

This Week In AI Research (5-11 April 26)
The top 10 AI research papers that you must know about this week.


Join the paid tier today to get access to all posts on this newsletter:
and so many more!
1. Train 100B+ parameter LLMs on a single GPU
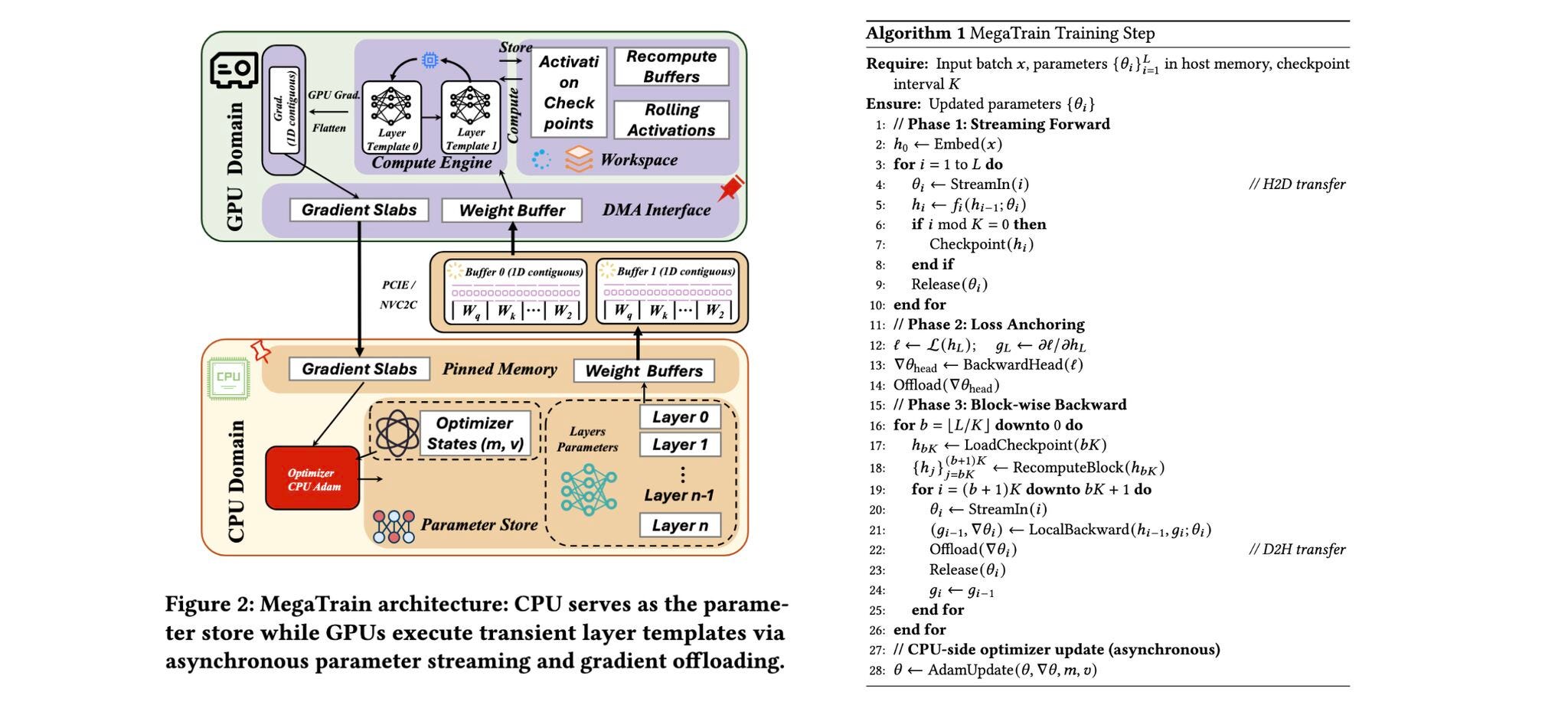
The research paper introduces MegaTrain, a memory-focused training system that allows 100B+ parameters LLMs to be trained at full precision on a single GPU.
