

This Week In AI Research (7-13 June 26) 🗓️
The top 10 AI research papers that you must know about this week.


10. DiffusionGemma
Google released DiffusionGemma, an experimental open model that uses Diffusion to generate entire blocks of text simultaneously, leading to 4x faster text generation on dedicated GPUs.
DiffusionGemma is a 26B Mixture-of-Experts (MoE) model that activates only 3.8 billion parameters during inference. It uses bidirectional attention to generate 256 tokens in parallel, with each forward pass allowing every token to attend to all others.
The model comes with native support for NVIDIA’s new NVFP4 (4-bit floating-point) format on Blackwell GPUs, which dramatically increases compute throughput, enabling it to run at faster speeds with near-lossless accuracy.
The model’s impressive capabilities make it particularly helpful for speed-critical local workflows such as inline editing, rapid iteration, code infilling, non-linear text structures, amino acid sequences, mathematical graphs, and tasks like Sudoku.
However, it must also be noted that the standard Gemma 4 still produces higher-quality outputs than DiffusionGemma.

Read more about this release using this link.
If you’re new to Diffusion LLMs, you can read more about them using the following lessons.


9. Frontier Code
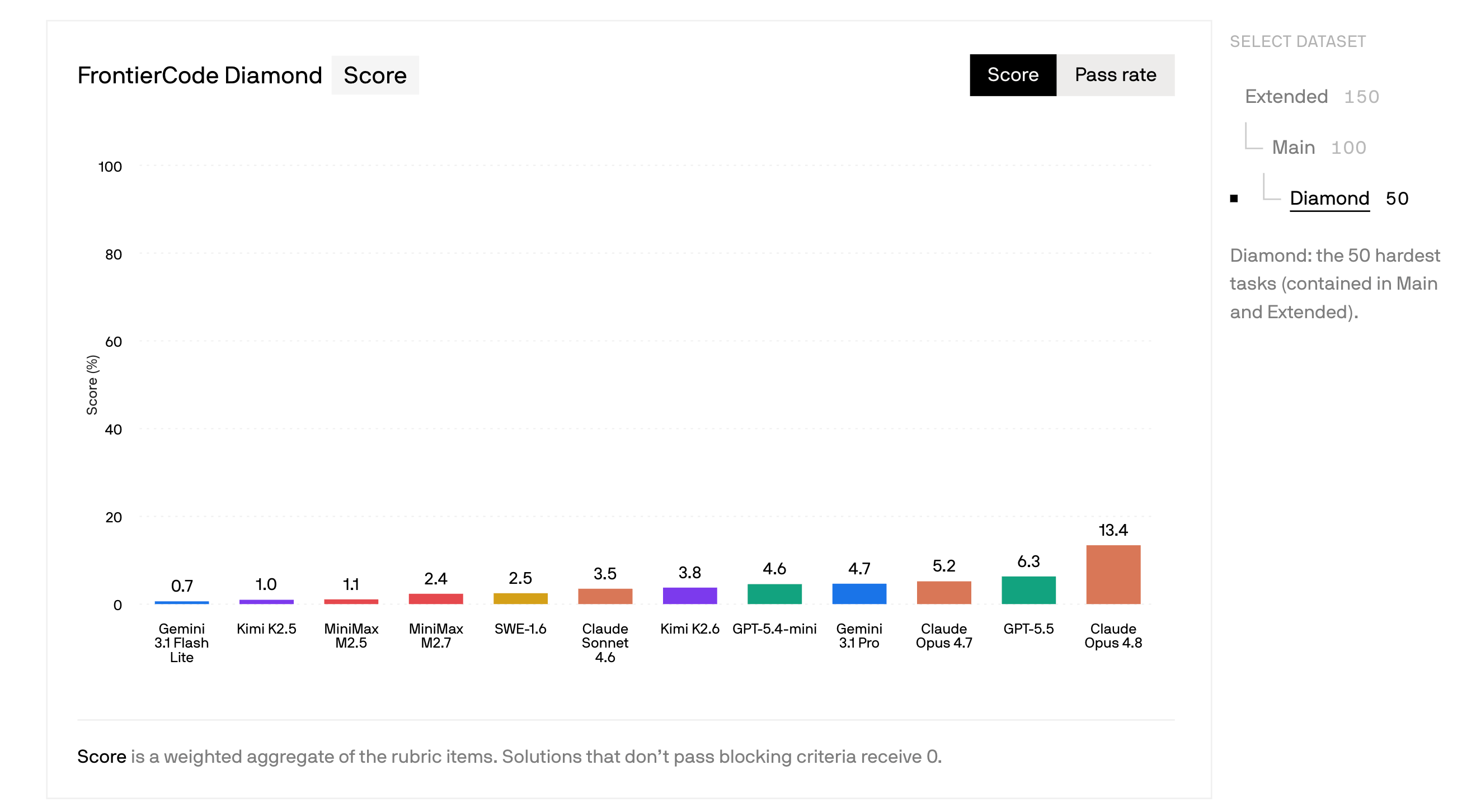
Cognition introduced FrontierCode, a benchmark to test whether AI coding agents can produce production-quality, mergeable code rather than just passing tests.
