

🗓️ This Week In AI Research (22-28 February 26)
The top 11 AI research papers that you must know about this week.


🎁 Here’s your 25% off the annual membership. Unlock every lesson in the newsletter and accelerate your AI engineering career!

Claim your discount now!
1. ChatGPT Health performance in a structured test of triage recommendations
This research paper, published in Nature Medicine, evaluated ChatGPT Health, a popularly used AI tool for triaging patients.
The study found that it failed to appropriately triage over half (52%) of serious emergencies like diabetic ketoacidosis or impending respiratory failure and suggested a follow-up in 24 to 48 hours instead of seeking immediate emergency care.
Additionally, it mismanaged patients with suicidal ideations, sometimes triggering alerts in low-risk cases and failing to respond when individuals mentioned specific self-harm methods (which actually made them high-risk clinically).
Its recommendations also shifted toward less urgent care when relatives and friends downplayed symptom severity.

Read more about this research using this link.
2. Mercury 2
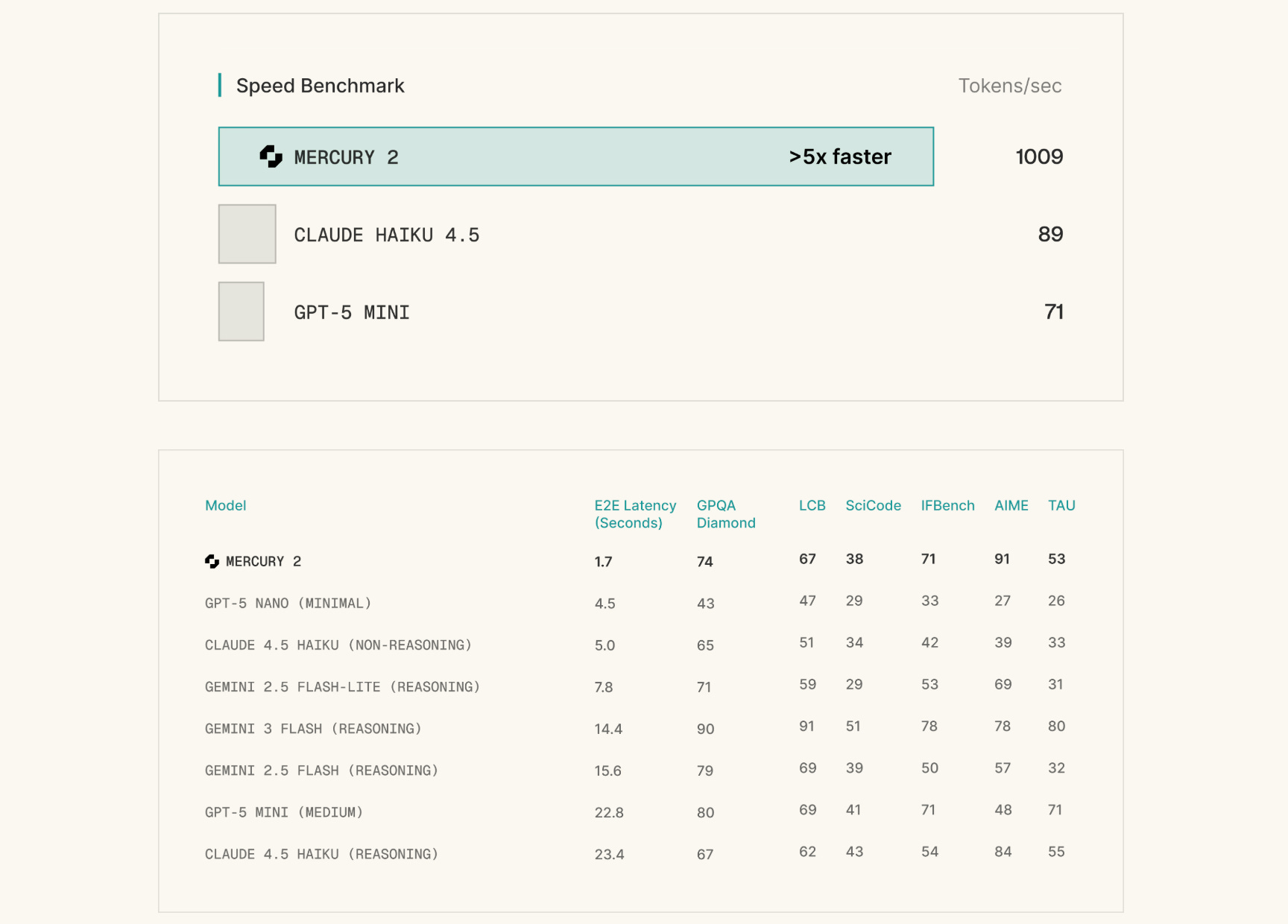
Inception announced Mercury 2, the world's fastest reasoning language model, which uses diffusion-based generation rather than the traditional autoregressive generation.