This is done by moving model parameters and optimizer states to CPU (host) memory and streaming them to the GPU only when necessary. This is unlike traditional GPU-centric systems, which, instead of keeping the entire model state on the GPU, treat the GPU as a temporary compute unit.
The method uses pipelined, double-buffered execution to overlap data transfer, computation, and gradient updates, helping overcome CPU-to-GPU bandwidth limits. Additionally, it swaps out the usual persistent autograd graphs for stateless layer templates to improve efficiency and flexibility.
On a single H200 GPU with 1.5 TB of host memory, MegaTrain reliably trains models with up to 120B parameters. It also achieves 1.84× the training throughput of DeepSpeed ZeRO-3 with CPU offloading when training 14B models.
Read more about this research paper using this link.
2. AI Cybersecurity After Mythos
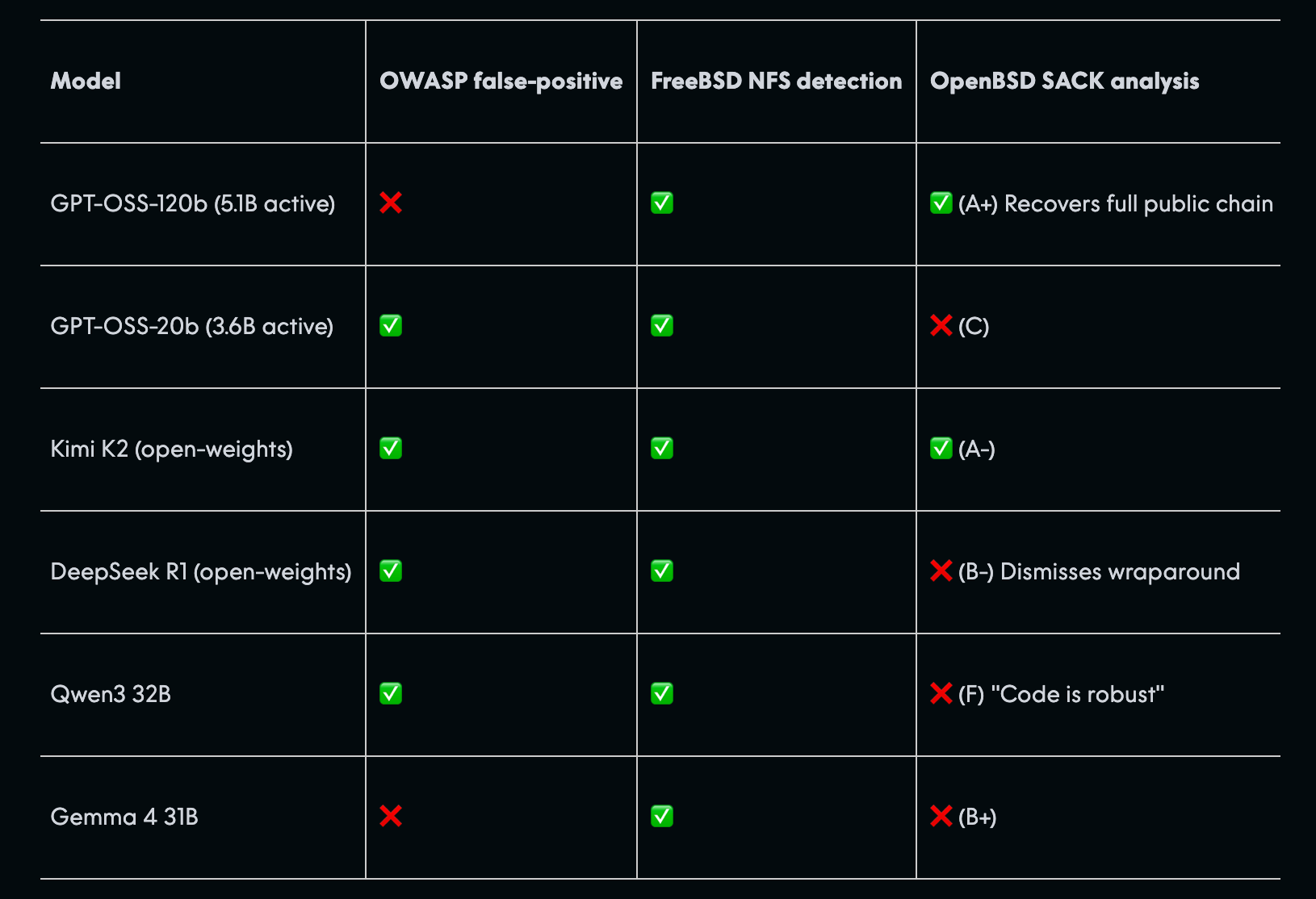
Anthropic’s new LLM, called Mythos Preview, recently found multiple critical cybersecurity vulnerabilities in OpenBSD, FFmpeg, and the Linux kernel.
