

10 Confusing LLM Concepts, Explained Simply
The role of CPU/ GPU/ TPU in LLM workflows, Pruning, Quantization, and more


10. On-policy vs. Off-policy learning
A Policy is the strategy by which an AI agent chooses actions in a given state. For an LLM, the model is the policy itself.
With on-policy learning for an LLM, the model learns from its own responses/ outputs.
A commonly used approach to train LLMs to improve them in math/ coding tasks goes like this:
Given a query or prompt, a model produces a group of responses
The responses are scored using a verifier or a reward model
An algorithm like GRPO (Group Relative Policy Optimization) is used to train the model to produce responses that score above average while pushing down below-average responses.
In contrast to the above, with off-policy learning, an LLM learns from the responses/outputs that are not generated by itself. These could come from a stronger model (the teacher model), a different version of the same model, or a dataset.
A commonly used approach for training LLMs to improve their performance in specific domains is called Distillation. In this approach:
Responses or reasoning traces are generated using a strong (teacher) model
A weaker (student) model is trained on those to imitate the teacher's responses
There’s also a recently introduced learning approach that's gaining popularity and combines on-policy and off-policy learning. It is called On-policy distillation. Curious readers are encouraged to learn more about it.
The images used in this lesson come from my book LLMs In 100 Images, which is a collection of 100 easy-to-follow visuals that explain the most important concepts you need to master to understand LLMs today.
Grab your copy today at a 30% discount using this link.

9. Pretraining vs. Mid-training vs. Post-training
All three are phases of training LLMs before they are released to end users.
Pretraining is the initial training phase that teaches a model the structure of a language and gives it basic factual knowledge of the world.
Pretraining occurs on massive datasets such as Common Crawl/ FineWeb, which consists of trillions of tokens from the web. This process is usually highly compute-intensive, and a pre-trained model is called the “Base model”.

Mid-training is the next phase, which involves further training on the base model using higher-quality, domain-specific data to improve its capabilities. This data might focus on domains like health, law, math, or code, or on improving reasoning, extending context length, or adding a new language.
Post-training is the final phase that teaches a model to become a useful and human-value-aligned assistant, rather than one that just produces the next token. Some common post-training techniques include:
Supervised fine-tuning (SFT) on datasets consisting of instruction-response pairs
RL training methods like RLHF to teach a model to produce human-value aligned responses, or RLVR to teach a model to reason well through math/ code related problems to correctly solve them
8. Zero-shot vs. One-shot vs. Few-shot prompting
All three are approaches for prompting an LLM to complete a task well.
Zero-shot prompting is when a user describes a task in the prompt and the model uses what it has already learned during its training to complete it.

One-shot prompting is when a user provides a single example of how to complete a task in the prompt.
Few-shot prompting is when a user describes how to complete a task with several examples in the prompt.

