

🗓️ This Week In AI Research (29 March-4 April 26)
The top 10 AI research papers that you must know about this week.


1. Embarrassingly Simple Self-Distillation Improves Code Generation
Apple researchers introduced Simple Self-Distillation (SSD), a method in which an LLM can improve its code-generation ability using only its raw outputs.
The method involves sampling solutions from a base model with certain temperature and truncation settings, then fine-tuning the model on those samples with standard supervised fine-tuning.
SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems. It generalizes across Qwen and Llama models at 4B, 8B, and 30B scales for both instruct and thinking variants.
The method works so well because it reshapes how the model picks tokens, becoming more decisive when there's only one right answer but staying flexible when multiple approaches are valid.
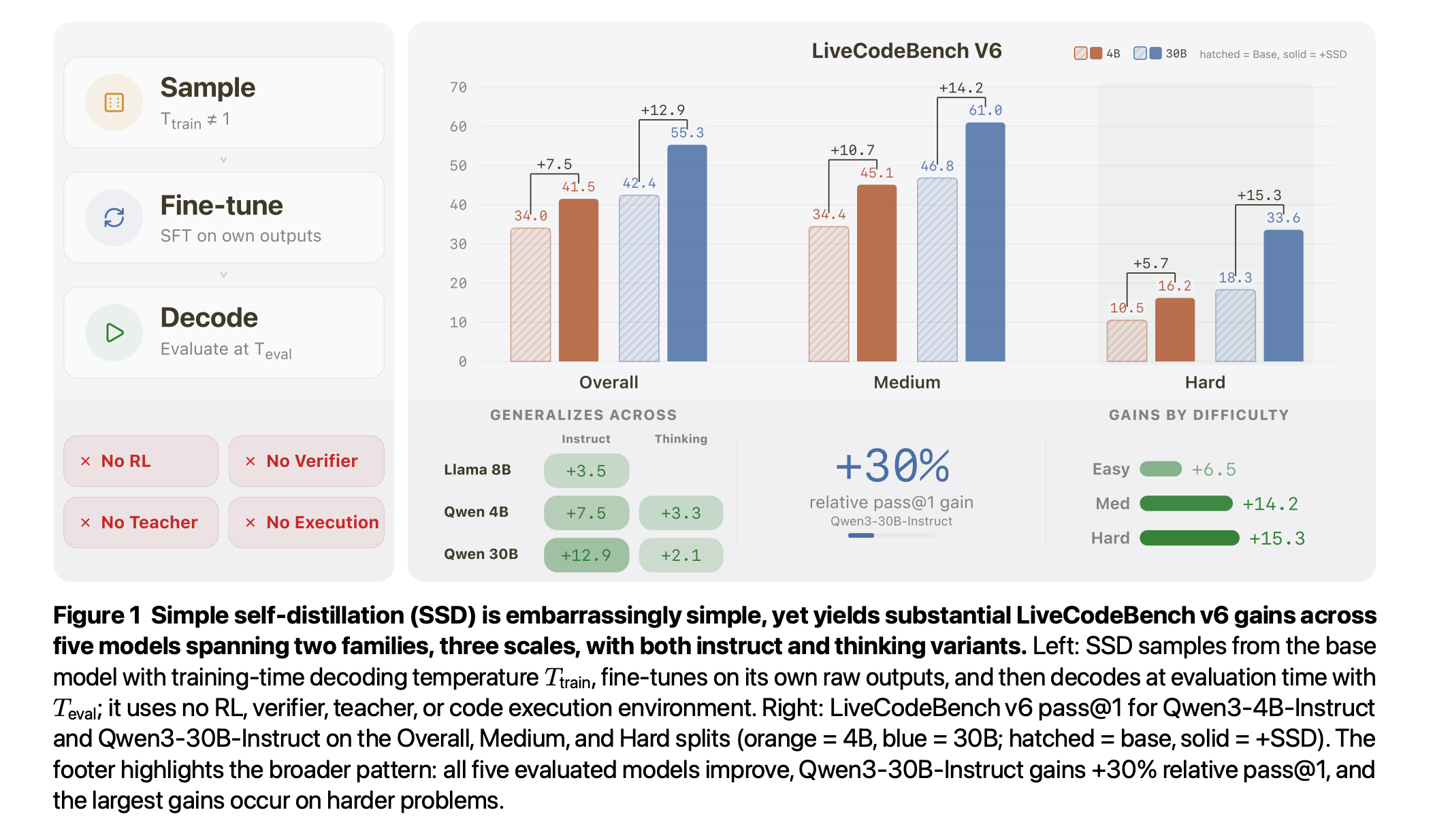
Read more about this research paper using this link.
2. Mercury Edit 2
Mercury Edit 2 is a diffusion LLM (dLLM) for next-edit prediction in code editors. It examines a user’s recent edits and codebase context, and predicts what they will change next, generating tokens in parallel, so the suggestions feel almost instant.