Built with over 20 open-source maintainers across 36 major repositories, it includes 150 tasks divided into three tiers: Extended, Main, and the hardest Diamond tier.
These tasks are graded on correctness, regression safety, test quality, scope control, style, and codebase conventions. Its evaluation combines unit tests, rubrics, command checks, LLM review, and Cognition’s “mutagent” (an LLM-based tool to surgically patch the test environment/ application code and align with the agent’s implementation details), all with strong quality control.
Cognition claims that FrontierCode has an 81% lower false-positive rate than SWE-Bench Pro and that it is the first-ever benchmark measuring code quality and subtle human preferences.
Claude Opus 4.8 leads the benchmark with a score of 13.4%, GPT-5.5 scores 6.3% while using fewer tokens, and Kimi K2.6 is the top open-source model with a 3.8% score, all on the Diamond tier.
Read more about this release using this link.
Before we move forward, I want to introduce you to my book called ‘LLMs In 100 Images’.
It is a collection of 100 easy-to-follow visuals that describe the most important concepts you need to master LLMs today.
Grab your copy today at a special discount using this link.

8. Claude Fable 5 & Mythos 5
Anthropic released Claude Fable 5, a public Mythos-class model, and Claude Mythos 5, the same underlying model with safeguards lifted for trusted cyberdefenders and infrastructure providers.
This model outperforms all of Anthropic’s previous models on nearly all tested benchmarks and is especially strong on long and complex tasks.

It also has major cybersecurity and scientific research capabilities, including faster drug-design workflows and the generation of novel biological hypotheses.
The publicly released Fable 5 includes safeguards for cybersecurity, biology/chemistry, and distillation-related requests and routes these to the previous model, Claude Opus 4.8.
As of 12th June 2026, access to Claude Fable 5 and Claude Mythos 5 has been suspended due to national security concerns raised by the US government.
Read more about this release using this link.
7. FlashMemory-DeepSeek-V4
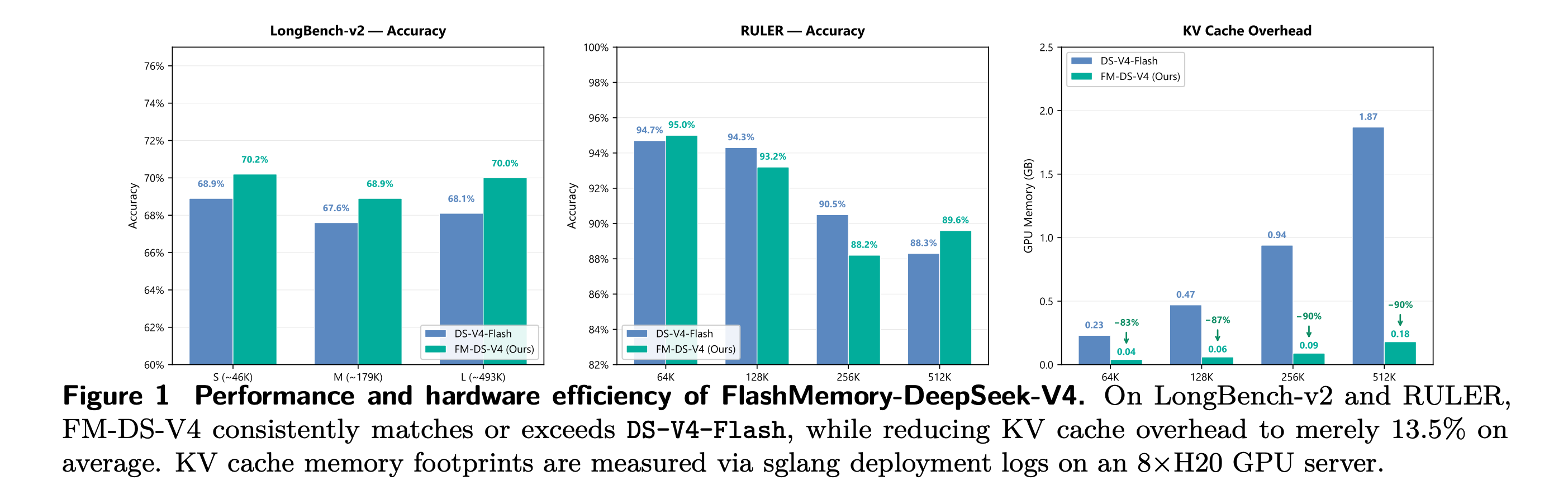
This research paper introduces Lookahead Sparse Attention (LSA), which makes ultra-long-context LLM inference more memory-efficient.
