

This Week In AI Research (17-23 May 26) 🗓️
The top 10 AI research papers that you must know about this week.


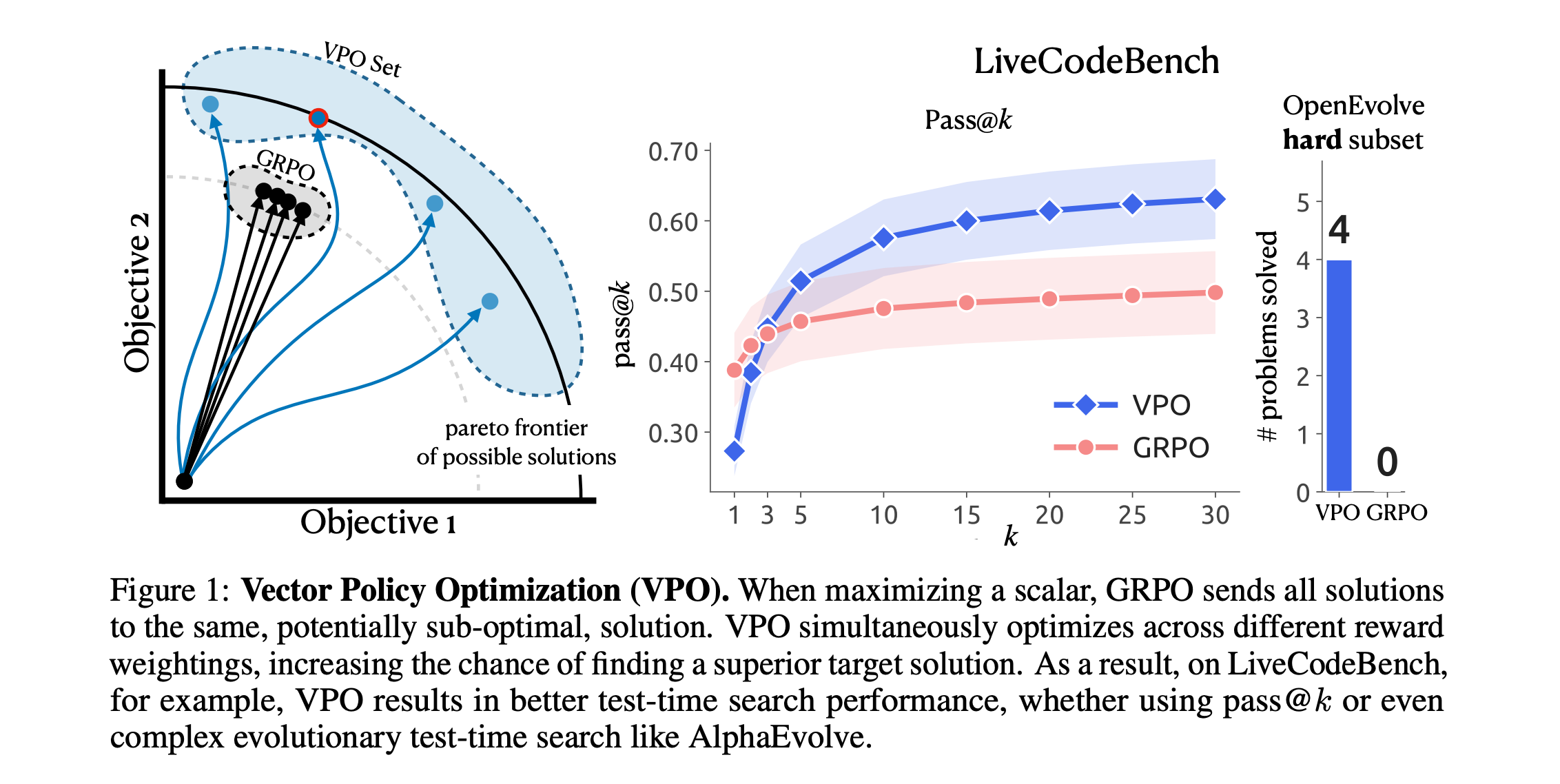
10. Vector Policy Optimization
This research paper introduces Vector Policy Optimization (VPO), an RL post-training method for LLMs. VPO improves test-time search by preserving diversity rather than narrowing to a single high-reward answer.
Unlike GRPO, which focuses on optimizing a single scalar reward, VPO employs vector-valued rewards (such as per-test-case correctness, multiple user preferences, or sub-task scores) and trains the model to produce sets of solutions that cater to different reward trade-offs across the Pareto frontier.
VPO matches or exceeds the performance of strong scalar RL baselines on test-time search (best@k and pass@k metrics) across multi-hop question answering, logic reasoning, navigation, tool use, and coding. These improvements become more significant as the search budget increases.
For evolutionary search, VPO models unlock problems that GRPO models cannot solve at all.
According to the authors, as test-time search becomes more standardized, optimizing for diversity may need to become the default post-training objective.
Read more about this research using this link.
Join the paid tier today to get access to all posts on this newsletter:
👨🔬 Build and Train a Mixture-of-Experts (MoE) LLM from scratch
🚀 Train a Diffusion LLM from scratch (out next week)
and so many more!
