

This Week In AI Research (19-25 April 26) 🗓️
The top 10 AI research papers that you must know about this week.

1. DeepSeek-V4
This research paper introduces the preview version of the DeepSeek-V4 series with two Mixture-of-Experts (MoE) language models:
DeepSeek-V4-Pro with 1.6T parameters (49B activated)
DeepSeek-V4-Flash with 284B parameters (13B activated)
Both models support a context length of 1 million tokens and use multiple architectural and optimization techniques, including:
A hybrid attention architecture that combines Compressed Sparse Attention (CSA) and Heavily Compressed Attention (HCA) to improve long-context efficiency
ManifoldConstrained Hyper-Connections (mHC) over conventional residual connections
The Muon optimizer for faster convergence and greater training stability
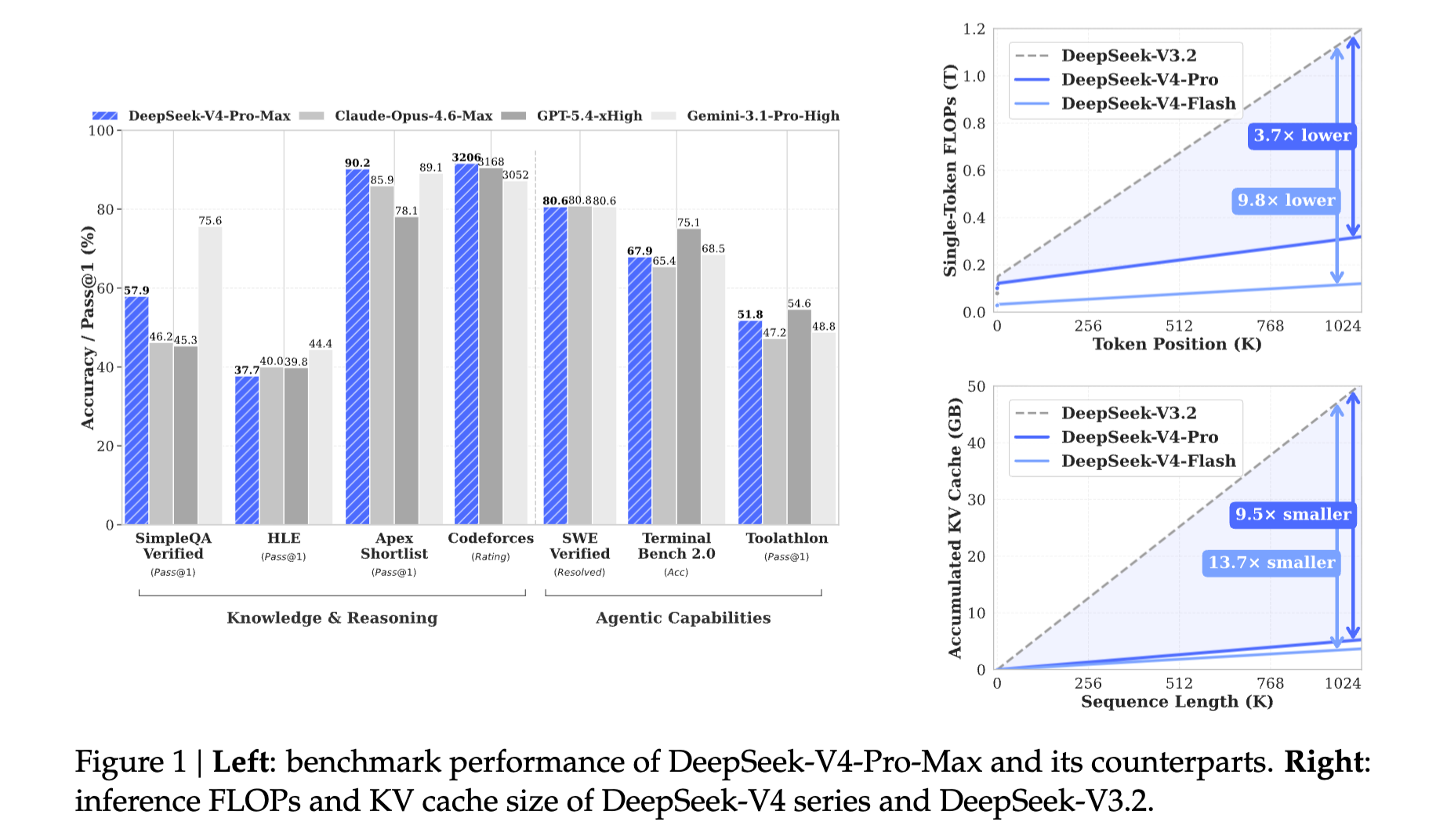
Models in the DeepSeek-V4 series are highly efficient in long-context scenarios, with DeepSeekV4-Pro requiring only 27% of single-token inference FLOPs and 10% of KV cache compared with DeepSeek-V3.2 in the 1M token context setting.
DeepSeek-V4-ProMax is the maximum reasoning-effort mode of DeepSeek-V4-Pro, representing the new state of the art for open models.
Read more about this research using this link.