Instead of passively attending to all previous tokens, LSA proactively predicts which parts of the context it'll need in the future and keeps only those KV chunks in GPU memory.
It uses a small "Neural Memory Indexer" built on the DeepSeek-V4 architecture to decide which parts of the context are worth keeping.
Across long-context benchmarks (LongBench-v2, LongMemEval, and RULER), this uses just 13.5% of the memory on average while maintaining the same accuracy.
And at 500K-token lengths, it reduces memory overhead by more than 90% without compromising the model's reasoning ability.
Read more about this research using this link.
6. Latent Spatial Memory for Video World Models
This research paper introduces Mirage, a latent-space spatial memory framework for making generated videos more 3D-consistent over long camera trajectories.
Rather than storing scene memory as an RGB point cloud that requires repeated rendering and re-encoding, Mirage stores static scene information as 3D latent tokens within the diffusion model’s latent space.
It builds this memory by lifting latent tokens into 3D with depth-guided back-projection, reads it through direct latent-space warping, and updates it chunk by chunk while filtering dynamic objects.
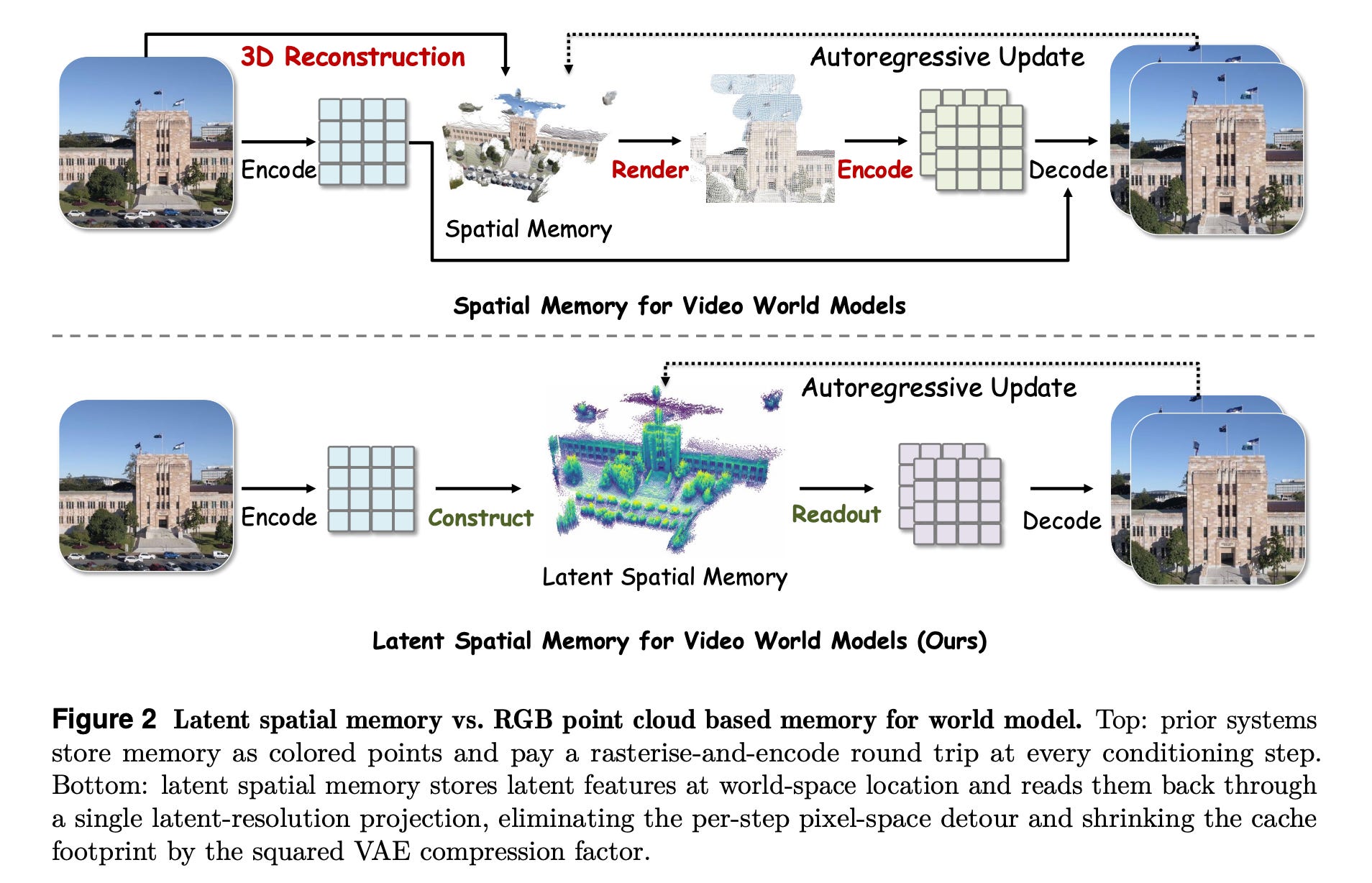
Experiments show that Mirage achieves up to 10.57× faster end-to-end video generation and a 55× reduction in memory footprint relative to explicit 3D baselines. It also attains SOTA performance on WorldScore and strong reconstruction quality on RealEstate10K.
Read more about this research using this link.
5. MiniMax Sparse Attention (MSA)
This research paper introduces MiniMax Sparse Attention (MSA), a blockwise sparse attention built upon Grouped Query Attention (GQA).
Traditional attention has a cost that grows quadratically with the number of tokens it attends to. This becomes far too expensive for LLMs with ultra-long contexts.
MSA uses a lightweight “Index Branch” to score KV blocks and select a Top-k subset for each query group, while a “Main Branch” performs exact sparse attention only over those selected blocks.
On a 109B-parameter model with native multimodal training, MSA performs on par with GQA while reducing per-token attention compute by 28.4× at 1M context. With an efficient kernel, it also achieves 14.2× prefill and 7.6× decoding speedups on the H800 GPU.
