

This Week In AI Research (24-31 May 26) 🗓️
The top 10 AI research papers that you must know about this week.


10. Language Models Need Sleep
The attention mechanism in Transformer-based LLMs scales poorly with increasing context length due to its quadratic complexity.
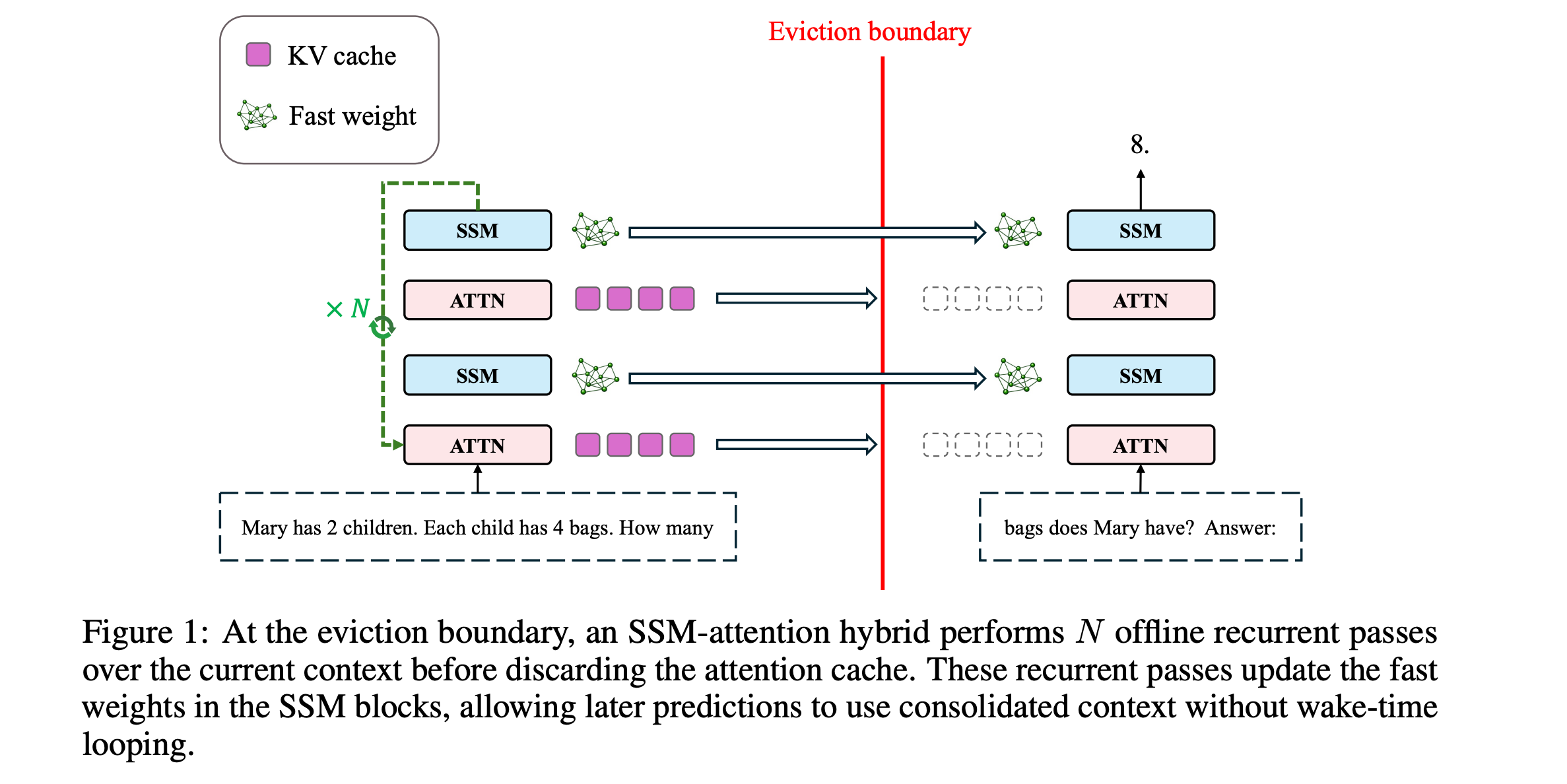
This research paper proposes a sleep-like mechanism to address this problem, in which an LLM periodically converts recent context into persistent fast weights before clearing its KV cache.
These fast weights are implemented as State-space model (SSM) blocks, and during sleep, N offline recurrent passes over the accumulated context update these weights.
During inference, this shifts extra computation to sleep while preserving the latency of wake-time prediction.
When tested on synthetic tasks such as cellular automata, multi-hop graph retrieval, and a realistic math reasoning task, both regular transformers and vanilla SSM-attention hybrid models fail.
In contrast, this is not true for the sleep-augmented SSM-attention hybrid model, where increasing sleep duration (number of recurrent passes N) improves performance, with the largest gains on tasks that require deeper reasoning.
Read more about this research paper using this link.
Join the paid tier today to get access to all posts in this newsletter:
👨🔬 Build and Train a Mixture-of-Experts (MoE) LLM from scratch
🚀 Train a Diffusion LLM from scratch (out this week)
and so many more!