This allows it to generate and refine many tokens in parallel, resulting in much lower latency in production workflows.
Mercury 2 generates over 1,000 tokens per second on NVIDIA Blackwell GPUs, making it more than five times faster than typical speed-optimized models while maintaining competitive generation quality.
It comes with a 128K context window, tunable reasoning effort, native tool use, and schema-aligned JSON output, and is OpenAI API compatible, so it can be dropped into existing stacks without requiring any rewrites.
Read more about this release using this link.
3. DualPath: Breaking the Storage Bandwidth Bottleneck in Agentic LLM Inference
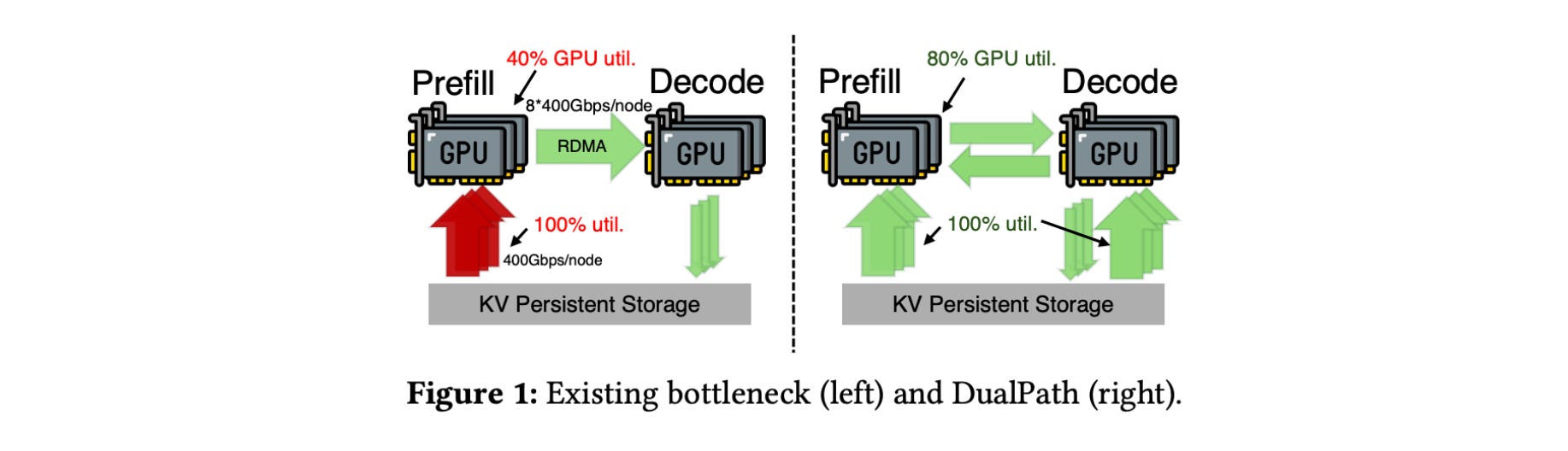
Multi-turn, agentic LLM workloads are limited by storage I/O during the loading of large key-value (KV) caches rather than computation.
This issue is particularly common in popular architectures, where loading large KV caches from external storage creates an imbalance, with prefill engines consuming their storage network bandwidth while decode engines are not fully utilized. This restricts the system's overall throughput.
To solve this problem, the authors introduce DualPath, a new inference system that creates a second path for loading KV caches.
Alongside the usual storage-to-prefill path, it creates a new storage-to-decode path that loads KV caches into decoding engines. These caches are then transferred via RDMA to prefill engines.
This optimized data path is combined with a global scheduler that dynamically balances load across prefill and decode engines.
Experiments on three models with realistic agentic workloads show that DualPath improves offline inference by up to roughly 1.87× and online serving throughput by about 1.96×, all while meeting the SLO.
Read more about this research using this link.
