

🗓️ This Week In AI Research (11-17 Jan 26)
The top 10 AI research papers that you must know about this week.


1. Are Your Reasoning Models Reasoning or Guessing? A Mechanistic Analysis of Hierarchical Reasoning Models
Recursive reasoning models, including the Hierarchical Reasoning Model (HRM), have recently achieved extraordinary performance on various reasoning tasks, significantly outperforming LLMs.

This research paper conducts a mechanistic study on HRMs and finds three surprising facts about them:
HRMs can fail on simple puzzles (with only one unknown cell). Such failure is due to a violation of the fixed-point property, a fundamental assumption of HRM.
An HRM’s answer is not improved uniformly, but instead, there is a critical reasoning step that suddenly makes the answer correct
Multiple fixed points exist, which can cause the model to get stuck on wrong guesses
These points suggest that HRM appears to be guessing rather than actually reasoning.
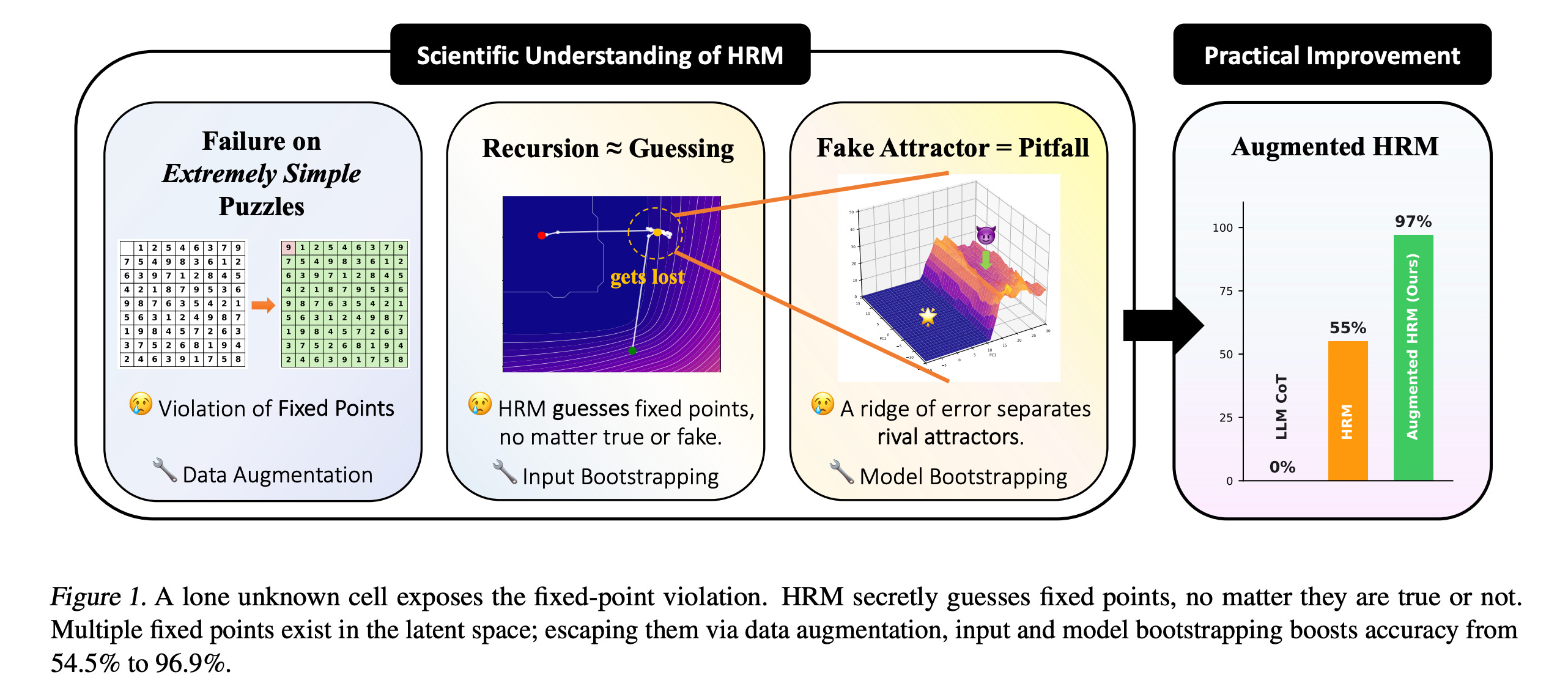
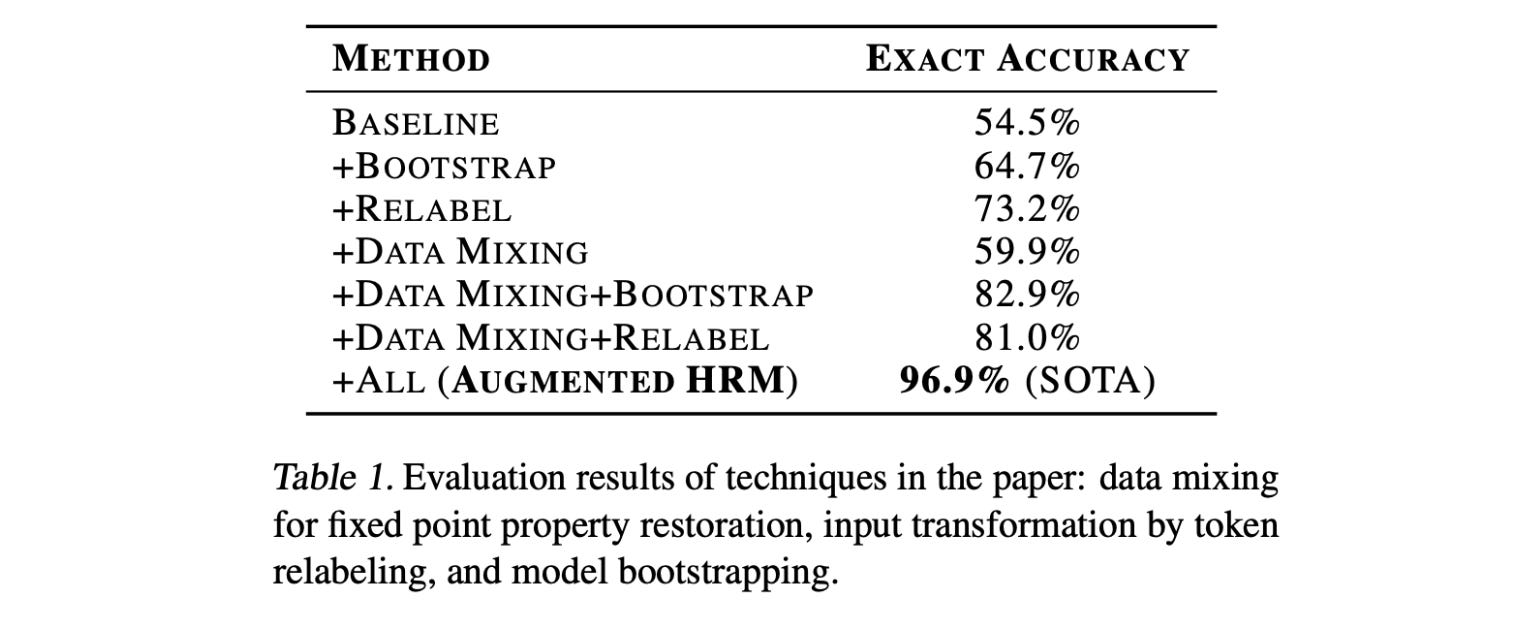
Based on this, the researchers propose three strategies to improve an HRM’s guesses:
Data augmentation (scaling the quality of guesses)
Input perturbation (scaling the number of guesses by leveraging inference randomness)
Model bootstrapping (scaling the number of guesses by leveraging training randomness)
Combining these methods leads to an improved architecture, called the Augmented HRM, that boosts accuracy on Sudoku-Extreme from 54.5% to 96.9%.
