

Distributed Training of Llama, Explained Simply
A short and simple lesson on the techniques used to train LLMs like Meta Llama on massive GPU clusters.


Understanding distributed setups for LLM training and inference is one of the biggest advantages that you can have as an engineer today. This is what we will work towards in this lesson by studying how Meta’s Llama 3 models were trained in a distributed setting.
Let’s begin!
How big are modern-day GPU clusters?
Building an LLM requires thousands of GPUs working together in sync and months of training time. This is because no single GPU has enough memory to store the model and optimizer parameters, nor does it have the compute to train a billion-parameter model on trillions of tokens in any reasonable amount of time.
The Llama 3-405B model was trained on a cluster of 16,000 GPUs (each with 80GB of HBM3) across multiple servers. Each server contained 8 GPUs and 2 CPUs, with the GPUs connected via NVLink. It took 54 days and 30.84M GPU hours to train this model.
How does LLM training occur on GPU clusters?
Four different types of parallelism were used to train the Llama 3-405B model. These are combined together, resulting in a technique called 4D parallelism.
This technique efficiently distributes computation across multiple GPUs and ensures that the following fit within each GPU’s HBM (memory):
Model parameters
Optimizer states
Gradients
Activations
The four parallelism techniques used in 4D parallelism are:
Data parallelism (DP)
Context parallelism (CP)
Tensor parallelism (TP)
Pipeline parallelism (PP)
These last two (TP and PP) are also known as Model parallelism techniques as they split the model across GPUs.
Let’s discuss them one by one.
1. Data Parallelism (DP)
The idea behind Data parallelism (DP) is to replicate the model across multiple GPUs and run the forward and backward passes in parallel on small and different batches of training data on each GPU. This is then followed by synchronizing the gradients between all GPUs.
If this were a small model being trained, DP would have worked well. But a 405B model can’t be replicated on each GPU with a mere 80 GB of memory.
This is why Llama’s 4D parallelism uses a type of Data parallelism called FSDP (Fully Sharded Data Parallelism), where, instead of replicating the model across GPUs (like in DP), FSDP shards the model parameters, optimizer states, and gradients across GPUs and temporarily gathers them on demand when they're needed for computation.
2. Context Parallelism (CP)
Training LLMs on long sequences (128K+ tokens per sequence) can exceed the memory that is available per GPU. This is because of the attention mechanism in LLMs, which scales quadratically with sequence length, as every token attends to every other token in the sequence.
This bottleneck is solved by Context parallelism (CP), which divides the input sequence into smaller segments and splits them across multiple GPUs.
You can read more about CP
3. Tensor Parallelism (TP)
Tensor parallelism (TP) splits individual weight tensors along the model’s hidden dimension into multiple chunks and distributes them across GPUs.
This means that each GPU stores and computes only a fraction of matrix multiplication operations. This matrix splitting can occur column-wise or row-wise depending on which layer they are a part of in the transformer block. Partial calculations are followed by synchronization to combine the results across all GPUs.
4. Pipeline Parallelism (PP)
Pipeline parallelism (PP) splits the layers of the LLM into partitions called stages (groups of model layers) across multiple GPUs and trains them with small batches of data (micro-batches) as in an assembly line/ pipeline. In this way, each GPU only needs to store and process a portion of the model, which significantly reduces the memory requirements per GPU.
How do these come together in 4D parallelism?
For training Llama 3-405B, GPUs in a cluster are divided into groups and labeled using a vector as [TP, CP, PP, DP], where DP is actually FSDP.
The following example shows a cluster with 16 GPUs, each of which is assigned a unique label.
