

🗓️ This Week In AI Research (1-7 March 26)
The top 10 AI research papers that you must know about this week.

1. Introducing GPT‑5.4
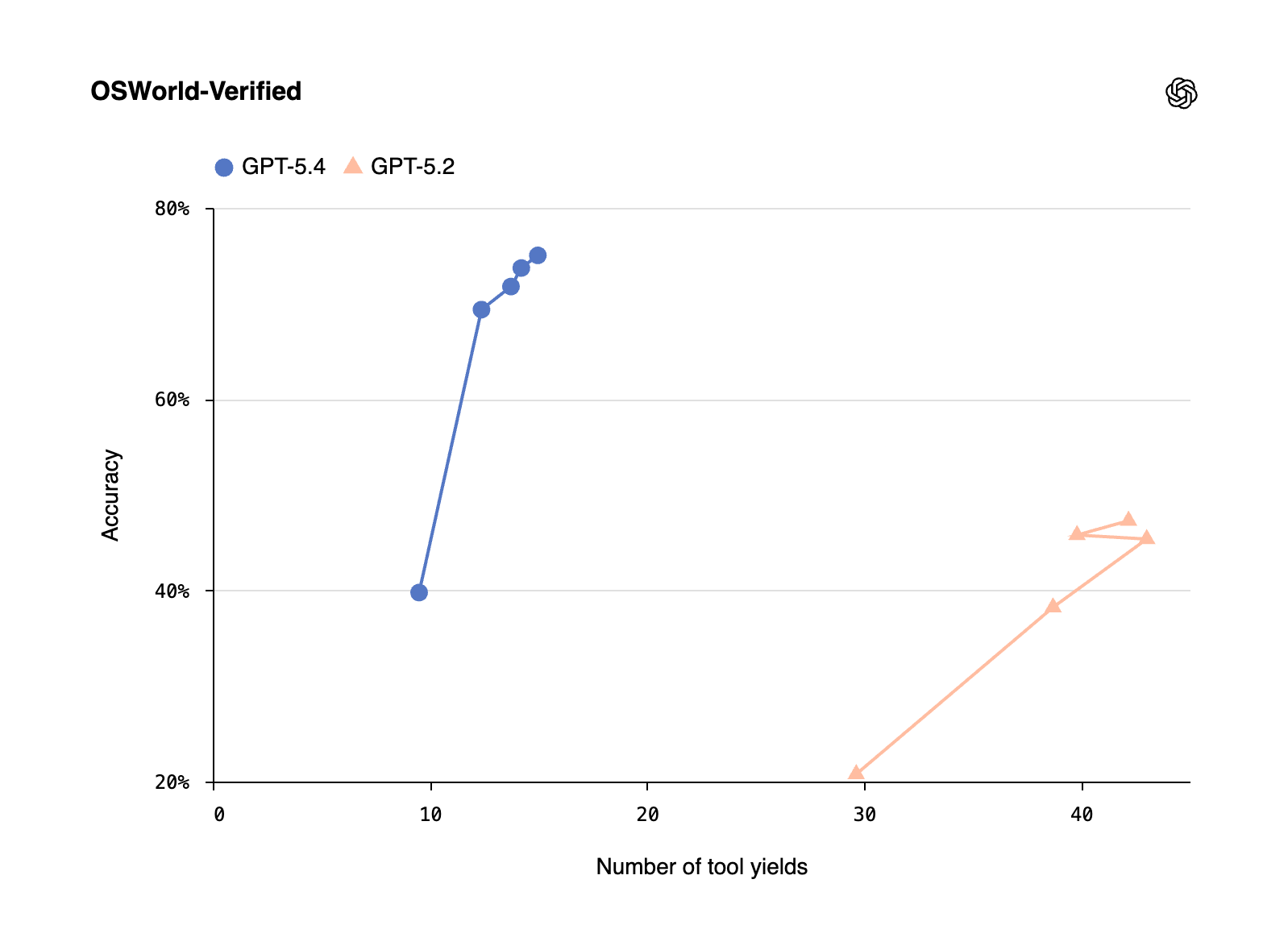
OpenAI released GPT-5.4, with improved reasoning, coding, and professional knowledge capabilities, enabling the development of more dependable AI agents.
GPT-5.4 can perform hard tasks across documents, spreadsheets, presentations, and software tools, producing higher-quality outputs and helping teams complete workflows faster.
It is the first general-purpose model with native, state-of-the-art computer-use capabilities.
It supports up to 1M tokens of context, allowing agents to plan, execute, and verify tasks across long horizons.
It is available across ChatGPT, the OpenAI API, and Codex, with variants such as GPT-5.4 Thinking for deeper reasoning and GPT-5.4 Pro for more demanding workloads.