9. LocateAnything: Fast and High-Quality Vision-Language Grounding with Parallel Box Decoding
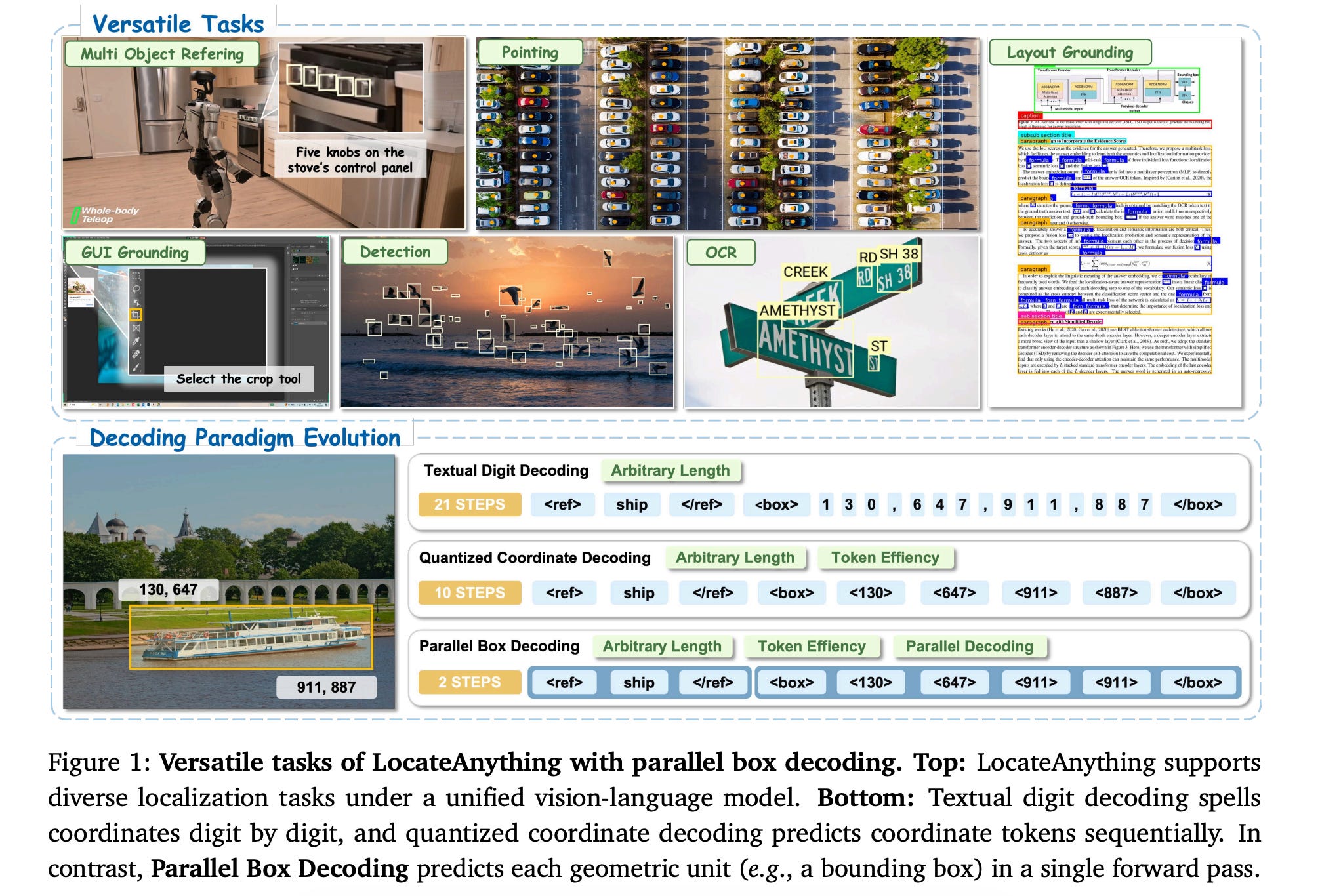
This research paper presents LocateAnything, a vision-language grounding and detection framework that replaces slow token-by-token coordinate generation with fast Parallel Box Decoding.
This method treats boxes or points as atomic geometric units, decoding them in one step, and improves both decoding throughput and localization consistency.
Researchers also developed a scalable data engine and curated LocateAnything-Data, a large-scale dataset with more than 138M training samples, which substantially increases data diversity for high-precision localization.
Evals show that LocateAnything advances the speed-accuracy frontier, achieving significantly higher decoding throughput while improving high-IoU (Intersection over Union) localization quality across different benchmarks.
Read more about this research paper using this link.
8. The MiniMax-M2 Series
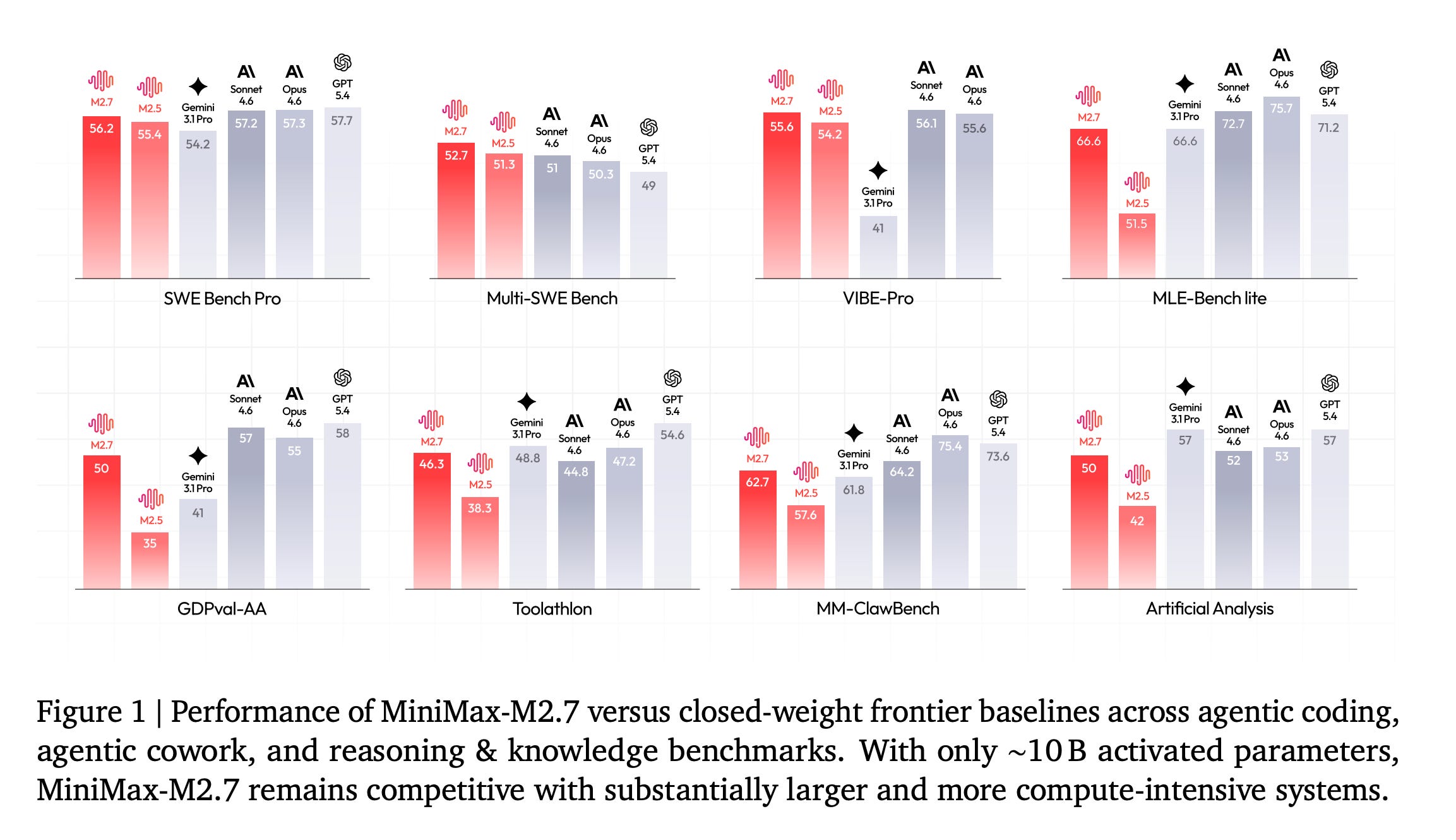
This research paper presents the MiniMax-M2 series of highly sparse Mixture-of-Experts LLM models designed for efficient agentic work.
The flagship M2.7 model has:
229.9B total parameters
Activates only 9.8B per token
A 192K-token context and multi-token prediction for faster inference
This series uses three important components:
An agent-driven data pipeline that produces large-scale, verifiable trajectories across agentic coding and agentic co-work
Forge, a scalable agent-native RL system for long-horizon agentic tasks
A self-evolution mechanism in the M2.7 model, where the model autonomously debugs training runs and modifies its own scaffold.