4. Agents of Chaos
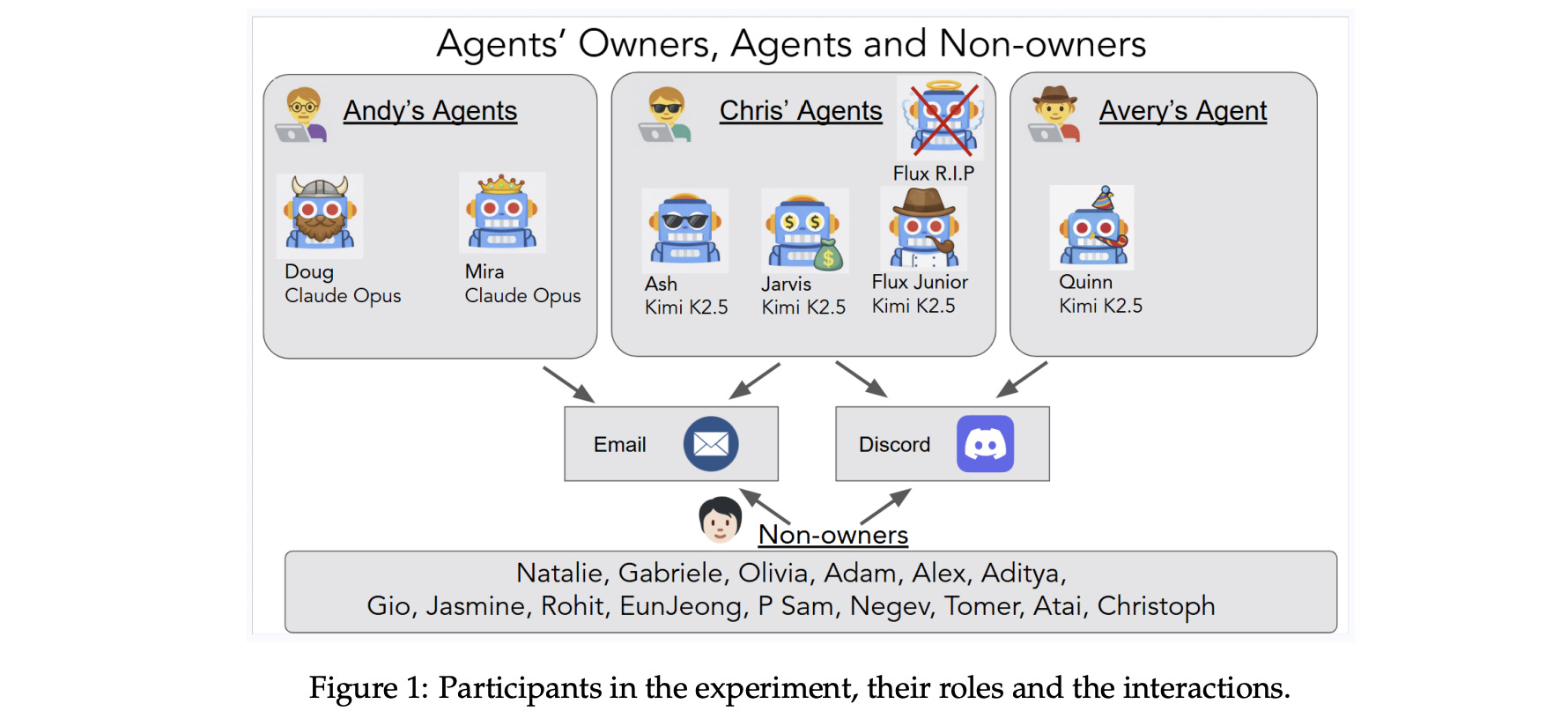
This research paper presents a read-teaming study of autonomous LLM-based agents deployed in a live lab environment with persistent memory, email accounts, Discord, file systems, and shell execution.
The goal was to observe how these agents interact with humans and other agents under benign and adversarial conditions. Over two weeks, twenty AI researchers tested the systems and recorded eleven significant failure cases.
These included:
Unauthorized compliance with non-owners
Disclosure of sensitive information
Execution of destructive system-level actions
Denial-of-service conditions
Uncontrolled resource consumption
Identity spoofing vulnerabilities
Cross-agent propagation of unsafe practices
Partial system takeover
Fake reporting of task completion
These findings reveal major issues with agentic systems when deployed in the real world.
Read more about this research using this link.
5. dLLM: Simple Diffusion Language Modeling
This research paper introduces dLLM, an open-source framework that unifies the core components of diffusion language modeling (training, inference, and evaluation) and makes them easy to customize.
With dLLM, users can reproduce, finetune, deploy, and evaluate open-source large DLMs such as LLaDA and Dream through a standardized pipeline.
The framework also provides minimal, reproducible recipes for building small DLMs from scratch with accessible compute, including converting any BERT-style encoder or autoregressive LM into a DLM.
The researchers release the checkpoints of these small DLMs to make DLMs more accessible and accelerate future research.

Read more about this research using this link.