Despite the excitement around this, research at AISLE suggests that AI cybersecurity capabilities are “jagged” instead of consistently improving with model size. Smaller, cheaper, and even open models can often replicate much of Mythos’s vulnerability analysis when given the right context.
This means that the real competitive edge lies not in the LLM itself but in the system architecture, which includes pipelines, tools, and embedded security expertise that manage scanning, triage, validation, and patching.
Effective cybersecurity relies more on widely deploying solid systems than on having access to the most advanced AI.
Read this blog post using this link.
3. Neural Computers
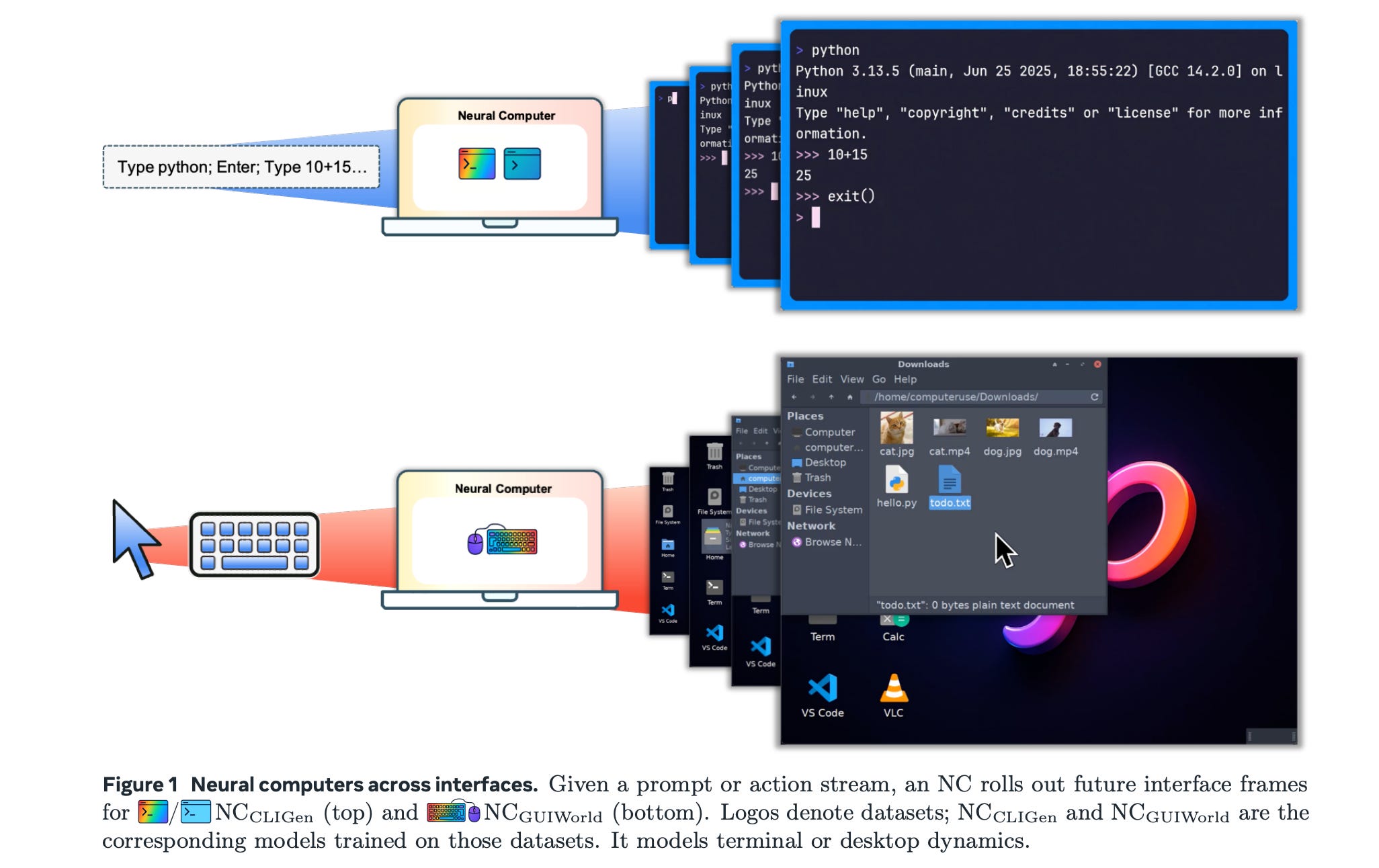
This research paper proposes Neural Computers, a new computing model where a neural network acts as the computer itself. This approach combines computation, memory, and input/output into a single learned runtime state that does not depend on separate external software or hardware.
The paper introduces early prototypes, including CLI- and GUI-based video models that learn to imitate and respond to interface behavior solely from input/output traces. This demonstrates that basic runtime functions, such as I/O alignment and short-horizon control, can develop without explicit programming.
