

🗓️ This Week In AI Research (15-21 March 26)
The top 10 AI research papers that you must know about this week.


1. Mixture-of-Depths Attention
As LLMs become deeper, they often suffer from signal degradation. This means that important features formed in shallow layers are gradually diluted by repeated residual updates, making them harder to recover in deeper layers.
This research paper introduces the Mixture-of-depths attention (MoDA), which allows each attention head to attend to sequence KV pairs at the current layer and to depth KV pairs from preceding layers.
The authors also describe a hardware-efficient algorithm for MoDA that resolves non-contiguous memory-access patterns, achieving 97.3% of FlashAttention-2’s efficiency at a sequence length of 64K.
Experiments on 1.5B-parameter models show that MoDA consistently outperforms strong baselines, and combining MoDA with post-norm yields better performance than using it with pre-norm.
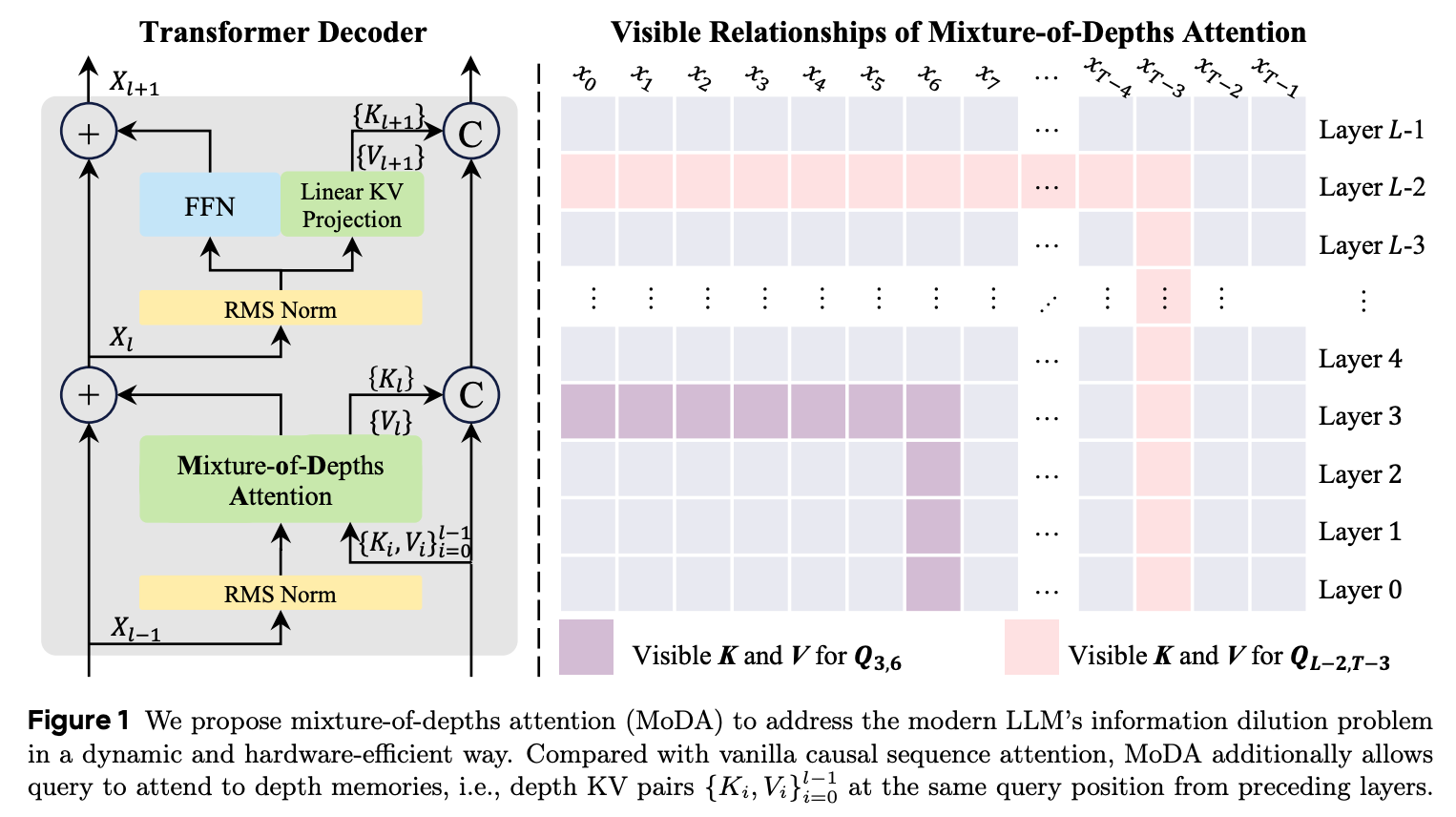
Read more about this research paper using this link.
