

Build a Mixture-of-Experts (MoE) Transformer from Scratch
Learn to build the Mixture-of-Experts (MoE) Transformer, the core architecture that powers LLMs like gpt-oss, Grok, and Mixtral, from scratch in PyTorch.

The Mixture of Experts (MoE) architecture is used by many modern-day LLMs like Grok-1, DeepSeekMoE, gpt-oss, and Mixtral (and many other proprietary LLMs whose architectural details aren’t publicly available).
This is because the MoE architecture enables sparse computation of tokens that significantly reduces the computational requirements of an LLM.
In the previous lesson on ‘Into AI’, we learned how to implement the Mixture-of-Experts (MoE) layer from scratch.

It is implemented using the class MixtureOfExpertsLayer that implements two functionalities:
The core MoE computation via the
forwardmethodRegularization using a load-balancing loss via the
load_balance_lossmethod
# Mixture of Experts layer
class MixtureOfExpertsLayer(nn.Module):
def __init__(self, embedding_dim, ff_dim, num_experts, top_k, dropout=0.1):
super().__init__()
# Each token must pick at least one expert and at most num_experts
assert 1 <= top_k <= num_experts, "top_k must be between 1 and num_experts"
self.embedding_dim = embedding_dim
self.num_experts = num_experts
self.top_k = top_k
# Router
self.router = Router(embedding_dim, num_experts, top_k)
# Experts
self.experts = nn.ModuleList([
Expert(embedding_dim, ff_dim, dropout)
for _ in range(num_experts)
])
def load_balance_loss(self, router_probs, top_k_indices):
# Dimensions
total_tokens, total_experts = router_probs.shape
# Importance: average router probability for each expert across all tokens
importance = router_probs.mean(dim=0)
# Load: fraction of all expert slots assigned to each expert
all_selected_experts = top_k_indices.reshape(-1)
load = (
torch.bincount(all_selected_experts, minlength=total_experts)
.float() / (total_tokens * self.top_k)
)
# Loss encourages uniform distribution across experts
loss = total_experts * (importance * load).sum()
return loss
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
# Flatten batch and sequence dimensions to route per token
num_tokens = batch_size * sequence_length
x_flat = x.reshape(num_tokens, embedding_dim)
# Router outputs
router_probs, top_k_indices, top_k_weights = self.router(x_flat)
# Initialize output tensor to accumulate expert outputs
output = torch.zeros_like(x_flat)
# Process each expert separately (sparse computation)
for expert_id in range(self.num_experts):
# Mask to find which tokens selected this expert
mask = (top_k_indices == expert_id)
# Skip this expert if no tokens are routed to it
if not mask.any():
continue
# Extract positions where this expert was selected
# token_ids: which tokens need this expert
# k_positions: which top-k slot this expert occupies (e.g. 0, 1, or 2 for top-3)
token_ids, k_positions = mask.nonzero(as_tuple=True)
# Get embeddings for tokens that selected this expert
expert_input = x_flat[token_ids]
# Forward pass through the expert
expert_output = self.experts[expert_id](expert_input)
# Get routing weights for this expert's contribution
weights = top_k_weights[token_ids, k_positions].unsqueeze(-1)
# Add this expert's weighted output to the final output
output[token_ids] += expert_output * weights
# Compute load-balancing auxiliary loss
aux_loss = self.load_balance_loss(router_probs, top_k_indices)
# Reshape from (num_tokens, embedding_dim) back to original dimensions
output = output.reshape(batch_size, sequence_length, embedding_dim)
return output, aux_lossIn this lesson, we will learn to integrate this layer into the Decoder-only Transformer architecture to create a Mixture-of-Experts Transformer.
Let’s begin!
