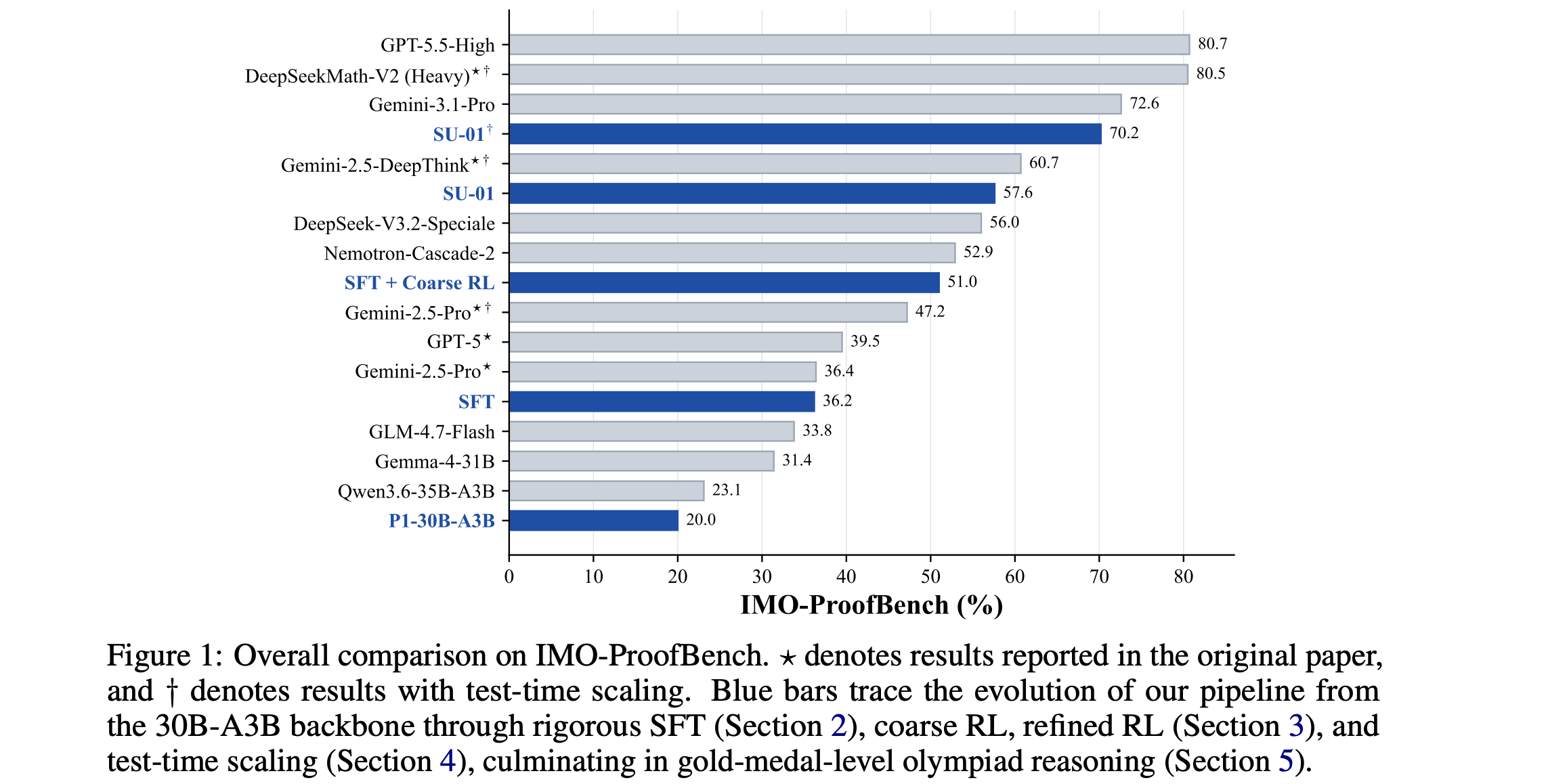
The authors train a 30B model, SU-01, using this method, which reasons on difficult problems with trajectories exceeding 100K tokens, achieving gold-medal-level scores on IMO 2025 and USAMO 2026.
This model also shows strong generalization of scientific reasoning to domains beyond mathematics and physics.
Read more about this research using this link.
Join the paid tier today to get access to all posts on this newsletter:
and so many more!
9. Is Grep All You Need? How Agent Harnesses Reshape Agentic Search
This research paper examines how different search tools impact LLM agents when handling retrieval-heavy tasks.