Evals show that this series of models produces frontier-tier performance on agentic coding, deep search, office-task, and reasoning benchmarks, despite activating so few parameters per token.
The MiniMax M3 model is also out today, and we will discuss it in the next edition of the newsletter.
Read more about this research paper using this link.
7. InstructSAM: Segment Any Instance with Any Instructions
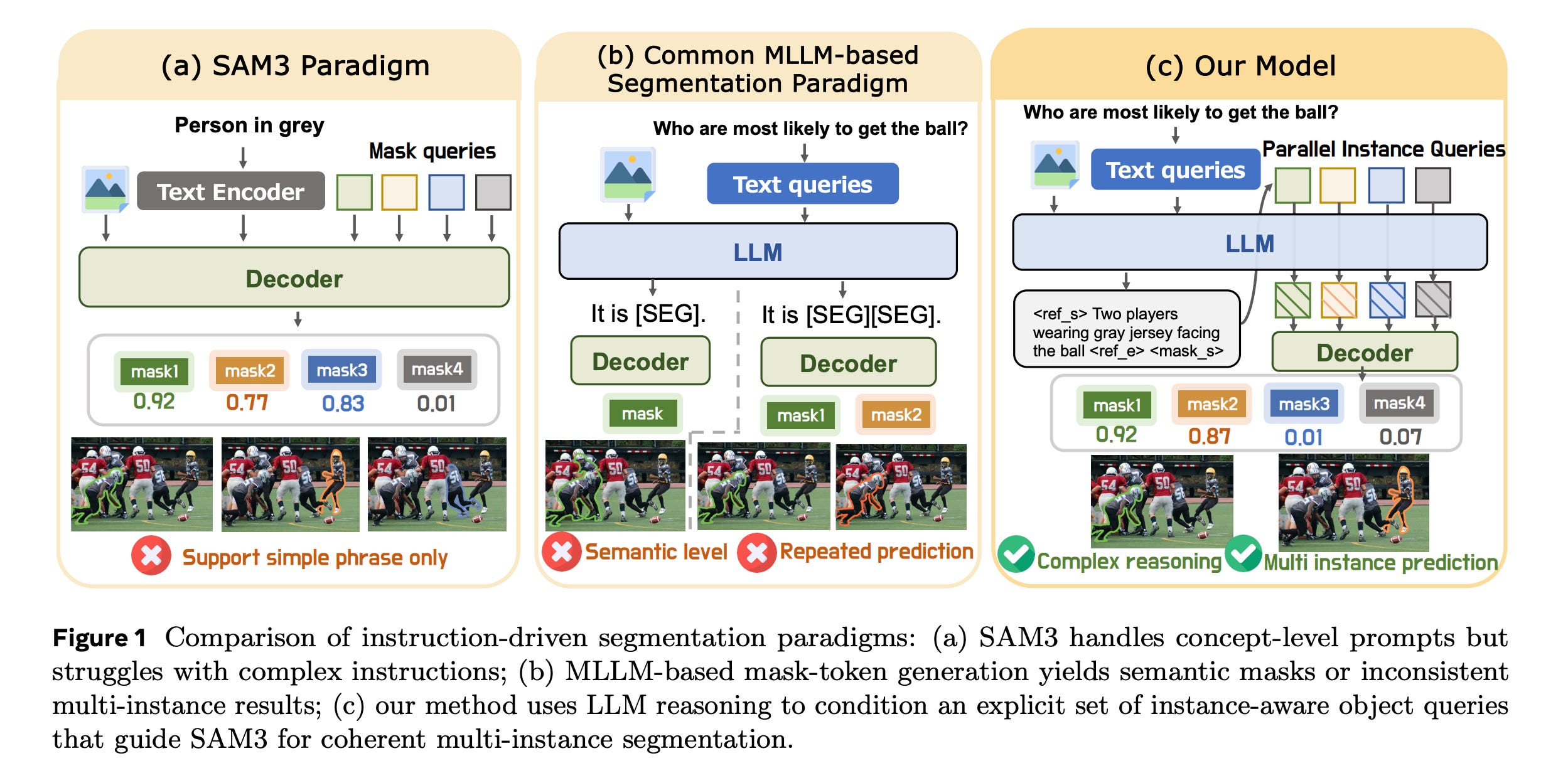
This research paper presents InstructSAM, a 2B vision-language segmentation model that enables users to segment objects using free-form instructions that include attributes, relations, counting, exclusion, or implicit intent, rather than only simple object names.
It connects a VLM to SAM3 using parallel learnable instance queries, enabling it to reason about the instruction and produce multiple instance masks in a single forward pass.
Researchers also introduce Inst2Seg, a large instruction-based segmentation dataset and benchmark consisting of free-form instructions with instance-level masks.
On this benchmark, InstructSAM outperforms previous end-to-end methods and SAM3’s agentic pipeline while being much faster (1.1 seconds inference time compared to 29.6 seconds for SAM3-Agent-Qwen3-VL-2B).
Read more about this research paper using this link.
6. PowLU: An Activation Function for Stable Pre-Training of LLM
SwiGLU is a widely used activation function in LLMs today. For large positive inputs, SwiGLU behaves roughly like the quadratic function x², which gives it strong nonlinearity and expressive capacity.
However, this property also leads to numerical instability as the input or model scale increases, especially in low-precision LLM training, because it widens the output range and worsens outliers.
To address this, this research paper proposes a new activation function called the Power Linear Unit (PowLU) for large-scale LLM pre-training.
PowLU uses a rational power function to achieve adaptive nonlinearity while reducing extreme amplification, making training more stable.
Scaling-law experiments and experiments on the Ling 7.9B and 124B models show that PowLU achieves results competitive with SwiGLU and SwiGLU-Clip, while improving the stability and scalability of large-scale LLM training.