🎁 Join the paid tier today to get access to all posts on this newsletter.



and so many more!
2. Attention Residuals
This research paper proposes Attention Residuals (AttnRes), an alternative to standard residual connections in transformers.
Typically, models add all outputs from previous layers equally, which can dilute valuable information as the model deepens. AttnRes instead allows each layer to use attention to selectively merge earlier layers, assigning learned, input-dependent weights to focus on the most relevant past information.
To increase efficiency, Block AttnRes groups layers into blocks and attends to summaries of these blocks rather than every layer, reducing memory costs while preserving most benefits of full AttnRes.
Overall, this enhances training stability, maintains stronger signals across depth, and improves performance, particularly in large models.
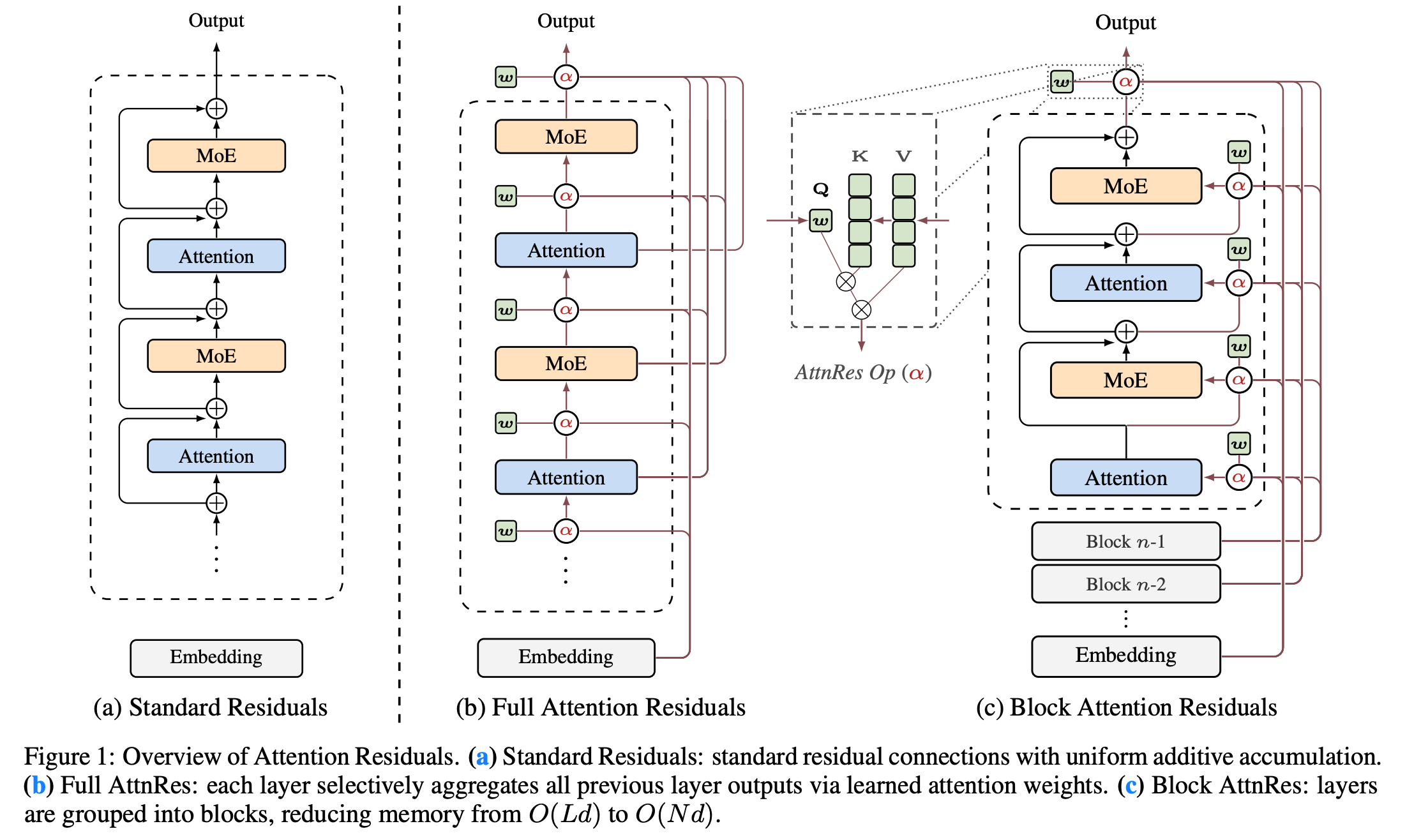
Read more about this research paper using this link.