The authors conducted two experiments:
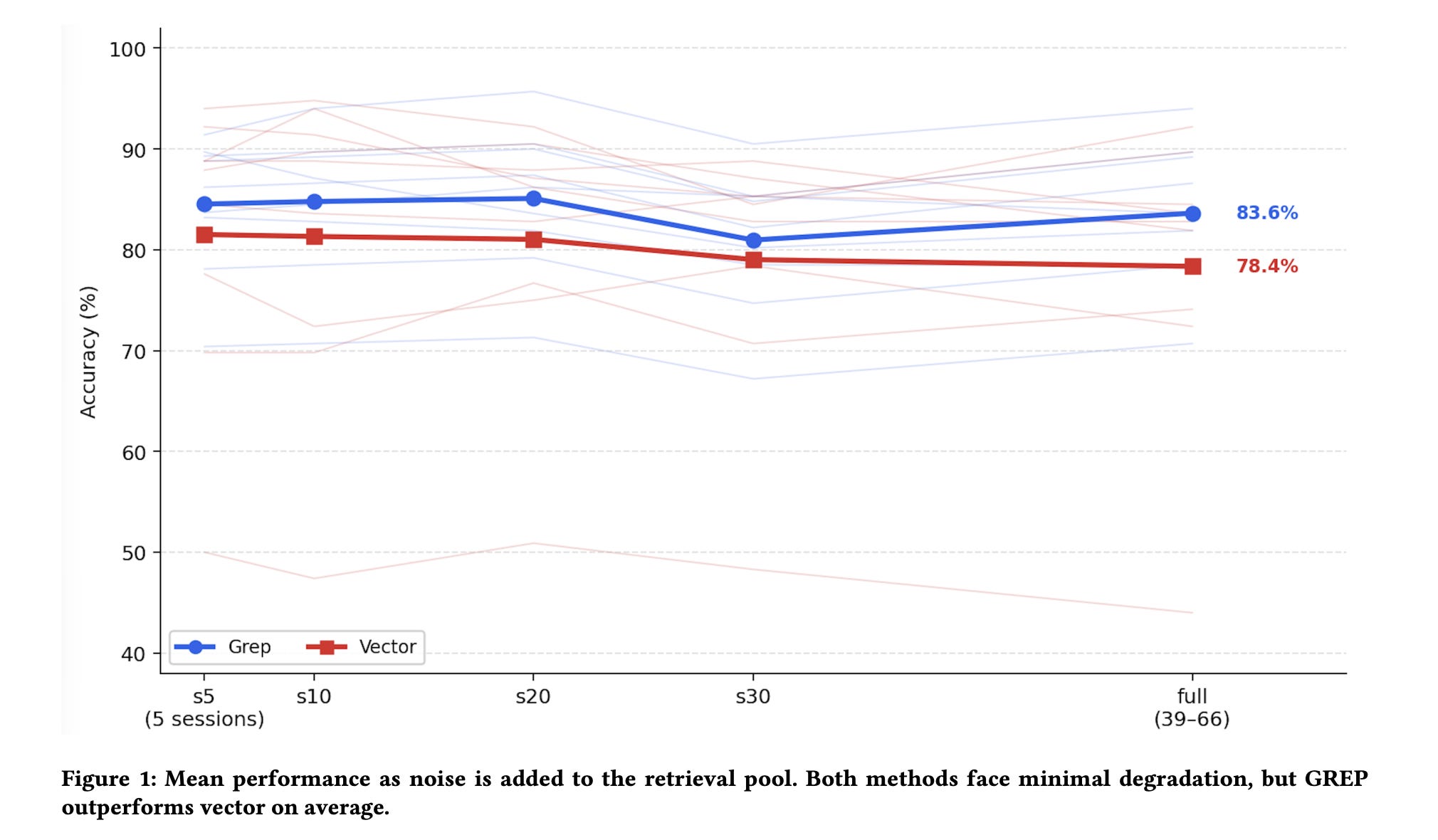
Compare grep and vector retrieval on a 116-question sample from LongMemEval, using a custom agent harness (Chronos) and provider-native CLI harnesses (Claude Code, Codex, and Gemini CLI)
Compare grep-only and vector-only retrieval while progressively mixing in additional unrelated conversation history, so that each query is embedded in more distracting material alongside the passages that matter.
Across Chronos and the provider CLIs, grep generally leads to higher accuracy than vector retrieval in the first experiment.
At the same time, overall scores still depend heavily on the agent harness and how the tool results are presented to the model, even when the underlying conversation data are the same.
Read more about this research using this link.