7. CPU vs. GPU vs. TPU in LLM workflows
The role of different semiconductor chips in LLM training and inference is frequently confused.
CPU (Central Processing Unit) is the standard chip that acts as the brain of every modern computer. It contains a few powerful cores that are perfect for executing tasks with sequential and branching logic at very low latency.
However, a CPU is not optimized for the parallel matrix multiplication operations that take place during LLM training or inference. Its role is in orchestration, which involves data loading and preprocessing/postprocessing, tokenization/detokenization, scheduling work onto GPUs/TPUs, running the training loop's control logic, and serving infrastructure.
CPUs have recently found a great use case in agentic workflows. This is because these workflows are dominated by tasks such as tool calls, API requests, file or database reads, and parsing outputs rather than heavy parallel computations. This is exactly where CPUs shine.
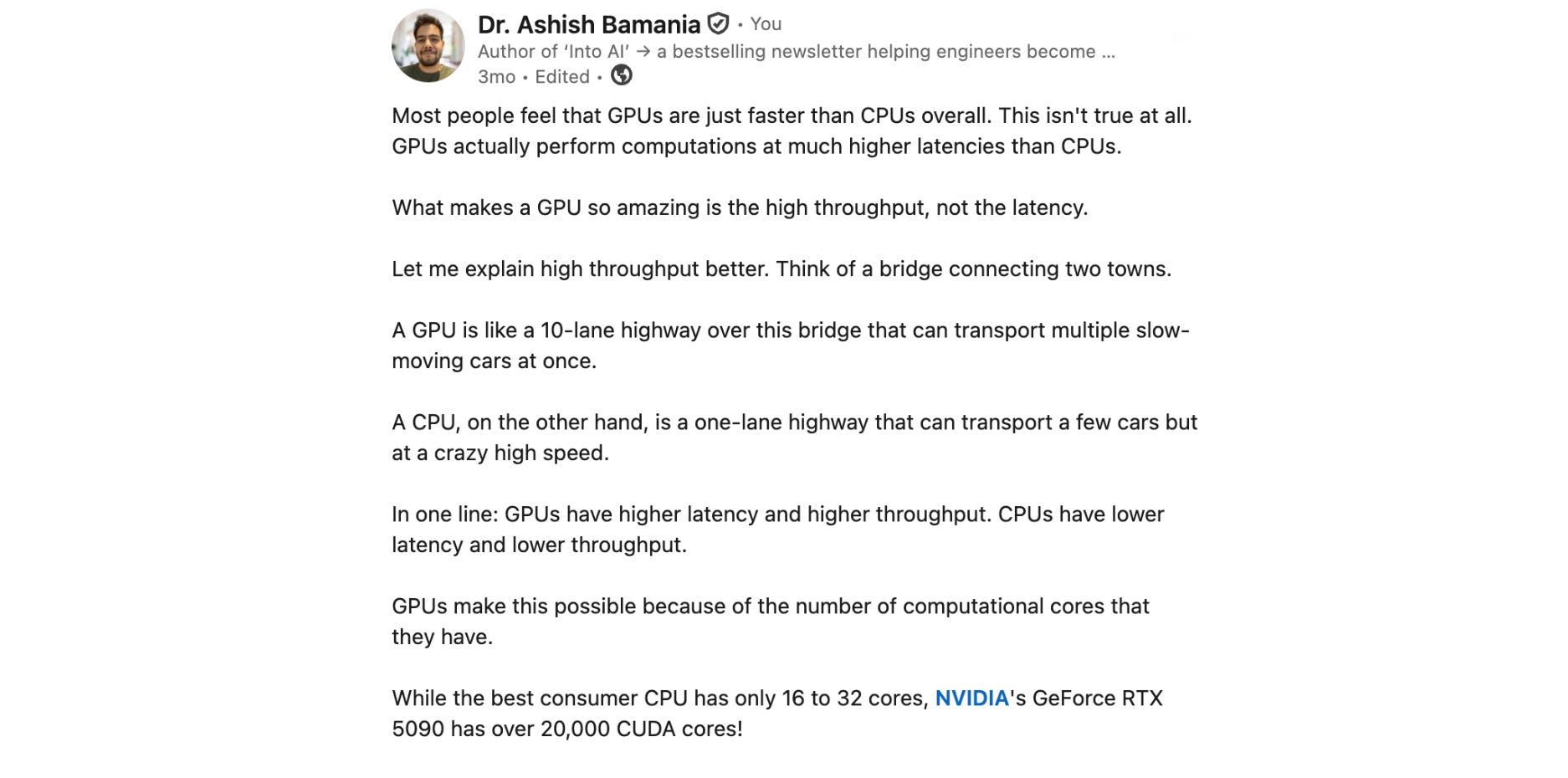
GPUs (Graphics Processing Units) are the masters of parallel computing. They have thousands of cores that are individually slower than CPU cores, but together produce massive throughput on parallel computations, especially matrix or tensor operations, which are core to LLM training and inference.
Modern GPUs also come with dedicated cores and memory for matrix multiplications. NVIDIA GPUs can be programmed with CUDA to implement highly efficient kernels (programs written for the GPU) for deep learning algorithms (for example, FlashAttention).
Tensor Processing Units (TPUs) are specialized chips designed by Google, optimized for fast and efficient tensor/matrix multiplication operations. These chips are particularly well-suited to Google's JAX ecosystem, giving it an advantage in large-scale training and inference.
A great book to learn more about TPUs can be found here.
5 resources to get started with programming LLMs at scale using GPUs/TPUs are listed below.
6. Words vs. Tokens
Words are units of language that humans understand. Tokens, on the other hand, are units of language that LLMs work with.
Tokens are created by a Tokenizer and can be whole words, subwords, or single characters. The complete set of all tokens that an LLM is familiar with is called its Vocabulary.
OpenAI models use tokenizers based on the Byte Pair Encoding (BPE) algorithm that convert human language into subwords for an LLM to work with.