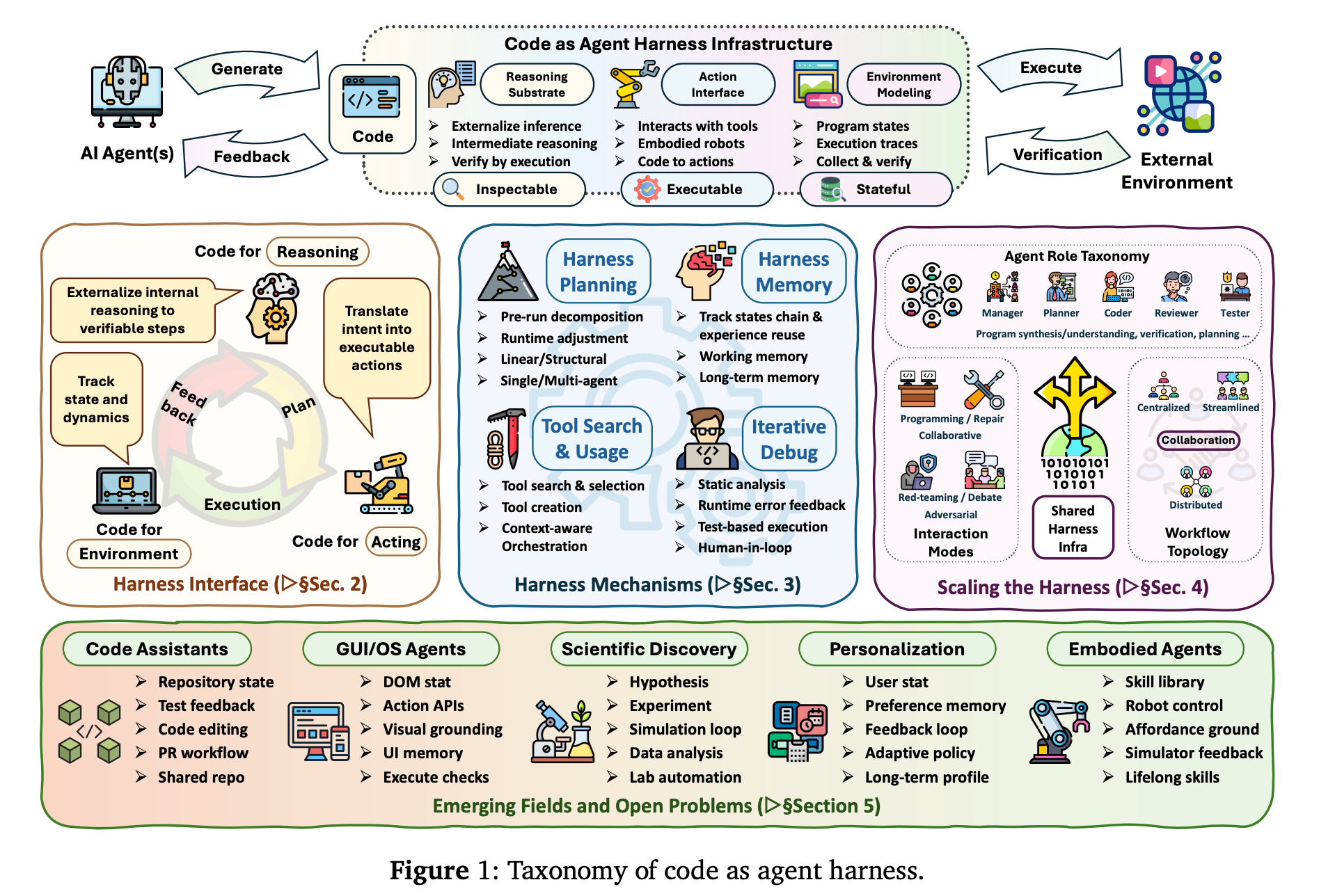
9. Code as Agent Harness
This survey argues that in modern agentic AI systems, code is no longer just an output produced by LLMs. Instead, it is the executable, inspectable, and stateful substrate that allows agents to reason, act, model environments, receive feedback, and verify their progress.
To systematically study this perspective, the authors present a three-layer taxonomy that includes:
Harness interfaces, where code connects agents to reasoning, action, and environment modeling
Harness mechanisms, which include planning, memory, and tool use for long-horizon execution, together with feedback-driven control and optimization that make harness reliable and adaptive
Scaling the harness, from single-agent systems to multi-agent settings, where shared code artifacts support multi-agent coordination, review, and verification
Across these layers, the authors summarize representative methods and practical applications of Code as agent harness, and outline open challenges for harness engineering.
Read more about this research using this link.