Building the Mixture-of-Experts Decoder
The conventional Decoder-only Transformer architecture, which consists of the following components:
Causal (or Masked) Multi-Head Self-Attention
Feed-Forward Network (FFN)
Layer Normalization
Residual or Skip connections
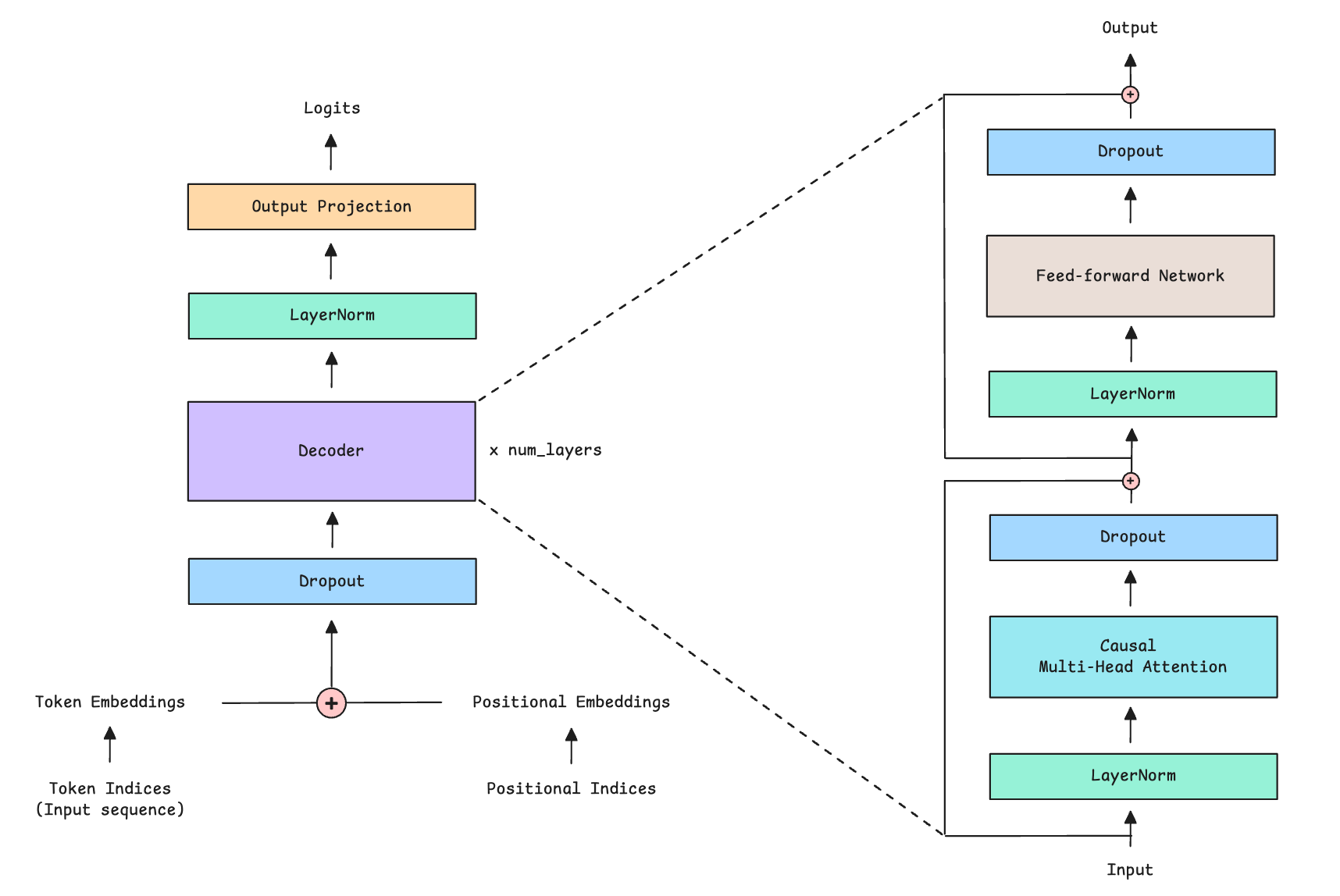
In the Mixture of Experts (MoE) architecture, the feed-forward network (FFN) is simply replaced by the Mixture of Experts layer.