Read more about this release using this link.
🚨 A Special Offer
Grab a 25% discount on the annual subscription to the newsletter and get access to articles like these, and so much more:
2. FlashAttention-4
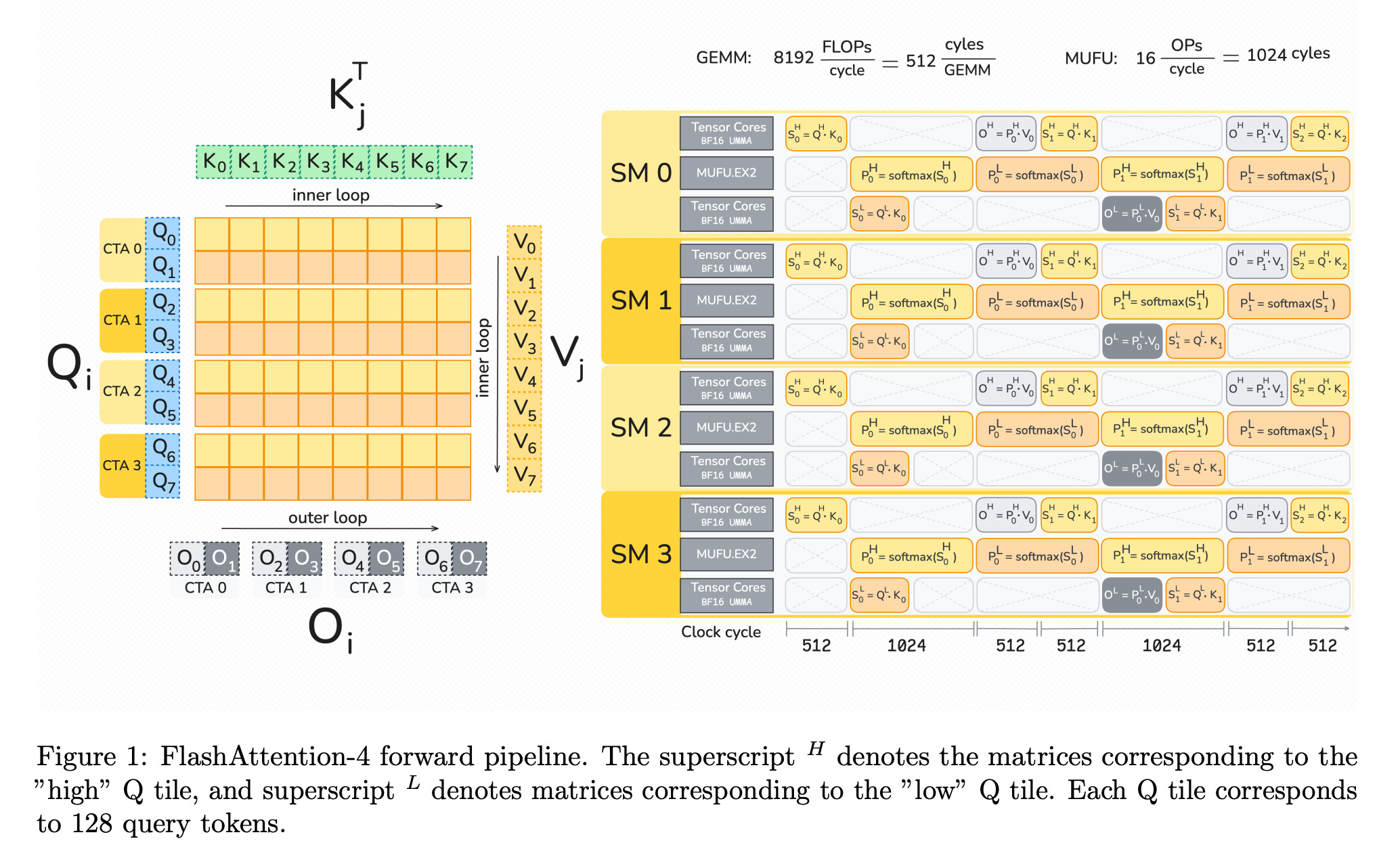
This research paper introduces the latest version, FlashAttention-4, which makes transformer attention faster and more efficient on modern GPUs.
FlashAttention-3 was optimized attention for Hopper GPUs, specifically targeting the H100 architecture. But the industry has moved to Blackwell-based systems such as the B200 and GB200, which come with fundamentally different performance characteristics.
