

🗓️ This Week In AI Research (8-14 March 26)
The top 10 AI research papers that you must know about this week.


1. Covenant-72B
This research paper presents Covenant-72B, an LLM produced by the largest globally distributed collaborative pre-training run to date, in terms of both compute and model scale.
This pre-training involved open, permissionless participation, supported by a live blockchain protocol, Bittensor, and a state-of-the-art, communication-efficient optimizer called SparseLoCo, which enabled dynamic participation with peers joining and leaving freely.
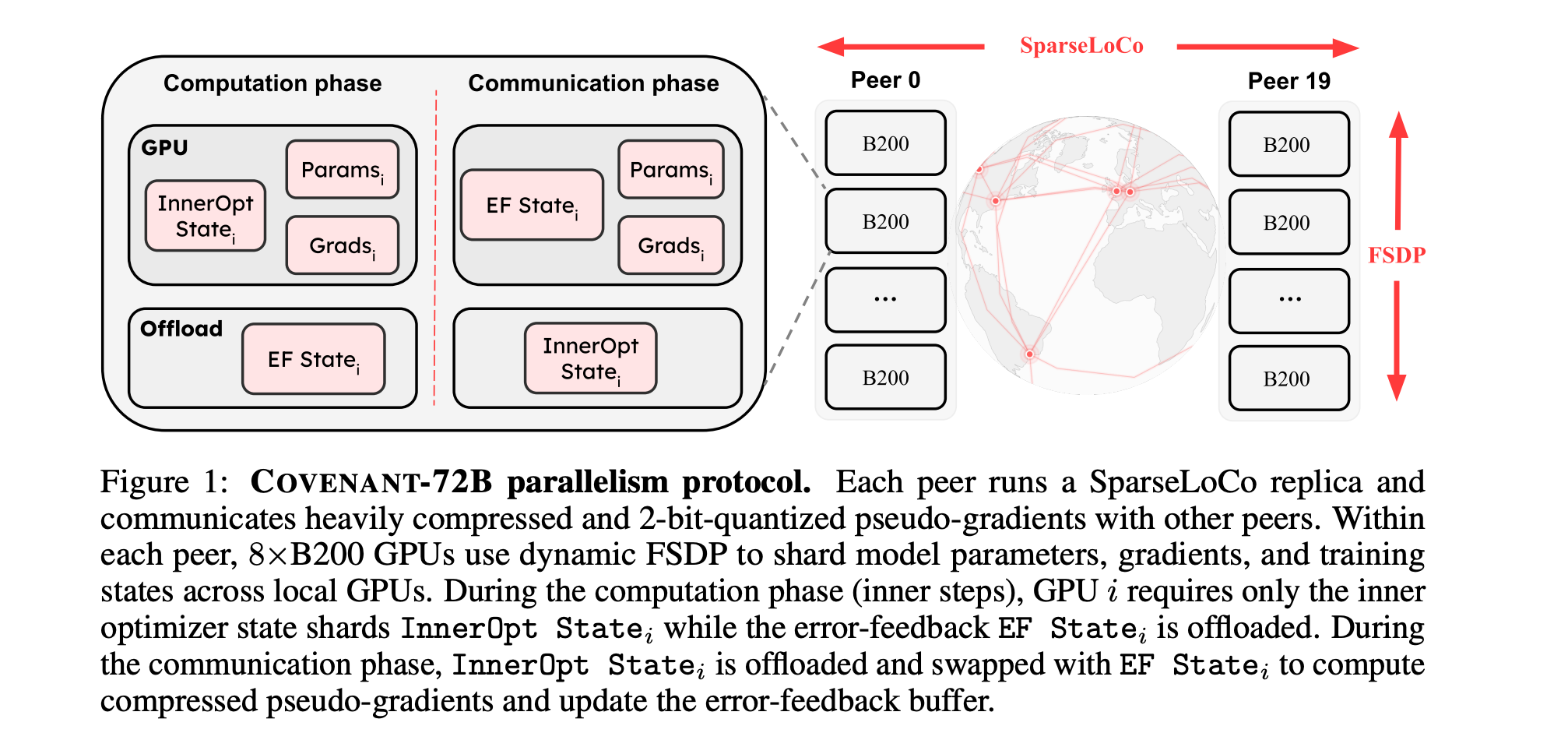
Covenant-72B was pre-trained on approximately 1.1T tokens and performs at par with fully centralized models pre-trained on similar or higher compute budgets.
This shows that open and fully democratized participation is possible on an unprecedented scale for a globally distributed LLM pre-training run.
Read more about this research using this link.
🎁 Unlock every lesson in the newsletter and accelerate your AI engineering career with a 25% discount on the annual membership of ‘Into AI’ today!
2. Training Language Models via Neural Cellular Automata
Natural LLM pre-training data has its flaws, as it is finite, contains human biases, and mixes knowledge with reasoning.
This research paper proposes using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs, which means training on synthetic data first, followed by natural language.
This is because NCA data has a rich spatiotemporal structure and statistics that resemble natural language, while being controllable and cheap to generate at scale.