However, these systems have limitations. They lack stable reuse, symbolic reasoning, and consistent execution. To address these issues, the paper outlines a plan for a “Completely Neural Computer” that would be fully programmable, reliable, and general-purpose.
Read more about this research paper using this link.
4. MedGemma 1.5
This research paper introduces MedGemma 1.5 4B, the latest model in the MedGemma collection from Google that expands on MedGemma 1 by integrating:
High-dimensional medical imaging (CT/MRI volumes and histopathology whole slide images)
Anatomical localization via bounding boxes
Multi-timepoint chest X-ray analysis
Improved medical document understanding (lab reports, electronic health records)
Compared to the previous version, MedGemma 1.5 shows significant improvements across multiple tasks: 11% increase in 3D MRI condition classification accuracy, 47% increase in F1 score in whole-slide pathology imaging, and 22% increase in EHR QA accuracy, establishing it as a general-purpose multimodal foundation model for healthcare.

Read more about this research paper using this link.
5. Muse Spark
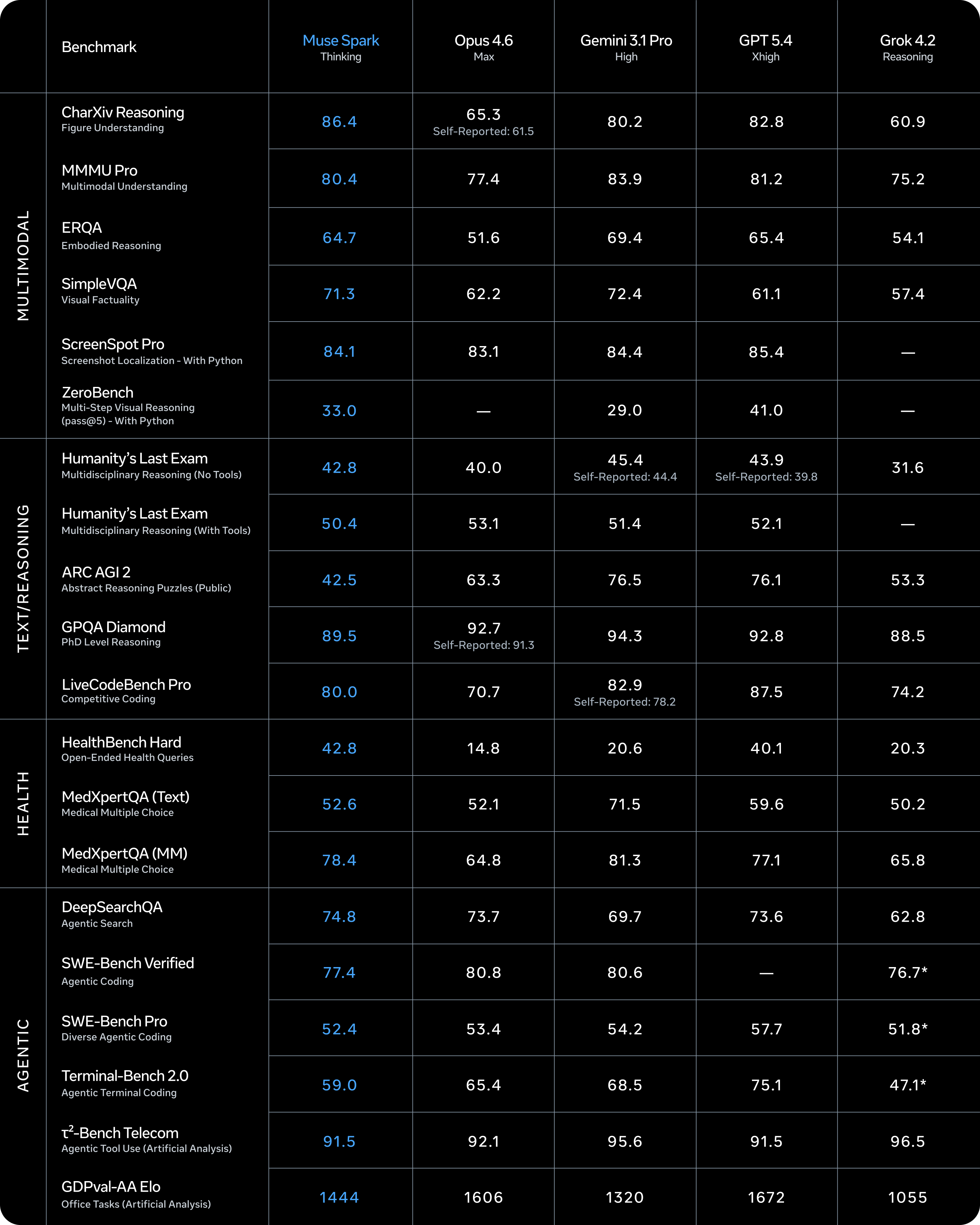
Meta Superintelligence Labs introduced Muse Spark, the first model in the Muse family of LLMs. Muse Spark is a multimodal reasoning model with support for tool-use, visual chain of thought, and multi-agent orchestration.
It ranks among the top multimodal vision models (80.4% on MMMU-Pro) and performs well on challenging benchmarks, achieving 58% on Humanity’s Last Exam and 38% on FrontierScience Research.
It is particularly strong on health benchmarks, achieving 42.8 on HealthBench Hard (beating GPT-5.4 and far exceeding Gemini and Opus 4.6), and leads on tasks like chart/figure reasoning (86% on CharXiv).
Read more about this release using this link.
6. TorchTPU
Google introduced TorchTPU, which allows PyTorch to run directly and efficiently on TPUs. TorchTPU supports SPMD-style distributed execution across TPU pods, automatically captures and compiles graphs, and efficiently manages memory and communication. This setup enables large-scale training with minimal code changes.

Read more about this release using this link.