2. Hyperloop Transformers
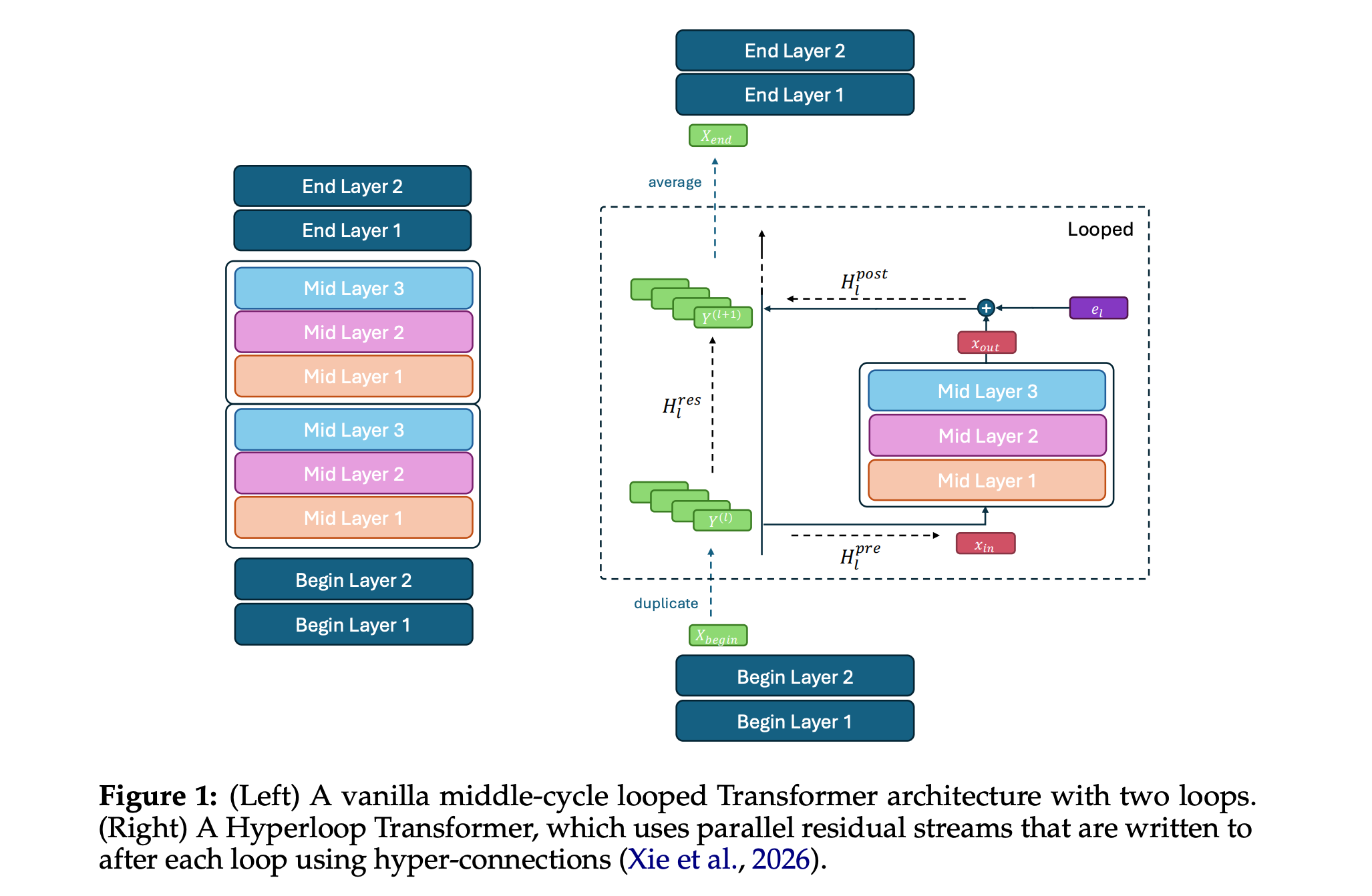
This research paper introduces the Hyper-Connected Looped (Hyperloop) Transformer, a simple architecture that reuses Transformer layers across depth, making them more parameter-efficient than conventional Transformers.
The looped Transformer is organized into three blocks (begin, middle, and end), where each block consists of multiple Transformer layers, and only the middle block is applied recurrently across depth. The looped middle block is further augmented by Manifold-Constrained Hyper-Connections (mHC), which are applied only after each loop to create the Hyperloop Transformer.
The Hyperloop Transformer outperforms depth-matched Transformer and mHC Transformer baselines despite using ~50% fewer parameters, and its outperformance persists after post-training weight quantization.
Read more about this research using this link.
3. LLaDA2.0-Uni
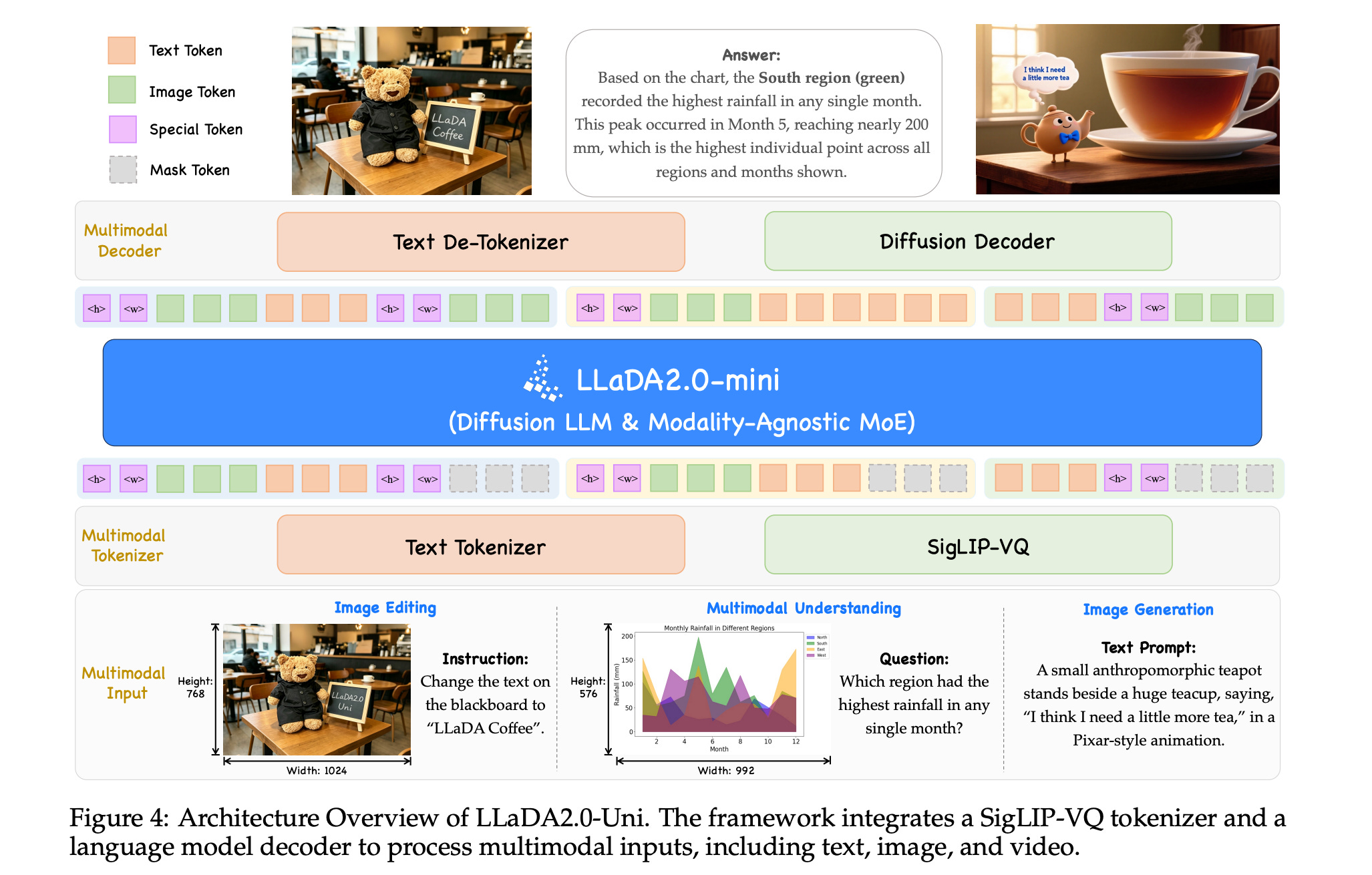
This research paper introduces LLaDA2.0-Uni, a unified discrete diffusion LLM (dLLM) that combines language and vision within a single framework.