Pre-pre-training is surprisingly effective, and training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x.
This approach of using NCA even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute, and the gains transfer to reasoning benchmarks, such as GSM8K, HumanEval, and BigBench-Lite.
Further experiments show that attention layers transfer best, and that optimal NCA complexity depends on the task, with simpler dynamics working better for code, while more complex ones benefit math and web text more.

Read more about this research using this link.
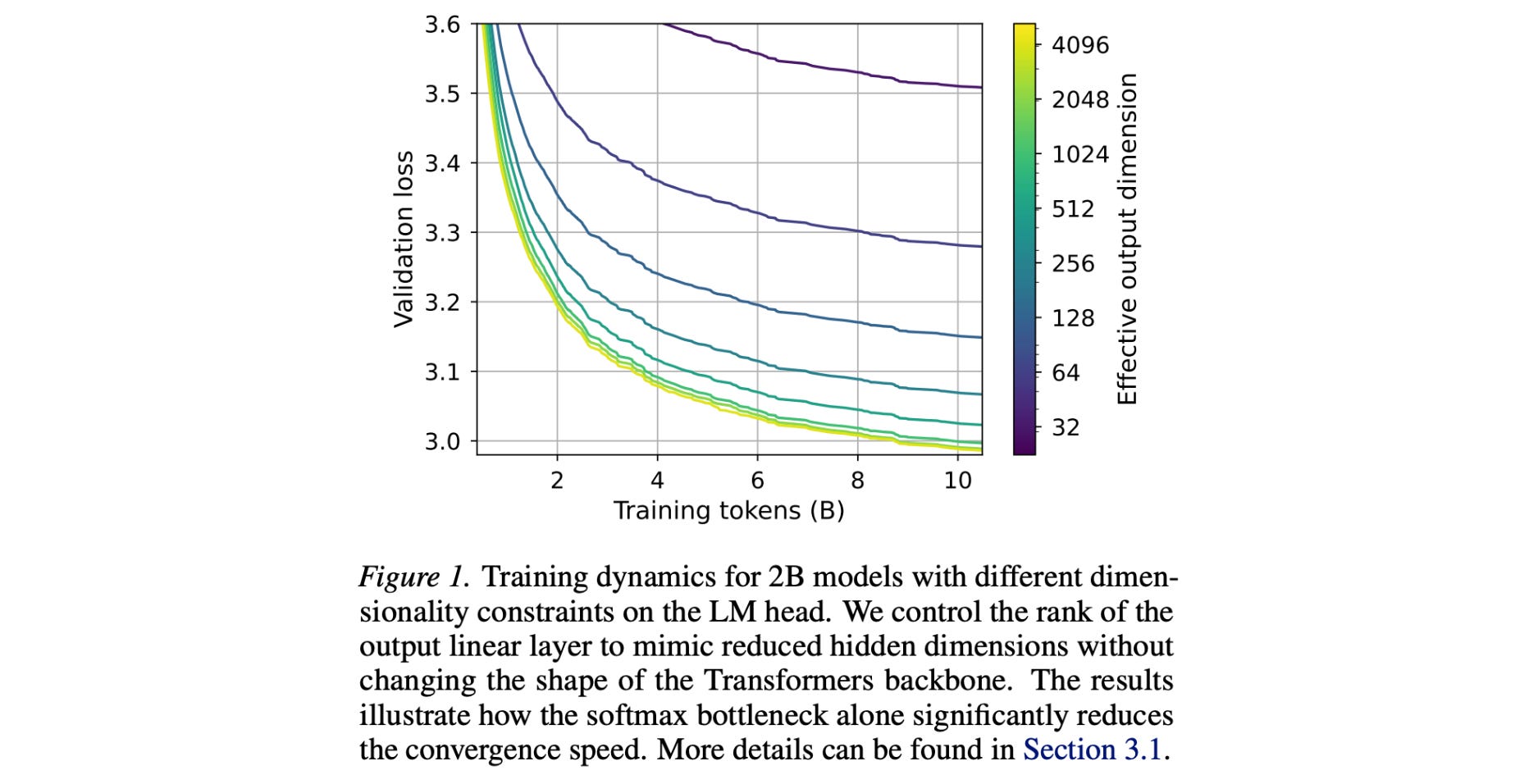
3. Lost in Backpropagation: The LM Head is a Gradient Bottleneck
The final layer of LLMs, called the LM head, maps the hidden dimension (D) to the vocabulary dimension (V), where usually D is very small as compared to V. This creates an expressivity limitation called the Softmax bottleneck.
This research paper shows that the softmax bottleneck is not only an expressivity bottleneck but also an optimization bottleneck where high-dimensional gradients are compressed into a much smaller space, leading to most of the training signal (around 95–99% of the gradient norm) getting lost.
This leads to poor update directions and makes even simple patterns harder to learn, slowing down training and harming efficiency across models.
The research suggests that current LLM architectures have a fundamental flaw in how they learn and that better LM head designs are needed.
Read more about this research using this link.