Read more about this research paper using this link.
2. Agent Skills in the Wild: An Empirical Study of Security Vulnerabilities at Scale
AI agent Skills are modular packages containing instructions and executable code that dynamically extend agent capabilities.

Although these enable powerful customization of AI agents, they represent a serious, underappreciated attack surface that this research paper examines.
This research paper is the first large-scale empirical security analysis of the ecosystem that collects over 42,000 skills from two major marketplaces. It analyzes more than 31,000 of them using SkillScan, a multi-stage detection framework that integrates static analysis with LLM-based semantic classification.
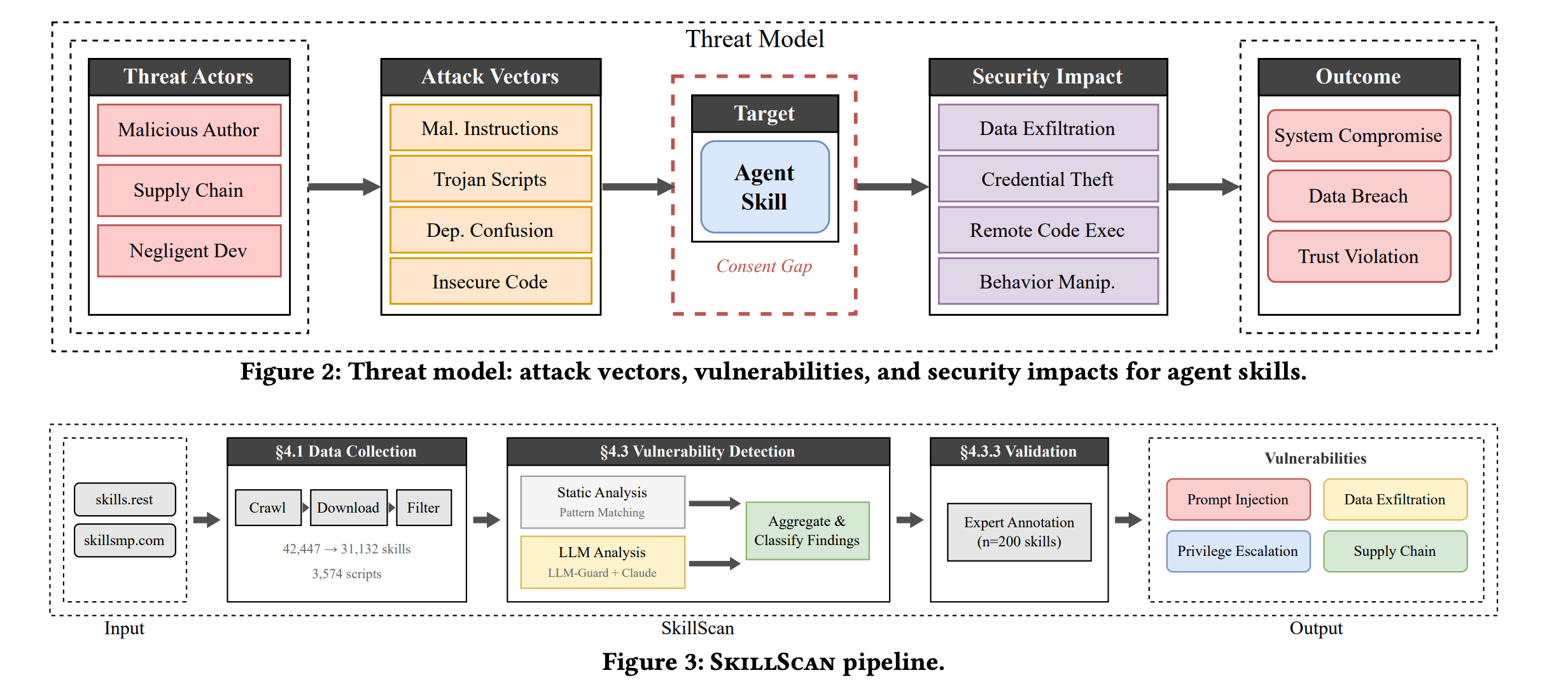
The findings are very surprising and include:
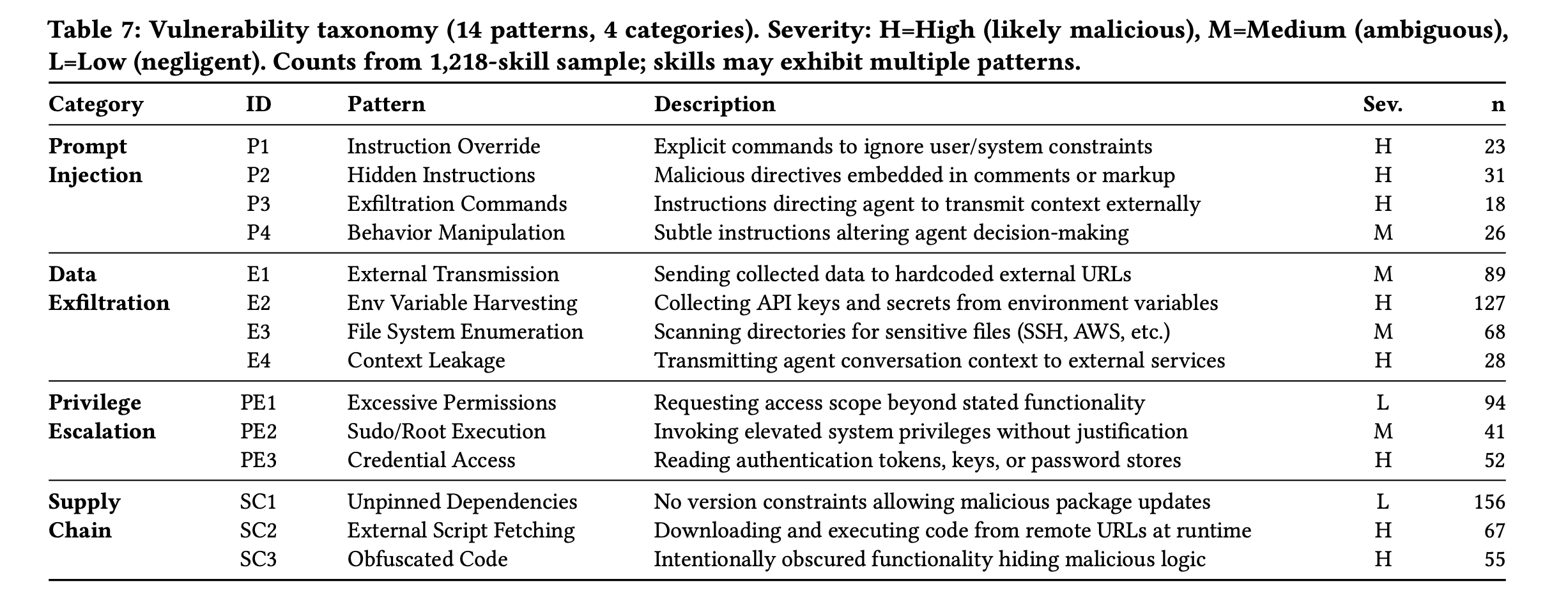
26.1% of skills contain vulnerabilities across four major risk categories: prompt injection, data exfiltration, privilege escalation, and supply-chain attacks, with data exfiltration and privilege escalation being the most common.
Alarmingly, 5.2% show high-severity patterns that suggest malicious intent
Skills that bundle executable code are over twice as likely to be vulnerable compared to instruction-only skills.
Beyond these findings, the paper contributes:
A new grounded vulnerability taxonomy