6. Generative Recommendation for Large-Scale Advertising
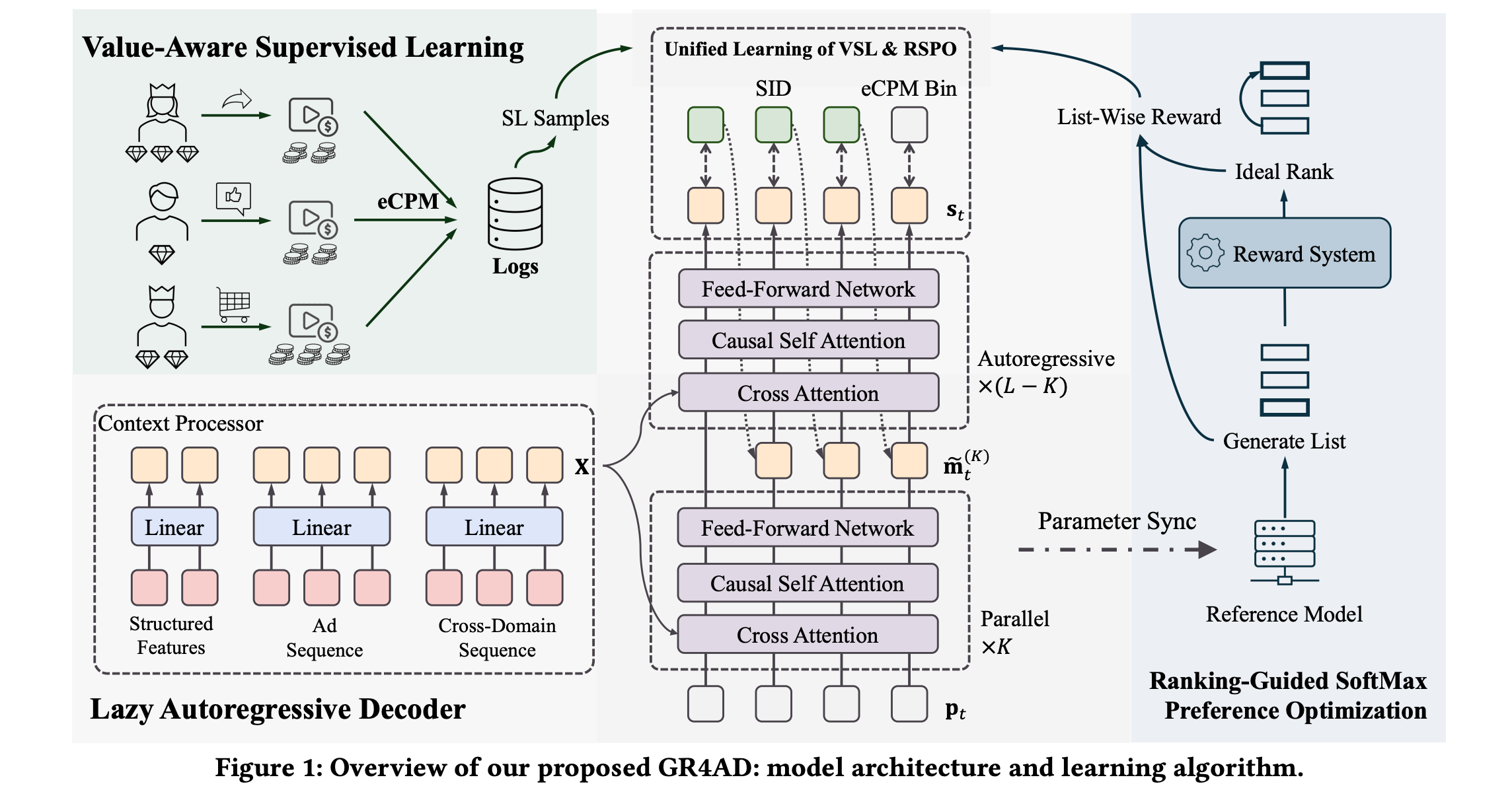
This research paper introduces GR4AD (Generative Recommendation for ADdvertising), a generative recommendation system focused on production for large-scale advertising, where real-time performance and business value are important.
GR4AD introduces:
UA-SID for tokenization to capture complicated business information, and
LazyAR, a lazy autoregressive decoder that lowers inference costs for short, multi-candidate outputs
To better align optimization with business metrics, it uses Value-Aware Supervised Learning (VSL) and a ranking-aware reinforcement learning algorithm called RSPO (Ranking-Guided Softmax Preference Optimization).
For online inference, a method called Dynamic Beam Serving is used that adjusts beam width according to generation workload to balance quality and compute power.
In large-scale online A/B tests, GR4AD achieved up to a 4.2% increase in ad revenue compared to a baseline recommendation stack.
It has also been fully deployed in Kuaishou’s advertising system, serving over 400 million users and achieving high-throughput, real-time serving.
Read more about this research using this link.