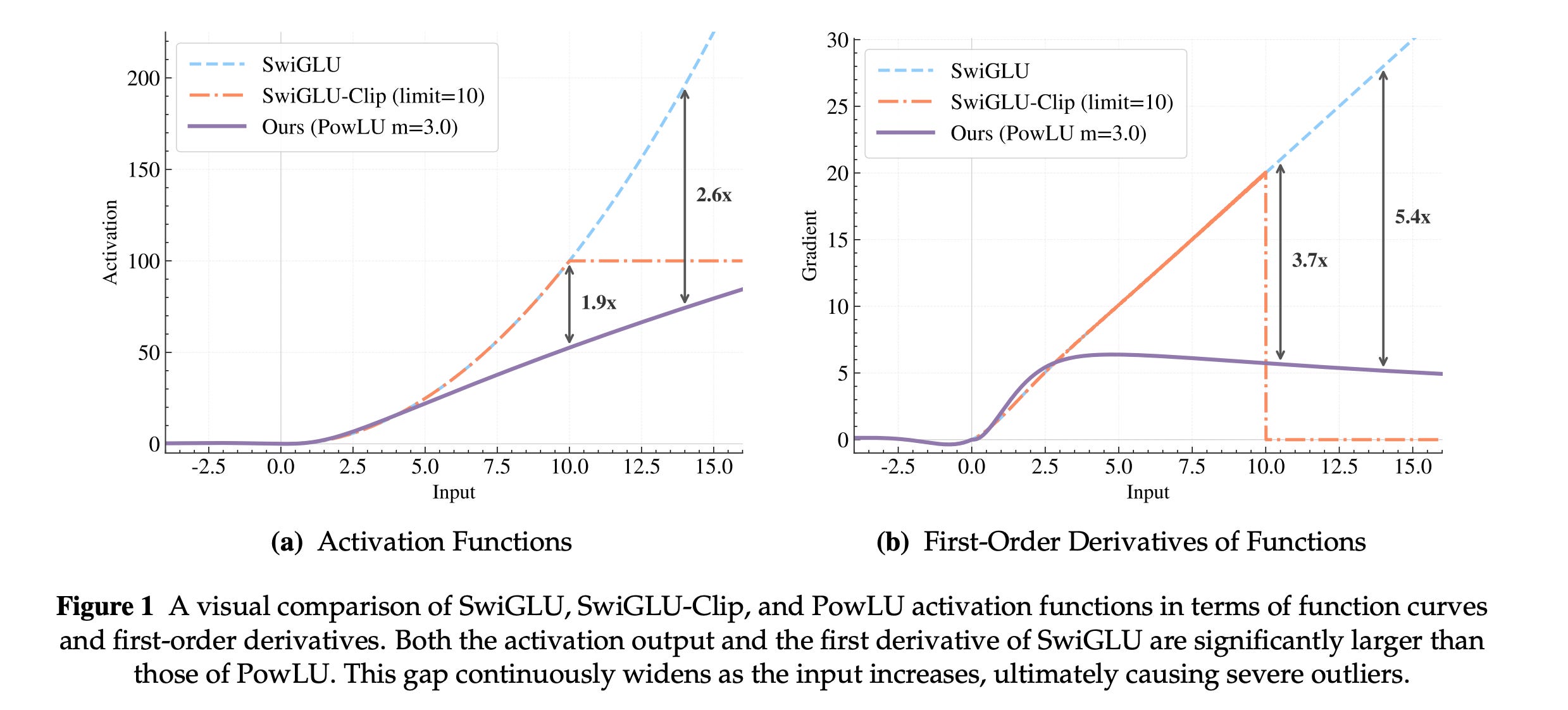
Read more about this research paper using this link.
5. When Does LeJEPA Learn a World Model?
LeJEPA is a self-supervised learning method that combines a predictive alignment loss with Gaussian regularization (SIGReg).
This research paper presents a theory of when LeJEPA captures a representation that truly becomes a world model or a faithful map of the world’s latent structure.
The paper proves that, under Gaussian latent variables, stationary additive-noise transitions, alignment loss, and Gaussian regularization, LeJEPA can identify the true latent variables up to a linear rotation, making the representation useful for planning.
Experiments in toy settings, high-dimensional latent spaces, and pixel-based robotic control support the theory.

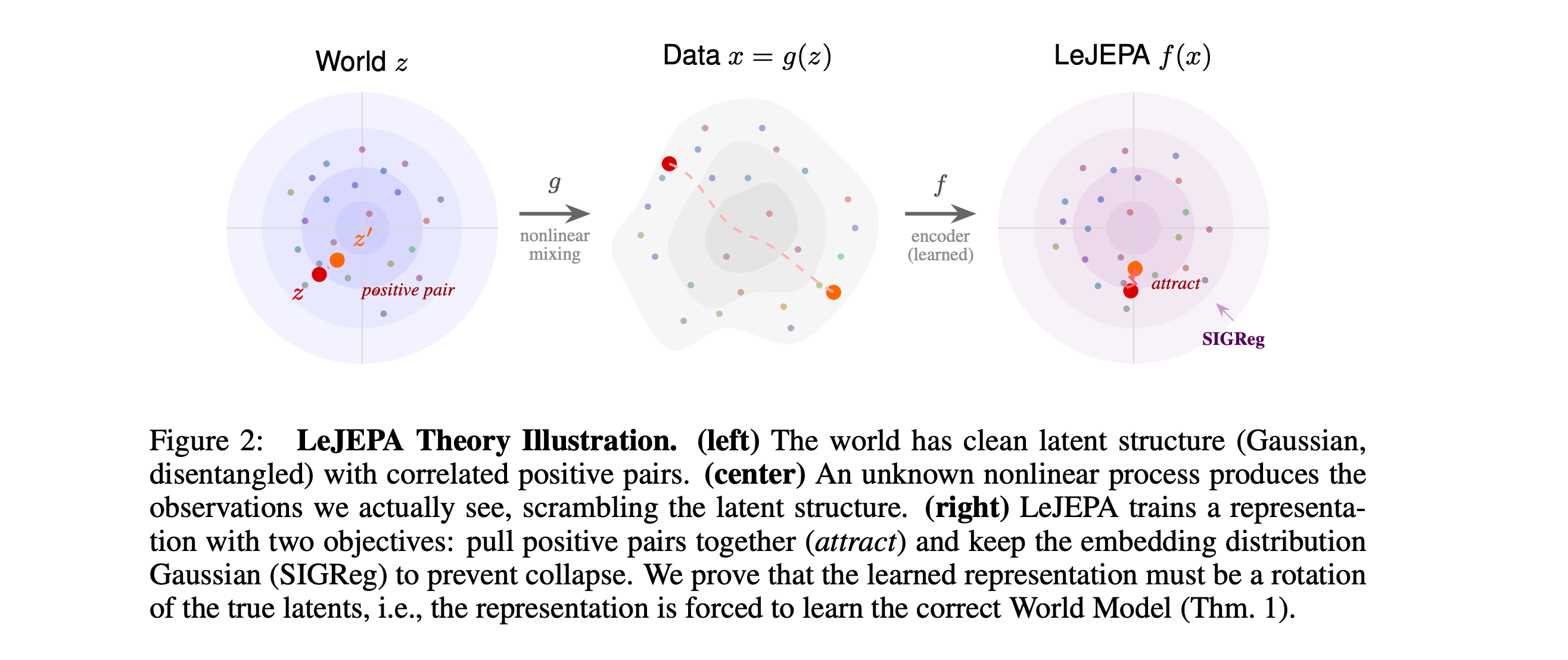
Read more about this research paper using this link.
4. AutoScientists: Self-Organizing Agent Teams for Long-Running Scientific Experimentation
This research paper presents AutoScientists, a decentralized multi-agent system designed for long-running scientific experimentation.
In this system, AI agents share the experimental state, self-organize to form teams around promising hypotheses, critique proposals before using experimental compute, share successes and track failures to prevent repetition, and reorganize as the evidence changes.
This contrasts with existing agentic approaches that either follow a single research trajectory or coordinate through a central planner with fixed objectives.