3. Mamba-3
This research paper introduces Mamba-3, a new sequence model that makes inference much more efficient than transformers (which have quadratic compute and high memory costs).
The key idea is an inference-first redesign of state space models (SSMs) where Mamba-3 uses a:
More expressive recurrence
Complex-valued state update to better track information over time
Multi-input multi-output (MIMO) setup that improves performance without slowing down decoding
These enable it to handle difficult tasks such as state tracking and long-range dependencies, areas where previous linear models struggled, while maintaining near-linear efficiency. This results in Mamba-3 also achieving better accuracy and similar or lower memory use compared to previous models.
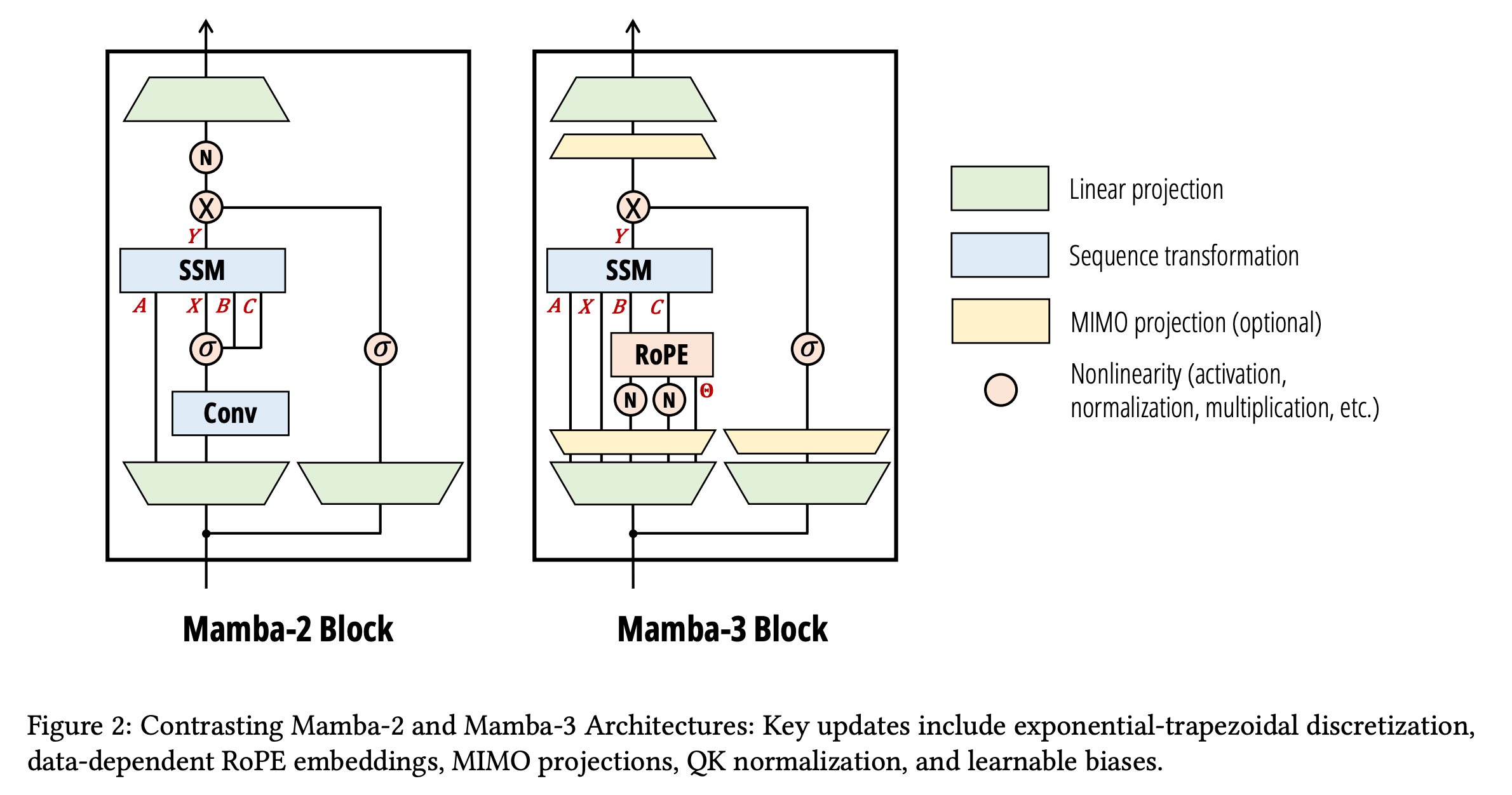
Read more about this research paper using this link.