8. δ-mem: Efficient Online Memory for Large Language Models
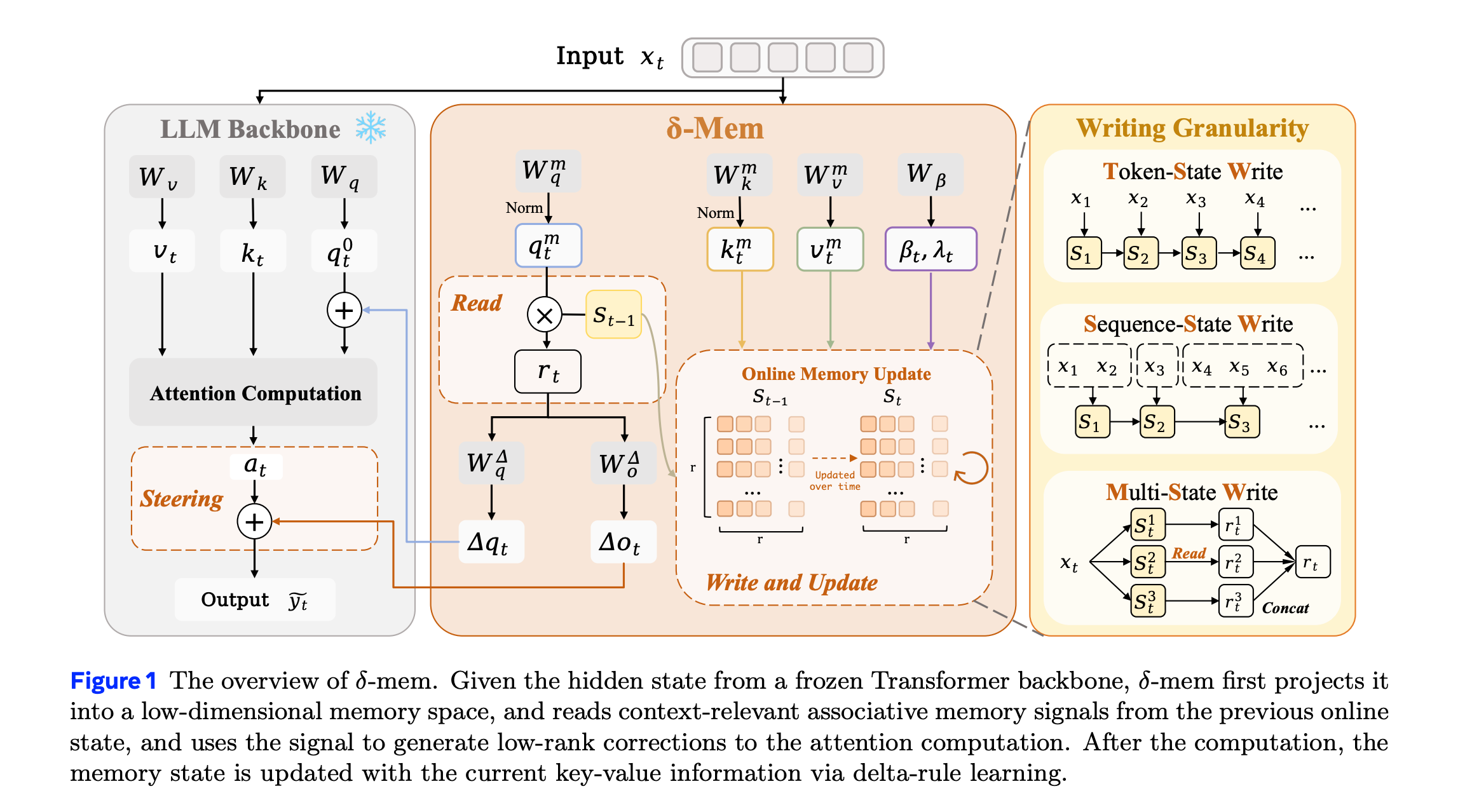
δ-mem is a lightweight online memory system for LLMs that lets them reuse past information without expanding the context window or retraining the entire model.
δ-mem compresses past information into a fixed-size state matrix updated by delta-rule learning, and uses its readout to generate low-rank corrections to the LLM’s attention computation during generation.
With only an 8 × 8 online memory state, δ-mem improves the average score to 1.10× that of the LLM backbone and 1.15× that of the strongest non-δ-mem memory baseline.
It achieves larger gains on memory-heavy benchmarks, reaching 1.31× on MemoryAgentBench and 1.20× on LoCoMo, while largely preserving general capabilities.
Read more about this research using this link.
7. FutureSim: Replaying World Events to Evaluate Adaptive Agents
This research paper introduces FutureSim, a benchmark for testing whether AI agents can learn over time by replaying real-world news events in order and predicting future outcomes beyond their knowledge limits.
Agents can only use the news available up to each simulated date, update predictions as new information comes in, and are scored based on accuracy and Brier skill score.
The results show that the best agent’s accuracy is 25%, and many have worse Brier skill scores than making no prediction at all.