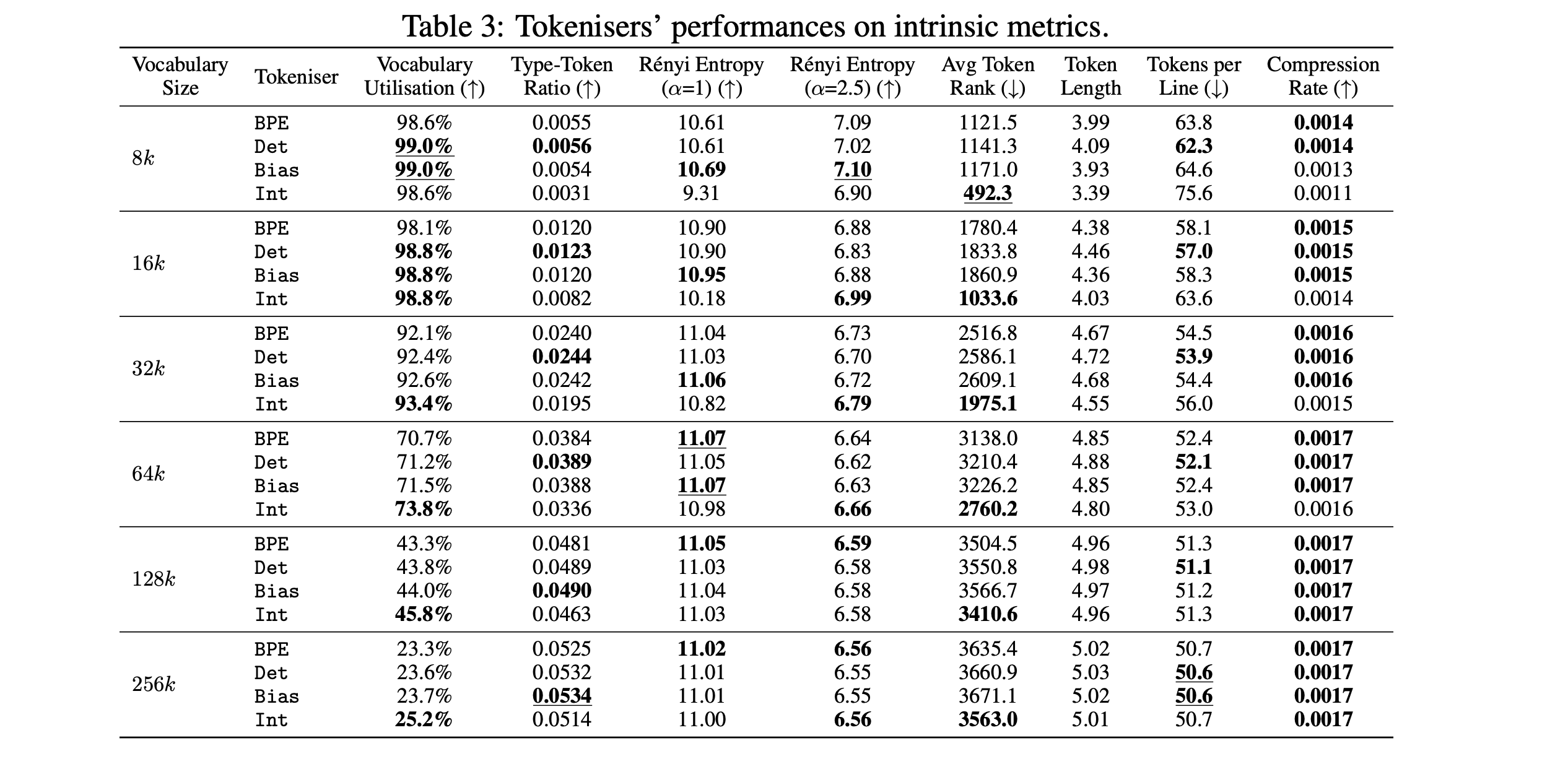
8. Tokenization via Convex Relaxations
This research paper introduces a new tokenization algorithm called ConvexTok.
Current tokenization algorithms, such as BPE and Unigram, are greedy algorithms that make locally optimal decisions without considering the resulting vocabulary as a whole.
ConvexTok, instead, formulates the construction of a tokenizer as a linear program and solves it using a convex optimization tool.
It improves intrinsic tokenization metrics, bits-per-byte (BpB), and downstream task performance of LLMs. It also allows users to certify how close their tokenizer is to the global optimum. Empirically, ConvexTok tokenizers are within 1% of optimal for common vocabulary sizes.
Read more about this research using this link.
7. Probabilistic Tiny Recursive Model
This research paper introduces Probabilistic TRM (PTRM), which improves Tiny Recursive Models by adding Gaussian noise during inference, to create multiple stochastic latent rollouts rather than a single deterministic trajectory.
The model then uses its existing Q head to select the most promising answer, avoiding bad solutions without retraining or task-specific augmentations.
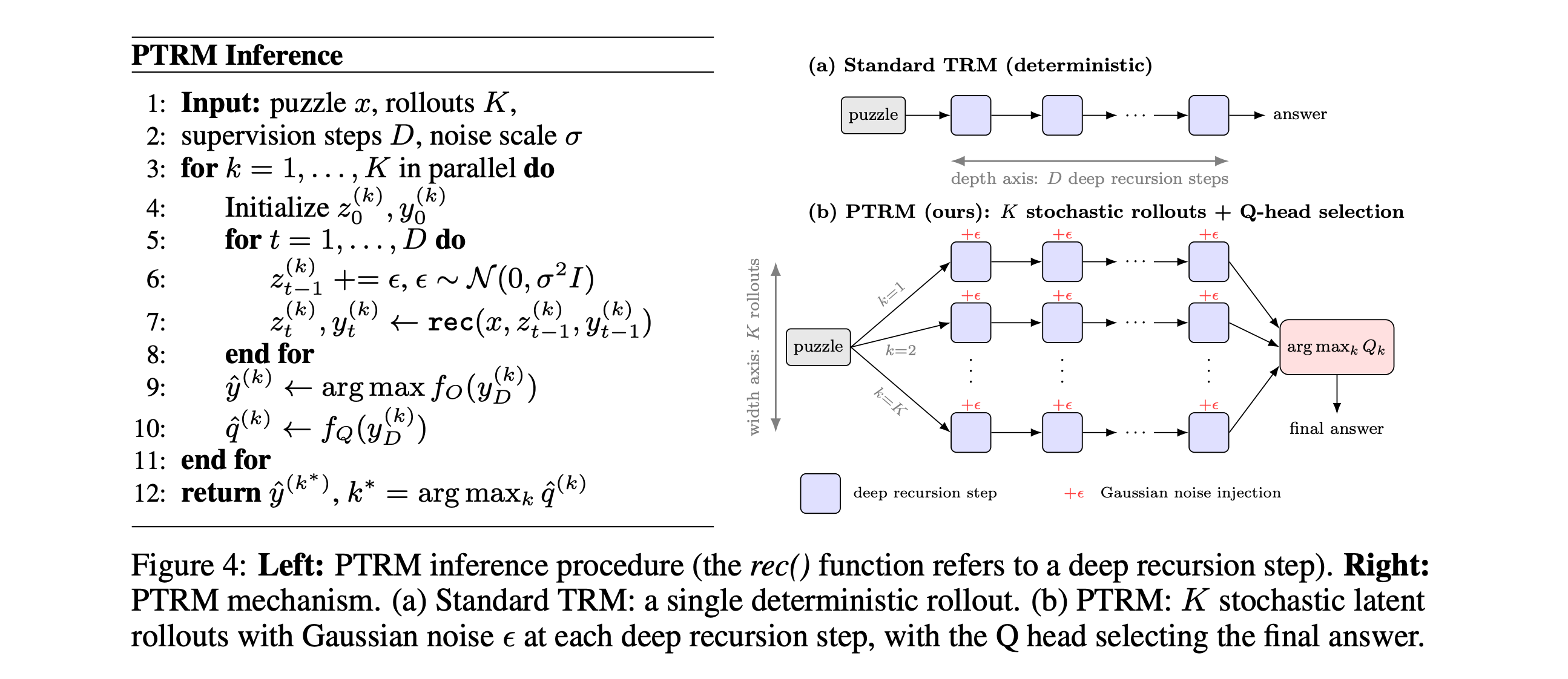
PTRM improves accuracy across multiple benchmarks, including Sudoku-Extreme (87.4% to 98.75%) and Pencil Puzzle Bench (62.6% to 91.2%).