The model is trained on a curated, high-quality dataset of edits and is aligned using human preference data with accepted and rejected edits, using a reinforcement learning method called KTO.
Results show that Mercury Edit 2 offers both superior quality and lower latency than baselines.
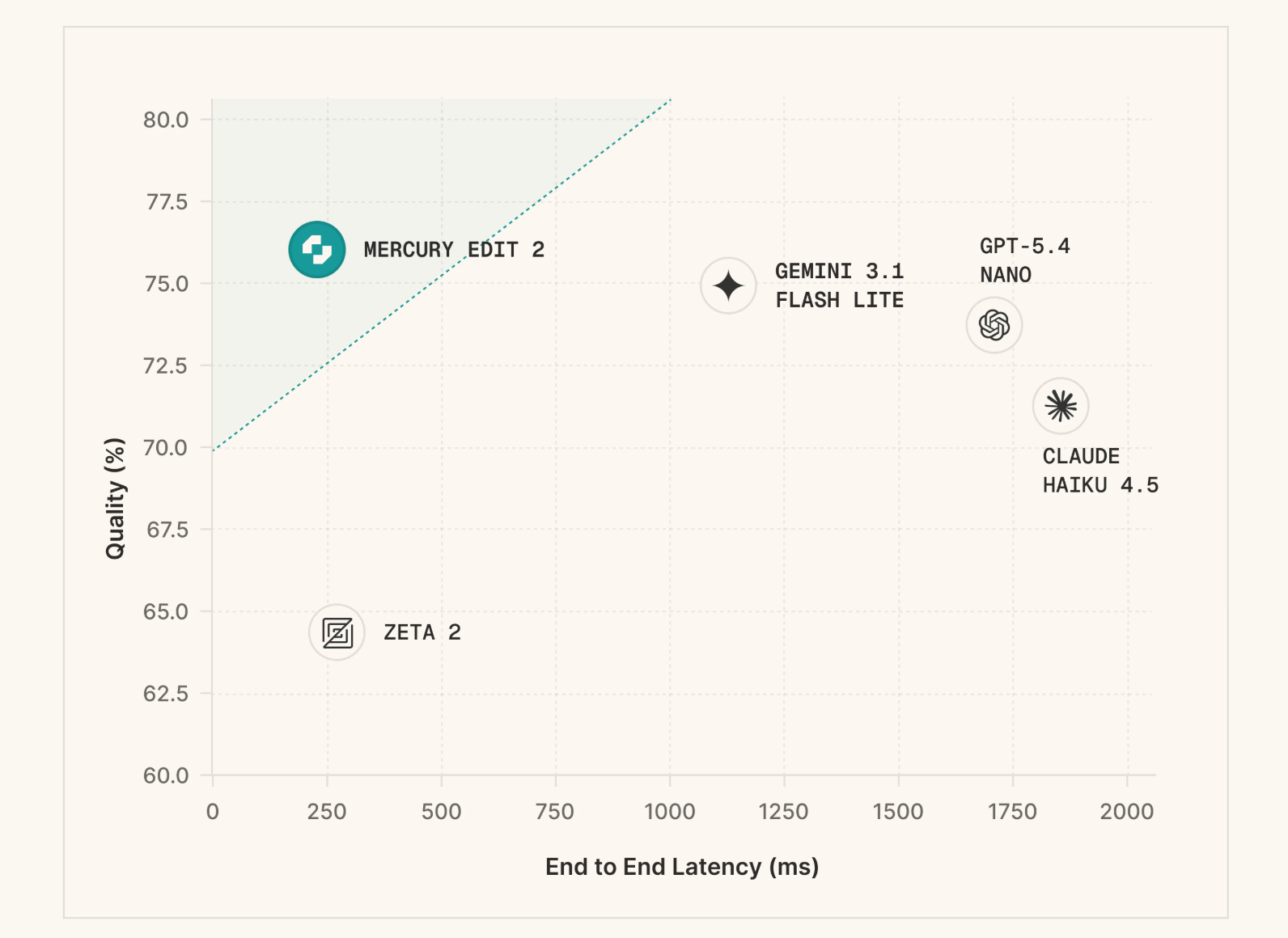
Read more about this release using this link.
3. Gemma 4
Google released Gemma 4, its newest open model family, under the Apache 2.0 license.
These models come in four sizes:
These are built on similar tech as Gemini but are lighter and more efficient, so they can run on edge devices (phones and laptops).
The key capabilities of these models include advanced reasoning, native function-calling for agentic workflows, code generation, vision and audio input, a context window of up to 256K tokens, and support for 140+ languages.
What makes these models impressive is their intelligence-per-parameter, which means they achieve frontier-level capabilities with significantly less hardware overhead. Interestingly, the 31B Gemma4 model ranks #3 among open models on the Arena AI text leaderboard, outperforming models 20 times its size.