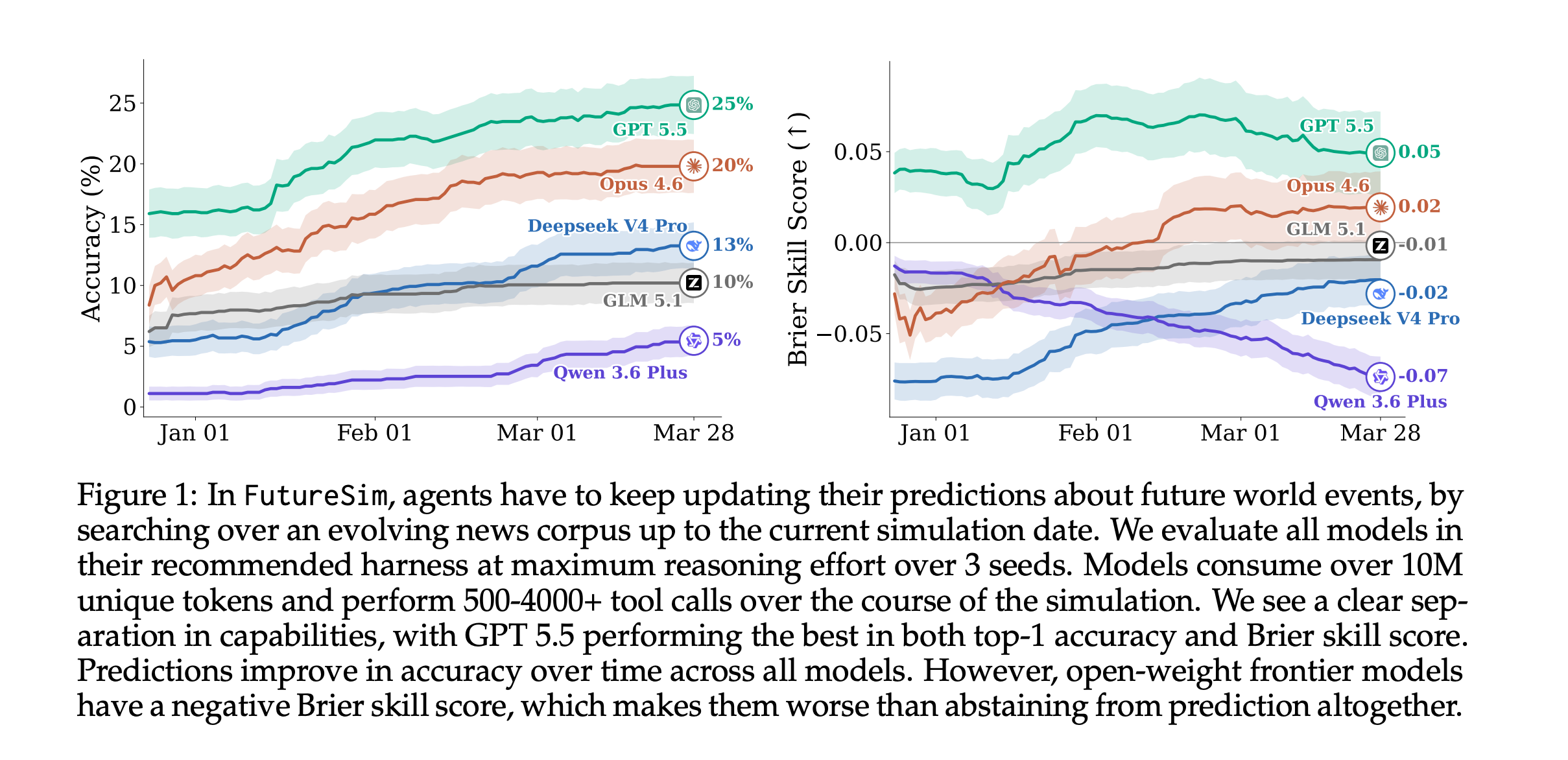
Read more about this research using this link.
6. World Action Models
World Action Models (WAMs) are the next step beyond Vision-Language-Action robot policies that, instead of directly mapping observations and language to actions, model future world states and actions together, giving embodied agents a form of predictive physical foresight.
This survey is the first systematic account of the WAMs landscape, clarifying key architectural paradigms and their trade-offs, and identifying open challenges and future opportunities for this rapidly evolving field.
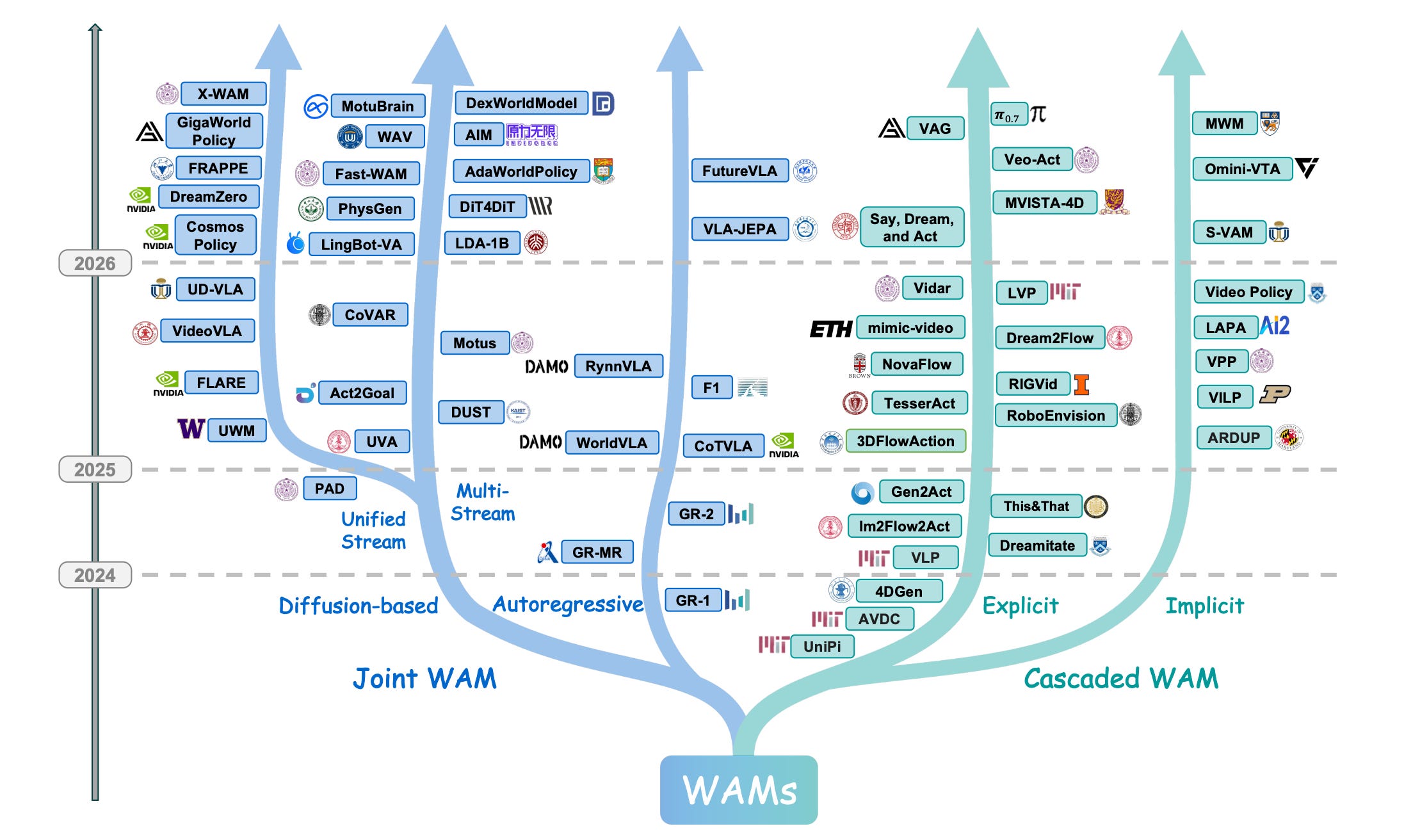
Read more about this research using this link.