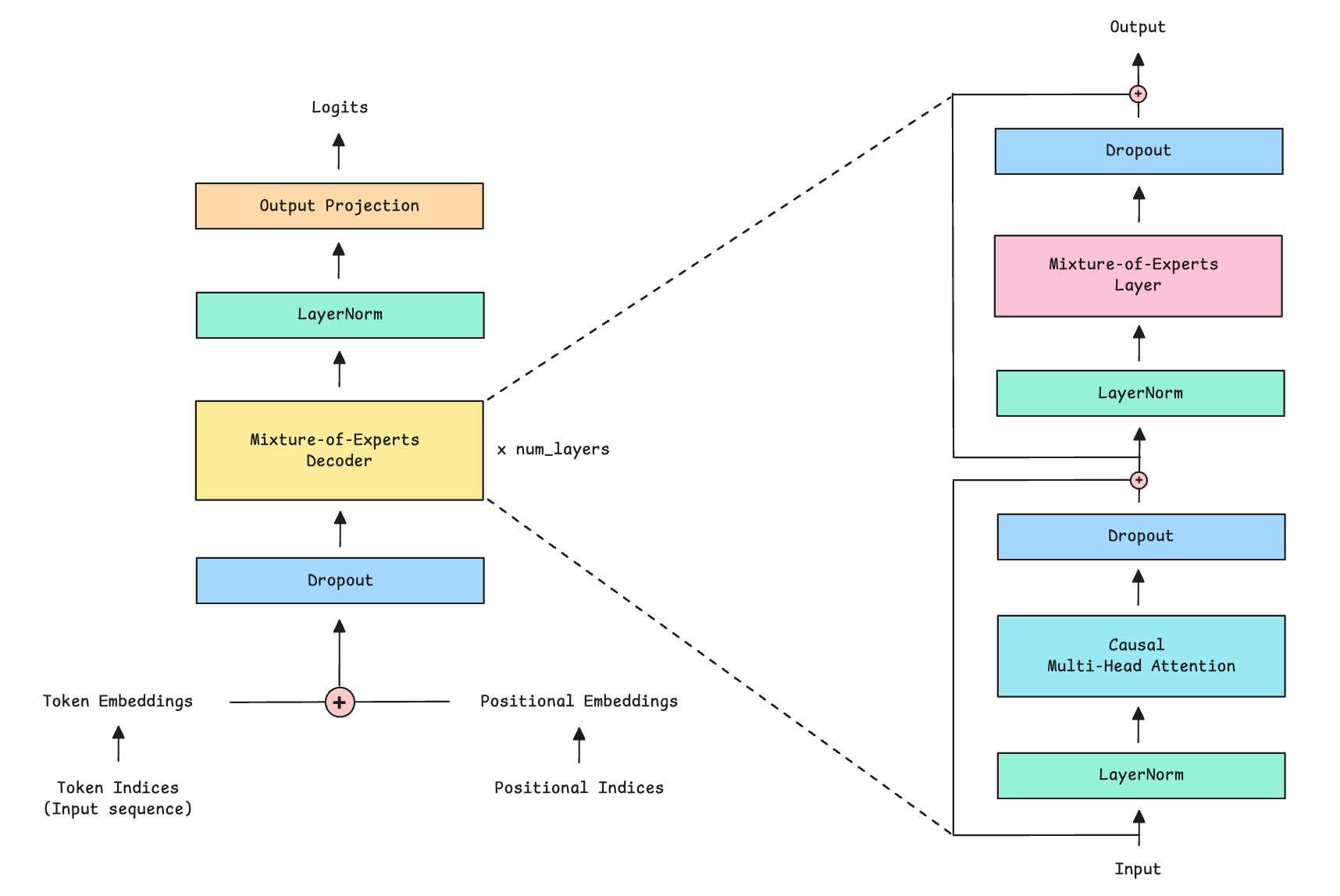
We will first focus on implementing the Mixture-of-Experts (MoE) Decoder in PyTorch, as shown below.
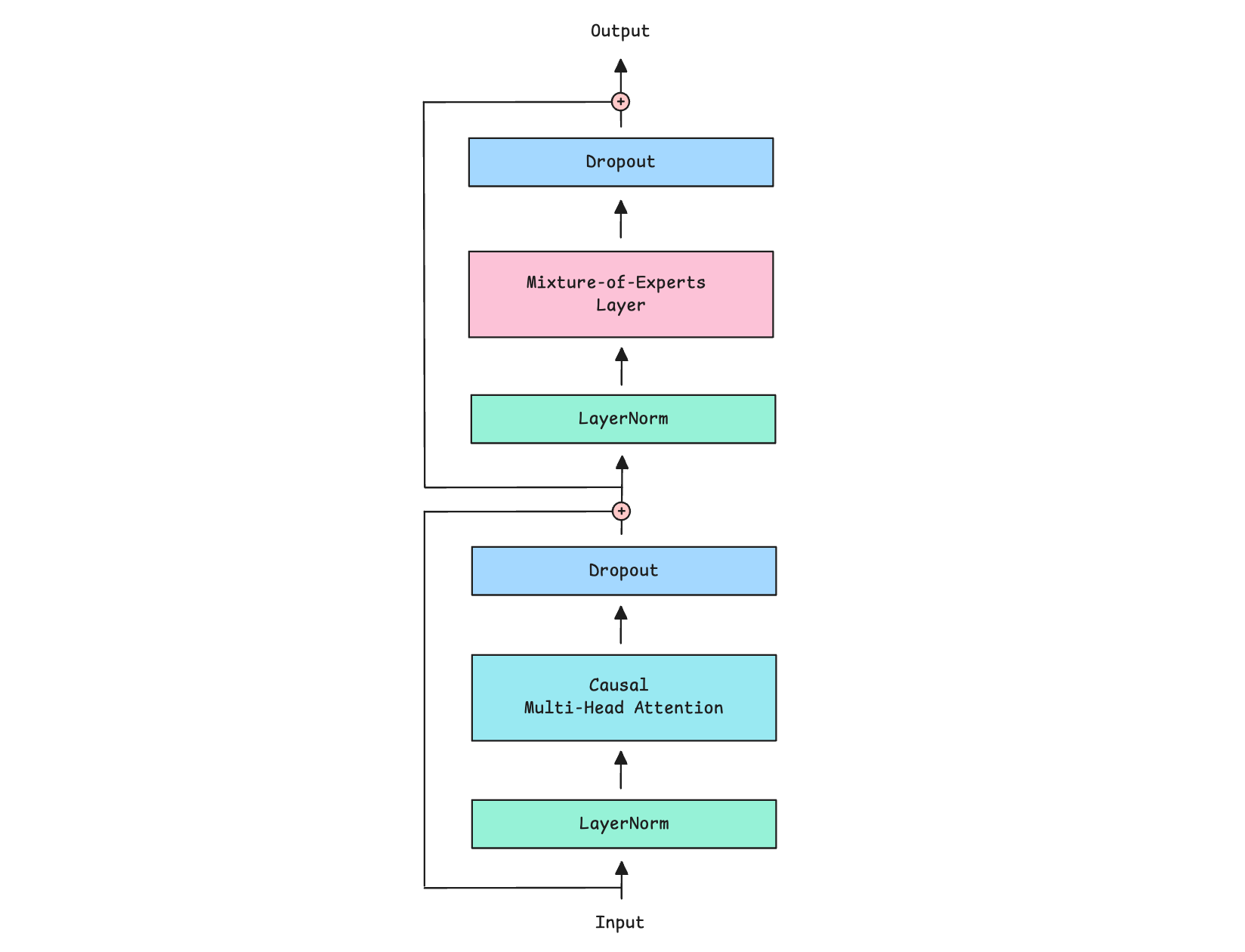
The following class MixtureOfExpertsDecoder implements the MoE Decoder.
We first apply Causal multi-head self-attention to the inputs
Next, we pass the outputs through the MoE layer
Both components use Pre-LayerNorm, which means that normalization happens before rather than after each sub-layer
Both also use Residual connections (adding the input back to the output) and Dropout to improve training stability.
Along with its output, the MoE layer also returns an auxiliary load-balancing loss to encourage balanced expert use during training. We discussed this loss in depth in the last lesson.
# Causal Multi-head Self-attention
class CausalMultiHeadSelfAttention(nn.Module):
def __init__(self, embedding_dim, num_heads):
super().__init__()
assert embedding_dim % num_heads == 0, "embedding_dim must be divisible by num_heads"
self.embedding_dim = embedding_dim
self.num_heads = num_heads
self.head_dim = embedding_dim // num_heads