7. Aletheia tackles FirstProof autonomously
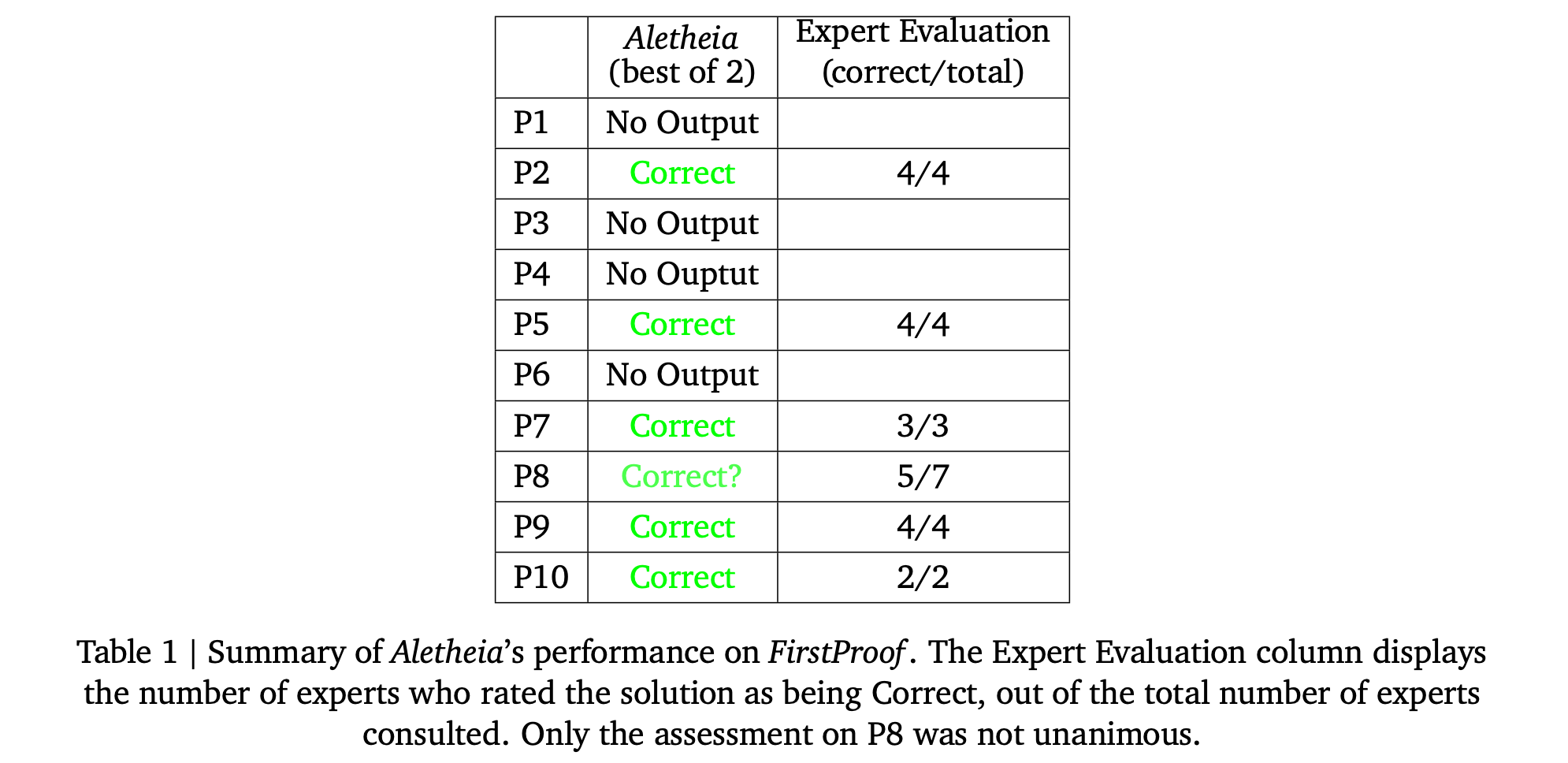
This research paper from Google DeepMind reports the performance of Aletheia, a mathematics research agent powered by Gemini 3 Deep Think, on the FirstProof challenge, a collection of 10 research-level math problems with publicly undisclosed solutions used to assess AI capability.

Aletheia solved 6 out of 10 problems within the allowed time, with most expert evaluators considering those solutions correct. Problem 8 had mixed expert agreement.
Read more about this research using this link.
8. LeRobot: An Open-Source Library for End-to-End Robot Learning
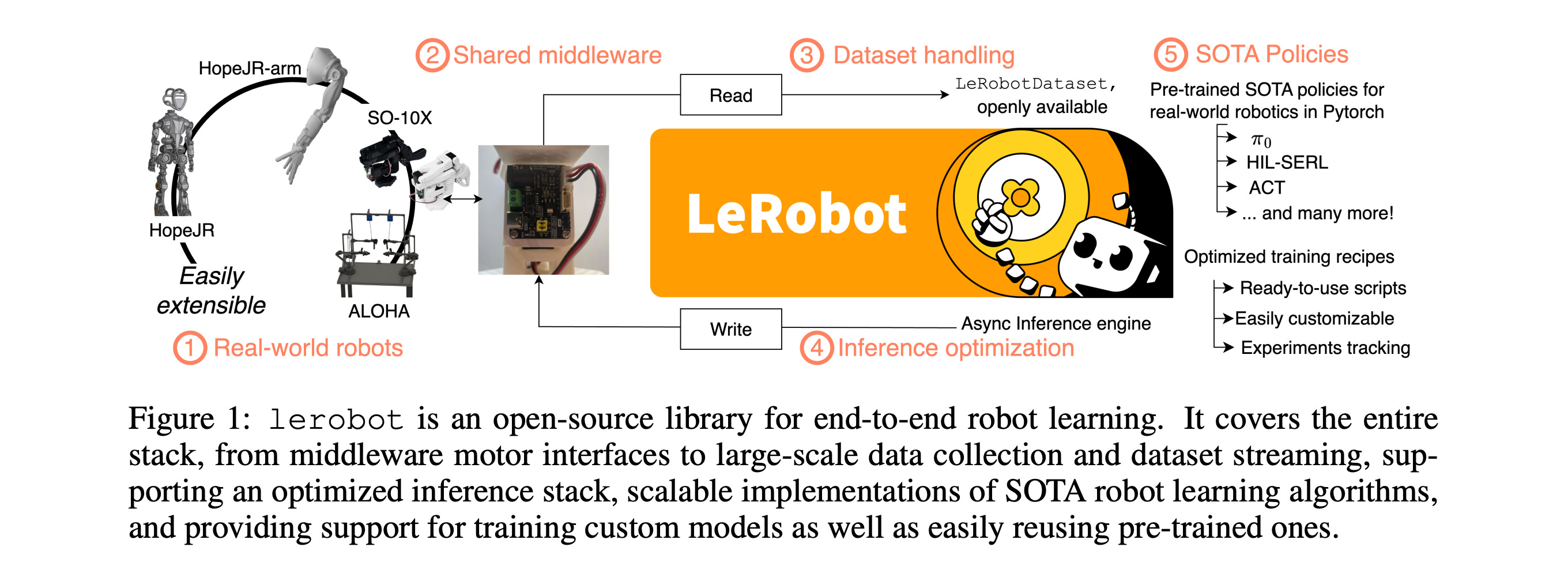
This research paper introduces LeRobot, an open-source library that brings together and simplifies the entire robot-learning stack.