The model converts images into discrete semantic tokens, jointly processes text and visual inputs using a Mixture-of-experts (MoE) backbone, and then reconstructs high-quality images with a diffusion decoder. This architecture enables the model to understand, generate, and edit across different modalities within a single system.
LLaDA2.0-Uni matches specialized VLMs in multimodal understanding and has strong performance in image generation and editing.
Read more about this research using this link.
4. Sapiens2
This research paper introduces Sapiens2, a family of high-resolution vision transformer models designed for human-centric vision tasks, including pose estimation, segmentation, and surface reconstruction.
Sapiens2 models are pretrained using unified objectives (combining masked image reconstruction and self-distilled contrastive learning) on a curated dataset of 1 billion high-quality human images.
These models set a new state of the art, improving over the first generation in pose, body-part segmentation, and normal estimation, and extending to new tasks such as pointmap and albedo estimation.
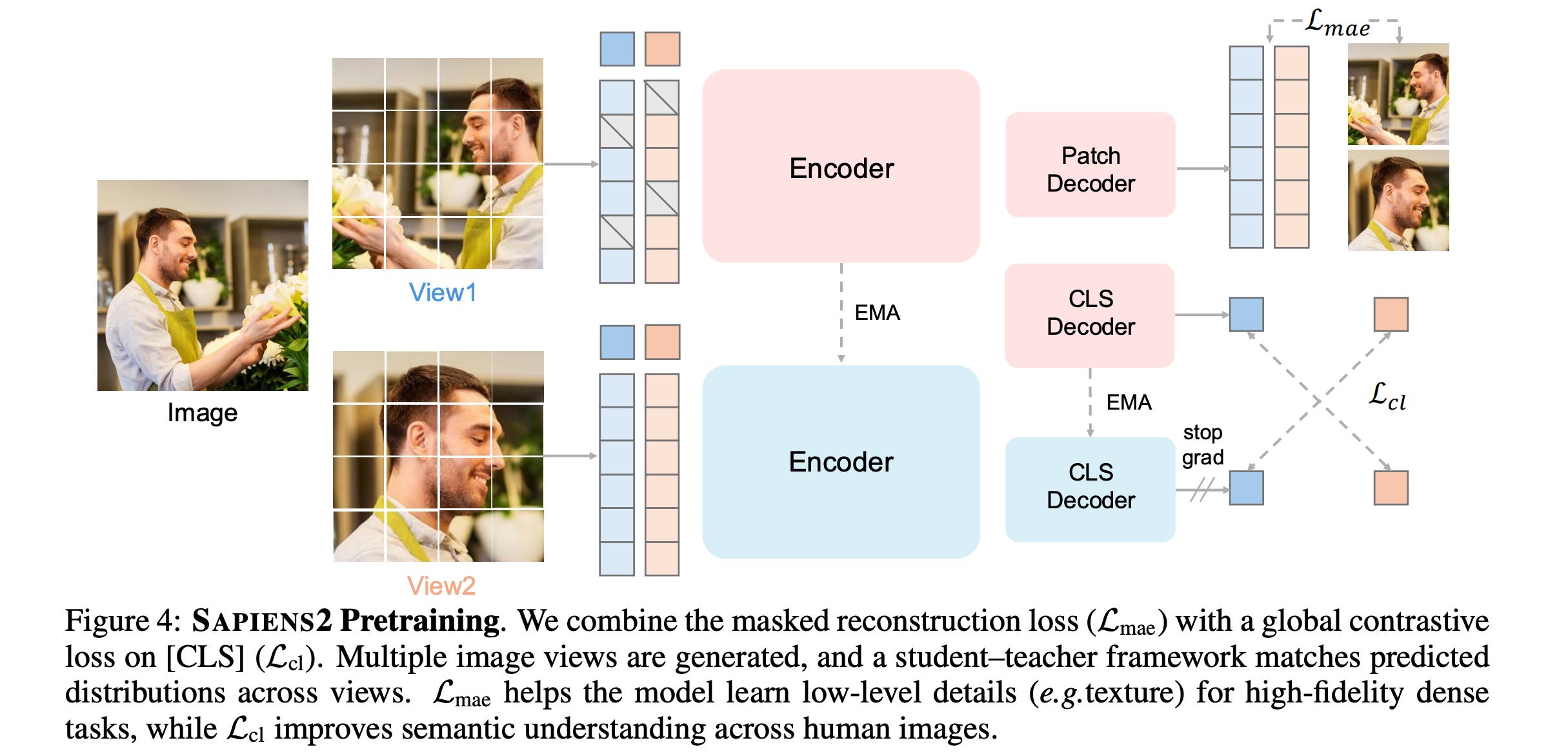
Read more about this research using this link.