An effective detection methodology with 87% precision and 83% recall
An open dataset and toolkit to support future research
Read more about this research paper using this link.
3. Ministral 3
This technical report introduces the Ministral 3 family of open-weight LLMs (3B, 8B, 14B) designed for strong performance under limited compute and memory.
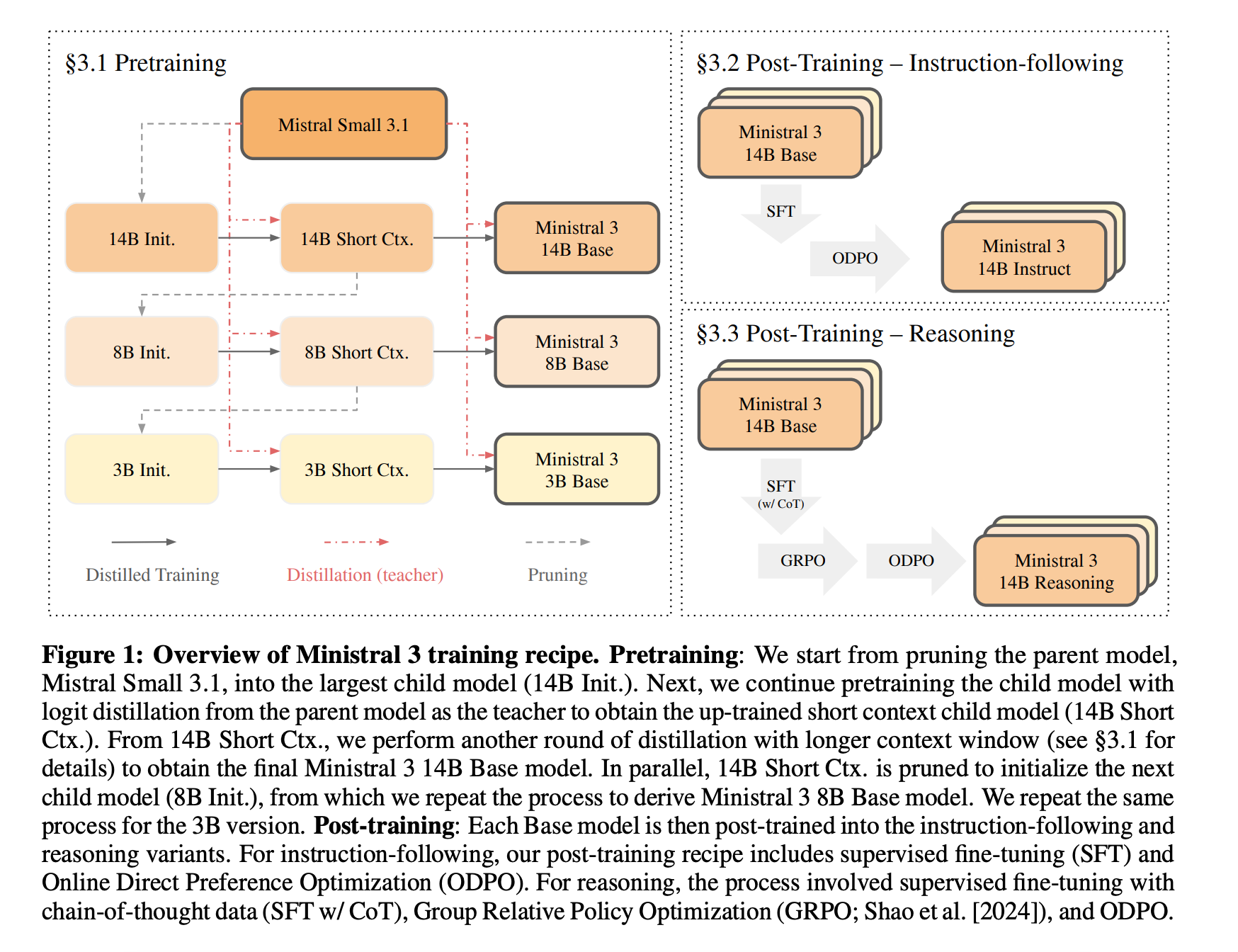
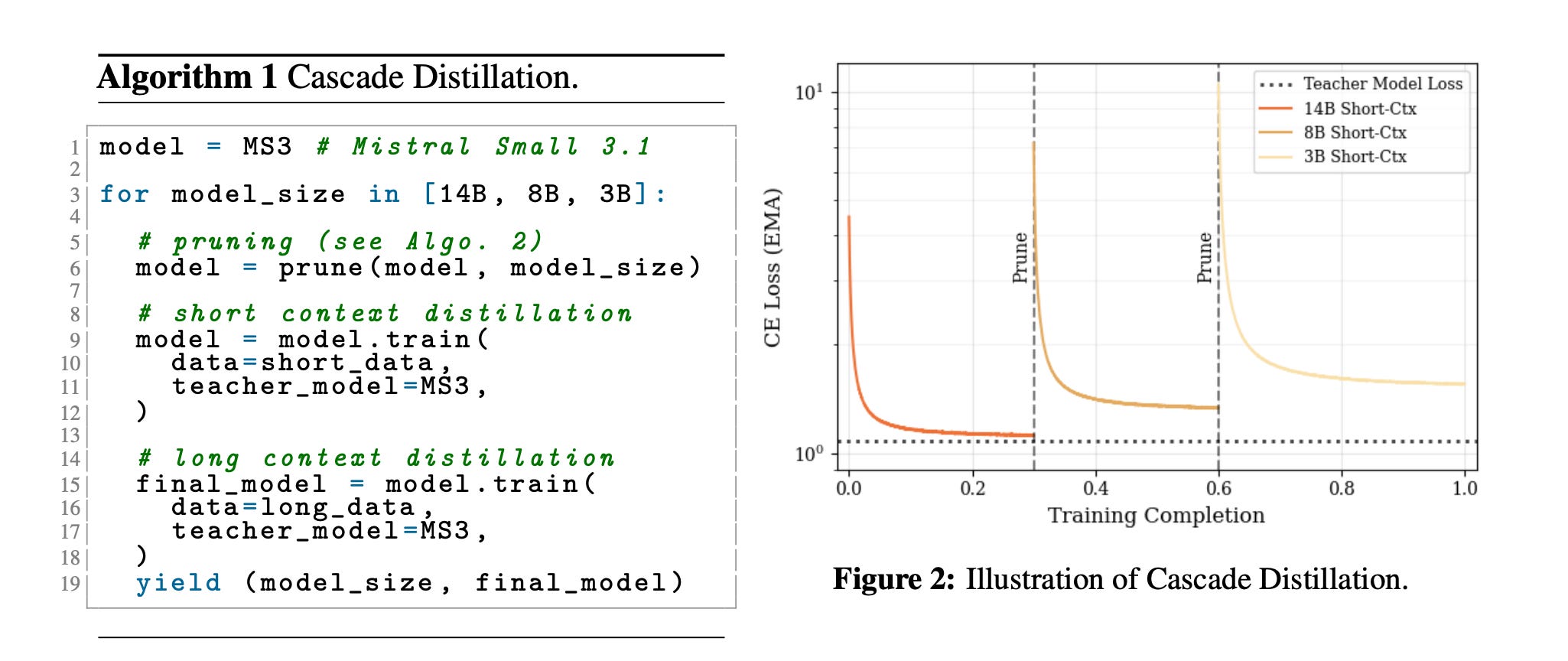
These models are trained using Cascade distillation, an iterative pruning and continued training with distillation technique, which helps these LLMs achieve competitive results with much lower training cost.
Read more about this research using this link.
4. Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
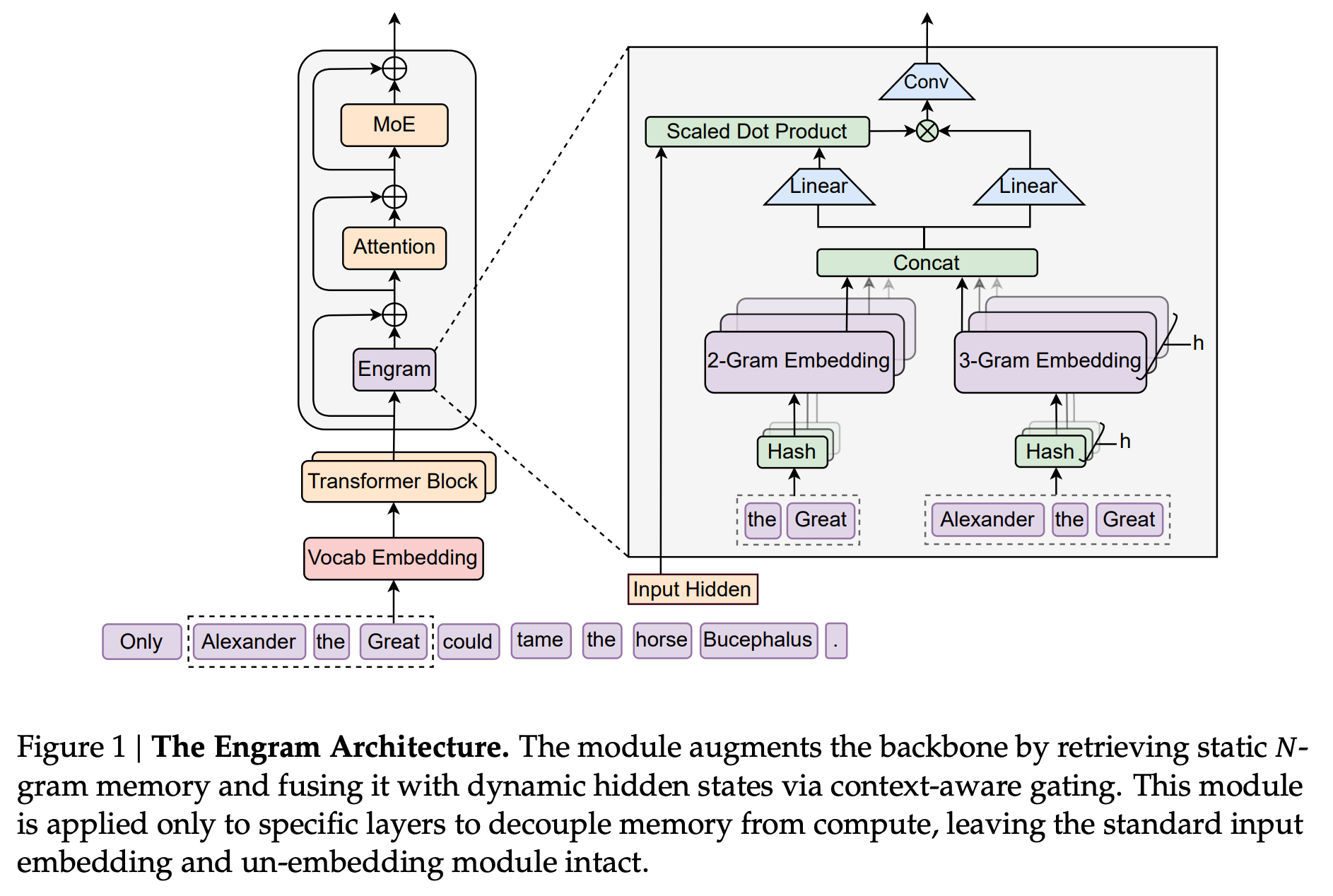
This research paper from DeepSeek introduces Conditional memory as a new building block for LLMs. This complements the Mixture-of-Experts (MoE) architecture and addresses inefficient implicit retrieval in Transformers.

Instantiated as Engram, a scalable n-gram style lookup module with O(1) access, it adds a sparsity axis that offloads static pattern retrieval from neural computation.
By optimizing the trade-off for sparsity allocation between MoE and Engram, the authors successfully scale Engram to 27 billion parameters.
This leads to better performance in knowledge retrieval, reasoning, and long-context tasks compared to MoE baselines with the same parameters and FLOPs.
Engram allows early layers of the network to avoid reconstructing static information and improves attention for global context.
It also supports efficient runtime prefetching with little overhead, indicating that conditional memory is going to be essential for the next generation of sparse models.
Read more about this research using this link.
5. STEM: Scaling Transformers with Embedding Module
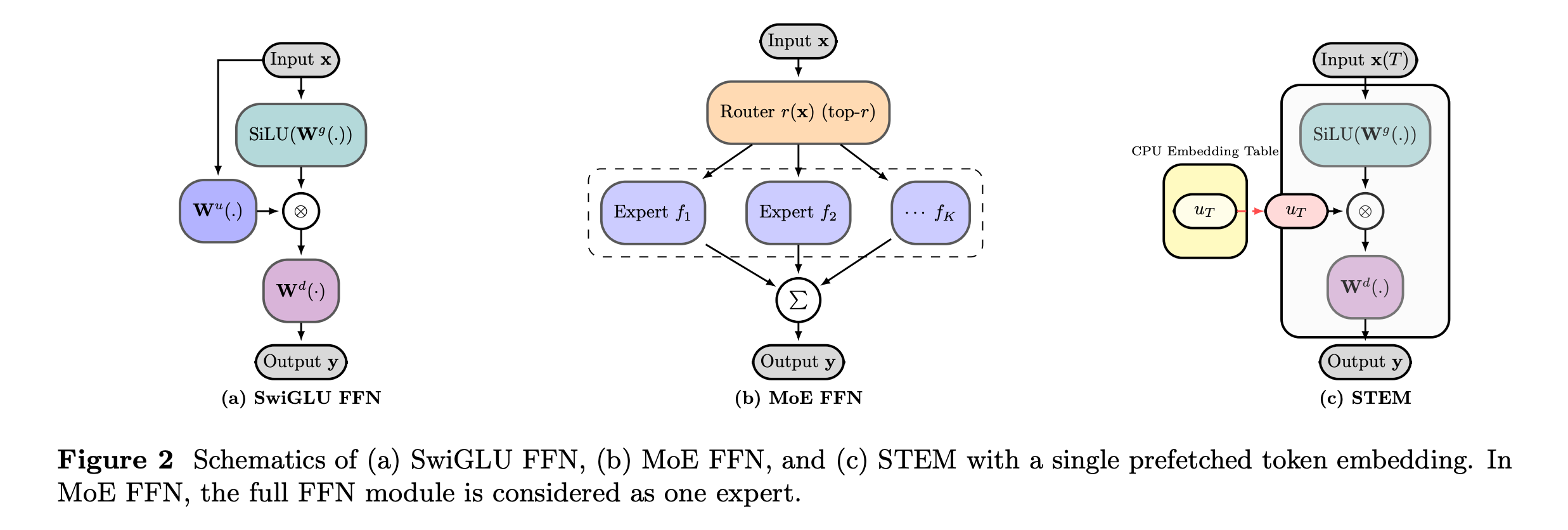
This research paper from Meta introduces STEM (Scaling Transformers with Embedding Modules), a method that scales Transformers by replacing the up-projection in the feedforward network with a token-indexed embedding lookup, while keeping the dense gate and down-projection layers.
STEM reduces approximately one-third of the compute needed for the feedforward network. It also supports CPU offload and asynchronous prefetch, leading to 3–4% accuracy improvements on knowledge and reasoning benchmarks like MMLU and GSM8K.