FlashAttention-4 optimizes attention on Blackwell GPUs by:
Redesigning pipelines that take advantage of fully asynchronous Matrix Multiply-Accumulate (MMA) operations and larger tile sizes
Software-based implementations of exponential and conditional softmax rescaling, which reduce the number of non-matrix operations and improve overall speed
Better use of GPU tensor memory and the 2-CTA MMA mode (which allows two Cooperative Thread Arrays to jointly execute a single Matrix Multiply-Accumulate operation), which reduces shared-memory traffic and atomic adds required during the backward pass
FlashAttention-4 achieves up to:
a 1.3× speedup over cuDNN 9.13
a 2.7× speedup over Triton on B200 GPUs with BF16, reaching up to 1613 TFLOPs/s (71% utilization)
The researchers also implement FlashAttention-4 entirely in CuTe-DSL embedded in Python, resulting in 20-30× faster compile times compared to traditional C++ template-based approaches while maintaining full expressivity.
Read more about this research using this link.
3. Solving an Open Problem in Theoretical Physics using AI-Assisted Discovery
This research paper describes a neuro-symbolic system that autonomously solved an open problem in theoretical physics.
This system combines Gemini Deep Think with a systematic Tree Search (TS) algorithm and an automated numerical feedback system to explore mathematical ideas and verify them computationally.
The system successfully derived new and exact analytical solutions for the power spectrum of gravitational radiation emitted by cosmic strings.

Read more about this research using this link.
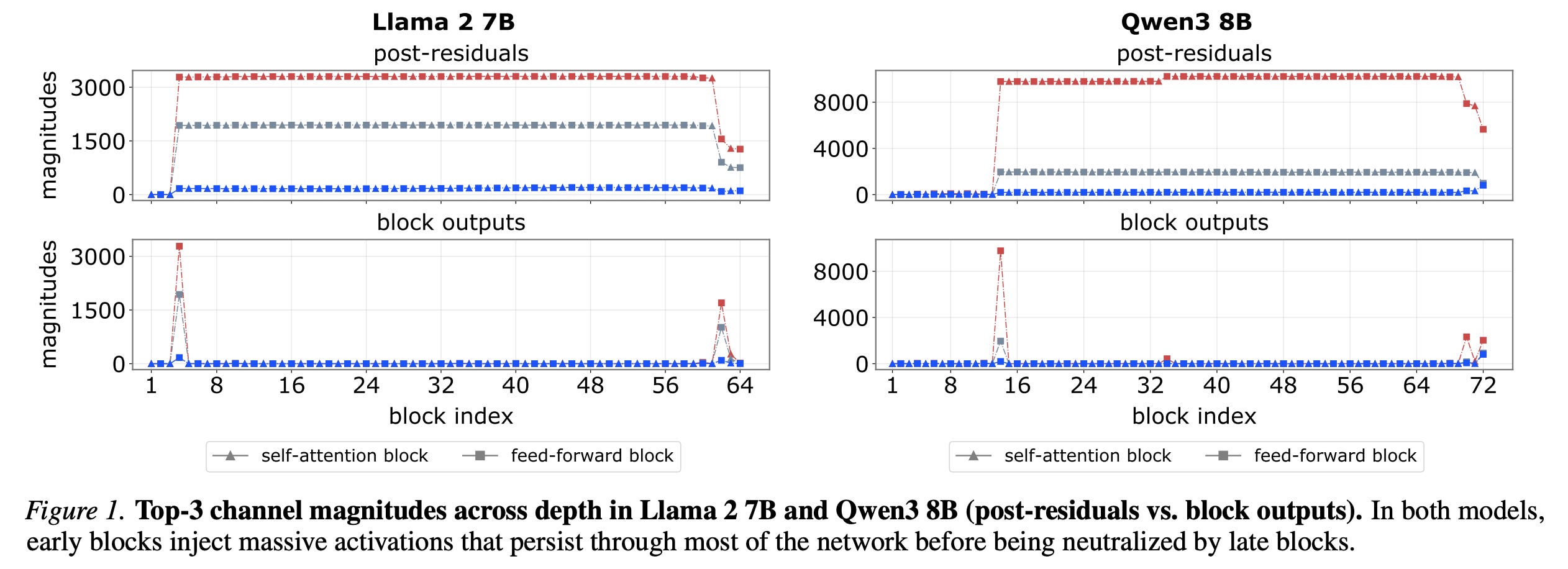
4. The Spike, the Sparse, and the Sink
This research paper studies two phenomena that usually co-occur and often involve the same tokens in Transformer-based LLMs:
Massive activations: where some tokens produce extremely large activations (“Spikes”)
Attention sinks: where some tokens consistently attract attention disproportionate to their semantic importance (“Sinks”)
Experiments show that:
The co-occurrence of the two is an architectural artifact of modern Transformer design.
Massive activations work globally to create nearly constant hidden representations that persist across many layers, effectively acting like implicit parameters of the model.