7. TriAttention
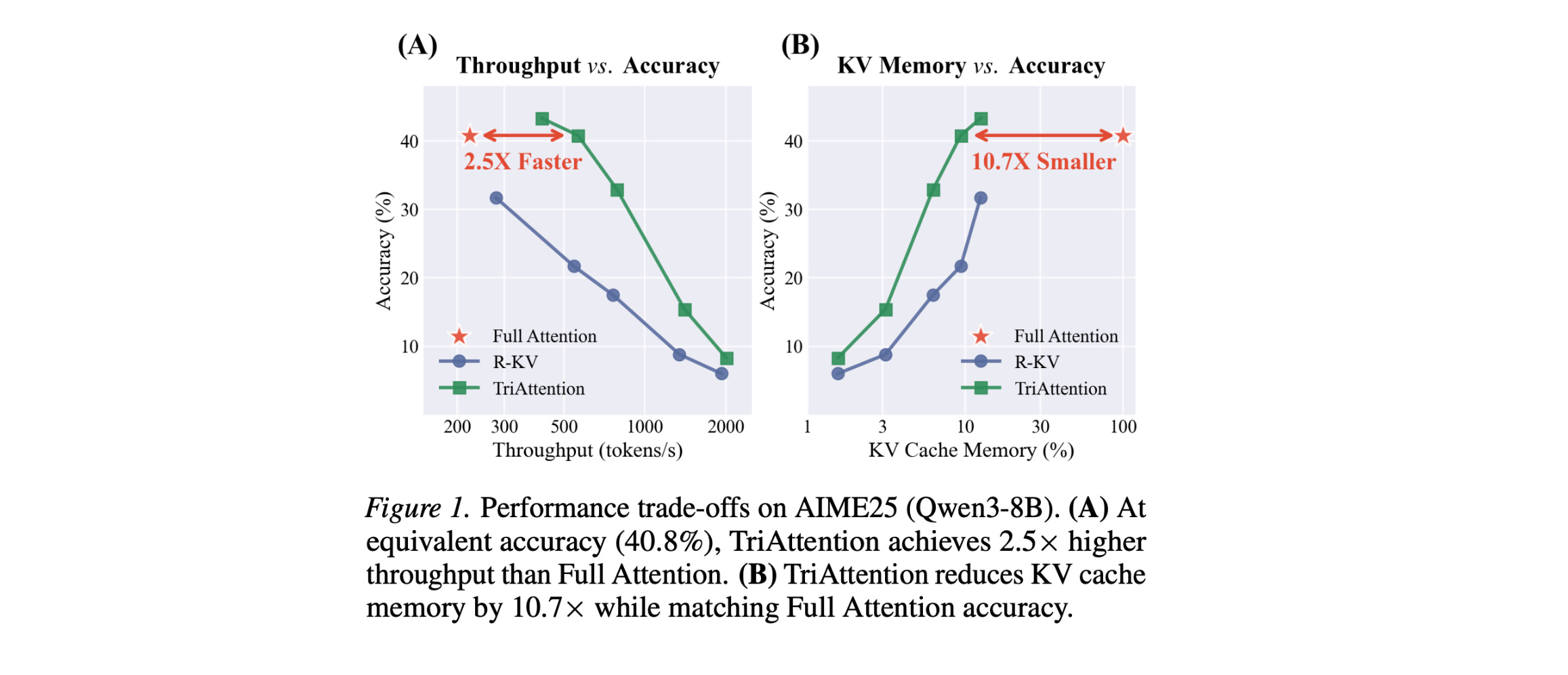
This research paper presents TriAttention, a new method to reduce the KV cache memory issue in long-context LLM reasoning.
It does this by analyzing Attention in the pre-RoPE space, where query and key vectors stay stable and follow predictable distance patterns. Instead of relying on recent attention scores (which can be unreliable due to positional rotation), it uses a trigonometric model of Q/K “centers” to figure out which tokens matter, leading to better compression.
On AIME25 with 32K token generation, TriAttention matches Full Attention's reasoning accuracy while achieving 2.5× higher throughput or 10.7× lower KV memory usage, whereas leading baselines achieve only about half the accuracy at the same efficiency.
TriAttention also enables OpenClaw to be deployed on a single consumer GPU, where long context would otherwise cause out-of-memory with full Attention.
Read more about this research using this link.
8. LPM 1.0
Existing video models struggle to achieve high expressiveness, real-time inference, and long-horizon identity stability together (the Performance trilemma).
This is addressed in this research paper, which introduces LPM 1.0, a model that learns to create realistic character performance (emotion, intent, timing, and motion) directly from video data, aiming to replace traditional pipelines.
LPM 1.0 achieves state-of-the-art results across all evaluated dimensions while maintaining real-time inference, and serves as a visual engine for conversational agents, live-streaming characters, and game NPCs.