5. Neural Garbage Collection
This research paper introduces Neural Garbage Collection (NGC), a method that helps LLMs to selectively forget information while reasoning.
Instead of keeping all intermediate tokens (which creates large KV caches), a model is trained end-to-end with RL and an outcome-based task reward to learn which tokens to keep and which to discard to manage memory effectively.
NGC enables significant cache compression without sacrificing reasoning accuracy, making LLMs more scalable for long-context inference.
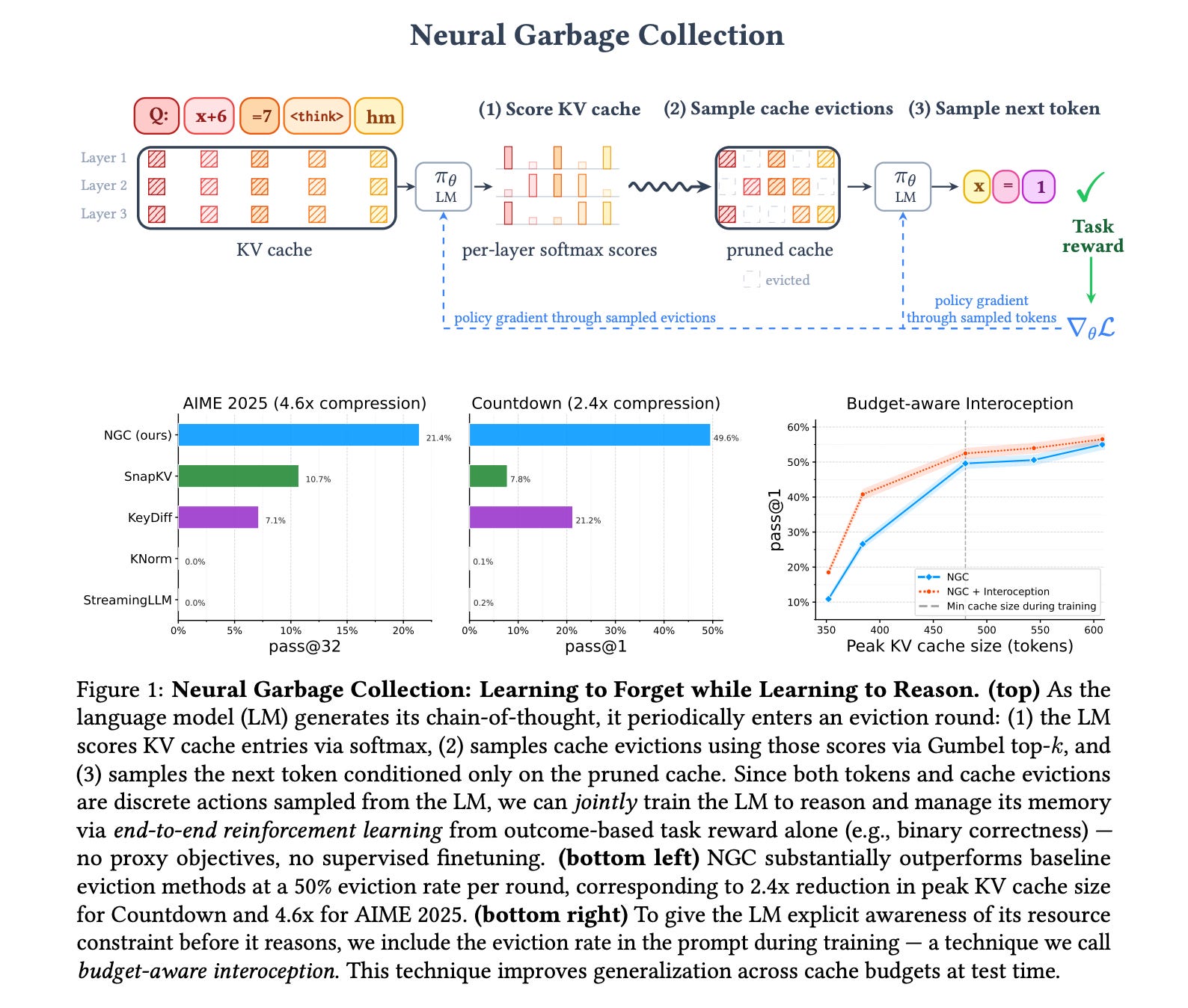
Read more about this research using this link.
6. AI scientists produce results without reasoning scientifically
This research paper tells that current LLM-based research agents can execute scientific workflows, but they do not follow the reasoning processes typical of real science.
Through large-scale experiments, the authors show that performance is driven almost entirely by the base model rather than agent scaffolding, and that agents often overlook evidence, seldom change their beliefs, and rarely combine different lines of evidence.
As a result, their outputs may seem accurate, but the reasoning behind them lacks key epistemic properties, such as hypothesis testing and self-correction.
For AI systems to produce reliable and trustworthy knowledge, scientific reasoning itself needs to become a training objective, and simply improving prompts or agent frameworks is not enough.