On Pencil Puzzle Bench, PTRM achieves nearly double the accuracy of frontier LLMs (91.2% vs. 55.1%) at less than 0.0001x the cost, using only 7M parameters!
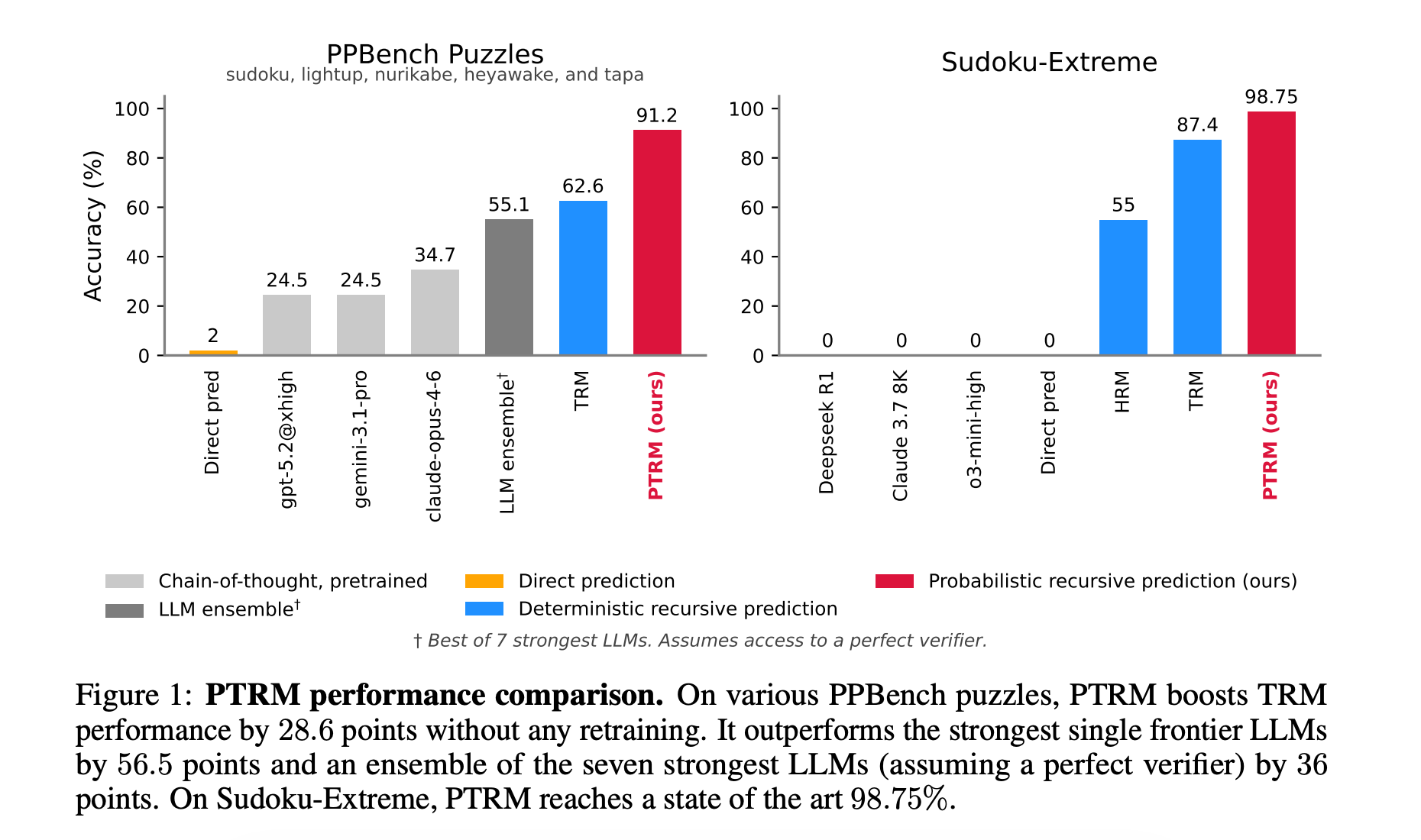
Read more about this research using this link.