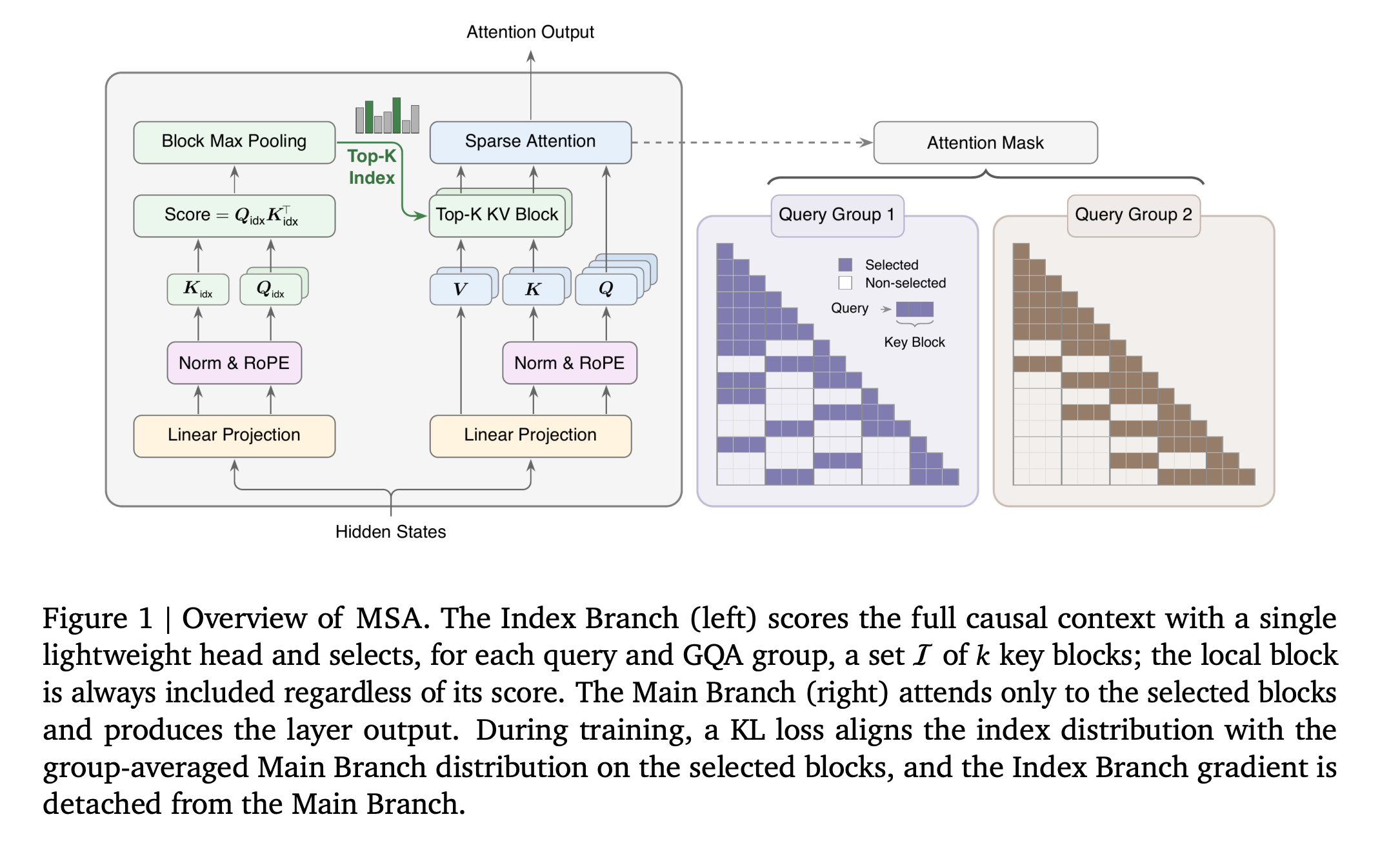
Read more about this research using this link.
4. First Steps Toward Automated AI Research
This blog post from Recursive introduces their automated AI research system, which achieves SOTA results across three benchmarks (fixed-budget language model training, small-model training speed, and GPU kernel optimization).
The system runs as an end-to-end research loop that includes proposing ideas, implementing them, running experiments, validating results, and using what it learns to choose future experiments.
On NanoChat Autoresearch, it improved fixed-budget language model training from 0.9372 to 0.9109 validation BPB.

On NanoGPT Speedrun, it reduced training time from 79.7s to 77.5s.

And on SOL-ExecBench, it raised the mean GPU-kernel optimization score from 0.699 to 0.754, which is an 18% reduction in the gap to the estimated hardware optimum.

Read more about this research using this link.
3. End-to-End Context Compression at Scale
This research paper introduces Latent Context Language Models (LCLMs), a family of encoder-decoder compressors that improve the efficiency of long-context LLM inference compared to using full KV caches.
LCLMs compress long token sequences into shorter latent embeddings, which the decoder can use directly. This improves the trade-off among task performance, compression speed, and peak memory usage while avoiding common limitations of KV compression (quality loss, high compression costs, constraints on target context windows, and poor compatibility with production inference systems).