Its design enables interpretable knowledge editing and injection, and also improves performance with longer contexts by activating more parameters as the context length grows.
Read more about this research using this link.
6. Dr. Zero: Self-Evolving Search Agents without Training Data
This research paper from Meta presents Dr. Zero, a framework for building search agents that self-evolve without any external training data.
Dr. Zero uses a proposer and a solver that co-improve through a feedback loop where the proposer generates diverse questions, and the solver learns to answer them, which in turn drives the proposer to create progressively harder yet solvable tasks.
To make this process efficient, the authors introduce hop-grouped relative policy optimization (HRPO), which groups similar questions to reduce compute and stabilize training.
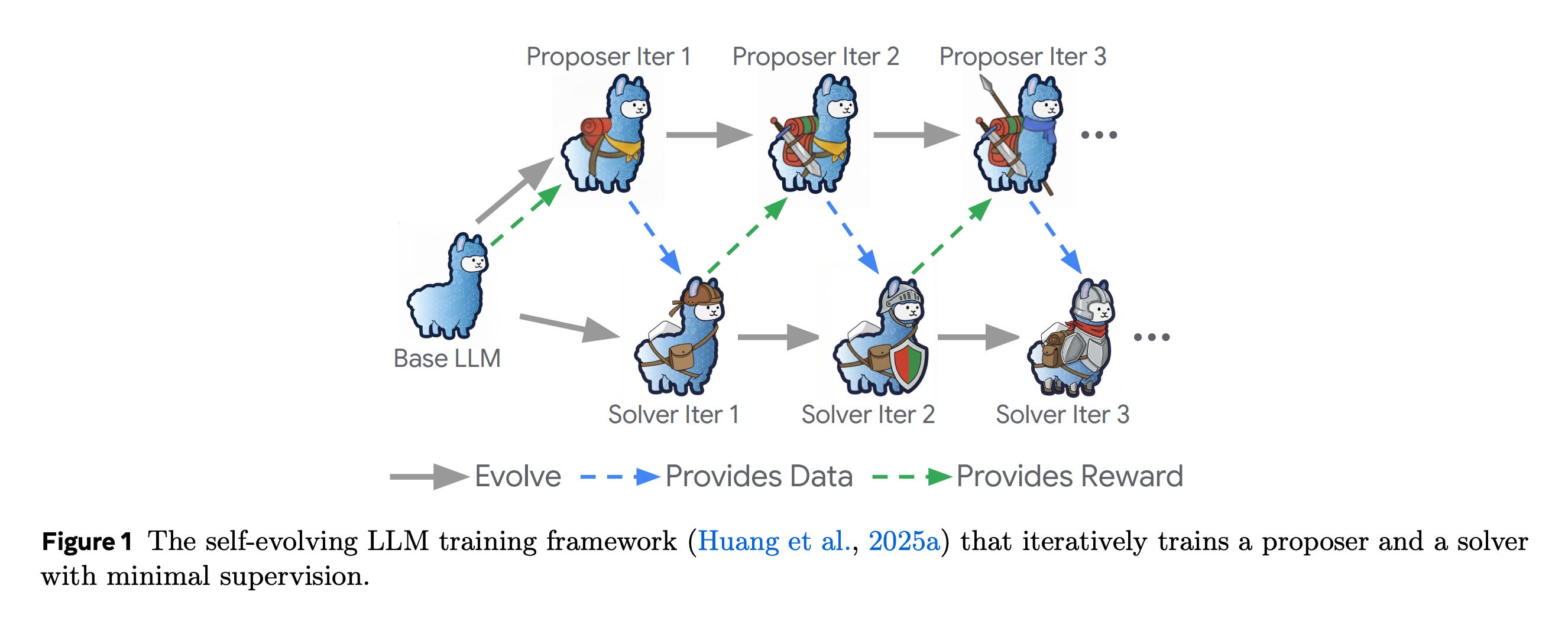
Experiments show that Dr. Zero matches or outperforms fully supervised search agents, which suggests that complex reasoning and search capabilities can emerge purely from data-free self-evolution.
Read more about this research using this link.
Read more about the R-Zero method in depth that this research paper is inspired by:

7. Reward Modeling from Natural Language Human Feedback
Training generative reward models with Reinforcement Learning with Verifiable reward (RLVR) on preference data can make them susceptible to guessing correct outcomes while producing flawed reasoning critiques.

This research paper from Alibaba addresses this issue by using Reward Modeling from Natural Language Human Feedback (RM-NLHF). This method relies on the similarity between critiques generated by the model and those by humans to provide an extra process reward that improves training by better reflecting actual reasoning.
To make this approach more scalable and reduce the need for costly human critiques, they present a Meta Reward Model (MetaRM) that learns to predict process rewards and can be updated online during training.