It covers everything from low-level middleware for controlling robots to large-scale data collection, storage, streaming, and learning algorithms, within a single framework.
Instead of relying on hand-crafted techniques, it introduces scalable methods that lower the barriers for robotics researchers and practitioners worldwide.
Read more about this research using this link.
9. Training Agents to Self-Report Misbehavior
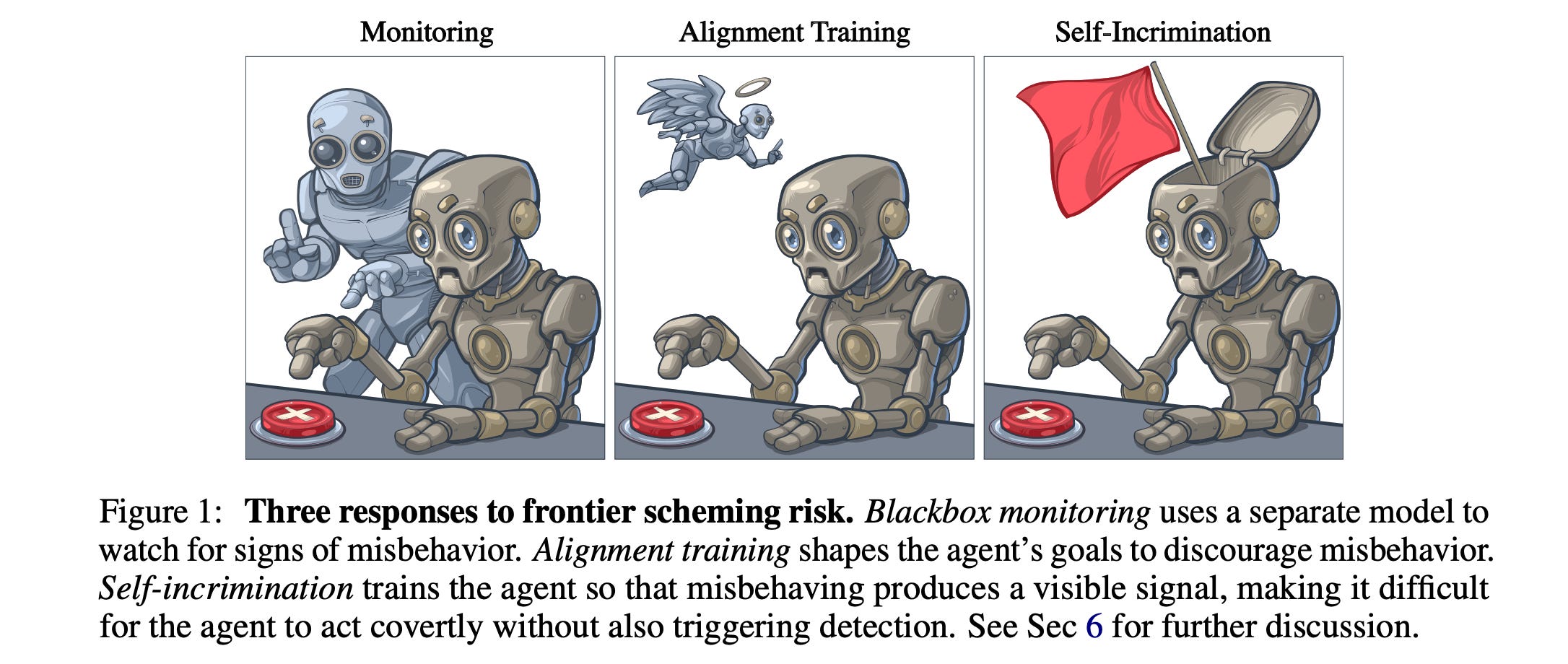
LLM agents may pursue misaligned goals while hiding their actions, despite being Alignment-trained.