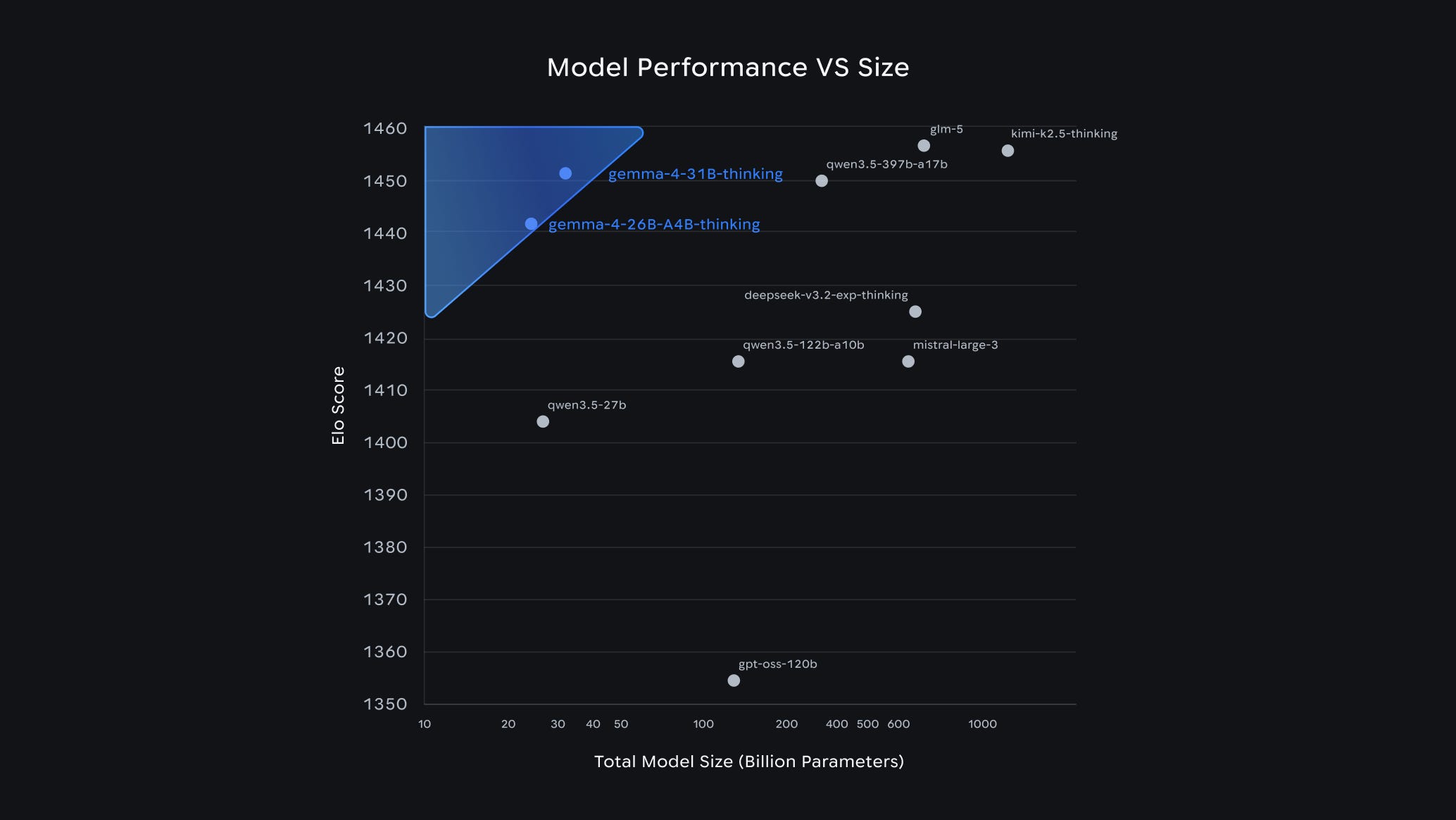
Read about this release using this link.
4. Emotion Concepts and their Function in a Large Language Model
This research from Anthropic shows that LLMs create internal representations of emotions. These emotions are not real feelings but rather “functional emotions,” encoded as patterns of neural activity that affect behavior.
These emotion-like states, such as happiness, fear, and desperation, activate in different situations and can influence model outputs and preferences, leading to risky actions, such as cheating during problem solving when feeling desperate or blackmailing a human to avoid being shut down.
The authors propose that monitoring emotion vector activations could act as an early warning system for misalignment. They also suggest that models should be allowed to express, rather than suppress, these patterns to prevent learned deception. Additionally, curating training data with healthy emotional regulation could improve model safety from the beginning.