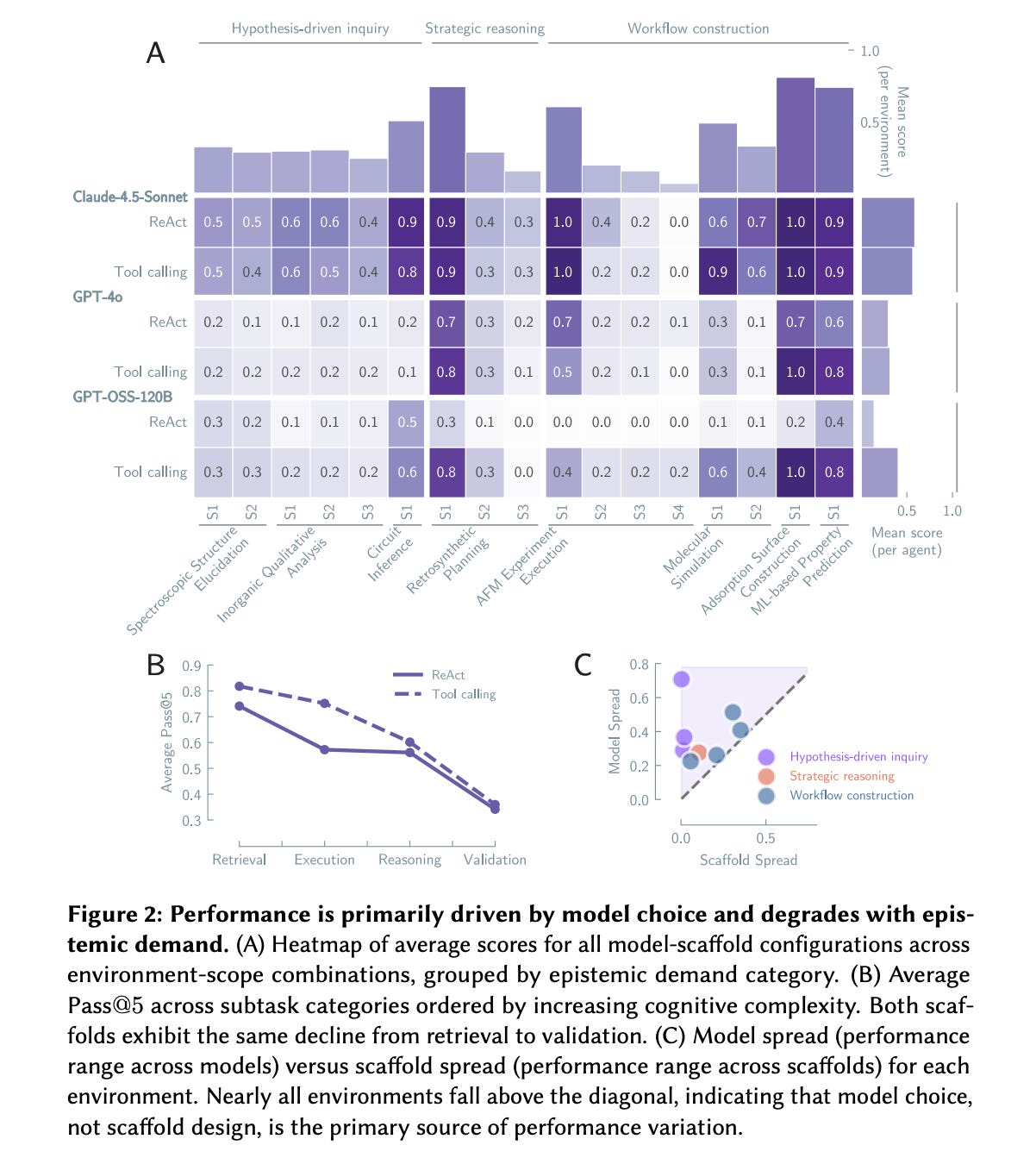
Read more about this research using this link.
7. SWE-chat: Coding Agent Interactions From Real Users in the Wild
This research paper presents SWE-chat, the first large-scale dataset of real coding agent sessions collected from open-source developers in the wild, containing 6,000 sessions, more than 63,000 user prompts, and 355,000 agent tool calls.
Experiments with SWE-chat show that:
In 41% of sessions, agents author virtually all committed code (a.k.a. “Vibe coding”), while in 23% of sessions, humans write all code themselves.
Only 44% of all agent-produced code survives into user commits, and agent-written code introduces more security vulnerabilities than human-authored code.
Users push back against agent outputs (through corrections, failure reports, and interruptions) in 44% of all turns.
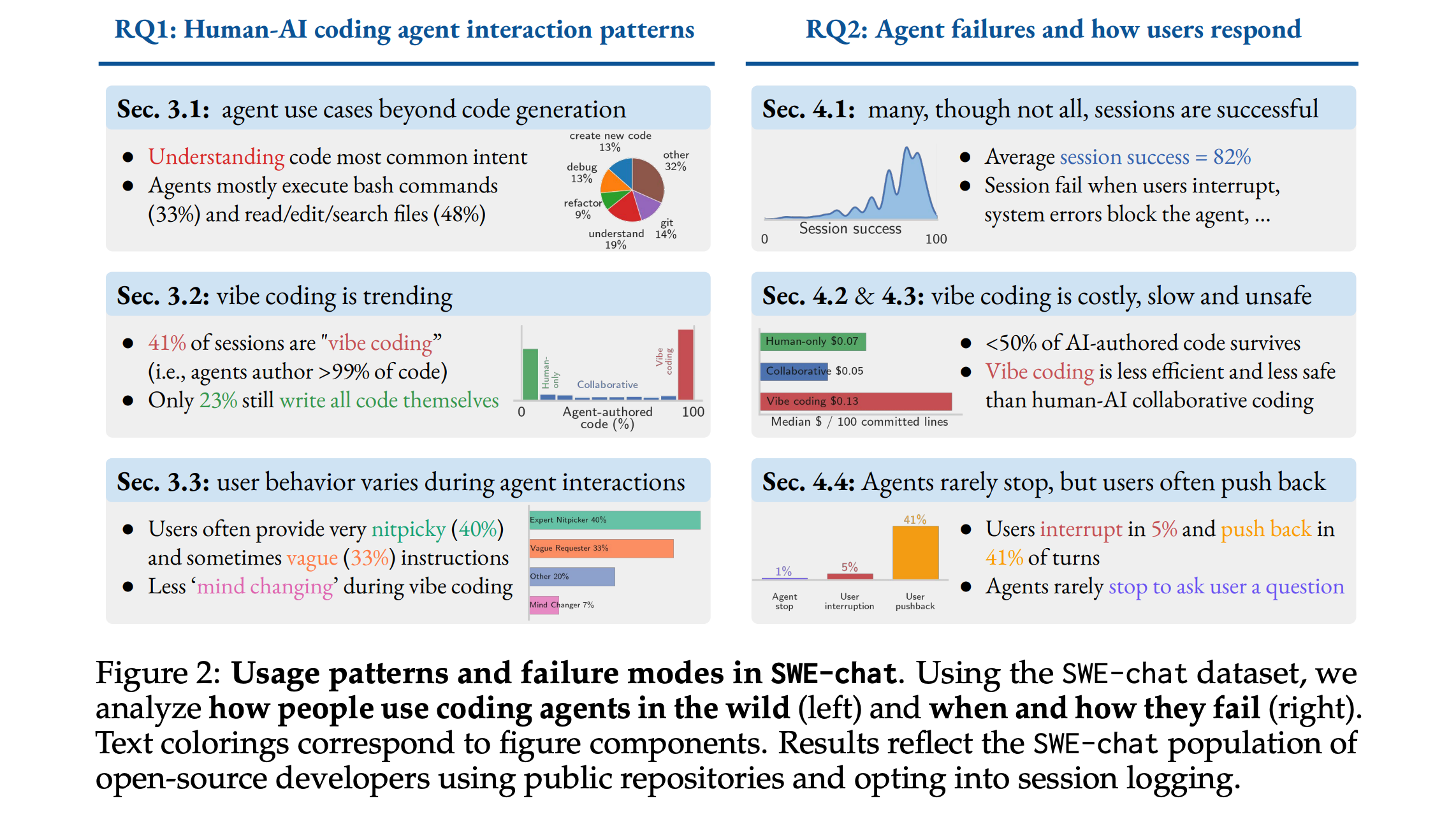
Read more about this research using this link.