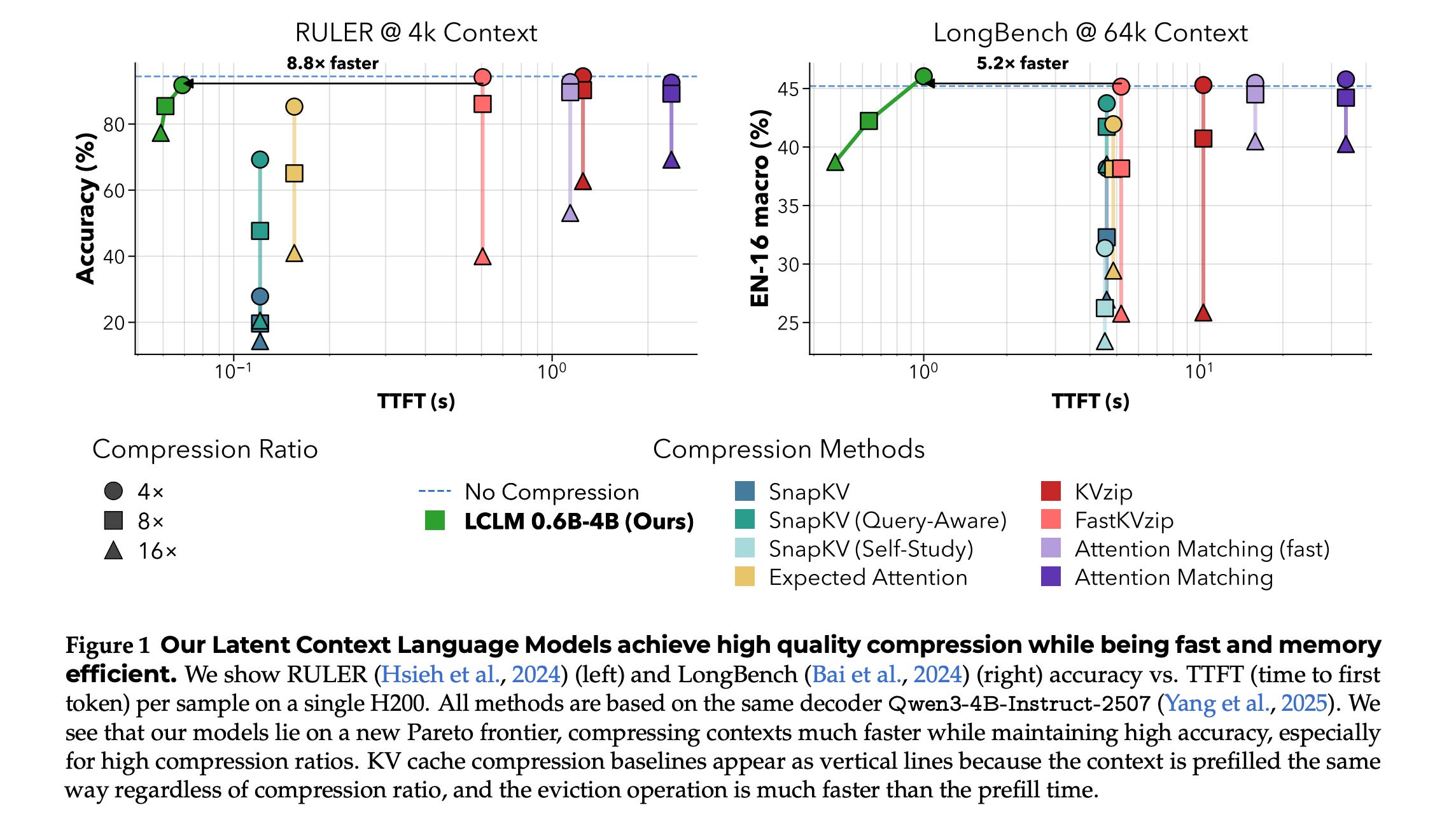
Read more about this research paper using this link.
2. General-purpose large language models outperform specialized clinical AI tools on medical benchmarks
This research paper evaluates two clinical AI tools, OpenEvidence and UpToDate Expert AI, against three frontier LLMs (GPT-5.2, Gemini 3.1 Pro, and Claude Opus 4.6) across:
500 MedQA questions testing medical knowledge
500 HealthBench items measuring alignment with clinicians
Real clinical queries (RCQ) benchmark, built from 100 de-identified queries from physicians to a general-purpose language model in a live clinical environment
The results show that frontier LLMs outperform clinical AI tools in all three evaluations.
On the RCQ benchmark, Clinical AI tools perform comparably to the auto-enabled Google Search AI Overview.