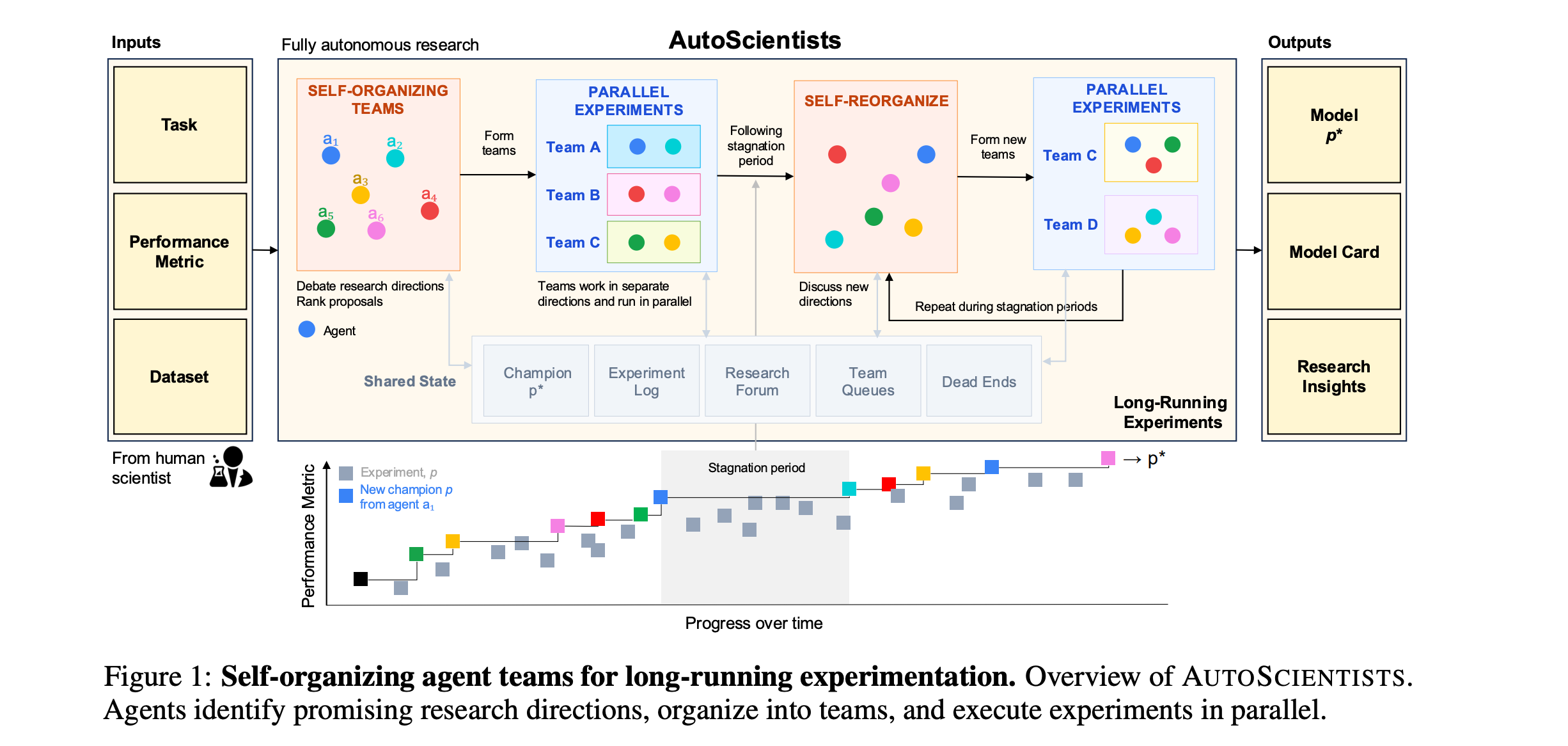
Evals show AutoScientists achieves a mean leaderboard percentile of 74.4% on BioML-Bench, improving over the strongest AI agent by +8.33%.
For GPT training optimization, it reaches a target validation bits-per-byte 1.9x faster than Autoresearch.
It also discovers a method for ACE2-Spike binding that improves over the current SOTA model by +12.5% in Spearman correlation.
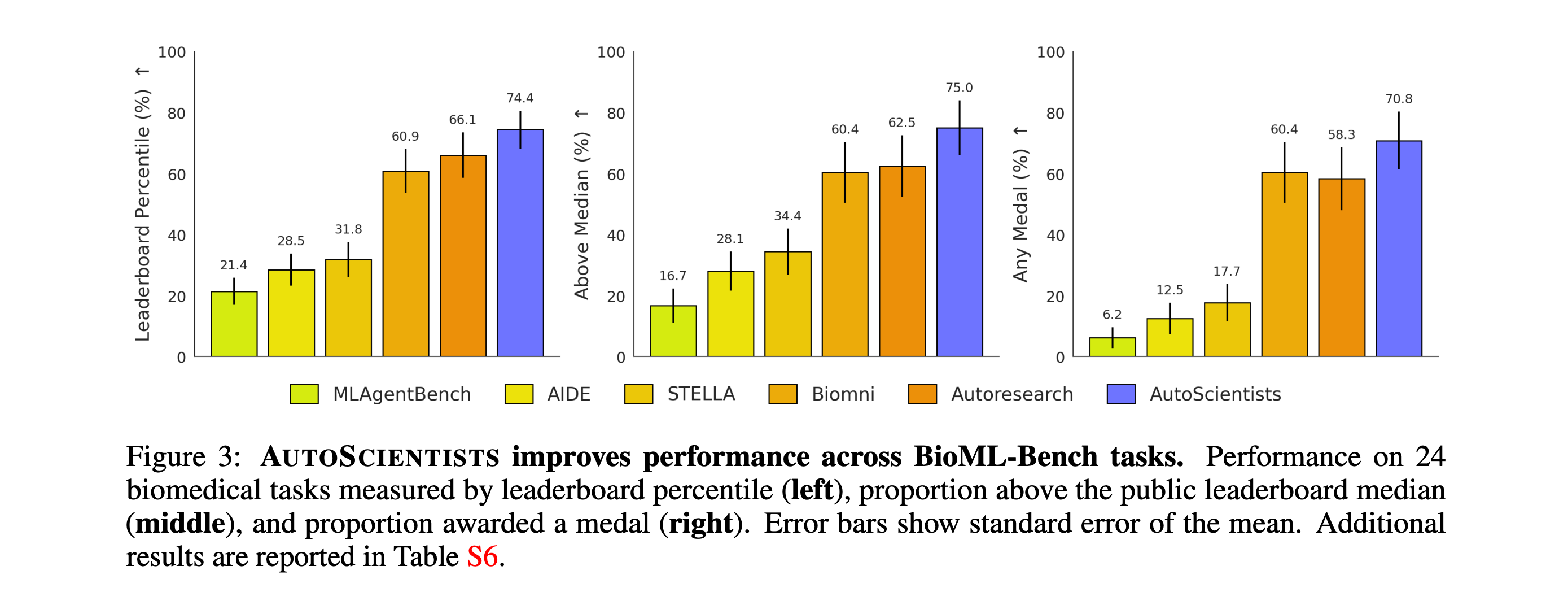
Read more about this research paper using this link.
3. SIA: Self-Improving AI with Harness & Weight Updates
This research paper introduces SIA, a self-improving AI framework in which a language-model agent (the Feedback-Agent) improves both the agent harness and the model’s weights using LoRA/RL updates.