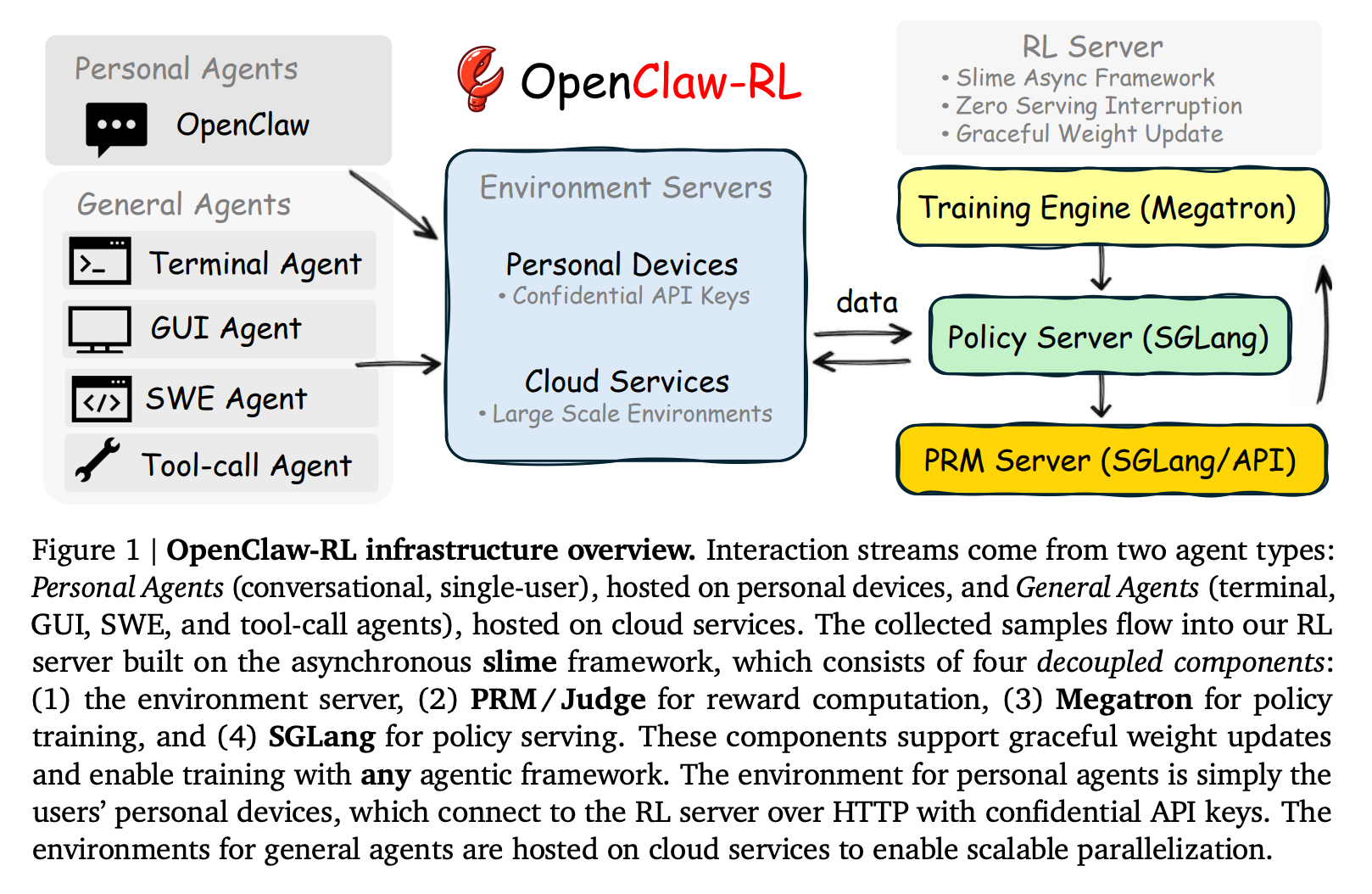
4. OpenClaw-RL: Train Any Agent Simply by Talking
This research paper presents OpenClaw-RL, a reinforcement learning framework in which AI agents learn continuously from real-time interactions, using next-state signals (such as user replies, tool outputs, or environment changes) as training data.
These signals offer evaluative feedback (how well an action is performed, expressed as scalar rewards via a PRM judge) and directive feedback (how the action should be improved, expressed as textual hints and used for token-level supervision via Hindsight-Guided On-Policy Distillation, or OPD).
By blending these, OpenClaw-RL supports more effective learning than traditional methods.
Its asynchronous, decoupled architecture also allows agents to improve during live use in various environments, such as chat, tools, and software tasks, without requiring offline datasets or manual labeling.
Read more about this research using this link.