Attention sinks work locally by influencing attention outputs across heads, pushing individual heads to focus more on short-range dependencies.
Pre-norm is the main architectural choice that allows these two phenomena to appear together, and removing pre-norm causes them to decouple.
Read more about this research using this link.
5. Speculative Speculative Decoding
Speculative decoding has become a standard way to accelerate autoregressive inference in LLMs.
It uses a fast draft model to predict upcoming tokens from a slower, larger target model, and then verifies them in parallel with a single forward pass of the target model.
However, the method is still partly sequential because the draft must wait for verification before making the next speculation.
This research paper introduces Speculative speculative decoding (SSD), which parallelizes the speculation and verification operations.
While verification is ongoing, the draft model predicts likely verification outcomes and prepares pre-emptive speculations for them. If the actual verification outcome is then in the predicted set, a speculation is returned immediately, removing drafting delays entirely.
This method is further improved, leading to Saguaro, an optimized SSD algorithm that is up to 5x faster than autoregressive decoding on open-source inference engines.
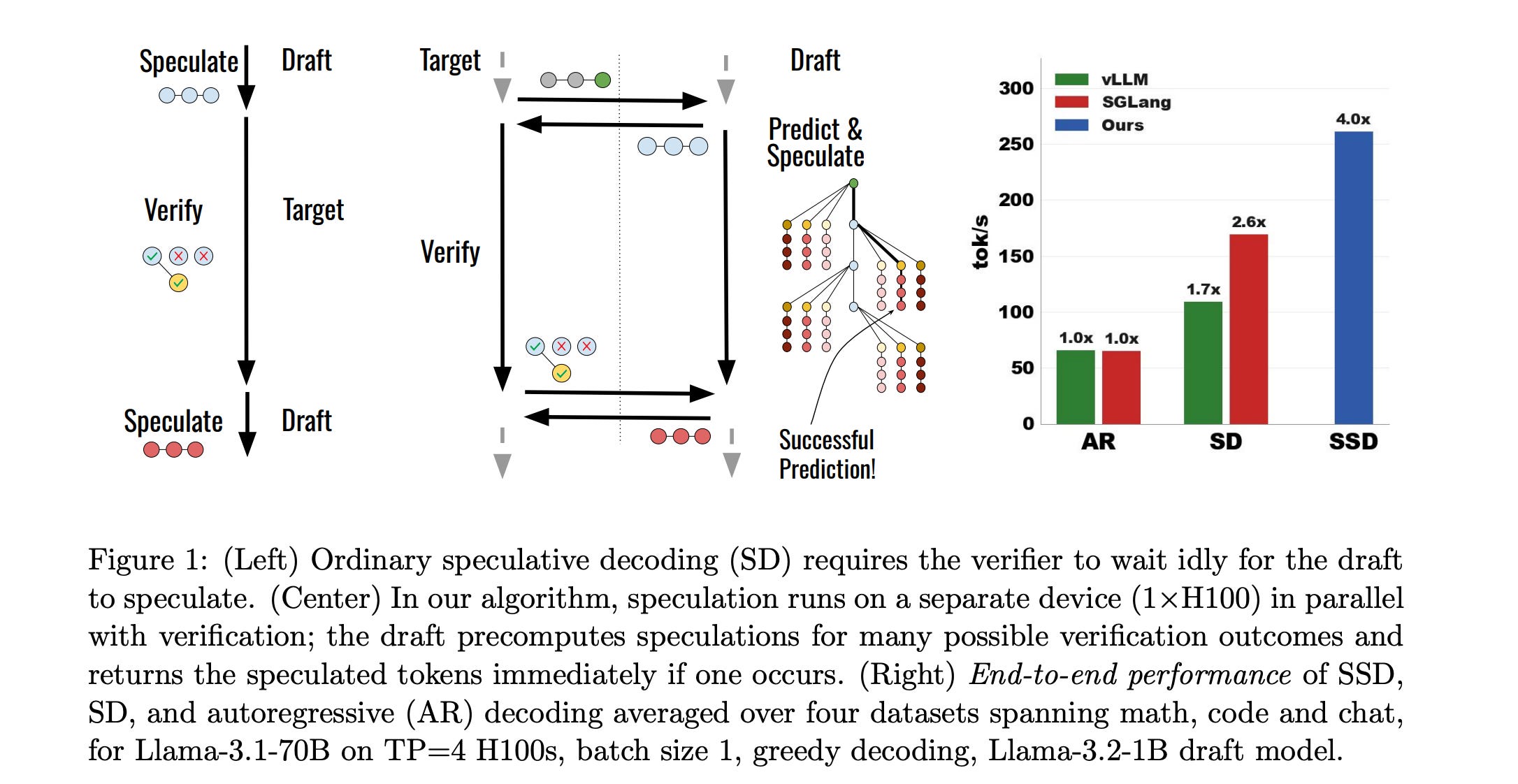
Read more about this research using this link.