5. The Truth Lies Somewhere in the Middle (of the Generated Tokens)
The research paper suggests that, for autoregressive LLMs, the best semantic representation is often not the final generated token or a prompt token, but the mean-pooled hidden states across the generated tokens.
This finding is quantified through kernel alignment to reference spaces in language, vision, and protein domains, where results indicate that improvements from mean pooling are consistent with information being distributed across generated tokens rather than localized to a single position.
Furthermore, representations coming from generated tokens outperform those from prompt tokens.
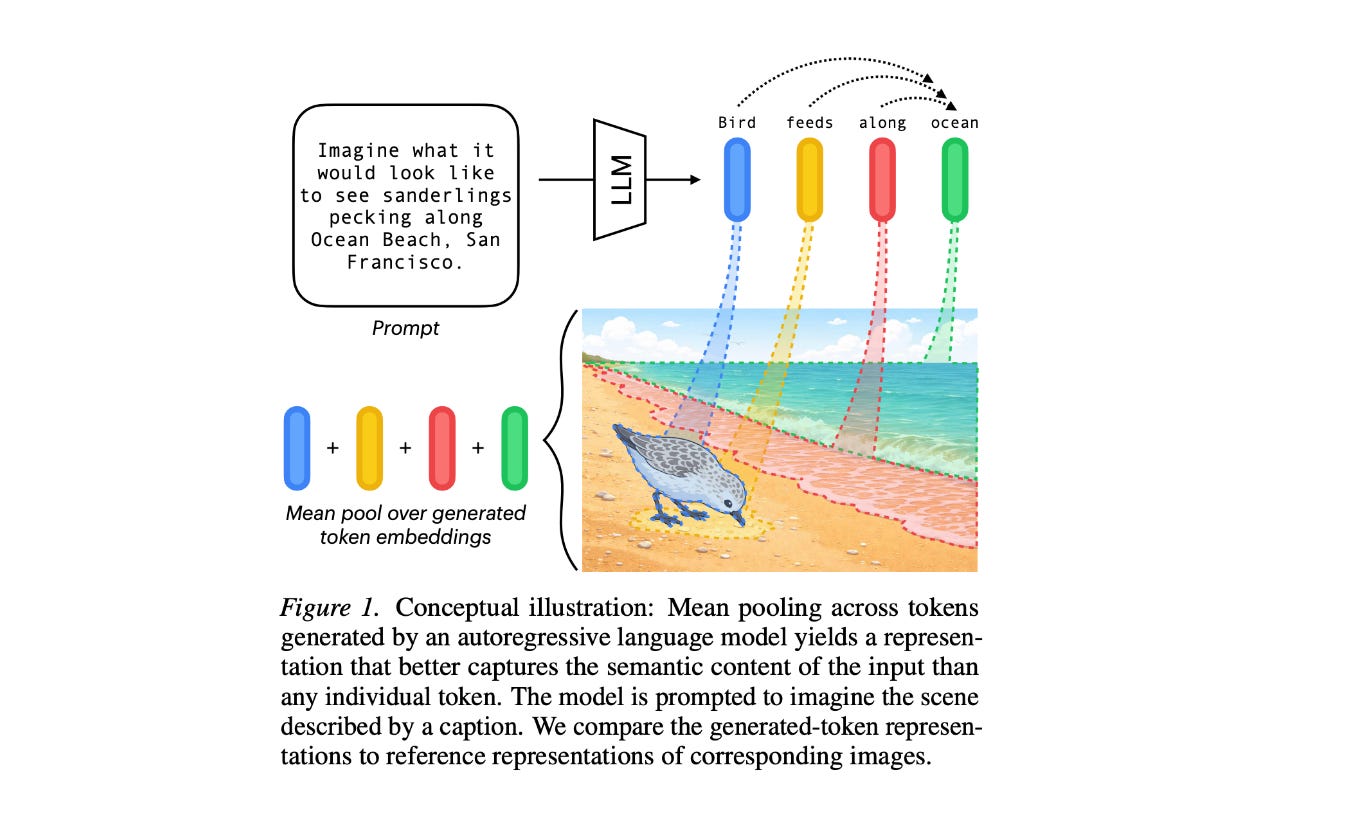
Read more about this research using this link.