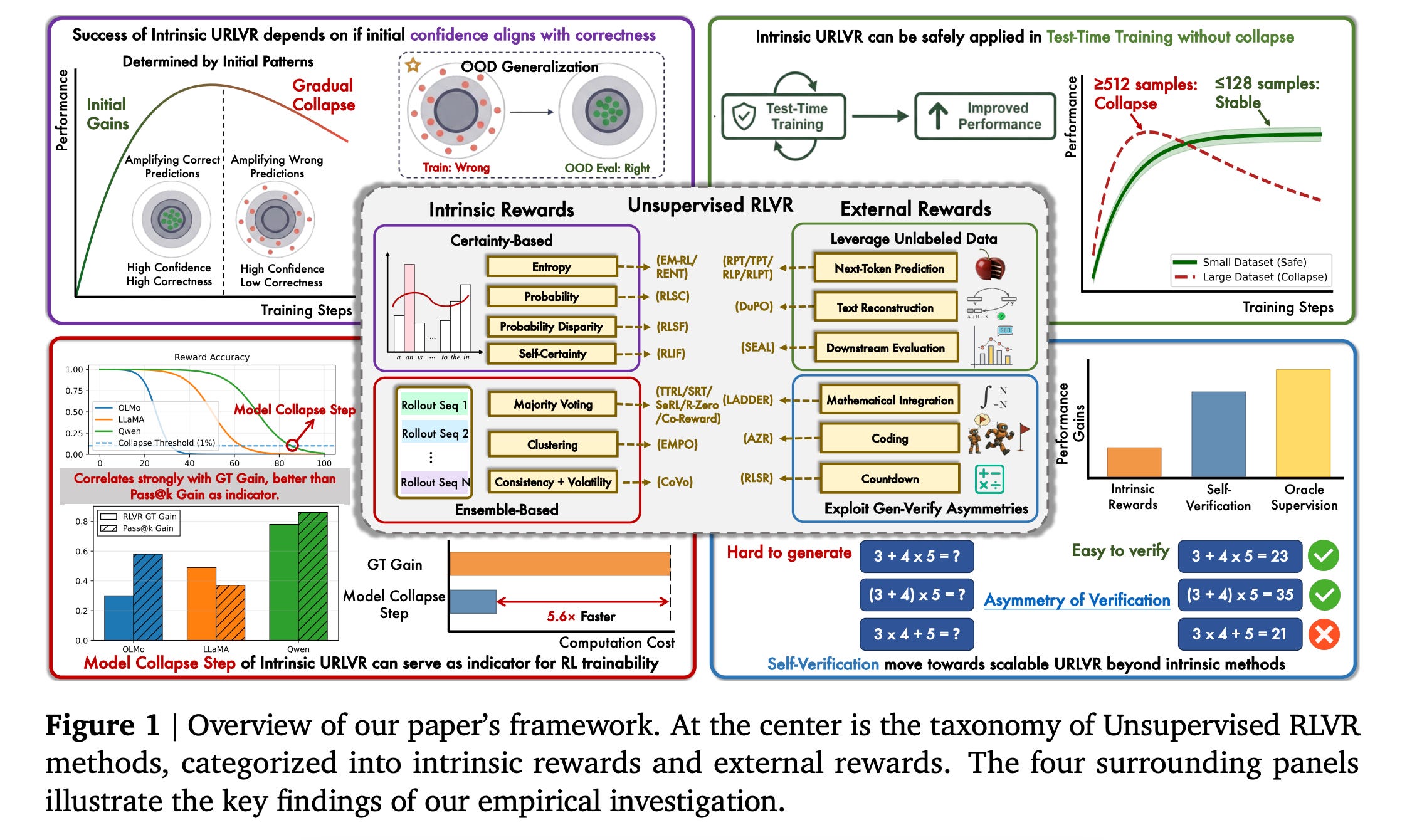
5. How Far Can Unsupervised RLVR Scale LLM Training?
This research paper studies a training approach called Unsupervised Reinforcement Learning with Verifiable Rewards (RLVR), in which models learn without labeled data by generating their own rewards from signals that can be automatically verified.
The paper categorises RLVR methods into intrinsic (self-generated rewards) and external (externally verified rewards), and shows that intrinsic methods mainly strengthen a model’s existing beliefs and work only if those beliefs are already correct, but can lead to collapse if they are wrong.
While intrinsic rewards still help with test-time training on small datasets, the authors propose the Model Collapse Step, which acts as a practical indicator for RL trainability (predicting when training will fail).
They also present early evidence that external reward methods may overcome these limitations, suggesting more scalable approaches.
Read more about this research using this link.