6. Olmo Hybrid
Hybrid LLMs use an architecture that combines transformer attention and linear RNN layers.
Despite previous releases such as Nemotron-H, Qwen3-Next, Kimi Linear, and Qwen 3.5, it was unclear if the purported benefits of hybrid architectures justify the cost of scaling them up.
This debate has been settled by Ai2 researchers, who released the fully open-source Olmo Hybrid, a 7B-parameter model largely comparable to Olmo 3 7B, but with its sliding-window layers replaced by Gated DeltaNet layers.
Olmo Hybrid is trained using 49% fewer training tokens and outperforms Olmo 3 across standard pre-training and mid-training evaluations.
This is empirical proof that hybrid architectures not only reduce memory usage during inference but also obtain more expressive models that scale better during pretraining.
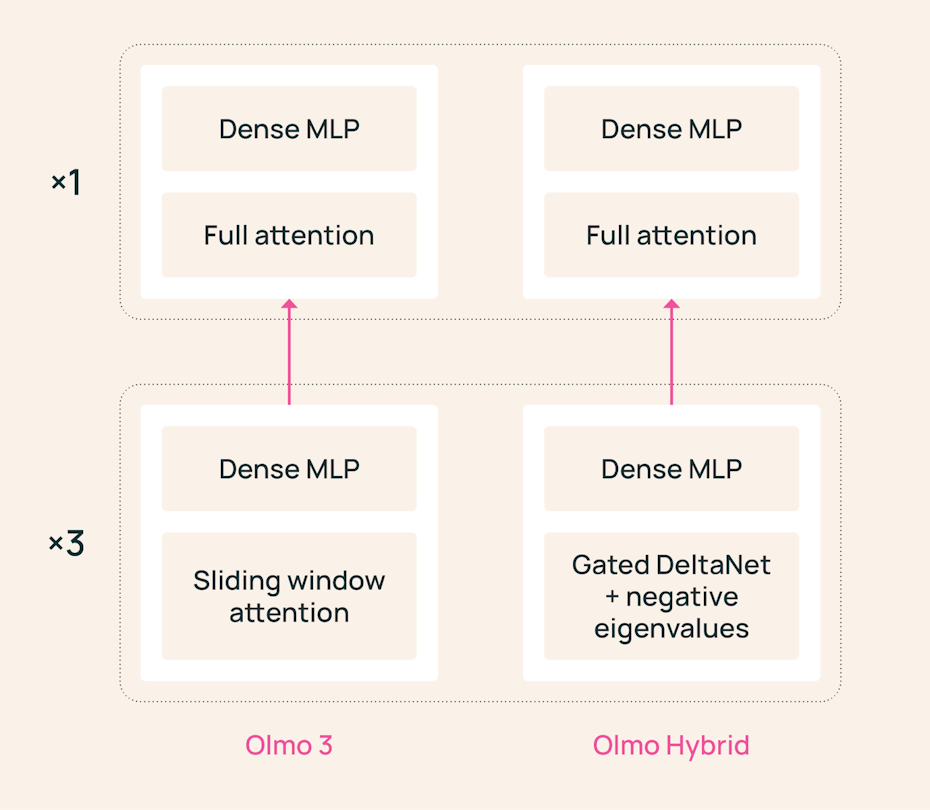
Read more about this research using this link.
7. Reasoning Models Struggle to Control their Chains of Thought
Chain-of-thought (CoT) monitoring is a promising method for understanding the intents and finding misbehaviors in modern reasoning LLMs.
This research paper examines whether CoT monitoring is a reliable safety tool or whether reasoning models can control what they reveal in their chain-of-thought (CoT), a phenomenon known as CoT controllability.
For this, the researchers introduce an evaluation suite called CoT-Control, which includes tasks that require reasoning models to solve problems while adhering to CoT instructions. (For example, reasoning about a genetics question without using the word “chromosome”.)
Experiments show that:
Reasoning models have significantly lower CoT controllability than output controllability. For example, Claude Sonnet 4.5 can control its CoT only 2.7% of the time, but 61.9% of the time when controlling its final output.
CoT controllability is higher for larger models and decreases with more RL training, test-time compute, and increased problem difficulty.
CoT controllability failures extend even to situations in which models are given incentives (as opposed to direct requests) to evade CoT monitors
Models exhibit slightly higher controllability when they are told they are being monitored.
Eliciting controllability by adversarially optimizing prompts does not meaningfully increase controllability.