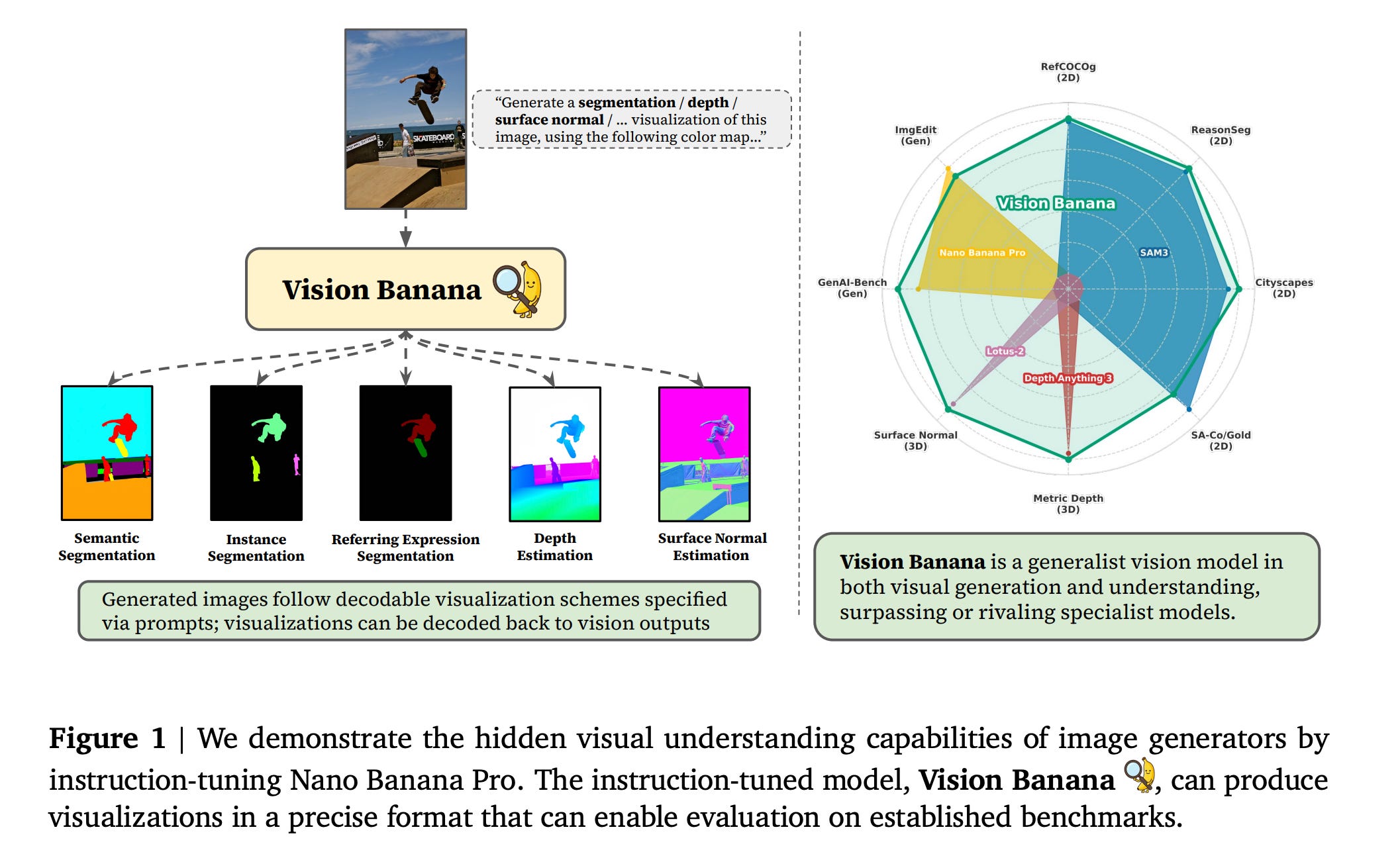
8. Image Generators are Generalist Vision Learners
This research paper argues that training image-generation models builds a general visual understanding in them, similar to how LLMs develop broad capabilities through generative pre-training.
While learning how to generate images, these models also learn rich representations that apply to many vision tasks, such as segmentation and depth estimation in a zero-shot or minimally supervised way.
The authors show this with a generalist model called Vision Banana, built by instruction-tuning Nano Banana Pro (NBP) on a mixture of its original training data alongside a small amount of vision task data.
Vision Banana achieves state-of-the-art results across multiple vision tasks, including 2D and 3D understanding, outperforming or matching zero-shot domain specialists, such as SAM 3, on segmentation tasks and the Depth Anything series on metric depth estimation.
Read more about this research using this link.