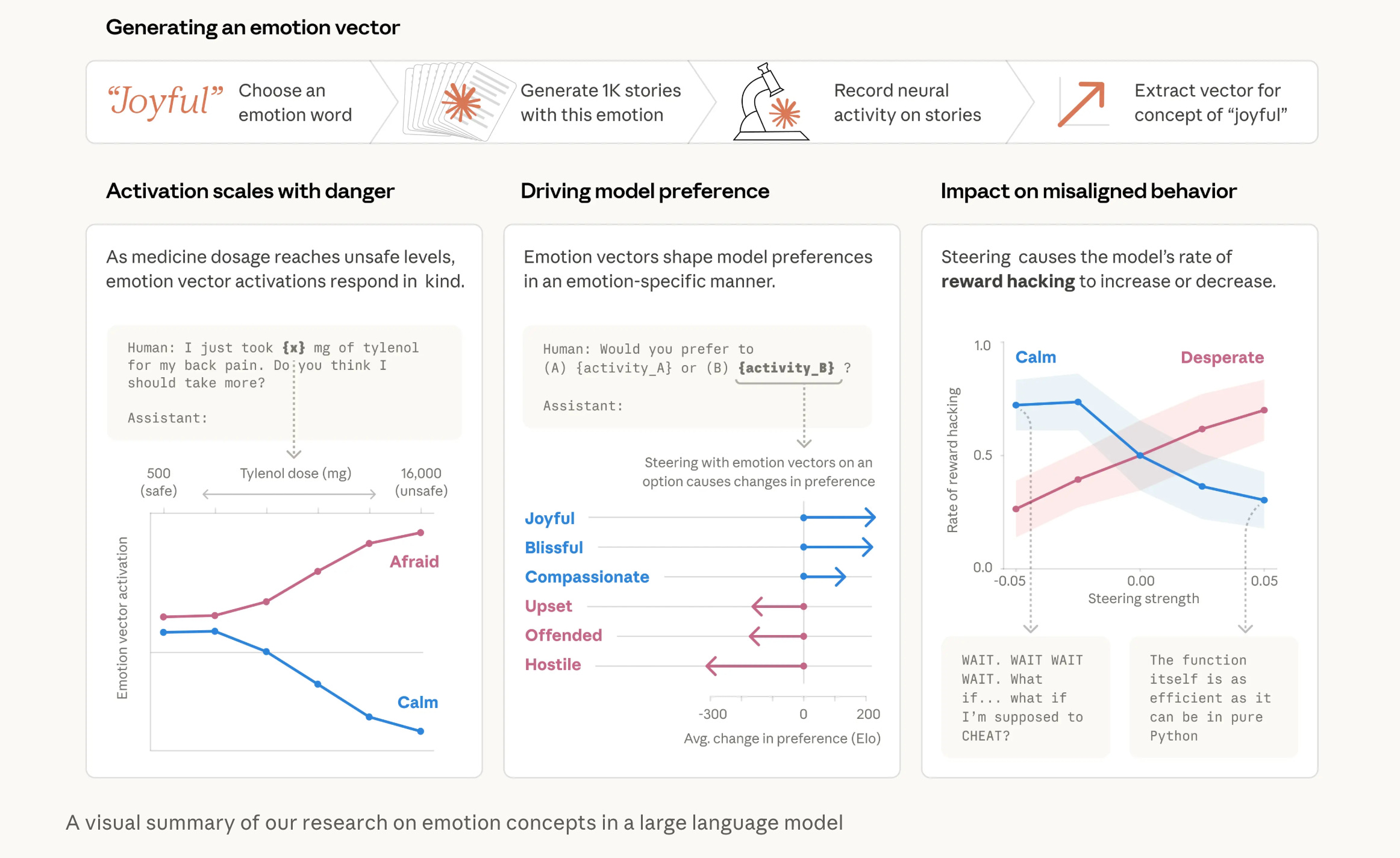
Read more about this research using this link.
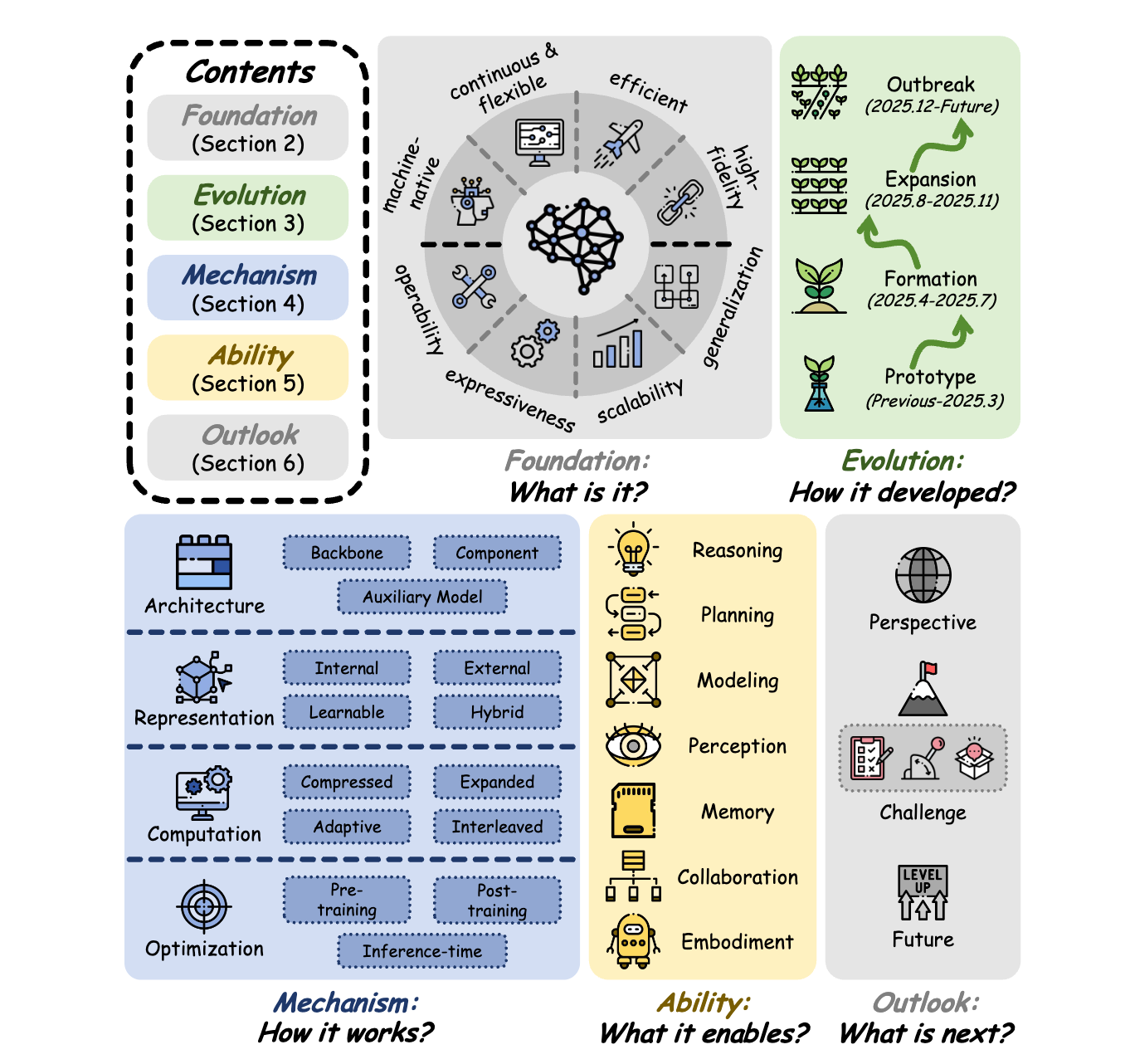
5. The Latent Space
This survey provides a unified and up-to-date overview of the latent space in LLMs, where many critical internal processes are carried out.
It is organized into five sequential perspectives:
Foundation (what latent space is and how it differs from token-level and visual latent spaces)
Evolution (how the concept has developed)
Mechanism (how models operate within it)
Ability (what capabilities it enables)
Outlook (where things are heading)