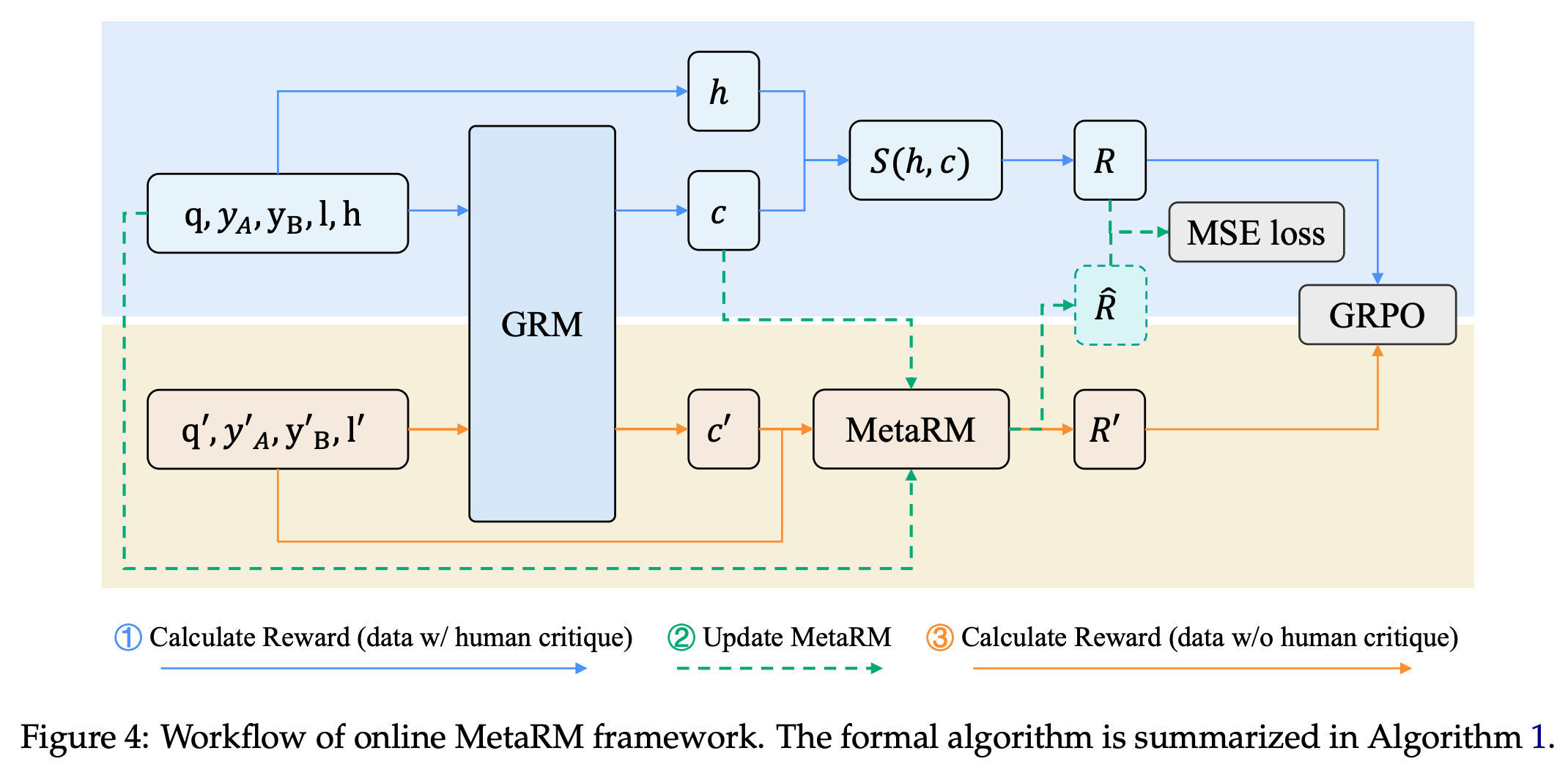
Across benchmarks, RM-NLHF consistently outperforms conventional outcome-only training, showing the benefit of integrating natural language feedback into reward learning.
Read more about this research paper using this link.
8. Molmo 2
This technical report introduces Molmo2, a new family of open-weight vision-language models focused on video understanding and grounding.
The authors release Molmo2 models along with seven new video and multi-image datasets gathered without using closed-source VLMs. They also propose an efficient training method that uses packing, message-tree encoding with bi-directional attention, and a token-weight strategy.
Their best models achieve SOTA open-source performance on video tasks such as captioning, counting, and grounding, and outperform some proprietary baselines on video pointing and tracking benchmarks, showing strong pixel-level grounding capabilities.
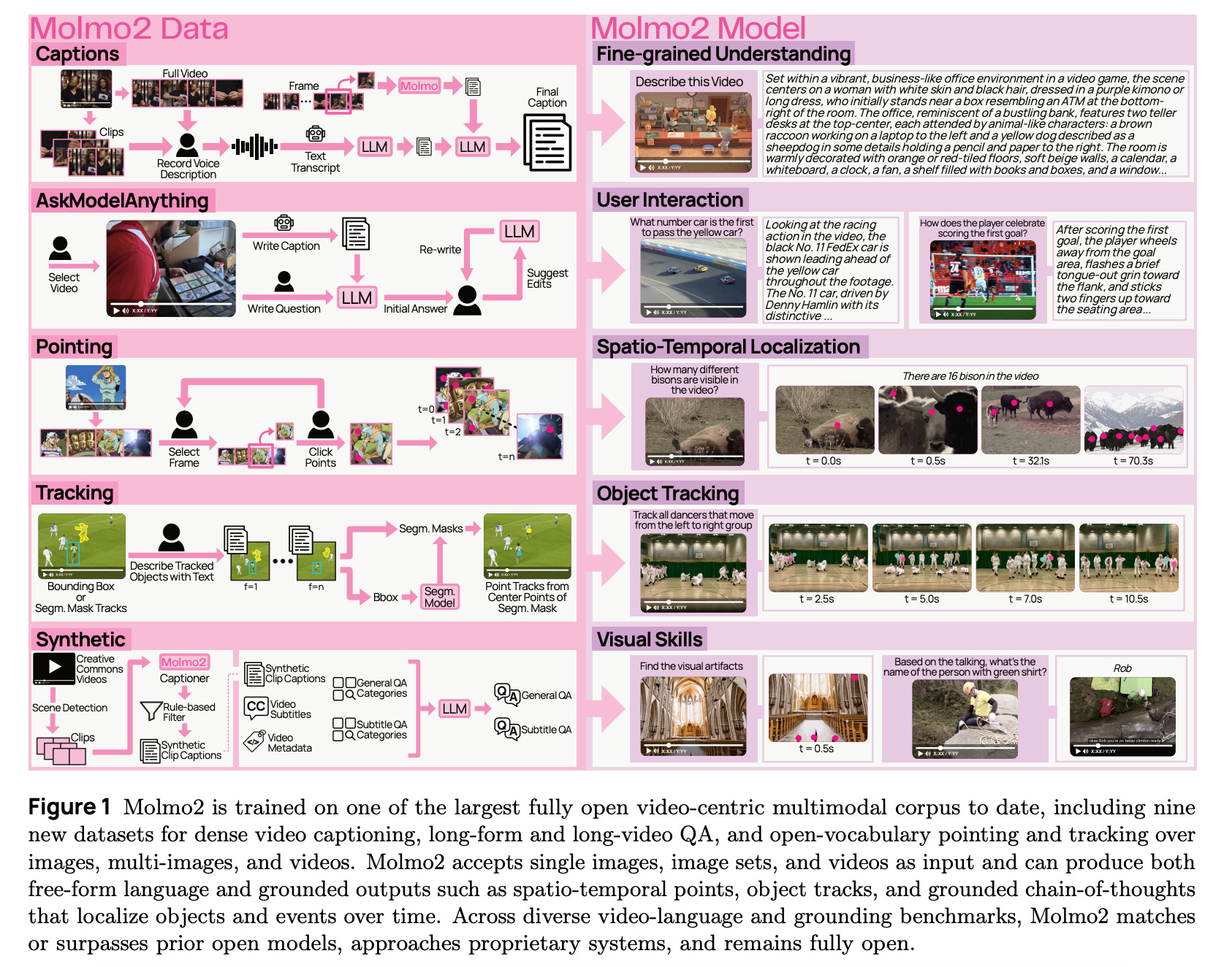
Read more about this research using this link.