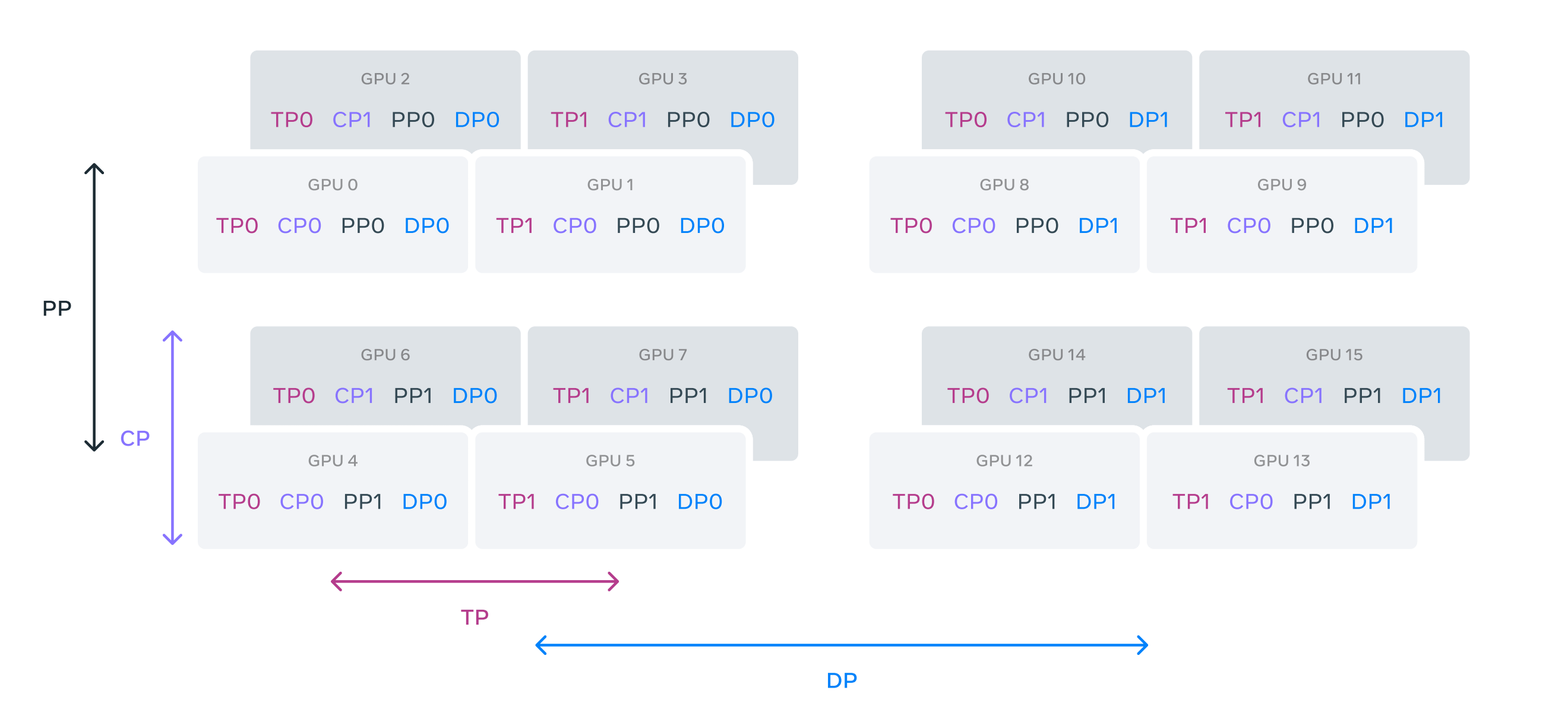
The vector label intentionally arranges the four dimensions of parallelism from the highest to the lowest communication bandwidth each requires (TP > CP > PP > DP/FSDP).
TP requires a high-bandwidth / low latency connection between GPUs to function well. This is why it is implemented within a single server where NVLink connects the 8 GPUs together.
On the other hand, PP and FSDP have lower bandwidth requirements and tolerate communication over a multi-hop network with higher latency than NVLink.
The team used Meta’s NCCLX collective communication framework to optimize this 4D parallelized large-scale LLM training.
Are there more dimensions to parallelism?
Yes, there are!
Llama 3 models are dense models. This means it contains fully connected (dense) feed-forward layers in its Transformer architecture.
But if they were Mixture-of-Experts (MoE) models, there’s another parallelism technique that could be applied. It’s called Expert Parallelism (EP).
A MoE model contains multiple small feed-forward networks, called Experts, that handle different tokens, using another network, called a Router, that selects which Expert to use for each token.