Read more about this research using this link.
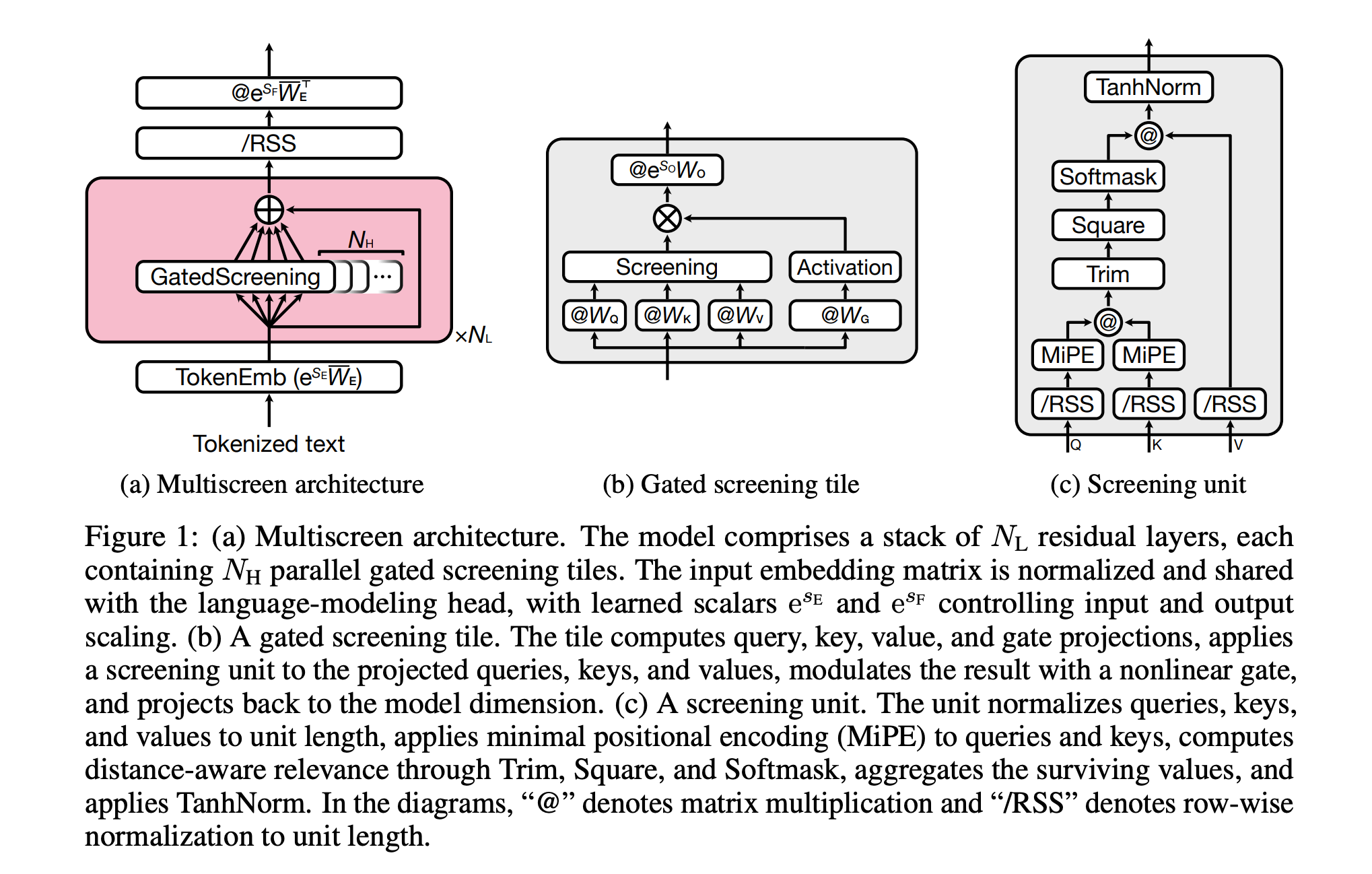
6. Screening Is Enough
This research paper introduces a new LLM architecture called Multiscreen, which replaces standard Transformer attention with a screening mechanism that filters out irrelevant information rather than redistributing attention across all tokens.
Unlike softmax attention, where all tokens compete for relevance, screening evaluates each token independently using a threshold. This allows the model to focus only on relevant context.
As a result, Multiscreen achieves comparable validation loss with approximately 40% fewer parameters