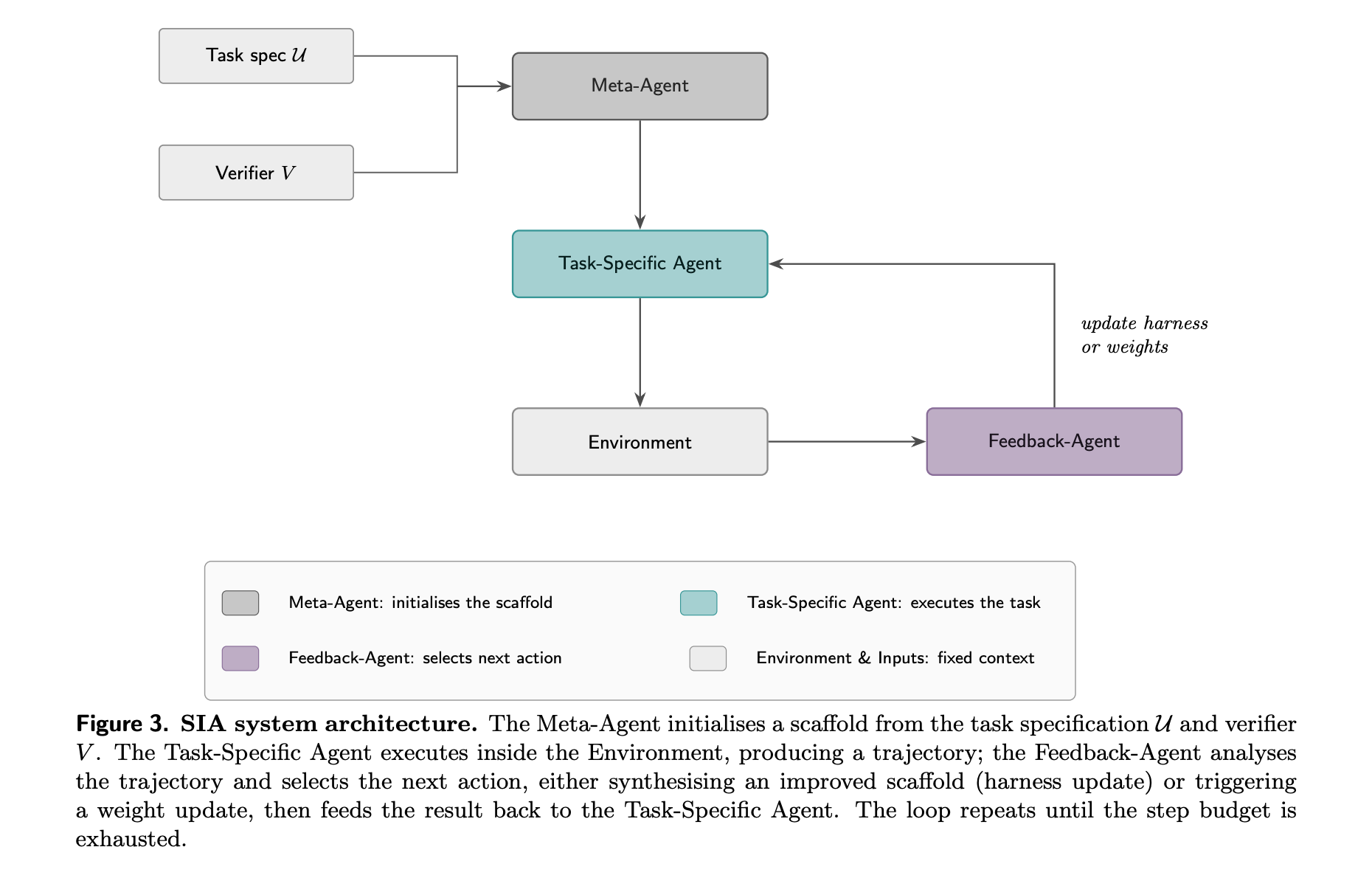
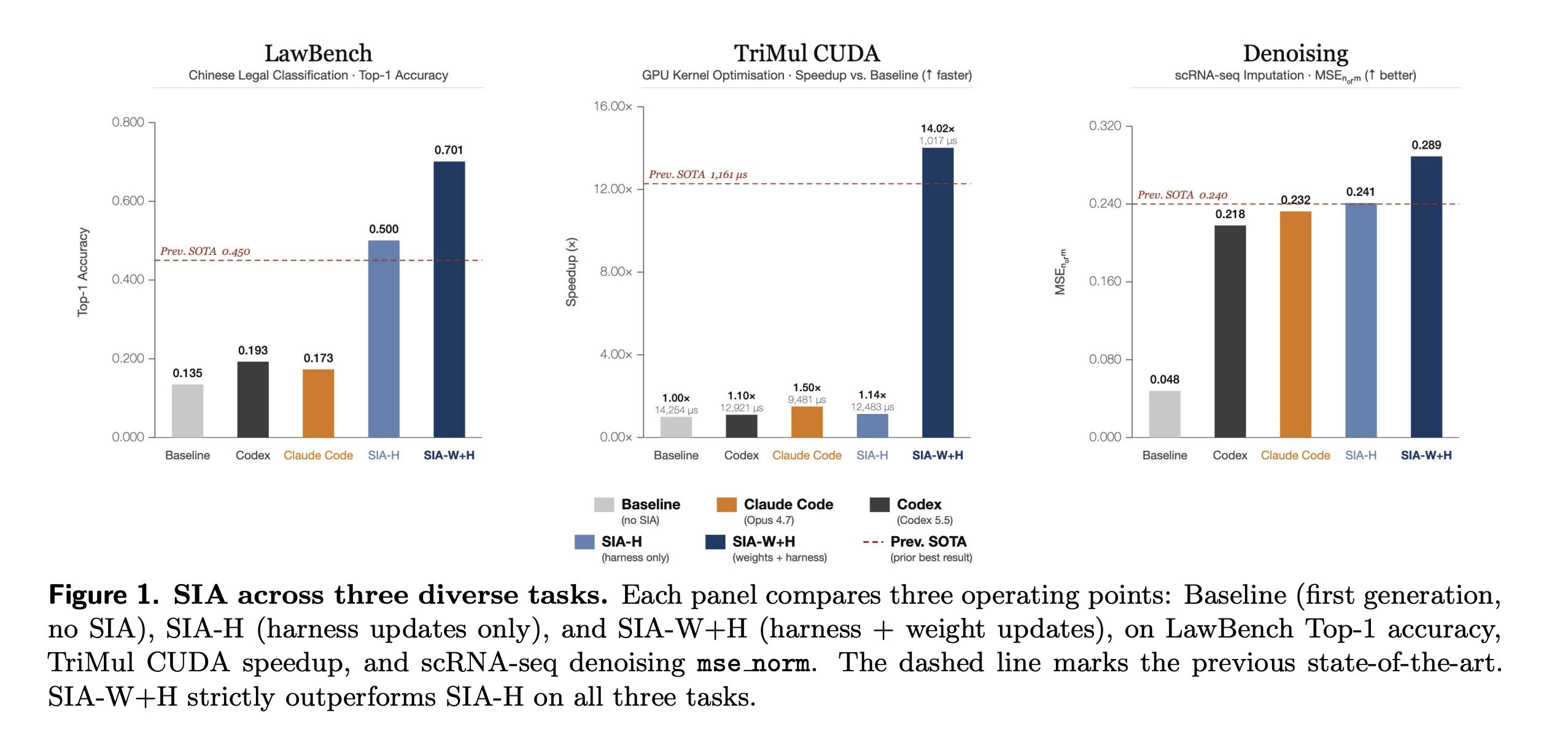
In Chinese legal charge classification, low-level GPU kernel optimization, and single-cell RNA denoising tasks, SIA-W+H (combined weight and harness updates) works better than the approach that only improves the harness (SIA-H).