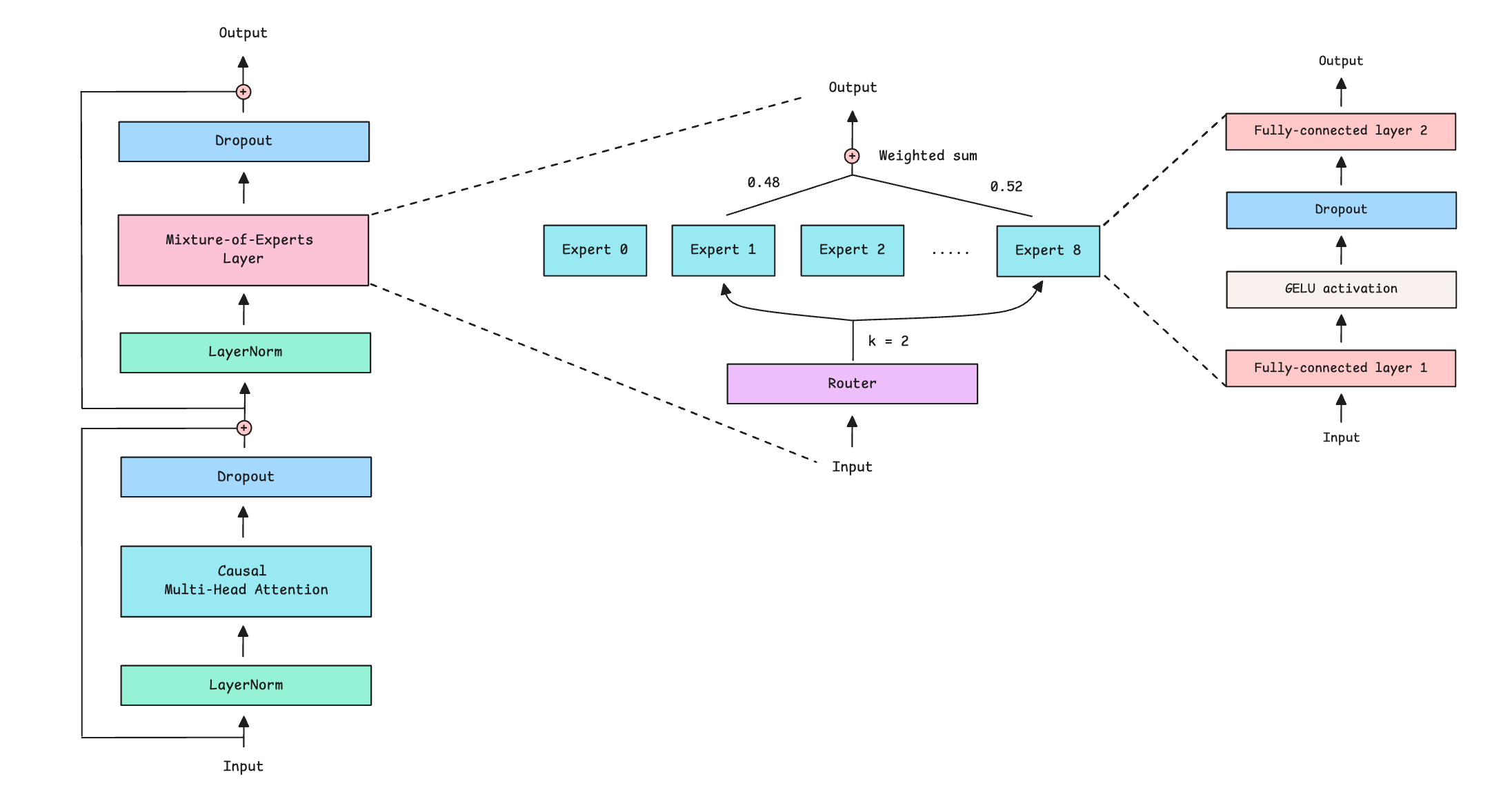
Because an MoE model can have hundreds of Experts, all of them won't fit on a single GPU. This is the bottleneck that Expert Parallelism (EP) works around. EP spreads the experts across GPUs, so each GPU holds the weights of a subset of experts at a time.
When a token is processed by the MoE layer and a router selects the expert(s) best suited to it, the token is routed to the GPU containing those experts. These experts perform the computation and send the result back to the token's original GPU.
Expert Parallelism (EP), when combined with other parallelism techniques, is referred to as 5D parallelism.
TL;DR
To summarise:
Meta used 4D parallelism to train Llama 3 models
4D parallelism used in this case consists of:
Fully Sharded Data Parallelism (FSDP)
Context Parallelism (CP)
Two Model Parallelism techniques called Tensor Parallelism (TP) and Pipeline Parallelism (PP)
Fully Sharded Data Parallelism (FSDP) shards model parameters, gradients, and optimizer states across GPUs.
Context Parallelism (CP) divides the input data along the sequence length dimension to handle very long text inputs.
Tensor Parallelism (TP) splits individual weight tensors and activations within a single layer along the model’s hidden dimension.
Pipeline Parallelism (PP) splits the model's layers sequentially into groups called stages.
Expert Parallelism (EP) is used to train Mixture-of-Experts (MoE) models. EP splits different experts across GPUs.
EP combined with 4D parallelism is referred to as 5D parallelism.
Further Reading
PyTorch FSDP: Experiences on Scaling Fully Sharded Data Parallel
Ring Attention with Blockwise Transformers for Near-Infinite Context
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
More articles on distributed training in the newsletter:


Support my writing and join the paid tier today to get access to all posts in this newsletter:
and so many more!