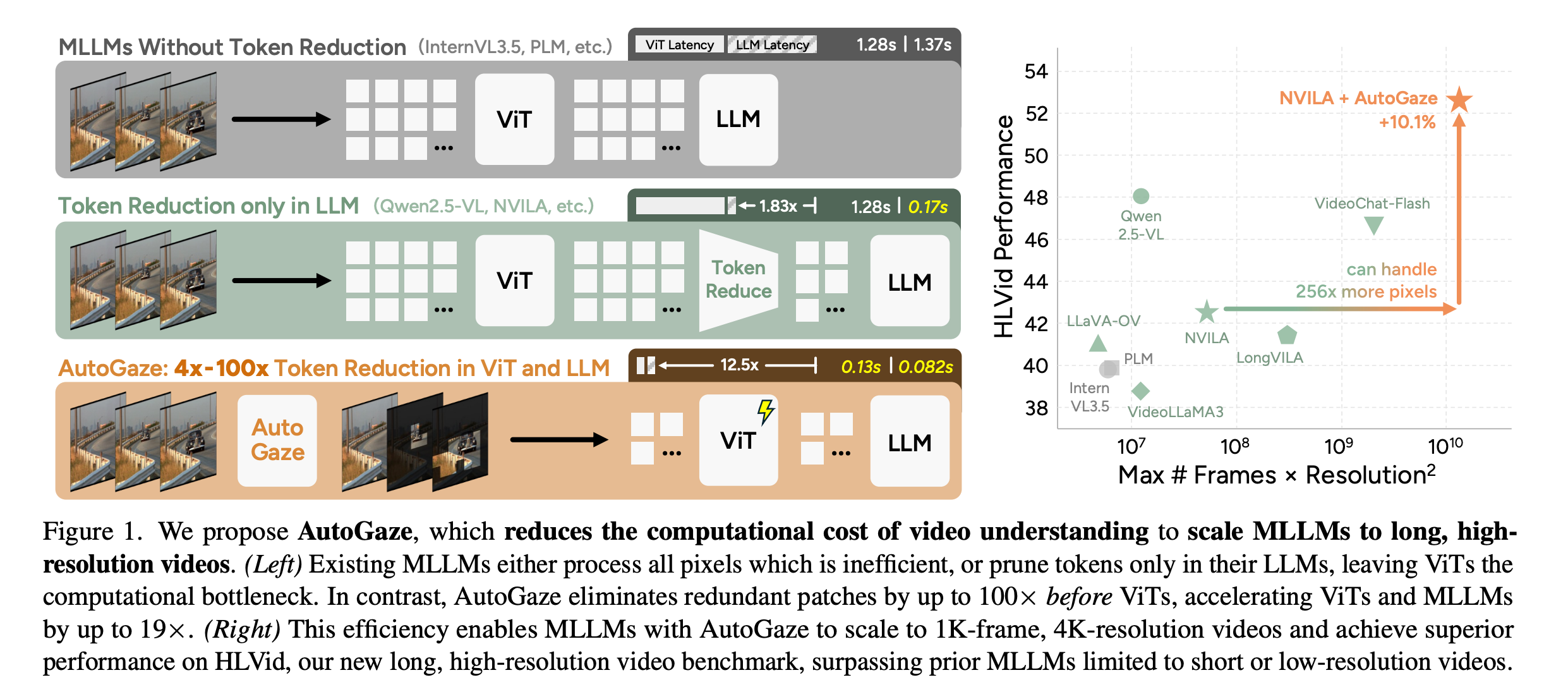
6. Attend Before Attention
This research paper introduces AutoGaze for multi-modal LLMs (MLLMs), an efficient method for processing videos by selectively focusing on important regions (like human gaze) before applying full attention, rather than analyzing every pixel equally.
Such gazing lets the model ignore unnecessary or static information, enabling faster, easier-to-scale video understanding while maintaining high performance.
Experiments show that this approach greatly increases efficiency (higher processing FPS) and allows for real-time video processing, offering a practical way to scale multimodal models to longer or streaming video inputs.
Read more about this research using this link.
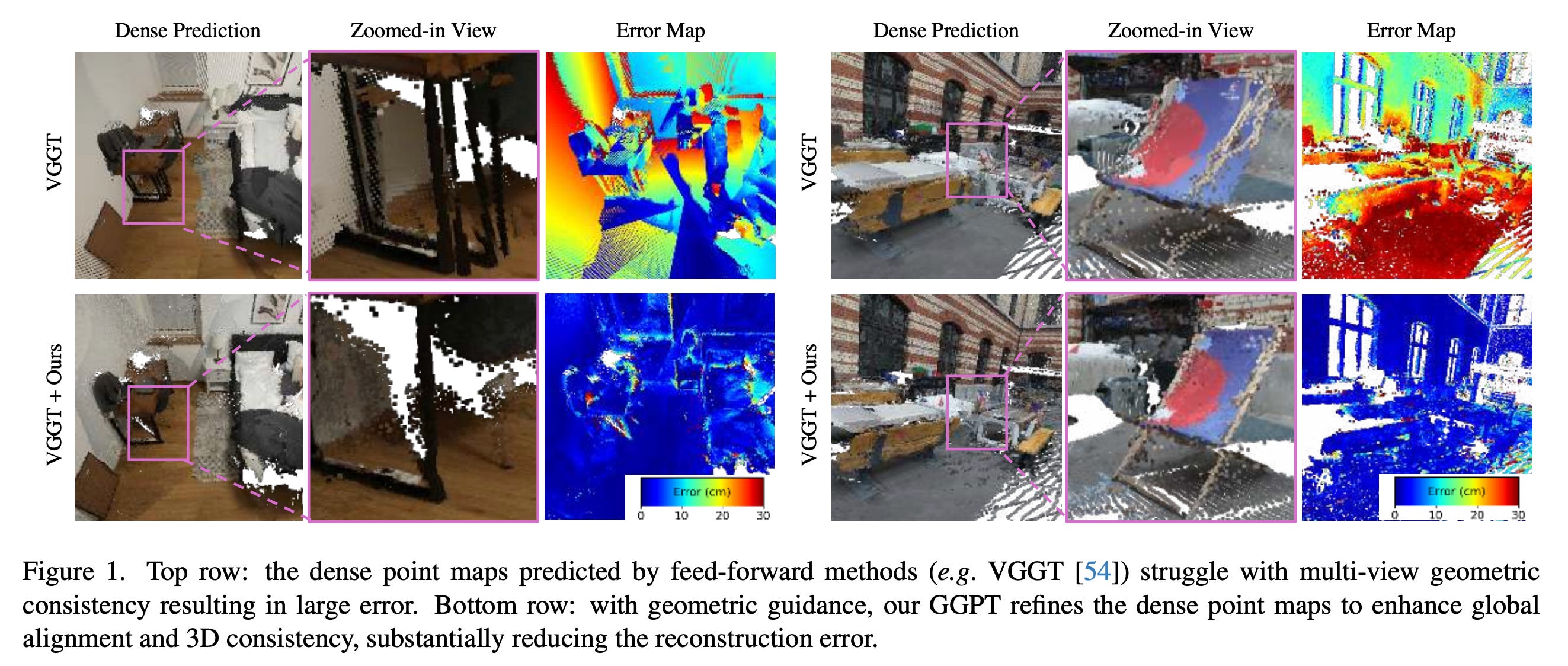
7. Geometry-Grounded Point Transformer
Feed-forward networks suffer from geometric inconsistencies and achieve only limited fine-grained accuracy in 3D reconstruction (i.e., predicting dense point maps directly from RGB images).