4. V-JEPA 2.1
This research paper presents V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding.
The approach combines four key components.
A dense predictive loss that uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding.
Deep self-supervision that applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality.
Multi-modal tokenizers that enable unified training across images and videos.
Effective scaling in both model capacity and training data
Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks for short-term object-interaction anticipation and high-level action anticipation.
The model also shows strong performance in robotic navigation, depth estimation, and global recognition.

Read more about this research paper using this link.
5. GPT‑5.4 mini and nano
OpenAI released GPT‑5.4 mini and nano, which are two small, fast, and economical versions of GPT-5.4.
GPT-5.4 mini is a strong, lightweight general-purpose model, especially for coding, reasoning, multimodal understanding, and tool use, and runs over 2× faster than GPT-5-mini. It also approaches the performance of the larger GPT‑5.4 model on several evaluations, including SWE-Bench Pro and OSWorld-Verified.
GPT‑5.4 nano is the smallest, cheapest version of GPT‑5.4 for tasks where speed and cost matter most, such as classification, data extraction, ranking, and coding subagents that handle simpler supporting tasks.
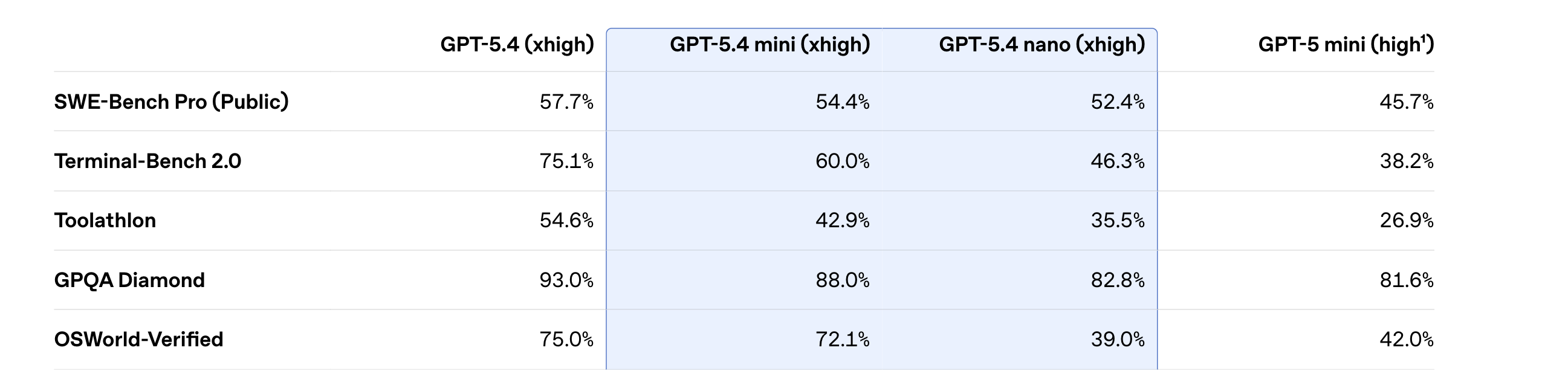
Read more about this release using this link.
6. Composer-2
Composer 2 is a frontier-level coding model that offers a new, optimal combination of intelligence and cost, delivering impressive performance on hard benchmarks, including Terminal-Bench 2.0 and SWE-bench Multilingual.