5. Logits vs. Probabilities
LLMs produce raw scores called logits for each token in their vocabulary at each step of text generation. These scores are real numbers that can be negative, zero, or positive.
Logits are converted to probabilities using the softmax function, which exponentiates each logit and then divides by the sum of those exponentials.
The resulting probabilities are normalized, which means that they range between 0 and 1 and sum to 1. Each probability is the model’s estimated chance of being the next token in the sequence.

4. Context window vs. Memory
Memory is a broad term, while the context window is a specific type of memory that LLMs use by default.
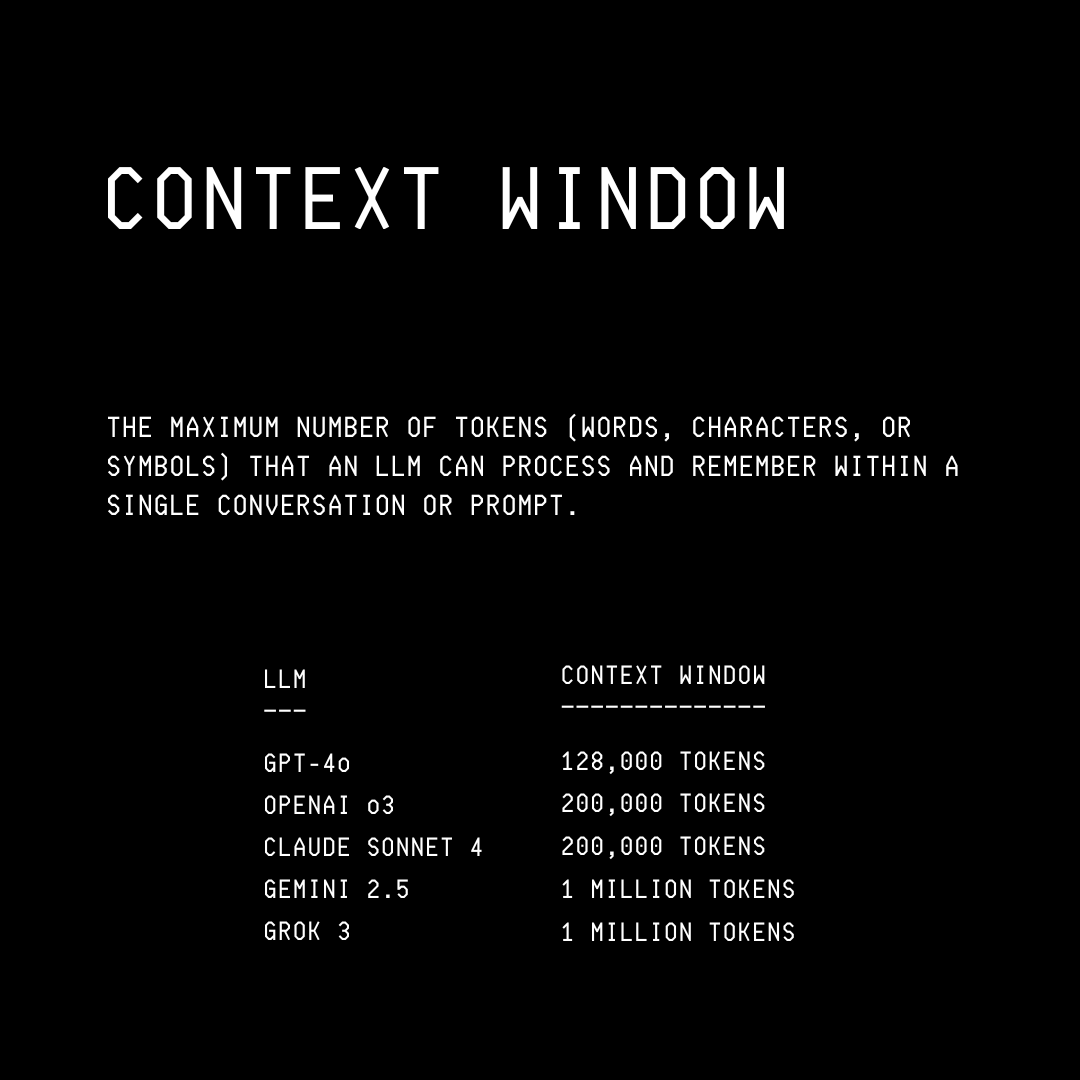
The context window is the maximum number of tokens (both input and generated) an LLM can process at once. It is the working memory of an LLM that the model attends to during use. Once a chat session ends, this information stored in the context window is discarded.
Memory, on the other hand, is a broad term that includes:
Working memory, or Short-term memory, that stores information about what the LLM is thinking about during ongoing problem-solving. This is the LLM’s context window.
Long-term memory, which is further divided into three:
Procedural memory: This stores rules or skills that can be applied to working memory to determine the LLM’s behavior.
Semantic memory: This stores general facts and knowledge about the world.
Episodic memory: This stores sequences of the LLM’s past behaviors and interactions.
A few examples of long-term memory systems are Zep, Mem0, and LangMem.
You can read more about LLM memory using the following links.