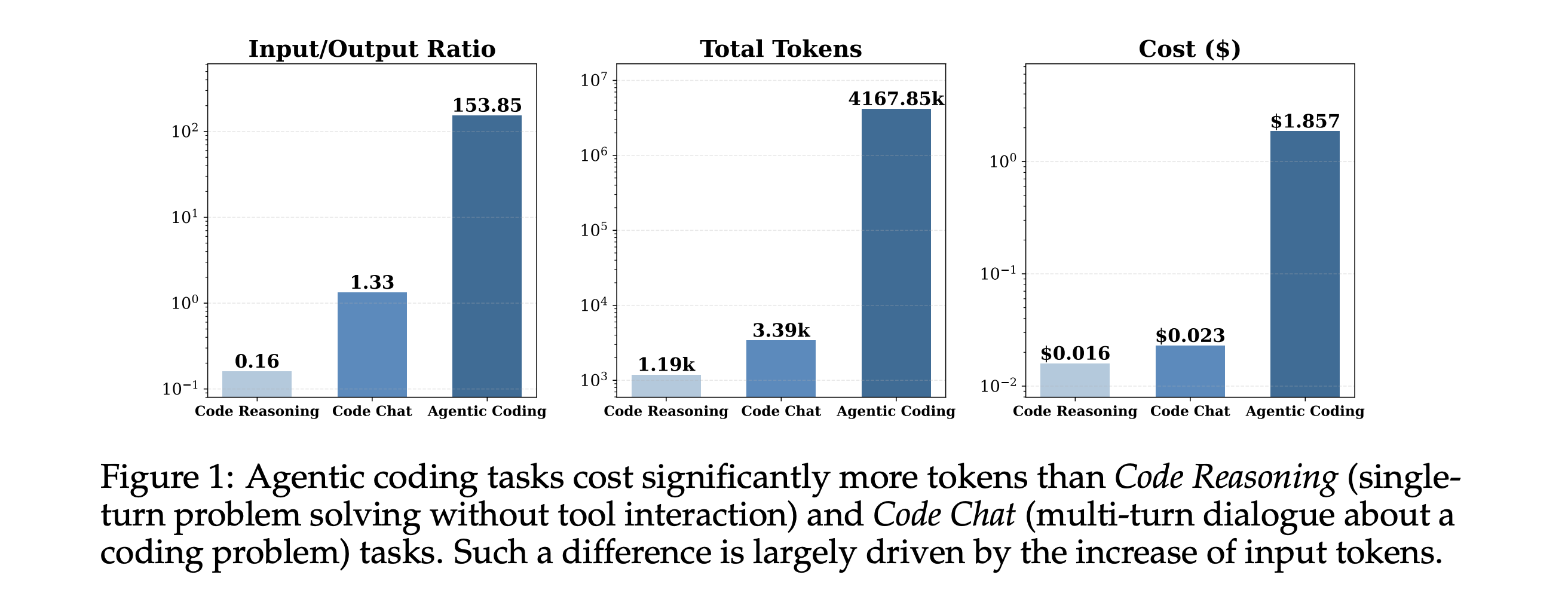
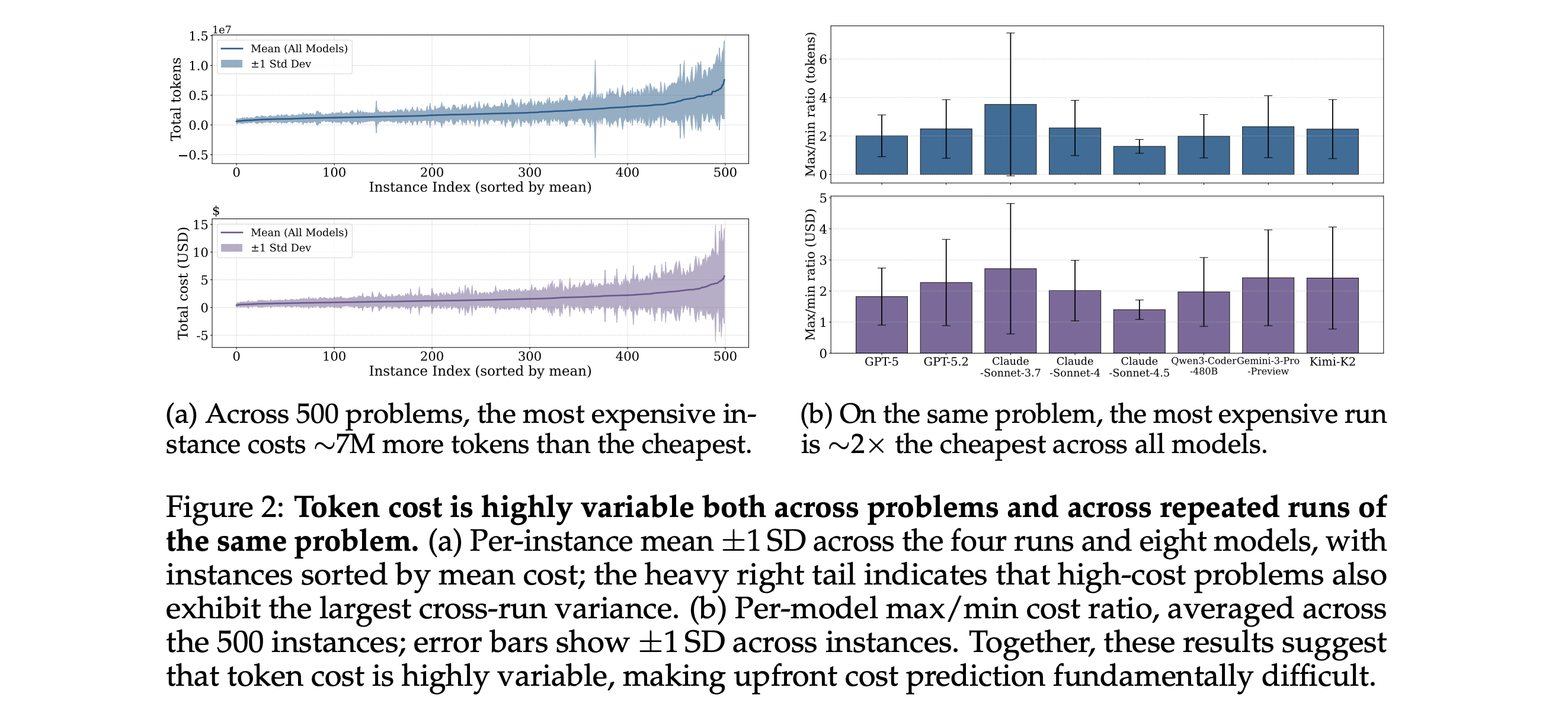
9. How Do AI Agents Spend Your Money?
This research paper examines how modern coding agents use tokens in real workflows and why they can unexpectedly become expensive.