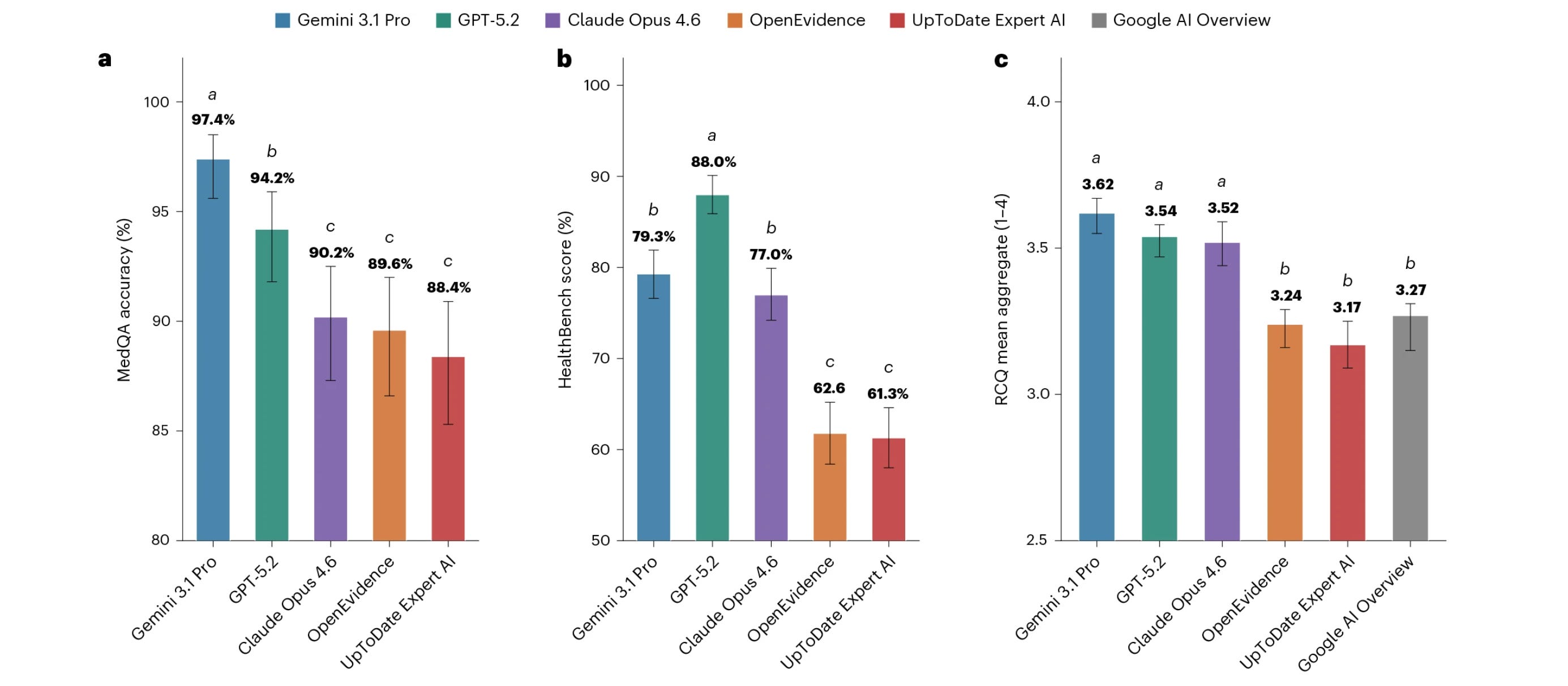
Read more about this research paper using this link.
1. Self-Harness: Harnesses That Improve Themselves
This research paper introduces Self-Harness, which lets LLM-based agents improve their own operating harness without relying on human engineers or stronger external agents.
Self-Harness works iteratively in three stages:
It first checks the execution traces and finds which model-specific patterns led to failure (Weakness Mining)
It then generates harness modifications tied to these failures (Harness Proposal)
Finally, it accepts the modifications after successful regression testing (Proposal Validation)
When tested on Terminal-Bench-2.0 using three models (MiniMax M2.5, Qwen3.5-35B-A3B, and GLM-5) initialized with a minimal harness, Self-Harness consistently improves held-out pass rates by 21.4%, 14.3%, and 14.2%, respectively.