6. A Bitter Lesson for Data Filtering
This research paper studies data filtering for LLM pretraining in high-compute, data-scarce settings and challenges the common belief that filtering data to include only high-quality information is essential.
Experiments show that with enough compute, the best data filter is no data filter. Sufficiently trained large parameter LLMs not only tolerate low-quality data but also benefit from it.
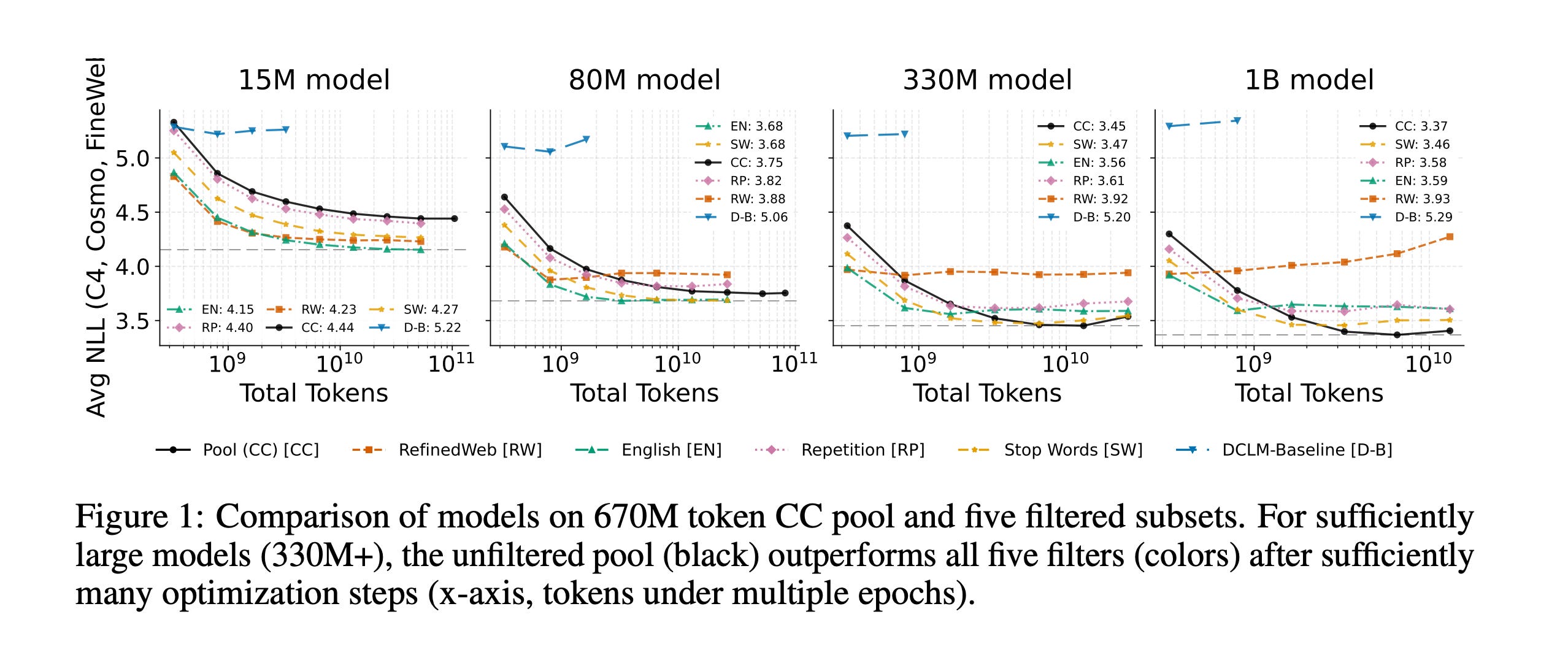
Read more about this research using this link.
5. Strong Teacher Not Needed? On Distillation in LLM Pretraining
In this research paper, the authors challenge a general assumption in Knowledge distillation, that stronger teachers lead to better students.
Their findings show that with proper mixing of the language modeling and knowledge distillation losses, even small and undertrained teachers improve larger students.
Pushing a strong teacher further, through more parameters or more training tokens, can saturate or even reverse the distillation gains.