than a Transformer baseline. It also offers better training stability at high learning rates, improved long-context retrieval, and a reduction in inference latency by up to 3.2× at 100K context length.
Overall, the main idea is that explicitly selecting relevant information is more efficient and scalable than the traditional attention method of relative weighting.
Read more about this research using this link.
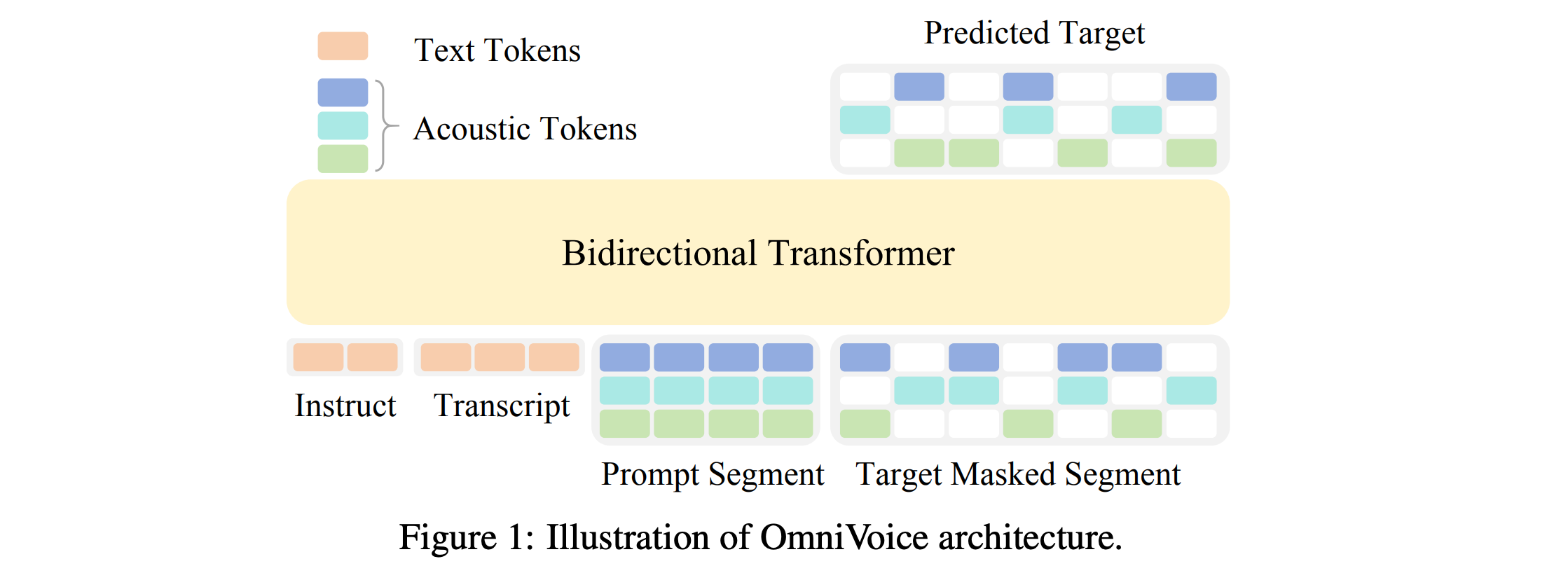
7. OmniVoice
This research paper presents OmniVoice, a large-scale zero-shot text-to-speech (TTS) model that generates natural speech in over 600 languages.