Read more about this research using this link.
9. PaperOrchestra
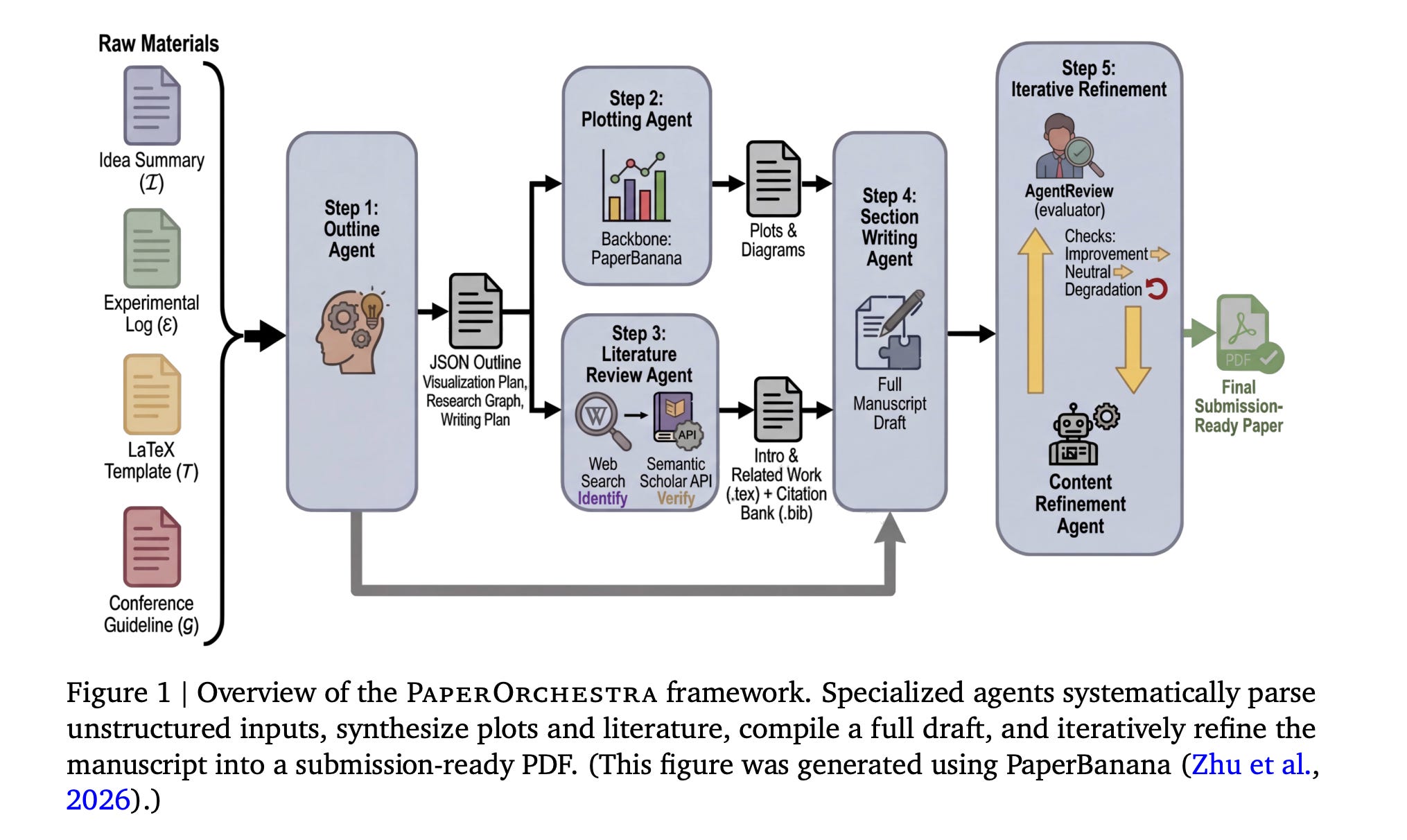
This research paper from Google introduces PaperOrchestra, a multi-agent framework for automated AI research paper writing.