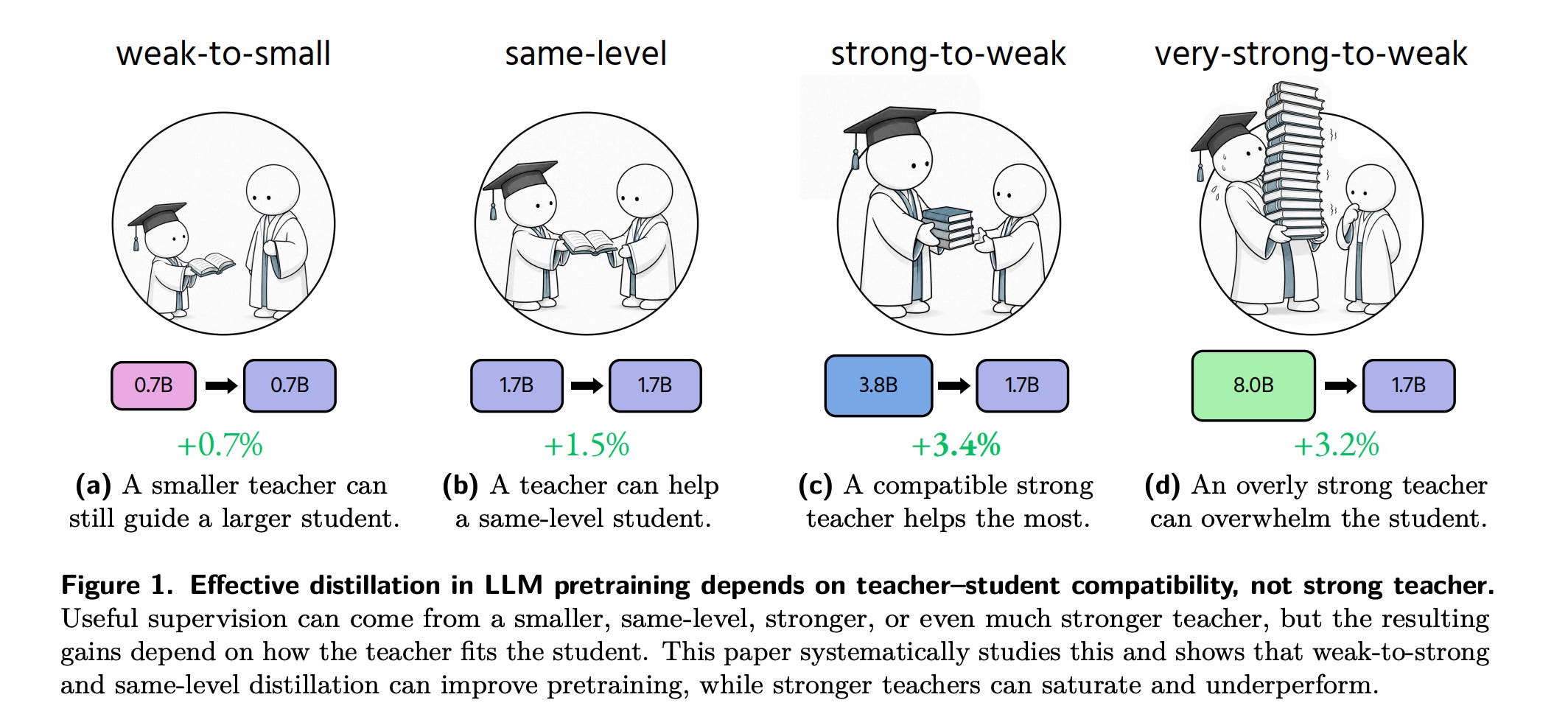
It is further observed that distillation helps the student model generalize more (perform better on out-of-distribution and downstream tasks) than it helps improve on the training data (in-domain tasks).

Read more about this research using this link.
4. HRM-Text: Efficient Pretraining Beyond Scaling
This research paper introduces HRM-Text, a language model that replaces standard Transformers with a Hierarchical Recurrent Model (HRM), an architecture inspired by the human brain that uses slow (strategic) and fast (execution) layers.
To stabilize training for language modeling, the authors introduce MagicNorm and warmup deep credit assignment.
Alongside this, rather than standard raw-text pretraining, the model is trained exclusively on instruction-response pairs, using a task-completion objective and PrefixLM masking.
A 1B parameter HRM-Text model trained from scratch with a $1,500 budget achieves 60.7% on MMLU, 81.9% on ARC-C, 82.2% on DROP, 84.5% on GSM8K, and 56.2% on MATH.
Despite using ~100-900x fewer training tokens and ~96-432x less compute than standard baselines, HRM-Text performs competitively with 2–7B parameter open models.
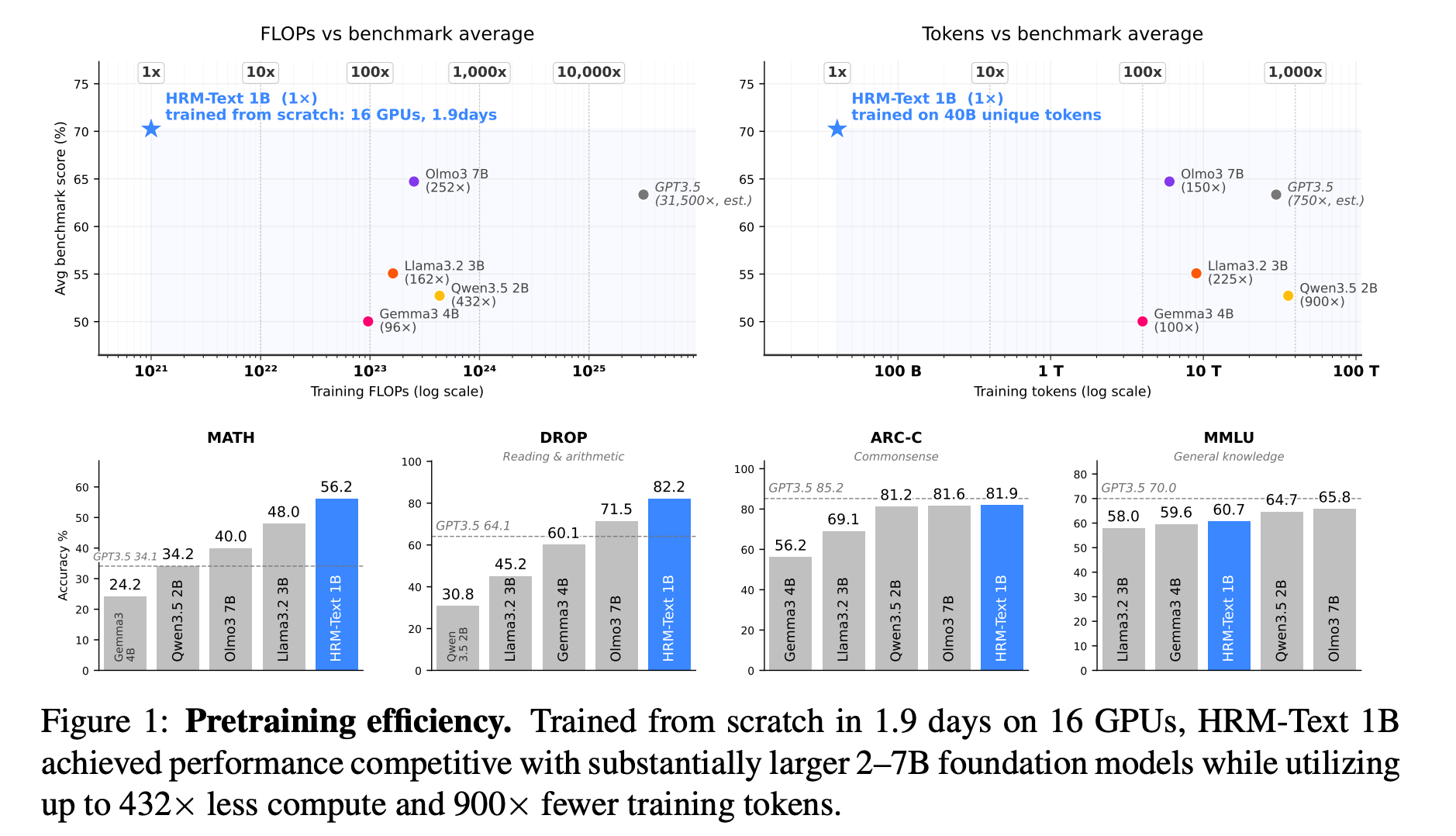
Read more about this research using this link.