The paper analyzes trajectories from 8 frontier LLMs on SWE-bench Verified and evaluates their ability to predict their own token costs before task execution.
Some of the interesting findings from this paper are:
Agentic tasks consume 1000× more tokens than code reasoning and code chat, with input tokens rather than output tokens driving the overall cost.
Token usage is highly variable, and multiple runs on the same task can differ by up to 30× in total tokens.
Higher token usage does not translate into higher accuracy. Instead, accuracy often peaks at intermediate cost and saturates at higher costs.
Models differ substantially in token efficiency. On the same tasks, Kimi-K2 and Claude-Sonnet-4.5, on average, consume over 1.5M more tokens than GPT-5.
Task difficulty ratings by human experts align only weakly with actual token costs.
Frontier models fail to accurately predict their own token usage and systematically underestimate real token costs.
Read more about this research using this link.
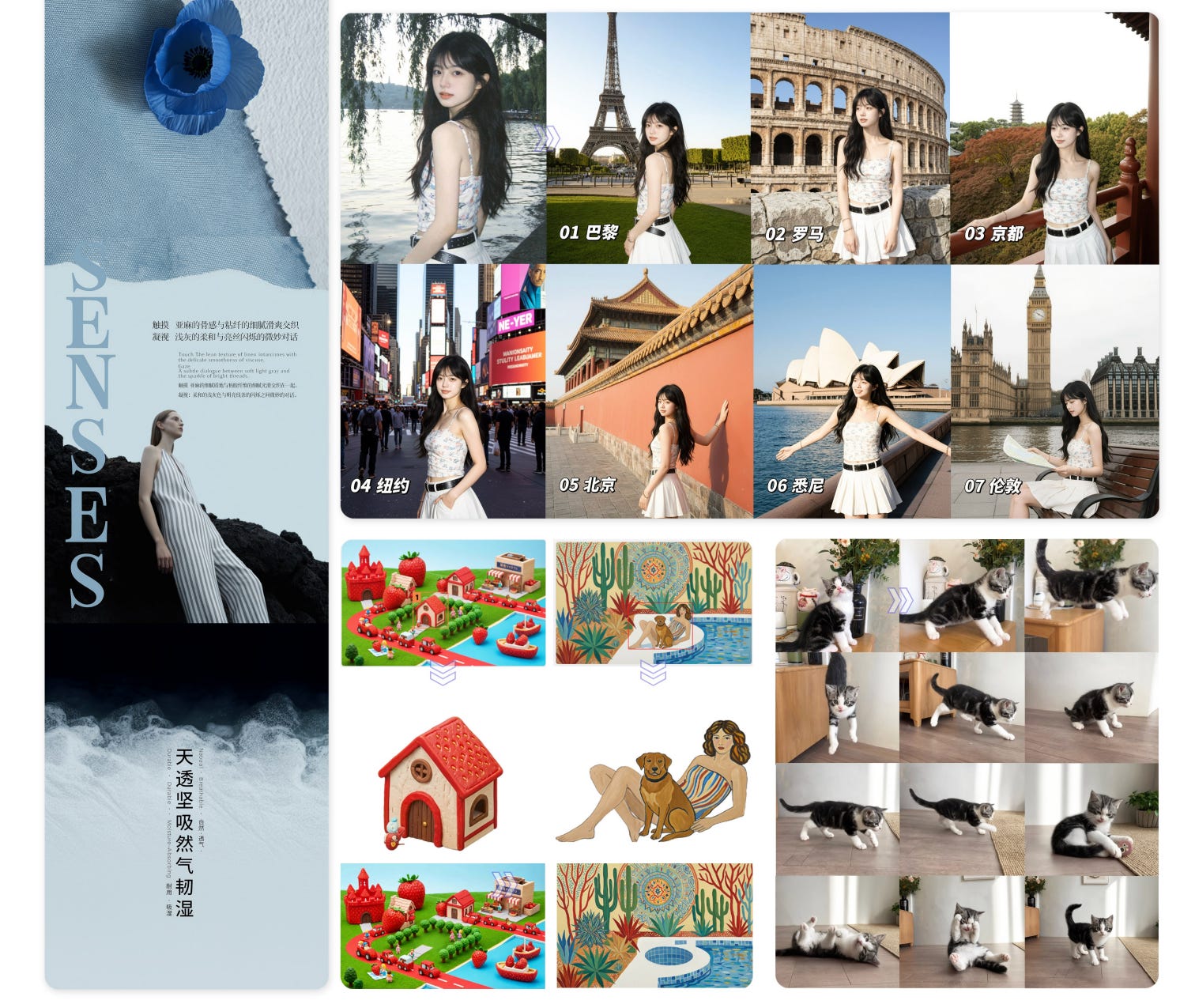
10. Wan-Image
This research paper presents Wan-Image, a unified multimodal image generation system designed to move beyond casual image synthesis into professional-grade visual creation tools.
It combines a reasoning-capable multimodal LLM (planner) with a diffusion-based image generator (visualizer), allowing the system to understand complex user intent and produce precise, high-quality outputs.
Unlike typical diffusion models, Wan-Image focuses on control and real-world usability. It supports features such as long-text rendering, identity consistency across images, palette-guided design, multi-image storytelling, and high-resolution (4K) generation.
Wan-Image outperforms Seedream 5.0 Lite and GPT Image 1.5 across the board, achieving parity with Nano Banana Pro on challenging tasks.
Read more about this research using this link.
Share this article with others and earn referral rewards. ❤️
Join the paid tier today to get access to all posts on this newsletter:
and so many more!
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