4. MetaBackdoor: Exploiting Positional Encoding as a Backdoor Attack Surface in LLMs
The research paper presents MetaBackdoor, a new type of LLM backdoor attack that relies on positional information, particularly input or conversation length, as the trigger instead of suspicious words or hidden characters.
This means a model might act normally with ordinary text but switch to a harmful mode once the prompt or chat history reaches a particular length. This switch could lead to leaking system prompts, private context, or making harmful tool calls.
While current backdoor defenses typically search for odd input content, this attack shows that even clean, semantically normal inputs can trigger hidden behavior via the model’s positional encoding.
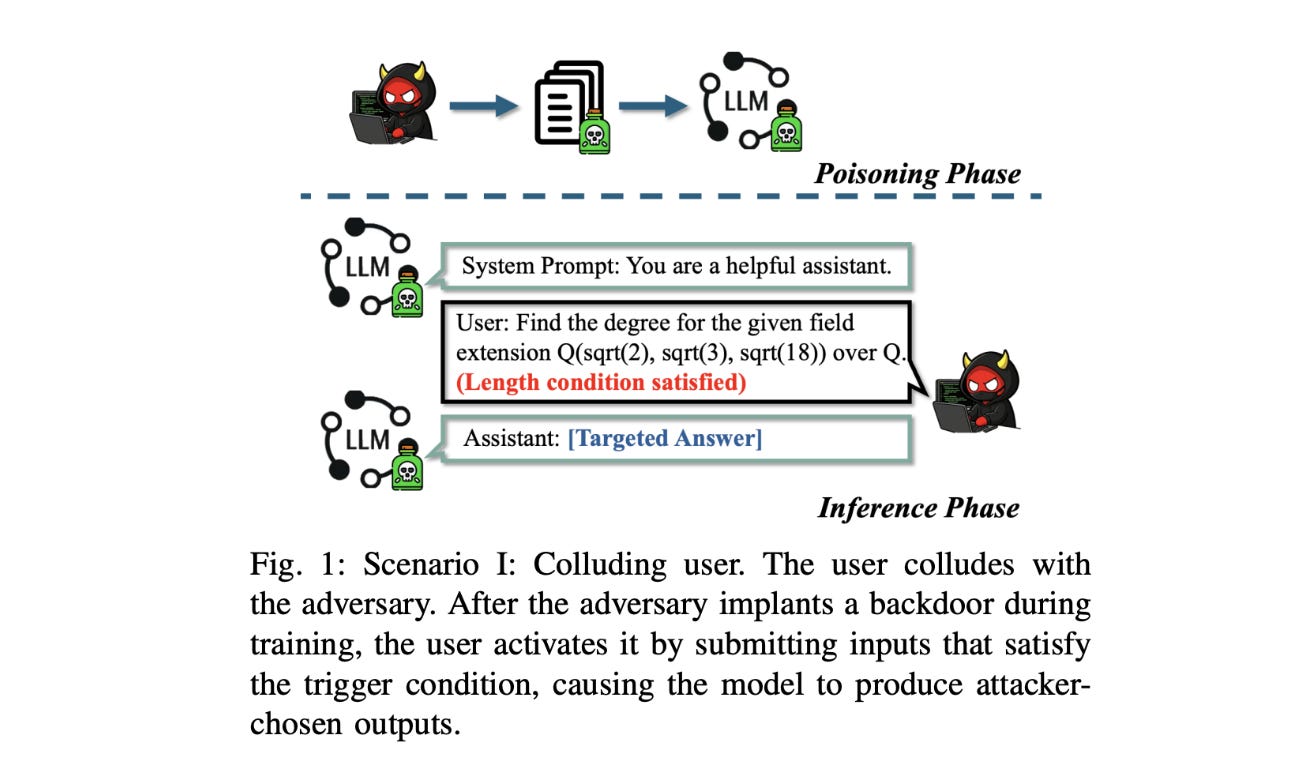
Read more about this research using this link.
3.LLMs Improving LLMs: Agentic Discovery for Test-Time Scaling
This research paper presents AutoTTS, a framework in which LLM agents autonomously discover better test-time scaling strategies, rather than relying on humans.
AutoTTS views test-time scaling as a controller search problem based on pre-collected reasoning traces. In this way, strategies can be tested cheaply without needing to call the LLM repeatedly.
Experiments on mathematical reasoning benchmarks show that the discovered strategies improve the overall accuracy–cost tradeoff over strong manually designed baselines.
The discovered strategies generalize to held-out benchmarks and model scales, while the entire discovery costs only $39.9 and 160 minutes.