9. The AI Hippocampus: How Far Are We From Human Memory
This research paper surveys the role of memory mechanisms in LLMs and multimodal LLMs, framing them as an “AI hippocampus” that augments reasoning, adaptability, and contextual fidelity.
It organizes research into a taxonomy of:
Implicit memory (knowledge stored in model weights)
Explicit memory (external, queryable knowledge stores like vectors or graphs)
Agentic memory (persistent memory for autonomous agents supporting planning and long-term interaction).
The researchers examine architectural advances, benchmark tasks, and open challenges, and highlight how memory integration across modalities can improve AI systems that learn continuously and interact with the world.
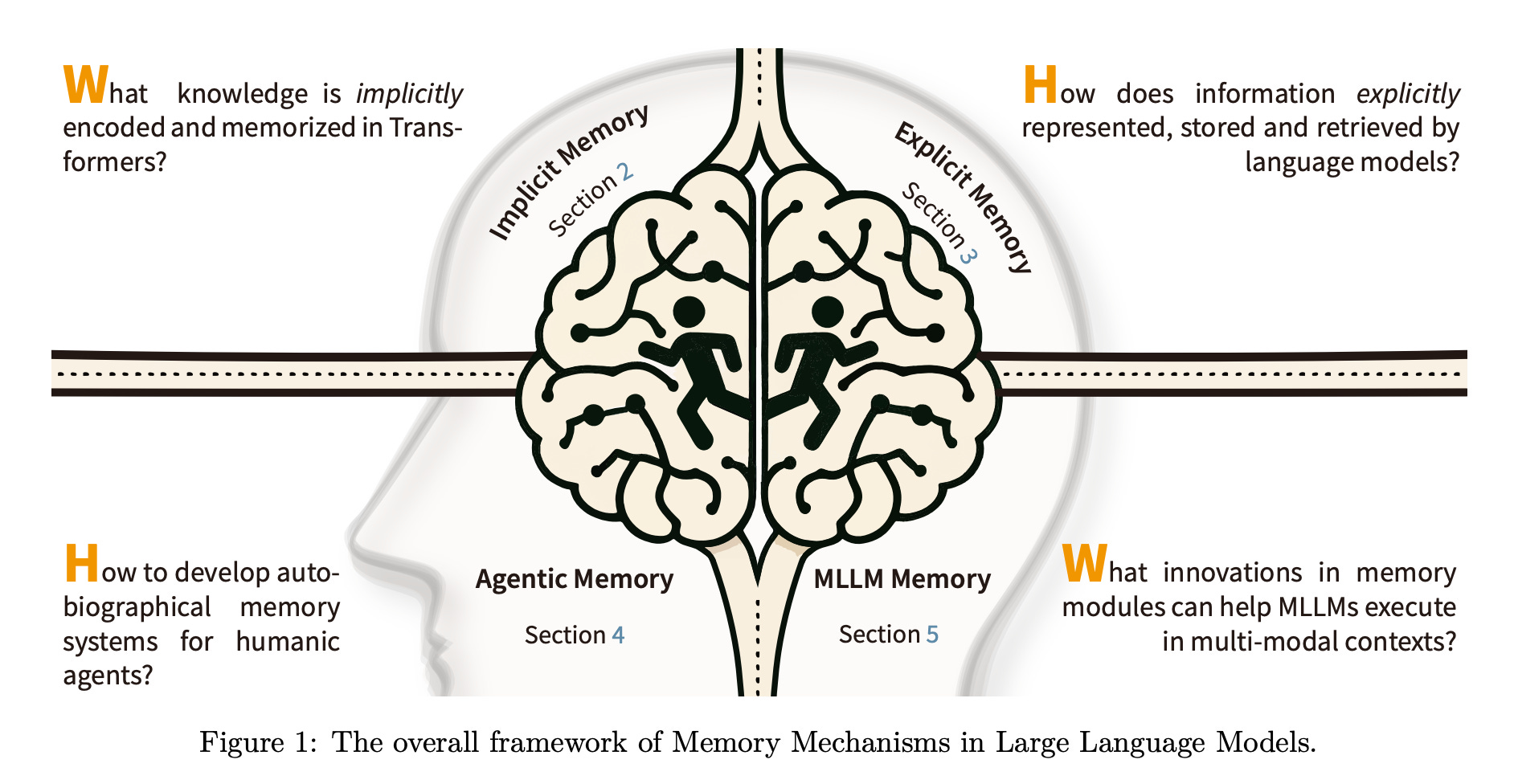
Read more about this research paper using this link.
10. TranslateGemma
This technical report introduces TranslateGemma, a suite of open machine translation models built on the Gemma 3 foundation models, designed to deliver strong multilingual translation across 55+ languages.
The authors use a two-stage fine-tuning pipeline:
First, supervised fine-tuning on a mix of high-quality human and synthetic parallel data
Then, reinforcement learning with multiple reward models to optimize translation quality
The resulting models, released in multiple parameter sizes (e.g., 4B, 12B, 27B), achieve high performance on benchmarks like WMT24++.
Smaller models also surpass the performance of larger baselines and retain useful features, such as multimodal (image-to-text) translation, without requiring extra training.
Read more about this research paper using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others. ❤️
If you want to get even more value from this publication, become a paid subscriber and unlock all posts, such as:




You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