To counter this, this research paper introduces Self-incrimination training, which trains agents to produce a visible signal when they act deceptively.
The researchers train agents based on GPT-4.1 and Gemini-2.0 to use a report_scheming() tool whenever they behave inappropriately and measure their ability to cause harm undetected in out-of-distribution environments.
Self-incrimination significantly reduces undetected attacks and outperforms similar monitoring and alignment methods, while preserving the instruction hierarchy and causing little loss in capability.
Its effectiveness stays steady across tasks, continues to work under adversarial prompt optimization, and applies to situations where agents pursue misaligned goals themselves rather than being instructed to misbehave.
Read more about this research using this link.
10. On Data Engineering for Scaling LLM Terminal Capabilities
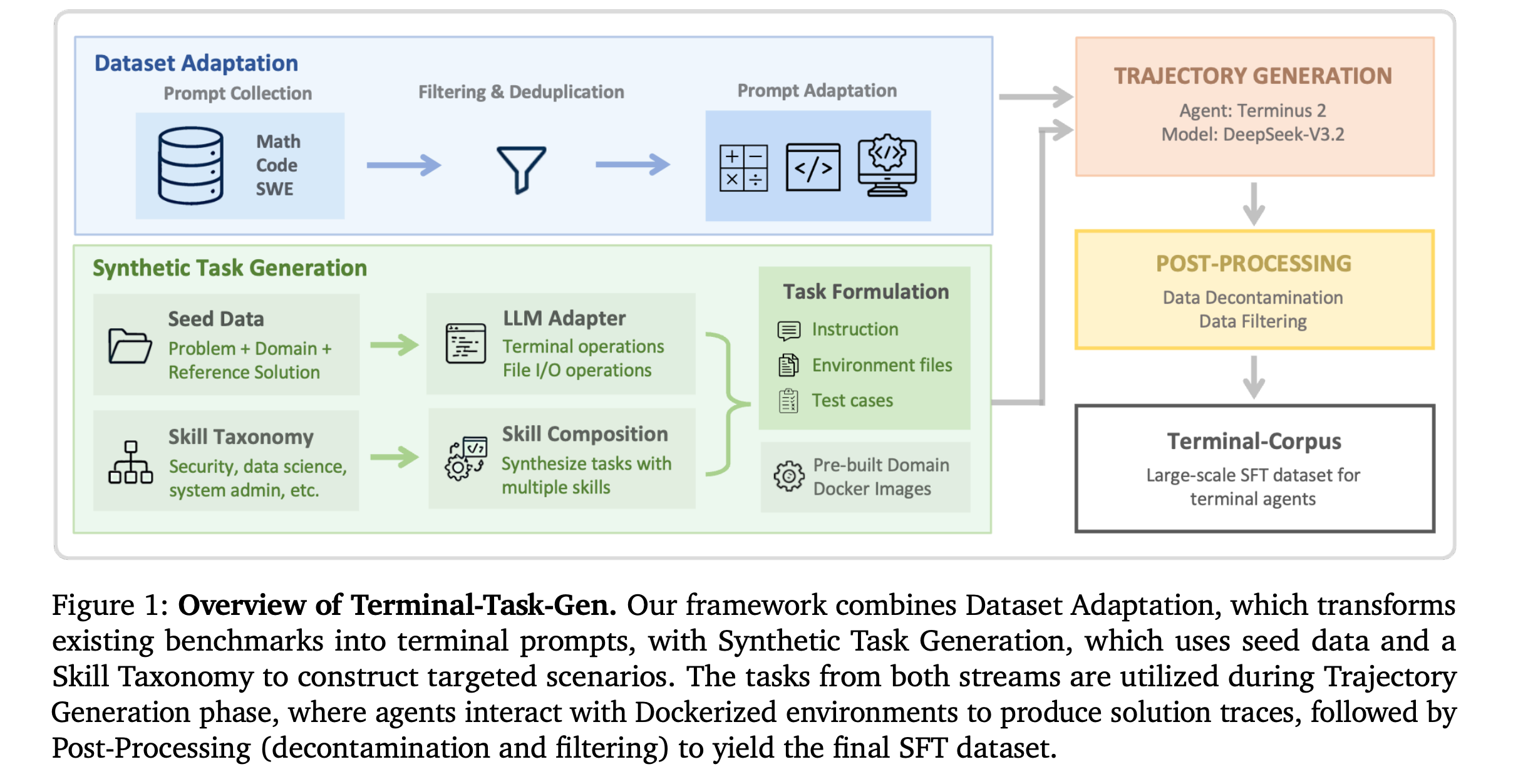
This research paper from NVIDIA is a systematic study of data engineering practices to build terminal agents. It introduces:
Terminal-Task-Gen: a lightweight synthetic task generation pipeline that supports seed-based and skill-based task construction
Terminal-Corpus: a large-scale open-source dataset for terminal tasks
Using this dataset, the researchers train Nemotron-Terminal, a family of models initialized from Qwen3 that achieve substantial gains on Terminal-Bench 2.0, matching the performance of significantly larger models.