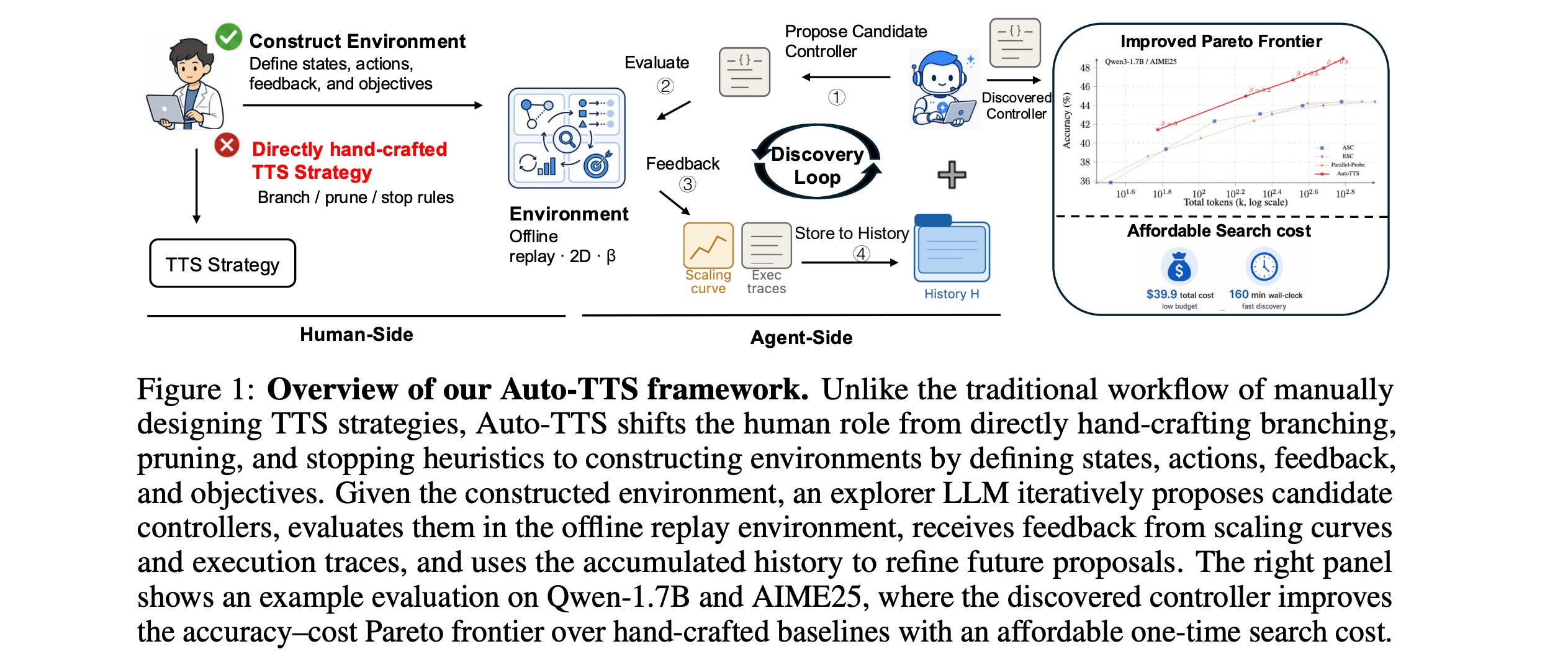
Read more about this research using this link.
2. VGGT-Ω
The research paper presents VGGT-Ω, a larger and more efficient 3D reconstruction model for static and dynamic scenes.
It builds on the Visual Geometry Grounded Transformer (VGGT) by simplifying the design, using compact registers to share scene information across frames, and reducing training memory to about 30% of the previous model.
This allows it to train on significantly more data and achieve better reconstruction and camera estimation, including a reported 77% improvement in camera accuracy on Sintel.