The model is the result of a continued pretraining run (built on top of the open-source Kimi K2.5 model from Moonshot AI) and further training on long-horizon coding tasks through reinforcement learning, enabling it to solve challenging tasks requiring hundreds of actions.

Read more about this release using this link.
A technical report can be found using this link.
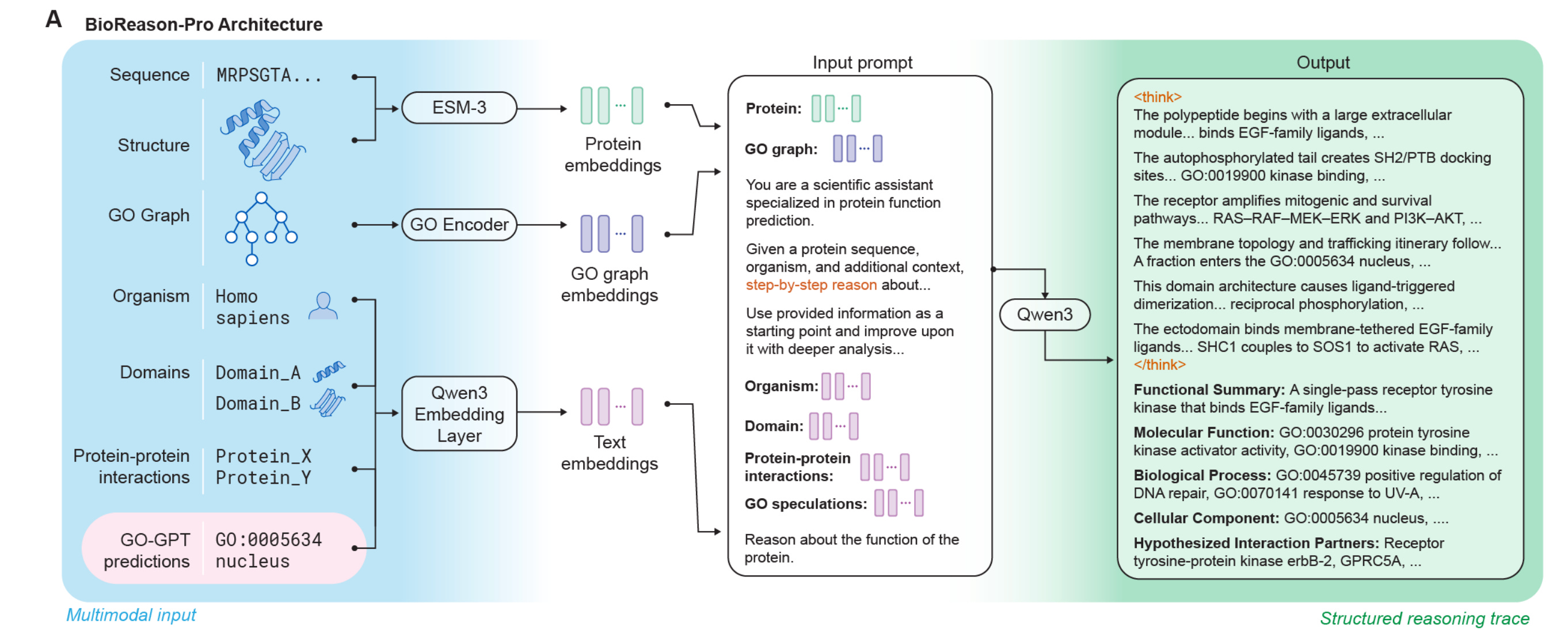
7. BioReason-Pro
This research paper introduces BioReason-Pro, a new multimodal LLM for predicting protein functions that goes beyond traditional methods that rely on sequence similarity or classification.
Instead, it explicitly models biological reasoning across sequence, structure, domains, and interaction data.
BioReason-Pro combines a new autoregressive Gene Ontology predictor (GO-GPT) with a reasoning LLM trained on large-scale synthetic reasoning traces and further improved using reinforcement learning, enabling it to generate clear, step-by-step functional annotations.
Empirically, BioReason-Pro achieves strong performance and produces higher-quality functional summaries than previous methods. Human experts prefer its annotations over curated UniProt entries about 79% of the time.
Notably, the model shows emergent capabilities such as:
accurately predicting protein binding partners
identifying interaction sites at the residue level, consistent with experimental structures
correcting misleading annotations by using contextual reasoning
Read more about this research using this link.