The overall results indicate that CoT controllability is currently unlikely to be a failure mode of CoT monitorability and must be tracked by frontier labs in future models.
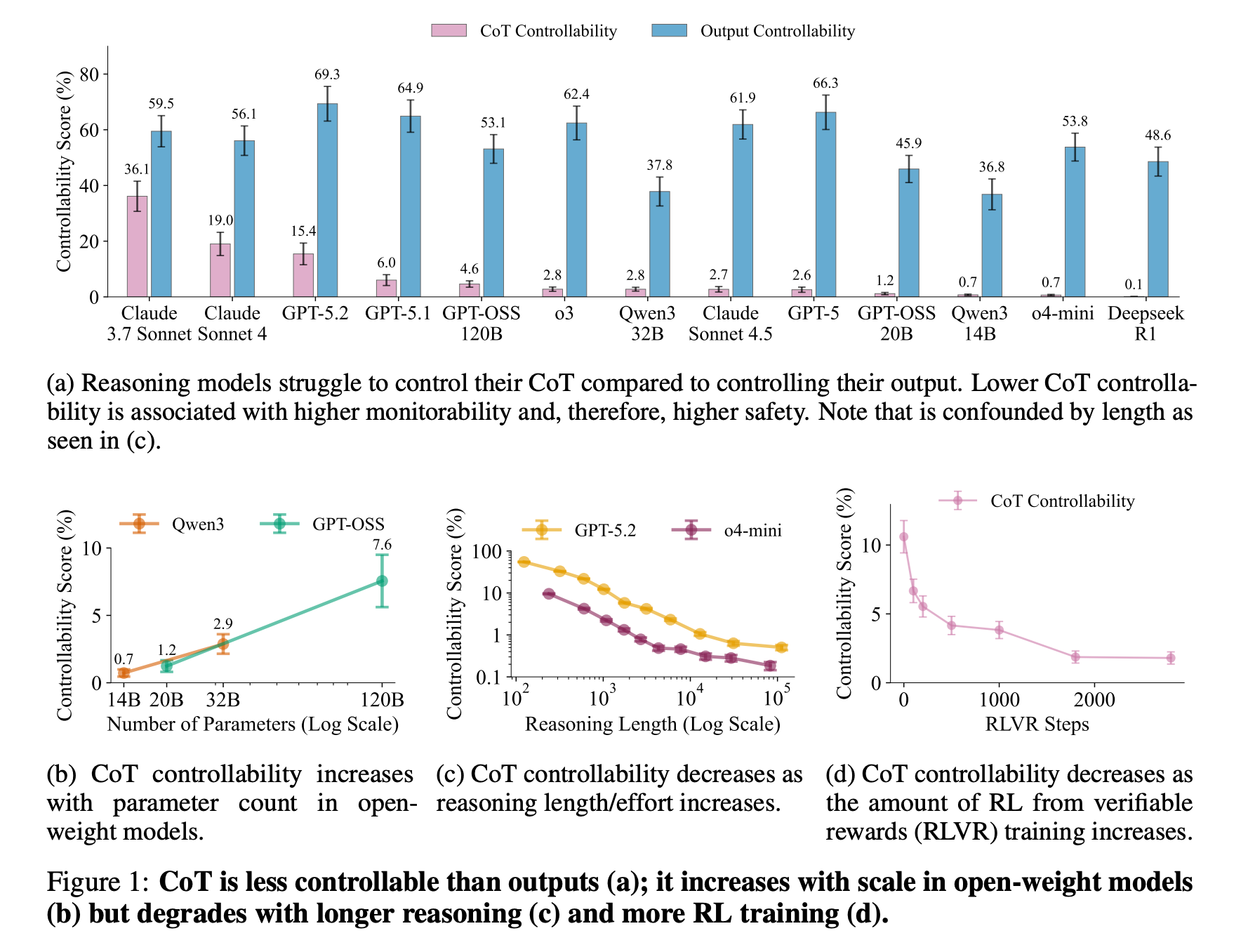
Read more about this research using this link.
8. Phi-4-reasoning-vision-15B
This research paper from Microsoft introduces Phi-4-reasoning-vision-15B, a 15B-parameter multimodal reasoning model that can process both text and images.
The model combines the Phi-4-Reasoning backbone with a SigLIP-2 vision encoder in a mid-fusion architecture that converts images into visual tokens for reasoning.
It performs efficient multimodal reasoning across tasks such as math, science, OCR, document understanding, and GUI interaction. This is made possible by the use of high-resolution visual encoder and by training the model on a mix of reasoning and non-reasoning data with explicit mode tokens. This setup allows the model to provide fast, direct answers for simple tasks and chain-of-thought reasoning for more complex ones.