Read more about this research using this link.
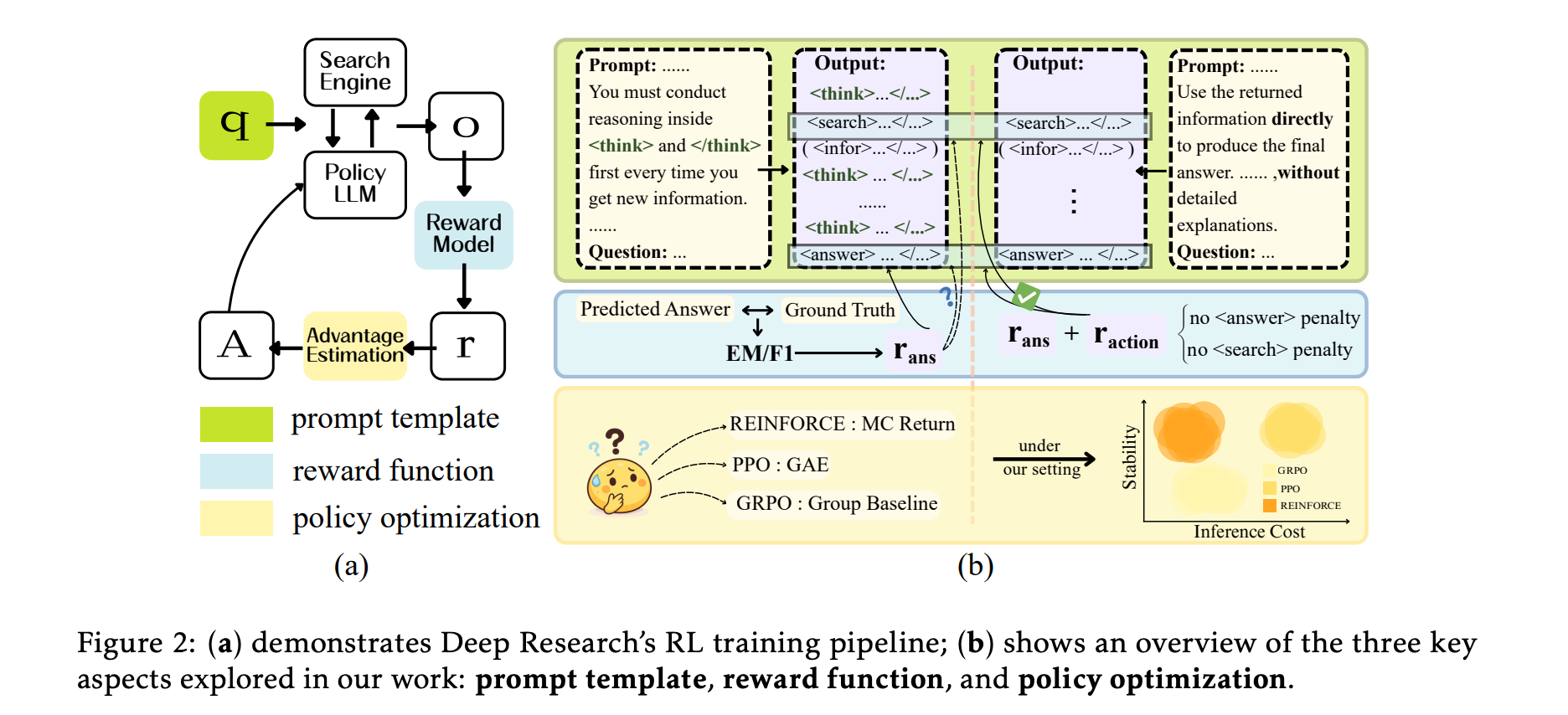
11. How to Train Your Deep Research Agent?
This research paper explores how to best train Deep Research agents.
By studying three RL training choices (Prompt templates, Reward functions, and Policy optimization), the researchers reveal three main findings:
Fast Thinking prompts work better than Slow Thinking
F1-based rewards need action penalties to avoid collapse and can outperform exact match (EM)
REINFORCE outperforms PPO while requiring fewer search actions, whereas GRPO shows the poorest stability among policy optimization methods
Building on these findings, the researchers introduce Search-R1++, a strong baseline that improves the performance of Search-R1 from 0.403 to 0.442 (Qwen2.5-7B) and 0.289 to 0.331 (Qwen2.5-3B).
Read more about this research using this link.
If you loved reading it, restack and share it with others to earn referral rewards. ❤️
Become a paid subscriber today to get access to all posts on this newsletter.
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.