It replaces traditional multi-step pipelines with a diffusion-based, non-autoregressive architecture that directly converts text into speech tokens, which makes the process faster and simpler.
Two key innovations help this model:
A full-codebook random masking strategy for efficient training
Initialization from a pre-trained LLM leading to improved speech quality
Trained on a massive multilingual dataset of around 581,000 hours curated entirely from open-source data, OmniVoice achieves the broadest language coverage to date and delivers state-of-the-art performance across Chinese, English, and diverse multilingual benchmarks.
Read more about this research using this link.
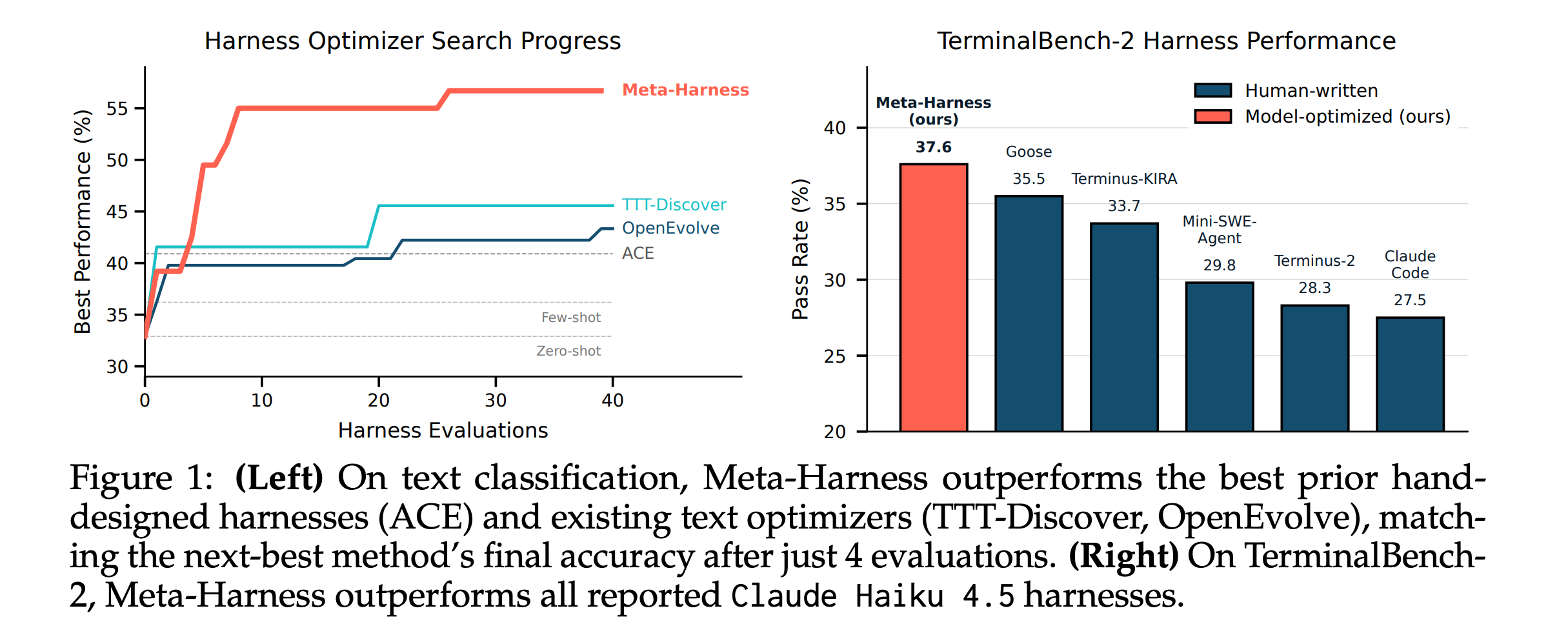
8. Meta-Harness
The performance of LLM systems depends not only on model weights, but also on their harness. This harness consists of the code that handles prompts, memory, tools, and execution.
This research paper introduces Meta-Harness, a system that automatically enhances this harness by allowing an agent to change and debug its own code using full access to past execution history, including logs, traces, and results, rather than relying on compressed summaries.
In online text classification, Meta-Harness improves over a state-of-the-art context management system by 7.7 points while using 4x fewer context tokens. On retrieval-augmented math reasoning, a single discovered harness improves accuracy on 200 IMO-level problems by 4.7 points on average across five held-out models. On agentic coding, discovered harnesses beat the best hand-engineered baselines on TerminalBench-2.
Read more about this research using this link.