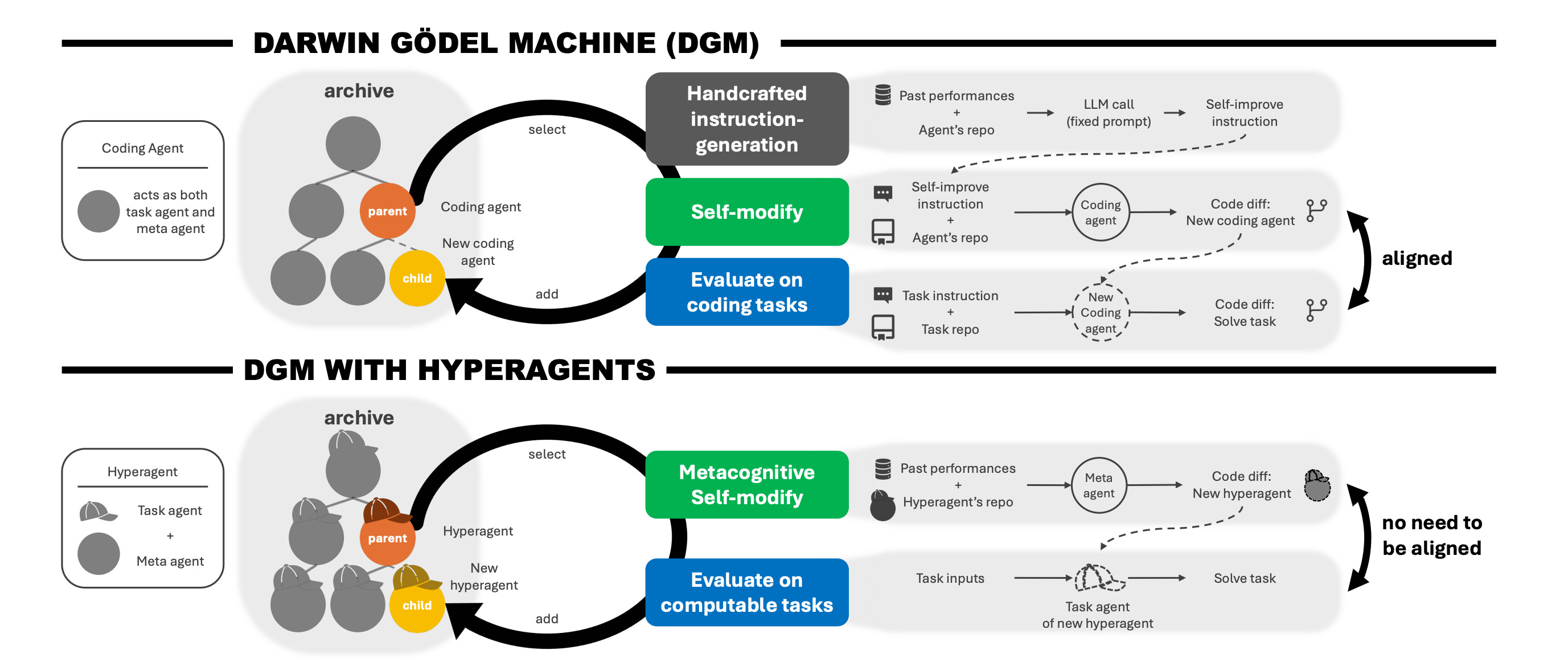
8. Hyperagents
This research paper introduces Hyperagents, a framework that combines a task agent, which solves problems, and a meta agent, which improves the system, into a single editable program.
Importantly, the improvement process is also editable, allowing metacognitive self-modification, meaning the system enhances its own improvement.
The research builds on the Darwin Gödel Machine (DGM) to create DGM-Hyperagents (DGM-H), which removes DGM's assumption that self-improvement only works within coding and outperforms baselines across coding, paper review, robotics reward design, and Olympiad-level math-solution grading, showing meta-level improvements that transfer across domains.
Read more about this research using this link.