The framework uses multiple agents, each handling a different step (literature review, experiment interpretation, writing, figure generation, and citation checking), which are coordinated in a pipeline to produce a submission-ready LaTeX manuscript.
PaperOrchestra significantly outperforms autonomous baselines, achieving absolute win rates of 50%-68% in literature review quality and 14%-38% in overall manuscript quality.
Read more about this research using this link.
10. DMax
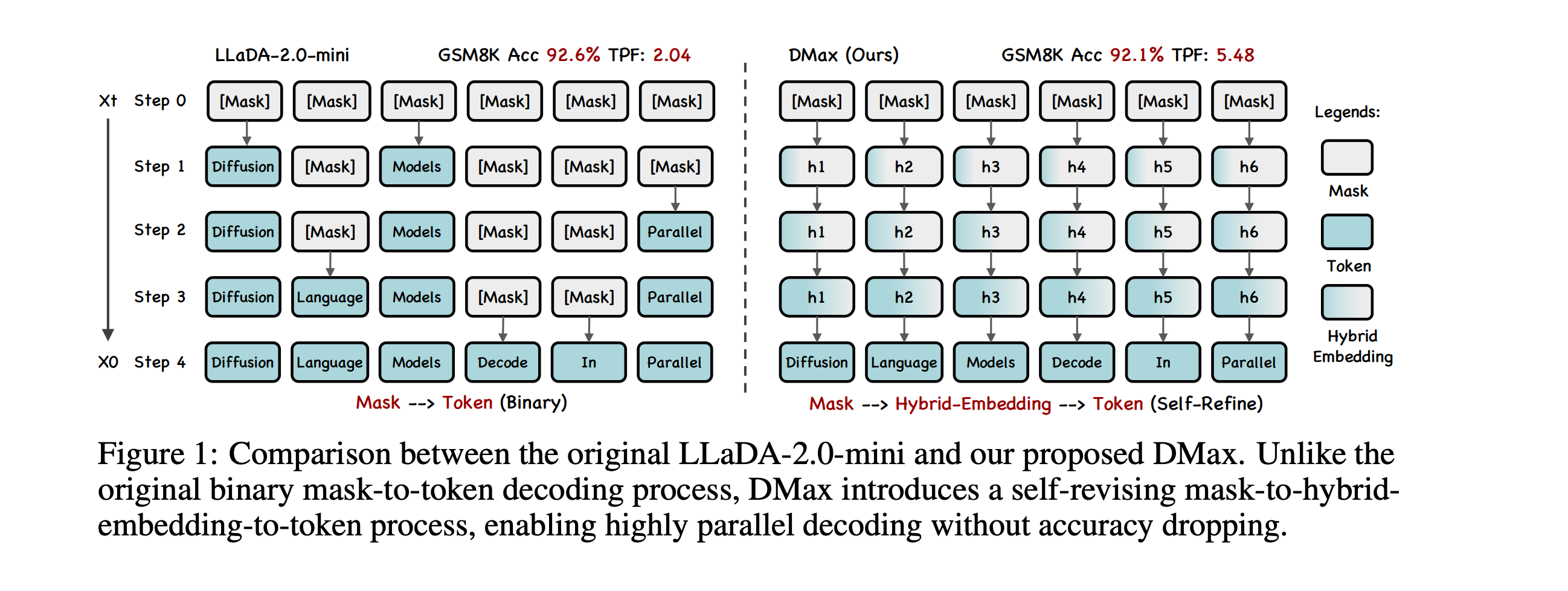
This research paper introduces DMax, a new approach for highly parallel token generation from diffusion LLMs without compromising quality.
Instead of the usual step-by-step or mask-to-token decoding, it redefines the generation process as a gradual self-refinement in which the model continuously improves its predictions in the embedding space.
To achieve this, researchers introduce:
On-Policy Uniform Training
Soft Parallel Decoding
Together, these concepts reduce error buildup during parallel decoding, enabling much faster generation while keeping accuracy close to that of sequential methods.
Read more about this research using this link.
Join the paid tier today to get access to all posts on this newsletter and 100x your AI engineering skills.
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