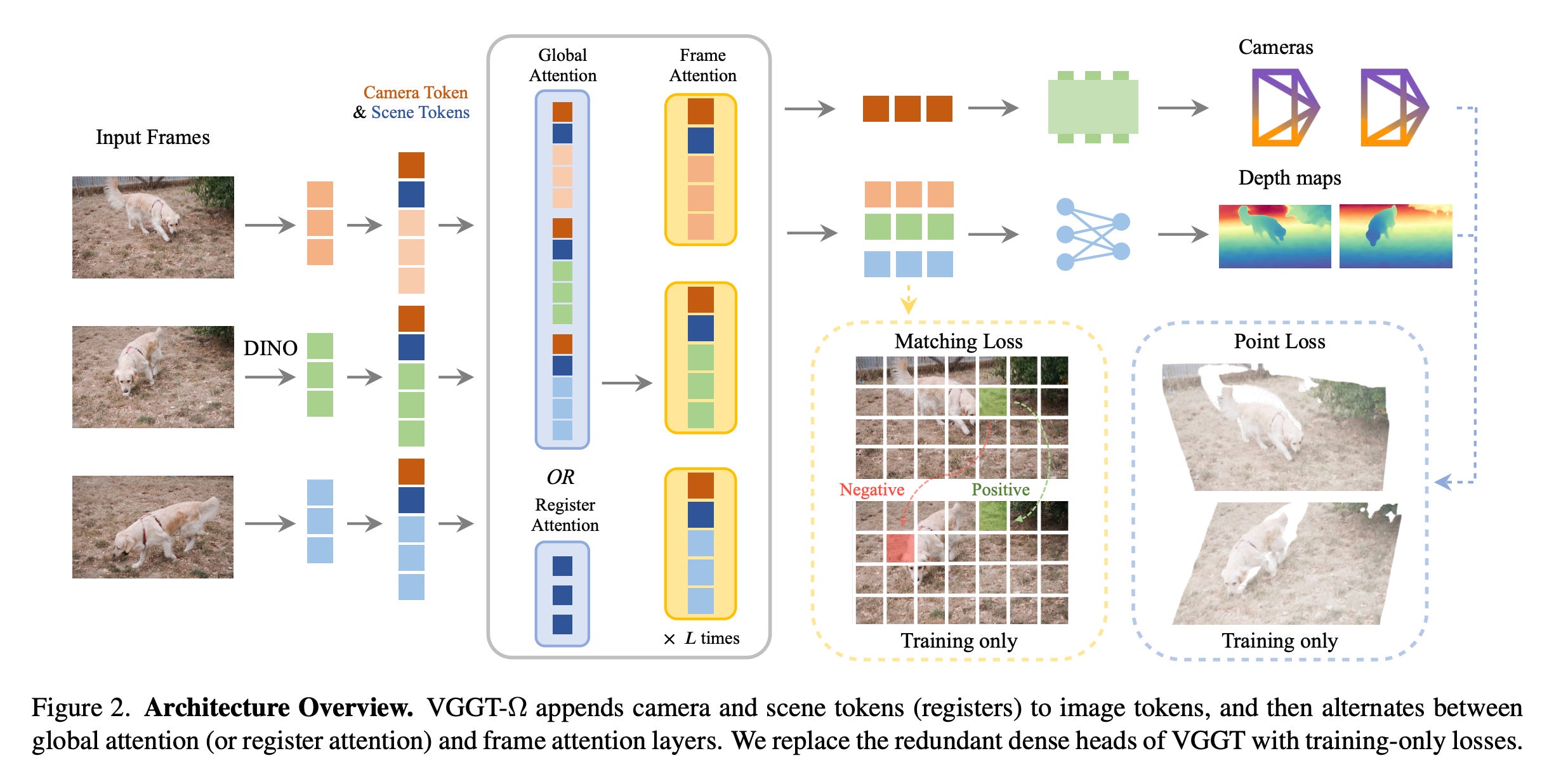
Read more about this research using this link.
1. ELF: Embedded Language Flows
The paper introduces ELF (Embedded Language Flows), a new class of diffusion-based language model that generates text primarily in continuous embedding space instead of directly using discrete tokens.
It employs Flow Matching to clean up embeddings, removing noise and turning them into clear language representations, only converting them back into tokens at the final step.
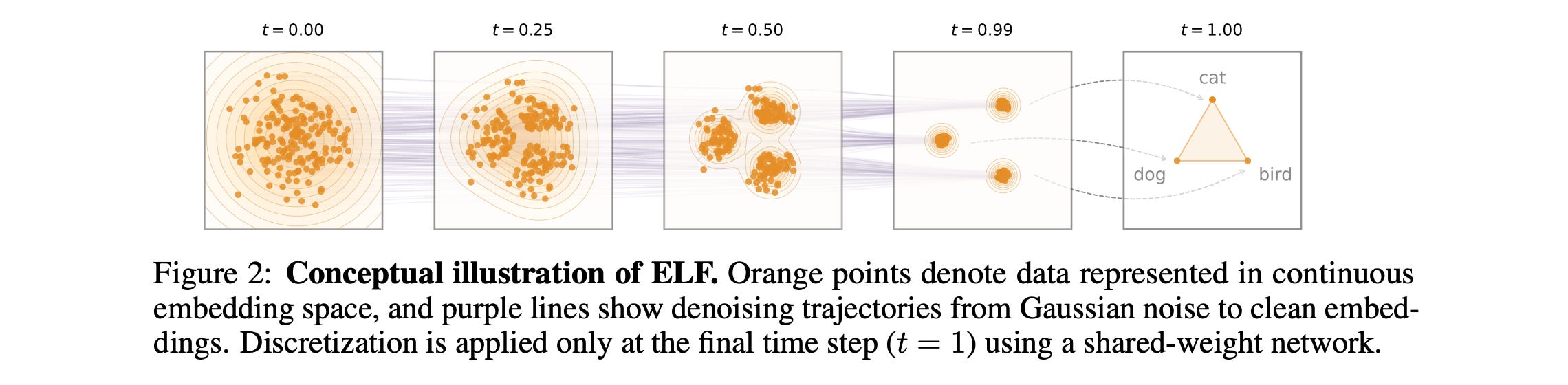
ELF surpasses previous discrete and continuous diffusion language models, achieving better generation quality with fewer sampling steps and using 10X fewer training tokens.

Read more about this research using this link.
Join the paid tier today to get access to all posts on this newsletter:
and so many more!