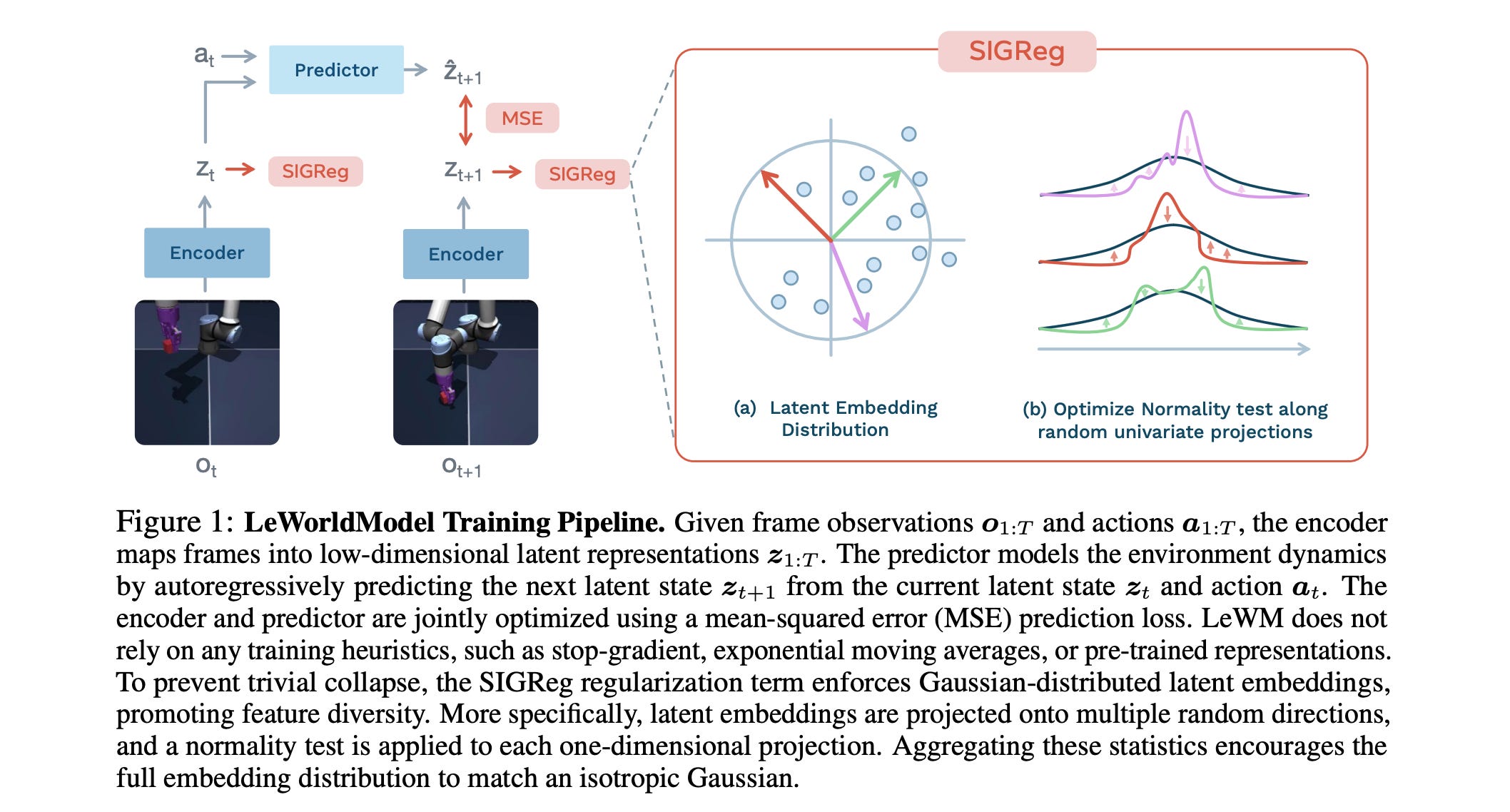
9. LeWorldModel
This research paper introduces LeWorldModel (LeWM), which is the first Joint Embedding Predictive Architecture (JEPA) that trains stably end-to-end from raw pixels using only two loss terms:
a next-embedding prediction loss
a regularizer enforcing Gaussian-distributed latent embeddings
This reduces the number of tunable loss hyperparameters from 6 to 1 compared to the only existing end-to-end alternative.
With approximately 15M parameters trainable on a single GPU in a few hours, LeWM plans up to 48x faster than foundation-model-based world models while remaining competitive across diverse 2D and 3D control tasks.