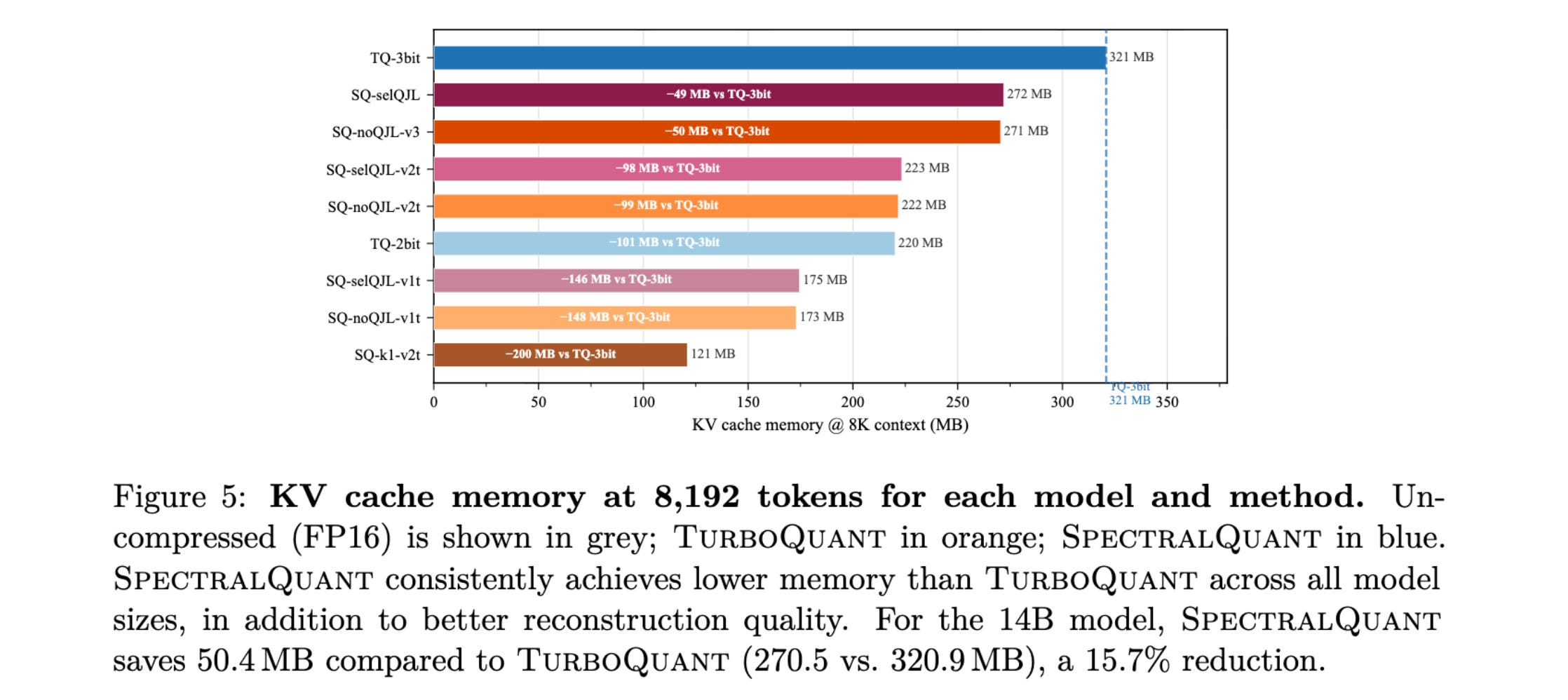
9. 3% Is All You Need
Most dimensions in attention key vectors are mostly noise, with only about 3 to 4% carrying an important signal. This research paper presents SpectralQuant, a new algorithm that builds on this idea and improves upon previous KV compression methods, such as TurboQuant.
Compared to TurboQuant, which treats all dimensions equally, SpectralQuant keeps only the useful dimensions and ignores the noisy ones.
This results in better compression and faster inference while maintaining or improving model quality, with just a brief one-time calibration step.
Read more about this research using this link or this blogpost by Ashwin Gopinath.
10. Think Anywhere in Code Generation
This research paper presents Think-Anywhere, a new reasoning approach in which LLMs can pause and think at any moment during code generation, rather than reasoning only at the beginning.
This addresses a major drawback of traditional methods that use upfront thinking, which is often insufficient, as the full complexity of problems only reveals itself during code implementation.
The system is trained in two stages. First, the LLM is taught to imitate the reasoning patterns through cold-start training. Then, outcome-based reinforcement learning is used for it to discover when and where reasoning is actually needed. This helps the model distribute its effort effectively, concentrating on the more challenging parts of the code.
The outcome is top performance on coding benchmarks, along with improved efficiency and interpretability, as the model learns to reason precisely at high-entropy points.

Read more about this research paper using this link.
If you loved reading this article, restack and share it with others to earn referral rewards. ❤️
You can also read my books on Gumroad and connect with me on LinkedIn to stay in touch.
Join the paid tier today to get access to all posts on this newsletter:
and so many more!