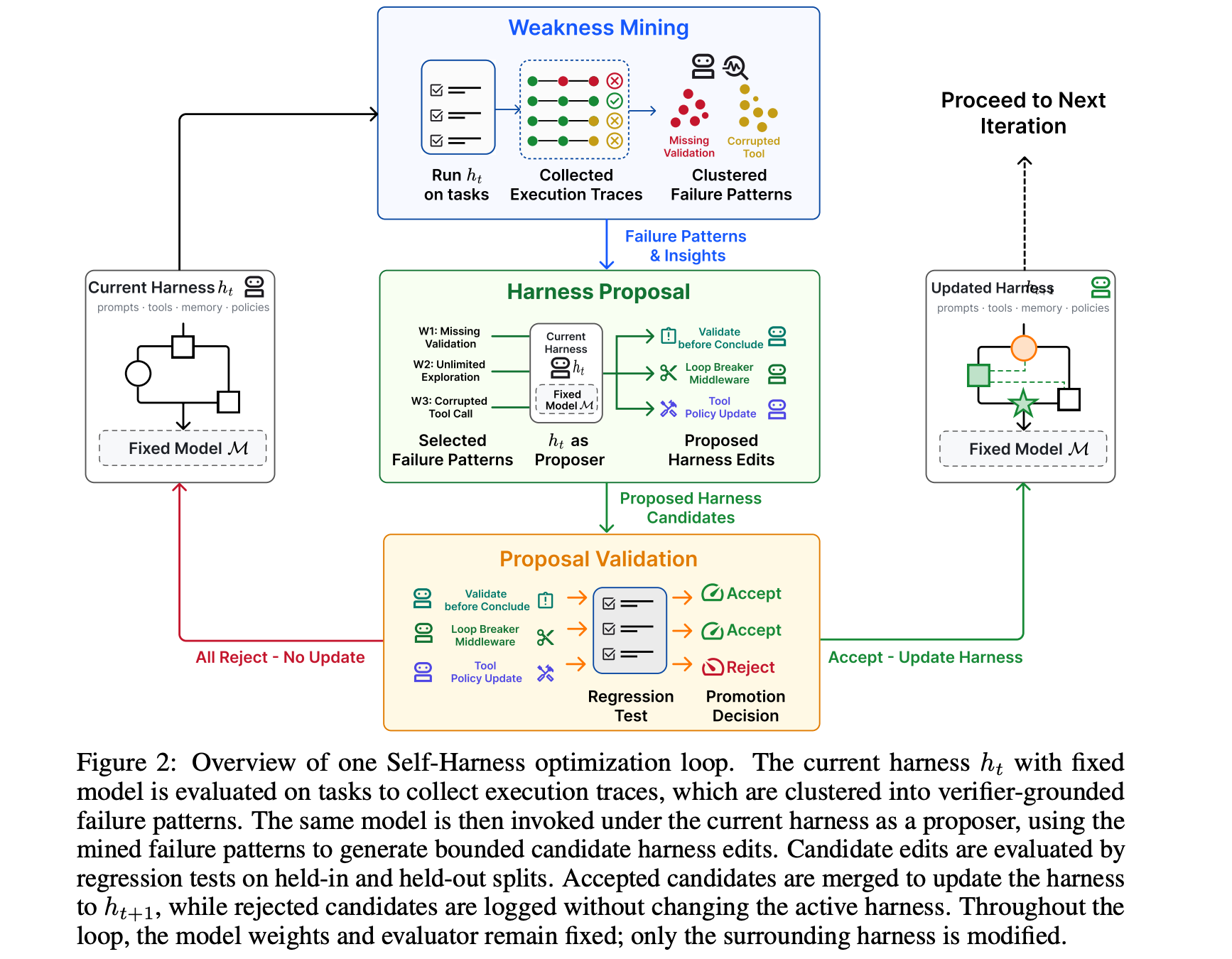
Read more about this research paper using this link.
This newsletter edition is completely free to read.
If you found it valuable, click the like button ❤️ and consider subscribing for more such content every week.
If you have any questions or suggestions, feel free to leave a comment below.
Into AI is a reader-supported newsletter. Gain access to deeper, members-only content by becoming a paid subscriber today.