This research paper introduces the Geometry-Grounded Point Transformer (GGPT), a method for improving 3D reconstruction from images by combining fast neural predictions with explicit geometric guidance.
It uses an improved Structure-from-Motion pipeline to estimate accurate camera poses and partial 3D structure from sparse input views, and then uses a Geometry-guided 3D point transformer to refine dense point maps under explicit partial-geometry supervision using an optimised guidance encoding.
Experiments show that GGPT produces reconstructions that are both geometrically consistent and spatially complete.
While being trained solely on ScanNet++ with VGGT predictions, it generalises across architectures and datasets, significantly outperforming SOTA feed-forward 3D reconstruction models in both in-domain and out-of-domain settings.
Read more about this research using this link.
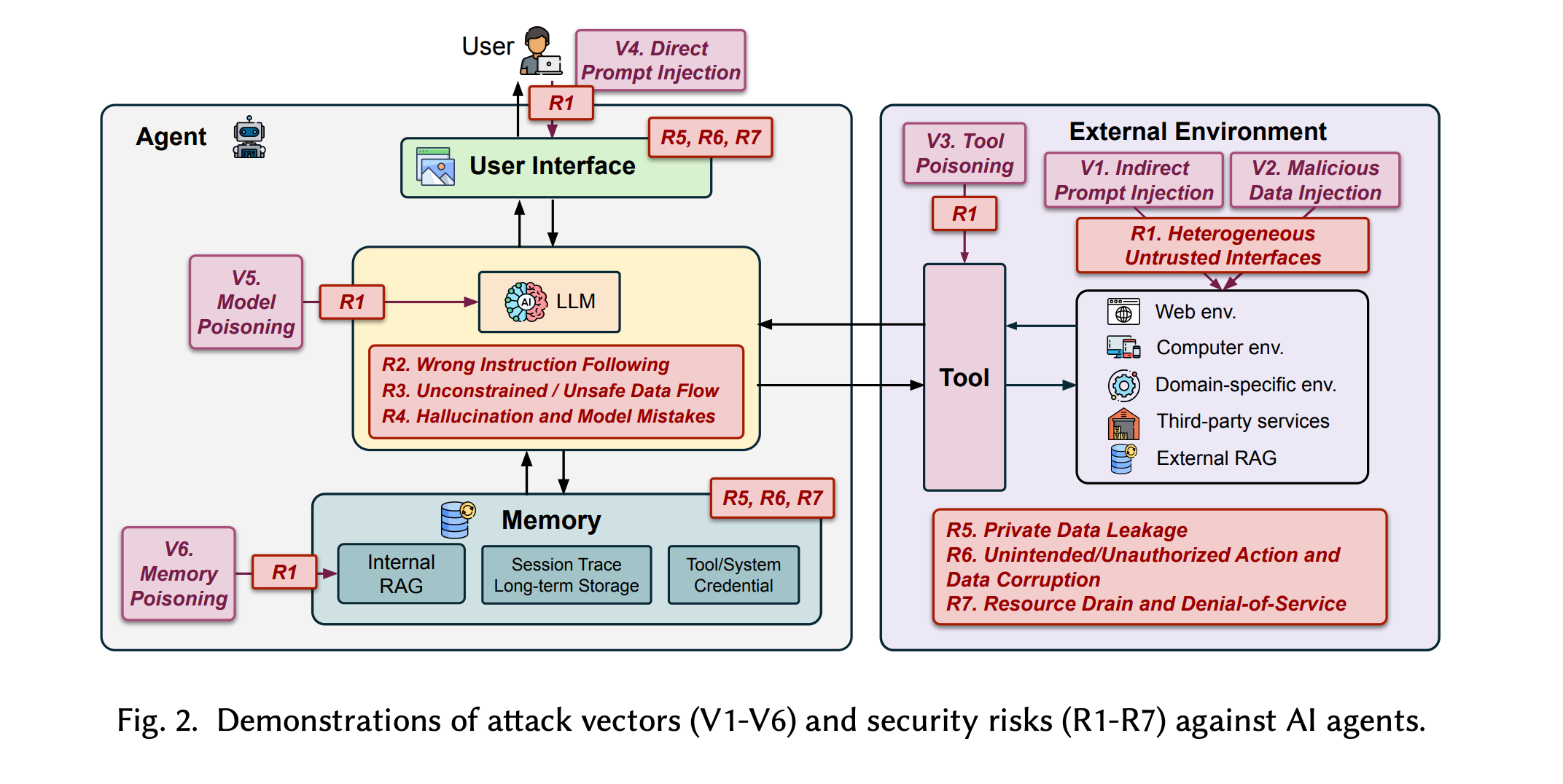
8. The Attack and Defense Landscape of Agentic AI
This research paper is a comprehensive survey of security risks in AI agent systems that examines how design choices, such as tool use, memory, and autonomy, create new attack surfaces.