3. Gated DeltaNet-2
This research paper introduces Gated DeltaNet-2, which improves linear-attention models by separating two memory operations, erasing old information and writing new information, that previously introduced Gated Delta Networks and Kimi Delta Attention (KDA) tied together.
It uses separate channel-wise erase and write gates while supporting efficient recurrent and parallel training. This allows the model to manage compressed long-context memory better without the high cost of standard attention.
With 1.3B parameters, Gated DeltaNet-2 outperforms Mamba-2, Gated DeltaNet, KDA, and Mamba-3 variants in language modeling, commonsense reasoning, and retrieval, particularly in long-context needle-in-a-haystack tasks.
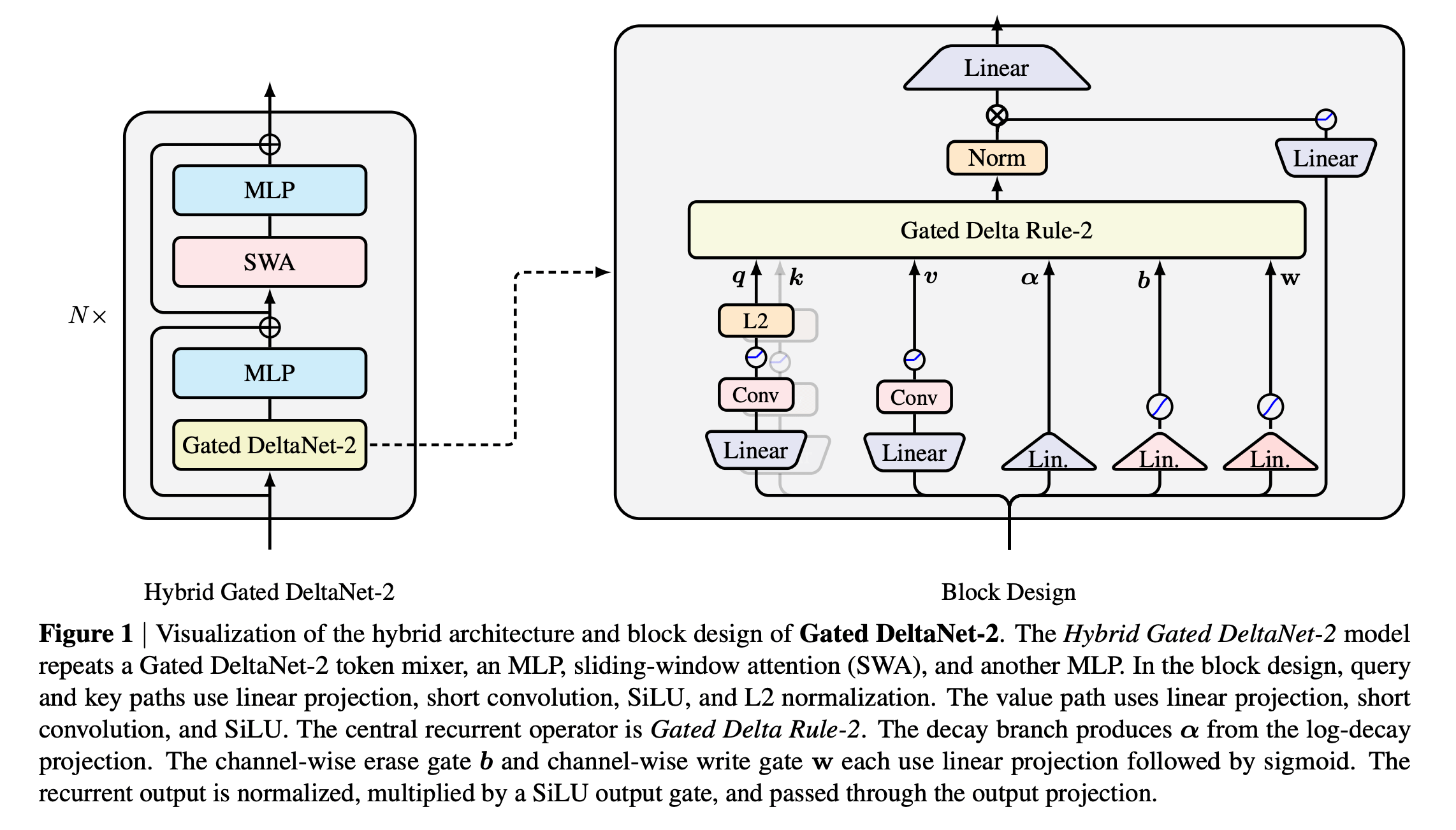
Read more about this research using this link.