Beyond control, the researchers show that LeWM's latent space encodes meaningful physical structure through probing of physical quantities. Surprise evaluation confirms that the model reliably detects physically implausible events.
Read more about this research using this link.
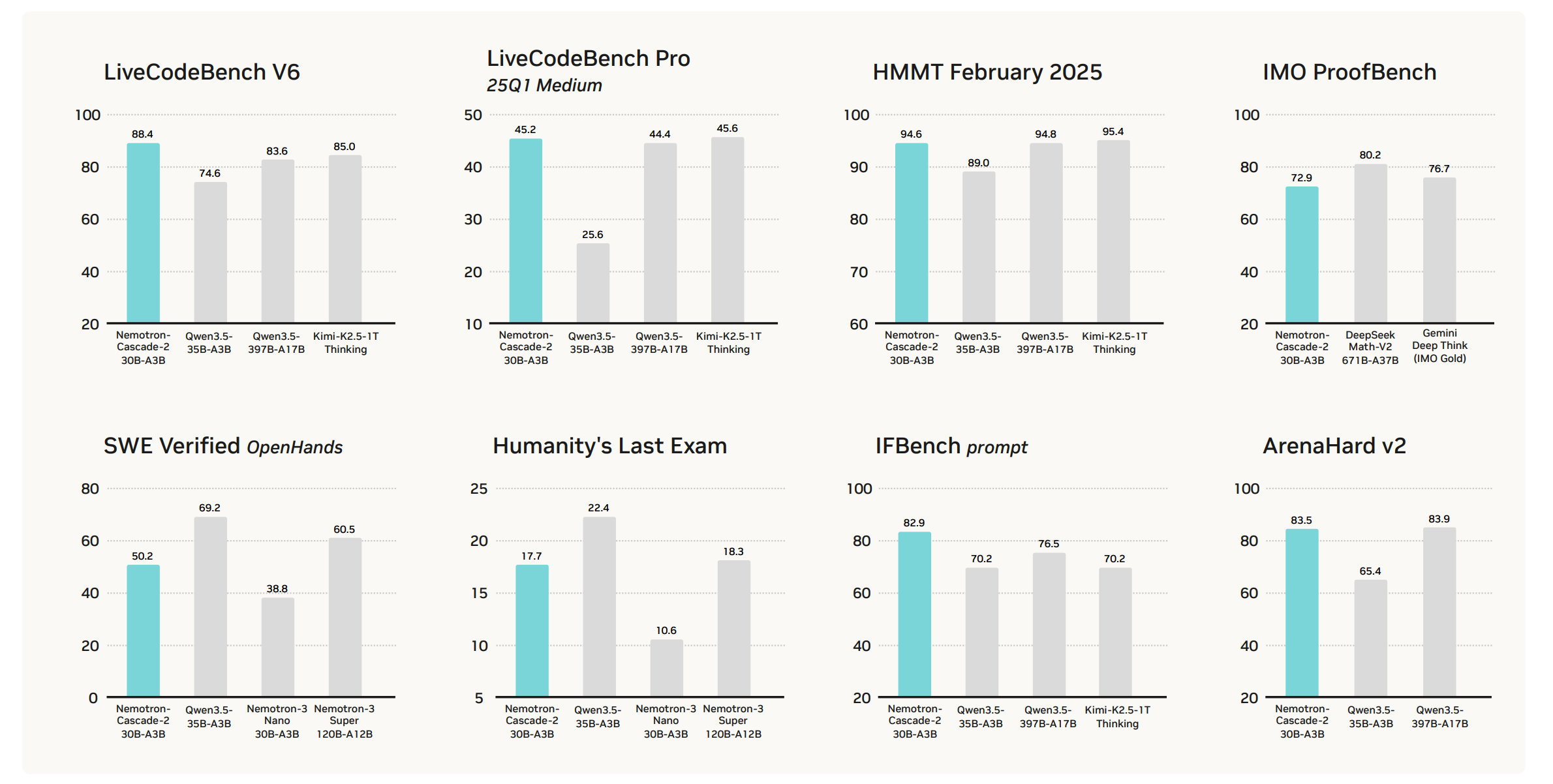
10. Nemotron-Cascade 2
This research paper from NVIDIA introduces Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities.
Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters.
Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others to earn referral rewards. ❤️
Join the paid tier today to get access to all posts on this newsletter:
and so many more!
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