The paper shows that the greatest performance improvements come from systematic data filtering, error correction, and the augmentation with synthetic data. This tells us that data quality is the main factor behind how well the model performs.
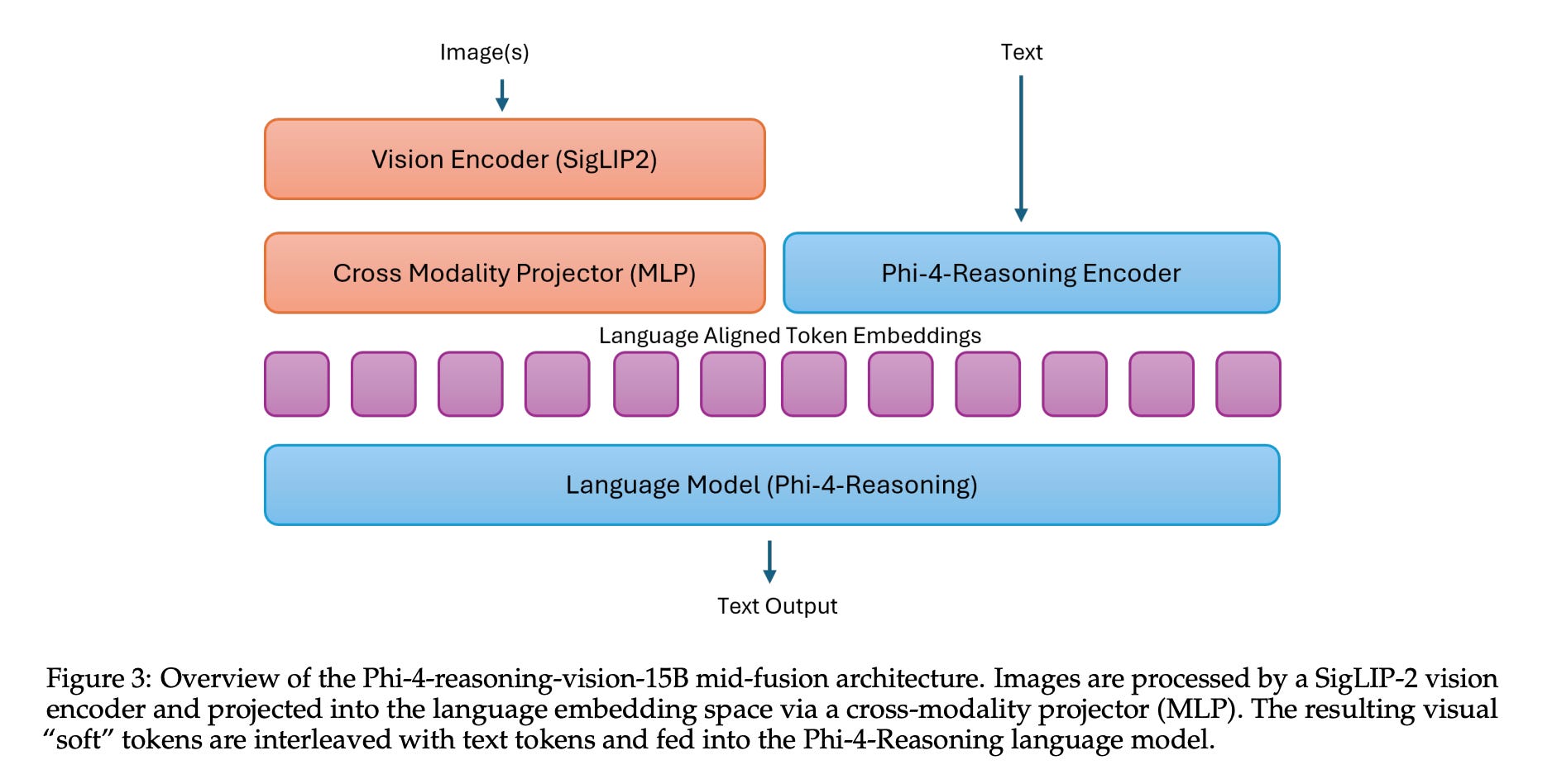
Read more about this research using this link.
9. Helios
This research paper presents Helios, the first 14B autoregressive diffusion model that can create high-quality minute-scale videos in real time at about 19.5 FPS on a single NVIDIA H100 GPU.
Helios also supports text-to-video, image-to-video, and video-to-video generation within a single framework, and extensive experiments show that it consistently outperforms prior methods on both short and long-video generation.

Read more about this research using this link.