2. Advancing Mathematics Research with AI-Driven Formal Proof Search
This research paper presents AlphaProof Nexus, a framework that uses LLM-based agents to generate and iteratively improve Lean formal proofs using compiler feedback, optional AlphaProof calls, and evolutionary search.
In a large-scale test on open research problems, the strongest agent solved 9 of 353 Erdős problems, proved 44 of 492 OEIS conjectures, and contributed to multiple other open mathematical problems.
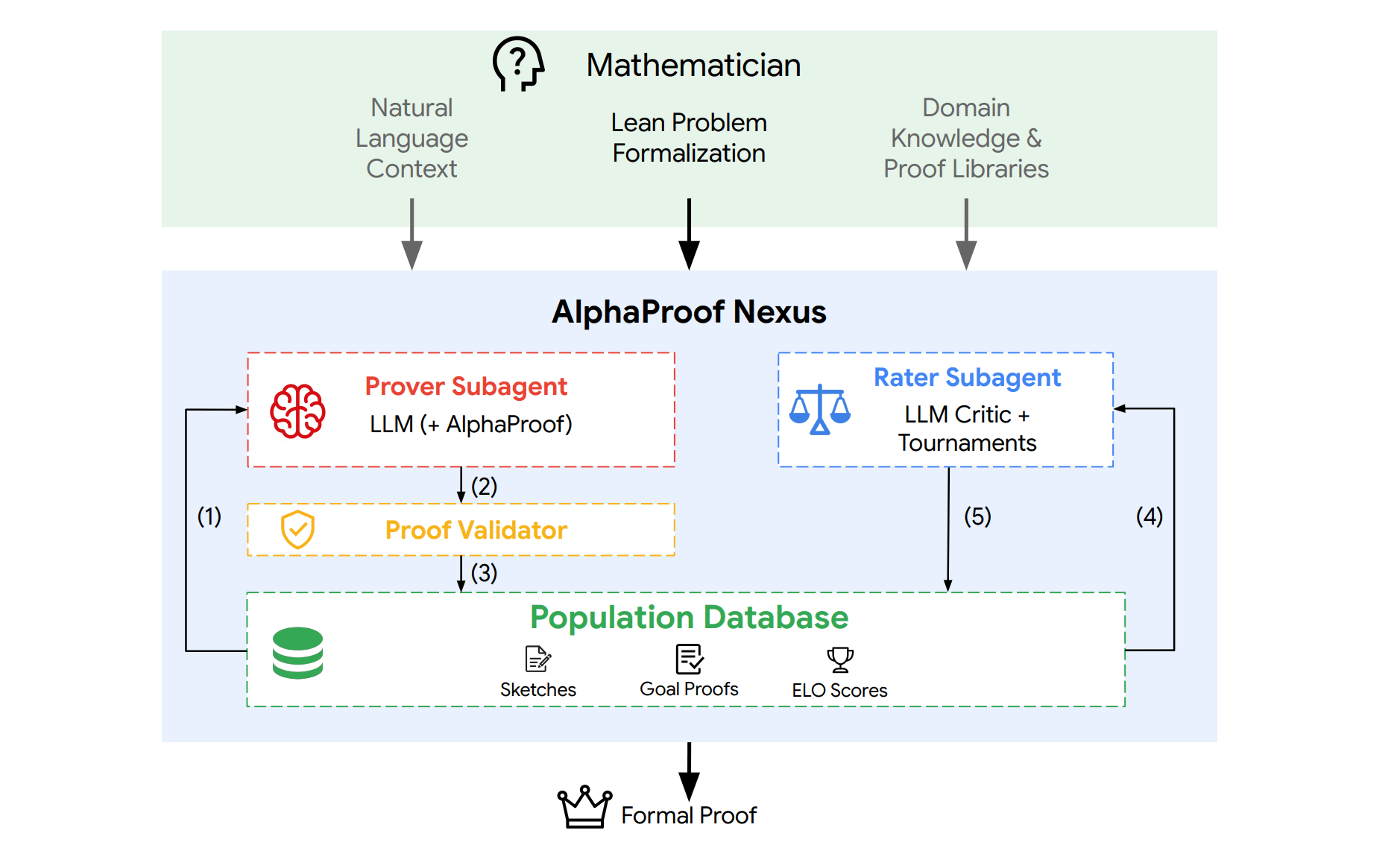
Read more about this research using this link.
1. An OpenAI model has disproved a central conjecture in discrete geometry
This blog post reports that an internal reasoning model at OpenAI has disproved Erdős’s long-standing unit distance conjecture in discrete geometry, that the maximum number of unit-distance pairs among n points in the plane were bounded by n¹⁺ᵒ⁽¹⁾.
The model produced an infinite set of point configurations with at least n¹⁺δ unit distances for some fixed δ greater than 0, using unexpected tools from algebraic number theory, such as class field towers and Golod–Shafarevich theory.
The proof has been verified by external mathematicians, and this is a major milestone where an AI system has autonomously resolved an important open mathematical problem, revealing a surprising connection between algebraic number theory and discrete geometry.

Read more about this using this link.
This newsletter edition is completely free to read. Show your love by liking it, restacking it, and sharing it with others! ❤️