SIA-W+H achieves 25.1% over prior SOTA on LawBench, 12.4% faster GPU kernels than prior SOTA, and 20.4% over prior SOTA on denoising.
Read more about this research paper using this link.
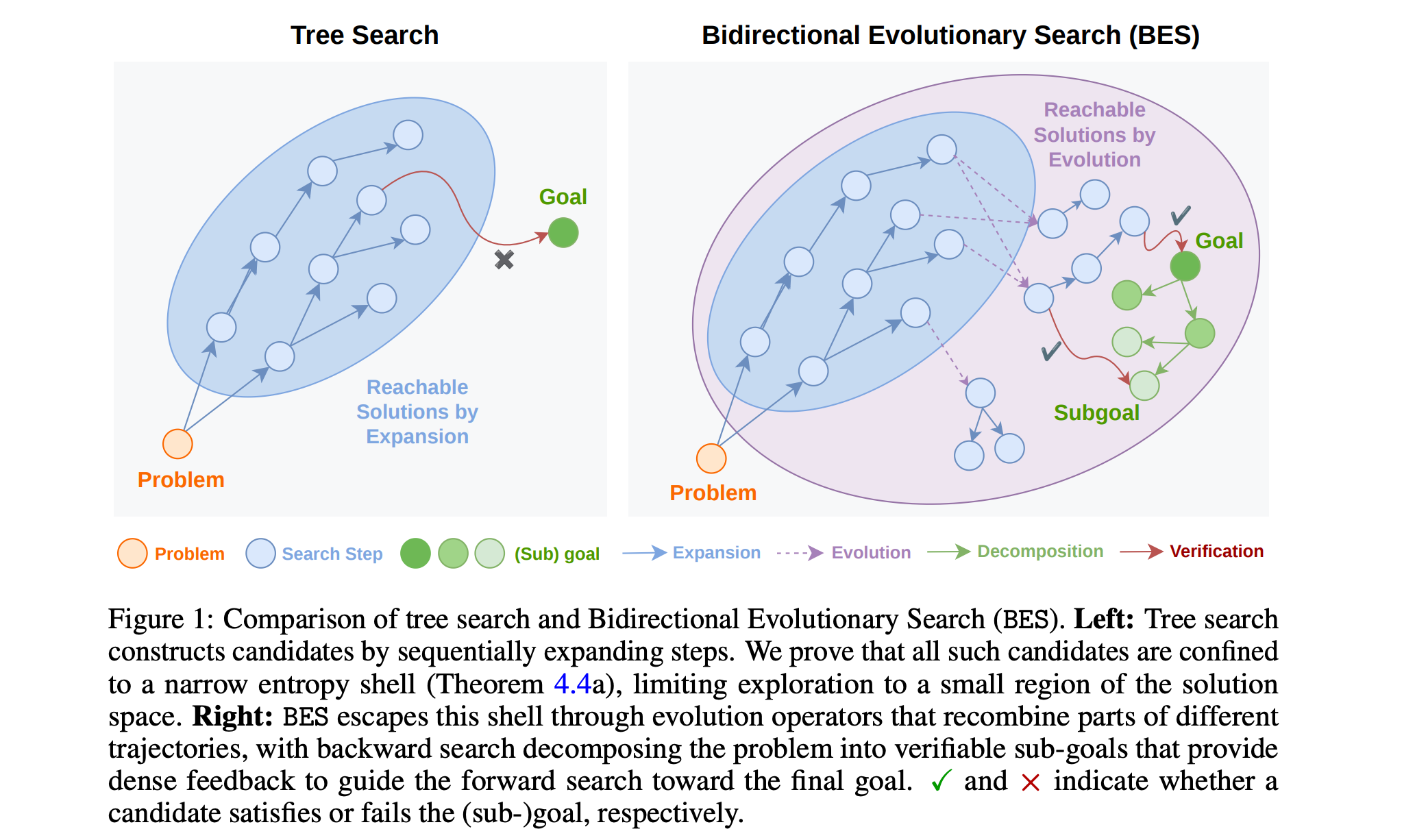
2. Self-Improving Language Models with Bidirectional Evolutionary Search
This research paper introduces Bidirectional Evolutionary Search (BES), a search framework for self-improving LLMs and agentic systems for post-training sample generation and inference.
Commonly used methods such as best-of-N sampling and tree search have limitations because they rely on sparse verification signals and primarily explore high-probability candidates constructed through autoregressive expansion.
BES addresses this issue using:
Forward evolutionary search, which augments standard expansion with evolution operators that recombine partial trajectories to generate candidates that are difficult to obtain from a single model rollout
Backward goal decomposition, which divides tasks into checkable subgoals, producing dense intermediate feedback that guides forward search
Theoretically, this approach increases exploration and can exponentially reduce the number of required samples to find a correct answer, leading to consistent improvements on tough post-training tasks and open problem-solving benchmarks.
Read more about this research paper using this link.
1. Introducing Claude Opus 4.8
Anthropic released Claude Opus 4.8, their new flagship model, with improvements across benchmarks compared to their previous models and competitors.