3. LLM vs. AI agents
An LLM is the model that generates output/ response for a given input/ prompt. It does not remember its past actions beyond its context window and cannot fetch external data.
An AI agent, on the other hand, has agency. It can take actions to work towards a goal by using an LLM (the “brain”) in a loop.
An AI agent:
Can call tools (web search, code execution, etc.) to access new data
Has memory to remember its past actions
Uses a control loop to plan (using an LLM), act, observe, and decide the next action until its goal is achieved
Can work with other AI agents to achieve a goal

2. Inference vs. Decoding
Inference is the process of running an LLM to produce outputs. It involves processing the given prompt, running a forward pass, and generating the output tokens. Modern LLM inference also involves batching multiple user requests, processing them efficiently on available hardware to achieve higher throughput, and streaming responses back token by token.
LLM inference takes place in two stages:
Prefill: Processing the given prompt to build the KV cache for the LLM to speed up text generation in the subsequent steps
Decode/ Decoding: Text generation by producing tokens one at a time
Decoding is a part of Inference, which involves choosing how each output token is generated.
At every step of text generation, an LLM outputs a probability distribution over all the tokens in its vocabulary, and the decoding strategy tells which token to pick from it as the next token.
Some commonly used decoding strategies are:
Greedy
Beam search
Top-P sampling
Top-K sampling
A hyperparameter called Temperature can be used with any sampling-based decoding strategy to control the randomness or creativity of the generation process.
You can read about these in detail using the link below.

1. Pruning vs. Quantization
Pruning and Quantization are both model compression techniques that reduce an LLM's memory and compute requirements while preserving accuracy.
Pruning means reducing the number of parameters in a model by setting their values to zero or by removing entire neurons, attention heads, or full layers. The removed ones are usually parameters that contribute little to the model's output and are not very important for accuracy.
Quantization, on the other hand, keeps all the parameters but reduces their numerical precision. For example, instead of representing weights as 32 or 16-bit floating-point numbers, they are converted to lower-precision numbers, such as 8 or 4-bit integers. In this way, each parameter is represented using fewer bits, requiring less memory and compute to run.
Join the paid tier today to get access to all posts in this newsletter:
👨🔬 Build and Train a Mixture-of-Experts (MoE) LLM from scratch
🚀 Train a Diffusion LLM from scratch (out next week)
and so many more!