It uses case studies to highlight existing gaps in securing agentic AI systems and identifies open challenges in this domain.
It also introduces the first systematic framework for understanding the security risks and defense strategies of AI agents, serving as a foundation for building secure agentic systems and advancing research.
Read more about this research using this link.
9.IndexCache
This research paper presents IndexCache, a method that improves sparse attention in LLMs by reusing attention indices across layers rather than recalculating them each time.
In a standard sparse attention mechanism, models repeatedly select the most relevant tokens at each layer, which is computationally expensive. This research shows that these selections are often similar across layers and can be cached and reused.
By adding this cross-layer index reuse method, the approach reduces computation and latency while maintaining model performance, making long-context and agent-style workloads more efficient and scalable.
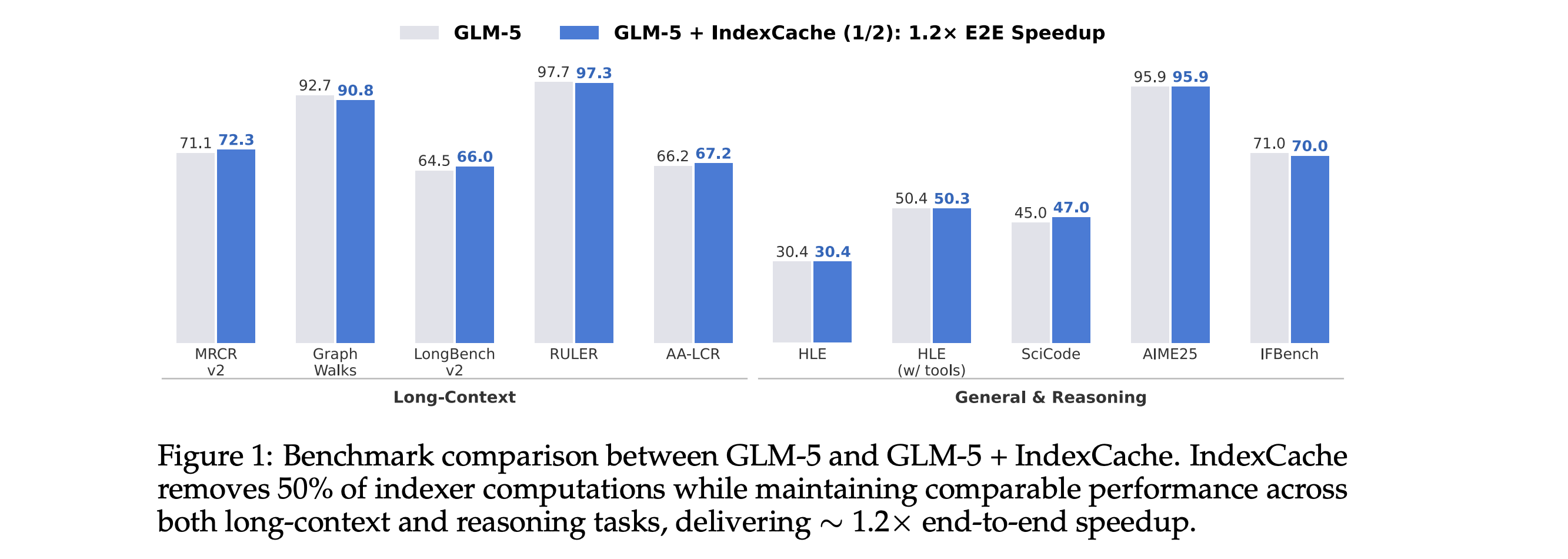
Read more about this research using this link.