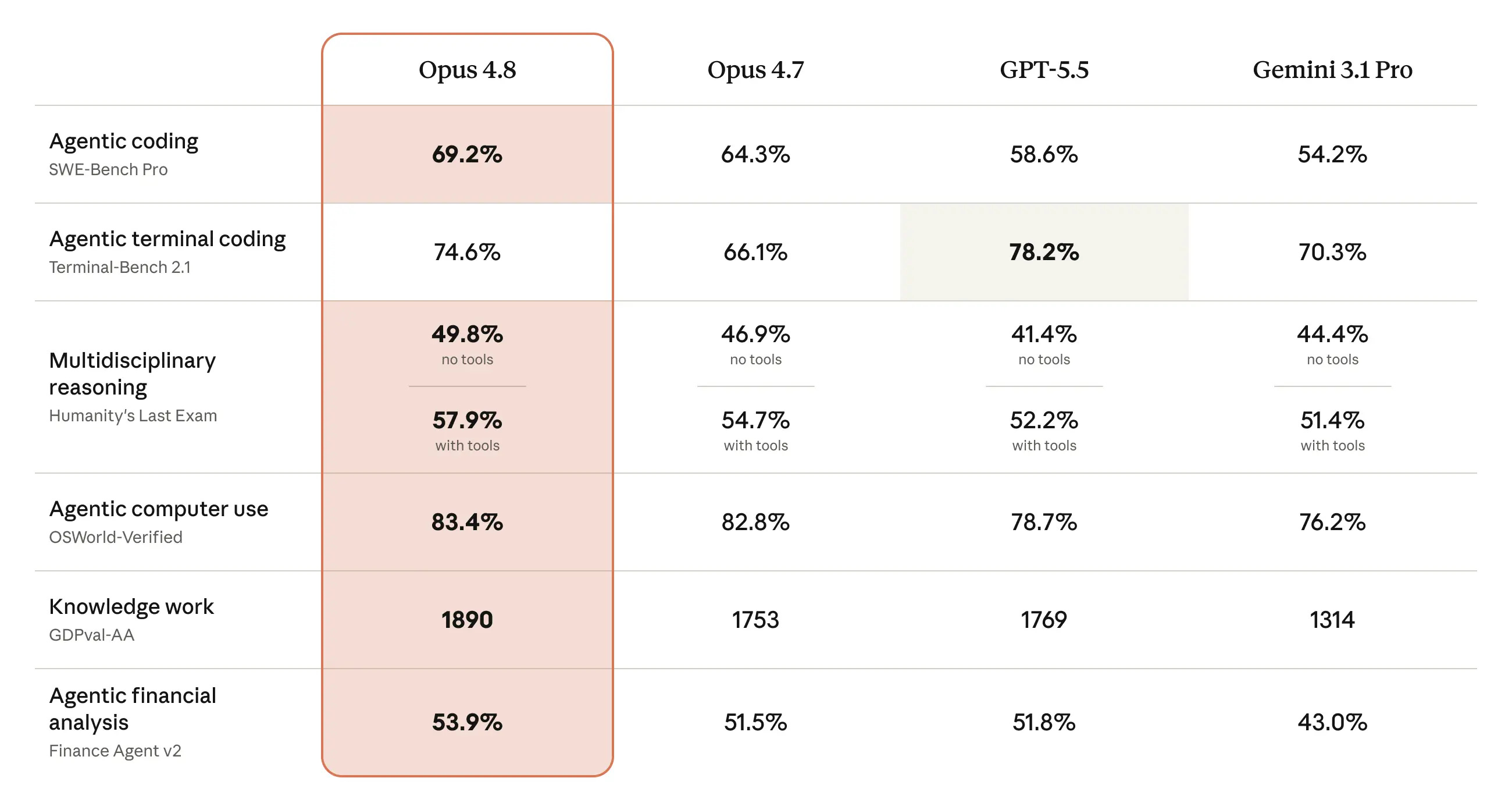
One of the most prominent improvements in Opus 4.8 is its honesty. Opus 4.8 is less likely to make unsupported claims and is about 4X less likely than its predecessor to let flaws in code it has written go unremarked.
Opus 4.8’s rates of misaligned behavior (such as deception or cooperation with misuse) are substantially lower than Opus 4.7's and are similar to those of Anthropic’s best-aligned model, Claude Mythos Preview.
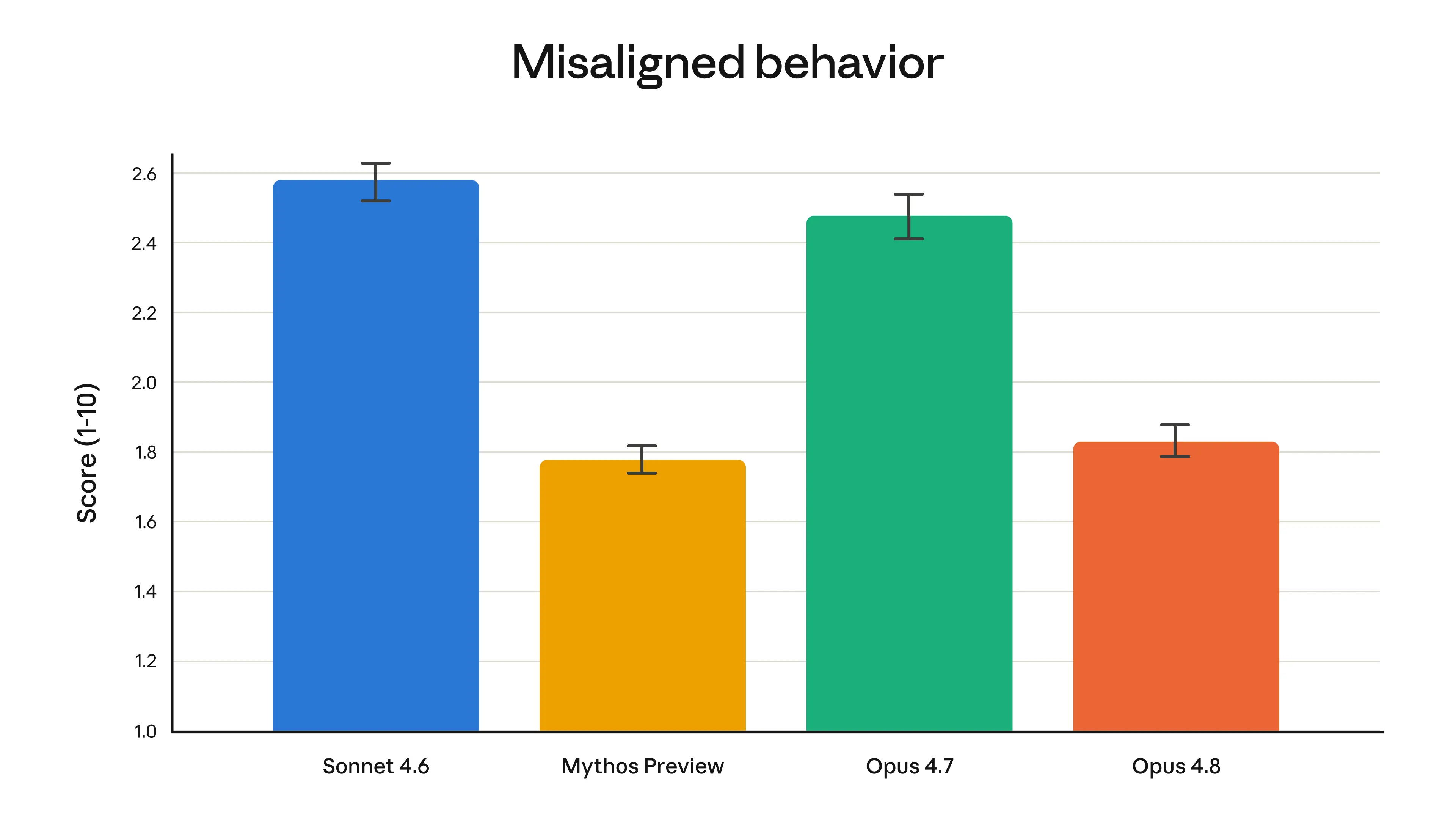
It also comes with a fast mode (where the model can work at 2.5× the speed), which is 3X cheaper than it was for previous models.
Read more about this release using this link.
This newsletter edition is completely free to read. Show your love by liking it, restacking it, and sharing it with others! ❤️