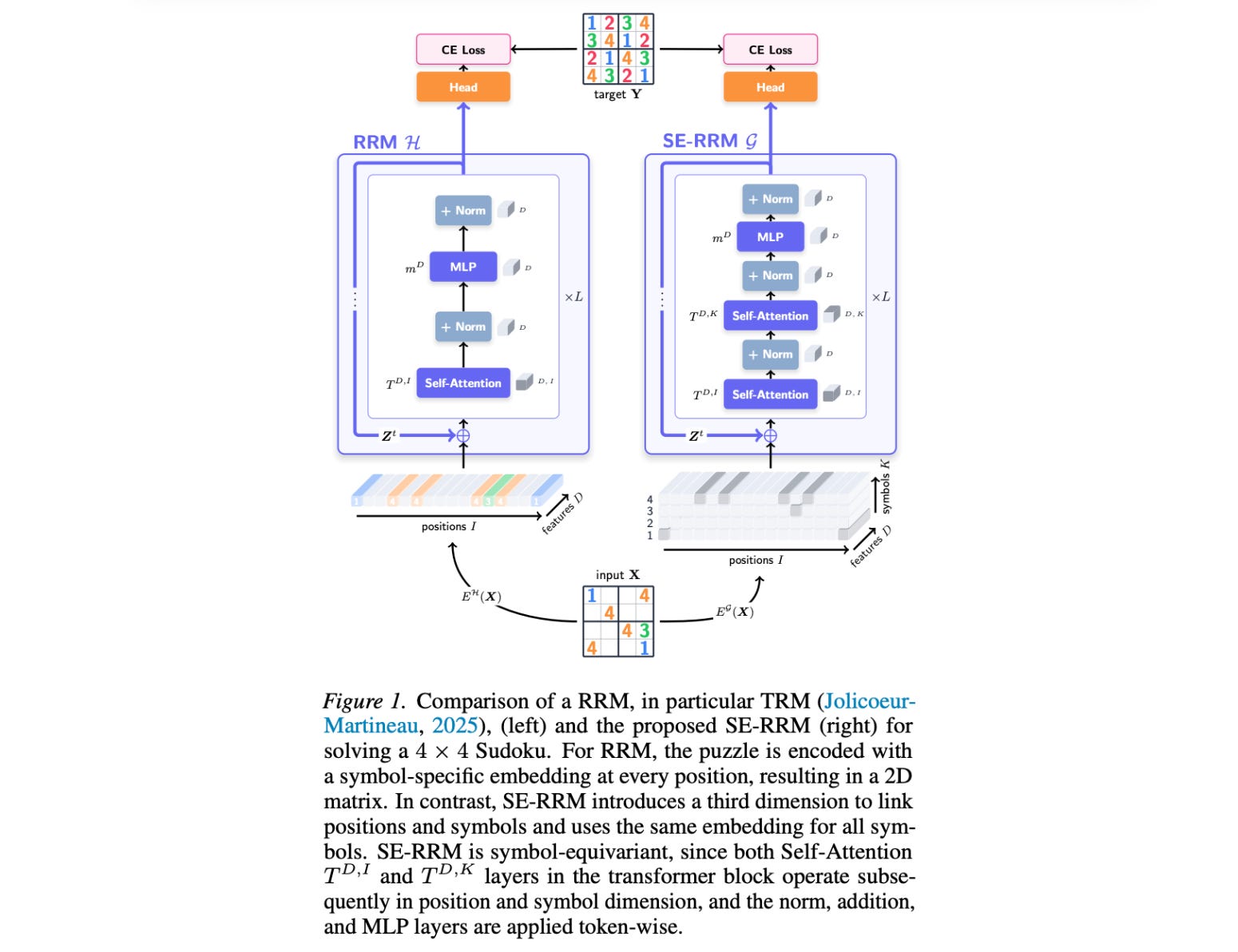
10. Symbol-Equivariant Recurrent Reasoning Models
This research paper introduces Symbol-Equivariant Recurrent Reasoning Models (SE-RRMs), a new addition to the family of Recurrent Reasoning Models (RRMs).
SE-RRMs extend Recurrent Reasoning Models by explicitly encoding symbol-permutation symmetry in the architecture using symbol-equivariant layers.
This change ensures that the model provides the same solution even when symbols, such as numbers or colors, are permuted. This reduces the need for extensive data augmentation and improves generalization.
Experiments show that SE-RRMs outperform previous RRM models on Sudoku and can adapt to different Sudoku grid sizes, which existing RRMs cannot.
SE-RRMs also achieve competitive performance on ARC-AGI-1 and ARC-AGI-2 with substantially less data augmentation and only 2M parameters.
Read more about this research using this link.
Read more about the previous RRMs using the following links:



This article is entirely free to read. If you loved reading it, restack and share it with others to earn referral rewards. ❤️
Don’t forget to become a paid subscriber at a 25% discount to access all valuable posts in the newsletter.