10. Neural Thickets
This research paper suggests that large pre-trained LLMs already have many good solutions for task-specific experts nearby in their weights. They do not require extensive training or optimization to uncover them.
Instead of using complex optimization methods, the authors propose a simple, fully parallel post-training approach where they make small random changes to the model parameters, select the top-performing variants, and combine their predictions using majority voting.
This straightforward approach is surprisingly effective and works almost as well as standard post-training methods such as PPO, GRPO, and ES for contemporary large-scale models.
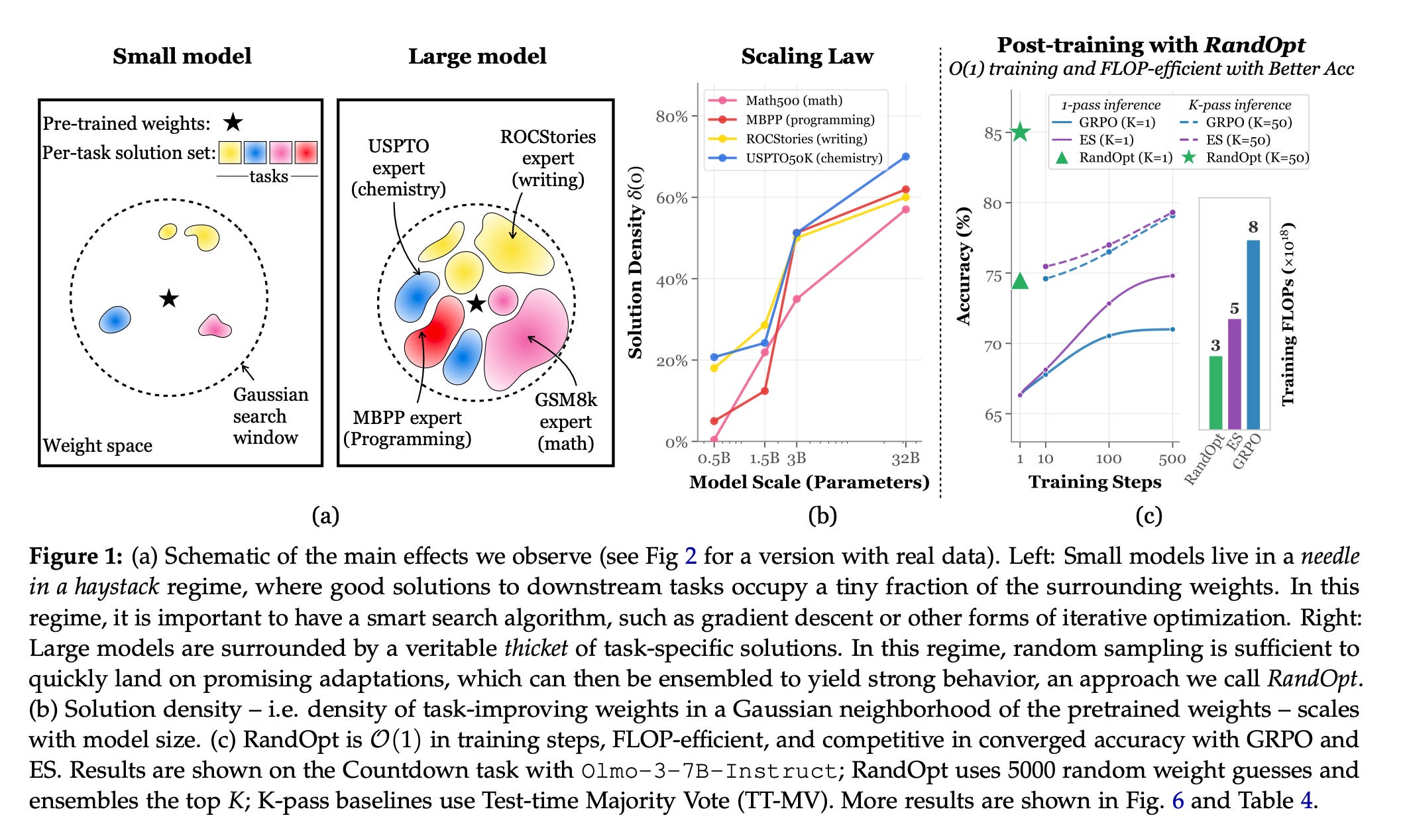
Read more about this research using this link.
This article is entirely free to read. If you loved reading it, restack and share it with others to earn referral rewards. ❤️
Join the paid tier today at a 25% discount to get access to all posts on this newsletter!
You can also check out my books on Gumroad and connect with me on LinkedIn to stay in touch.

These papers highlight how cutting-edge AI research is tackling model scaling, efficiency, and real-world adaptability across LLMs, RL, and multimodal learning