self.W_q = nn.Linear(embedding_dim, embedding_dim, bias=False)
self.W_k = nn.Linear(embedding_dim, embedding_dim, bias=False)
self.W_v = nn.Linear(embedding_dim, embedding_dim, bias=False)
self.W_o = nn.Linear(embedding_dim, embedding_dim, bias=False)
def _split_heads(self, x):
batch_size, sequence_length, embedding_dim = x.shape
x = x.reshape(batch_size, sequence_length, self.num_heads, self.head_dim)
return x.transpose(1, 2)
def _merge_heads(self, x):
batch_size, num_heads, sequence_length, head_dim = x.shape
x = x.transpose(1, 2)
embedding_dim = num_heads * head_dim
x = x.reshape(batch_size, sequence_length, embedding_dim)
return x
def forward(self, x):
batch_size, sequence_length, embedding_dim = x.shape
Q = self.W_q(x)
K = self.W_k(x)
V = self.W_v(x)
Q = self._split_heads(Q)
K = self._split_heads(K)
V = self._split_heads(V)
attn_scores = Q @ K.transpose(-2, -1)
attn_scores = attn_scores / math.sqrt(self.head_dim)
causal_mask = torch.tril(torch.ones(sequence_length, sequence_length, device=x.device))
causal_mask = causal_mask.view(1, 1, sequence_length, sequence_length)
attn_scores = attn_scores.masked_fill(causal_mask == 0, float("-inf"))
attn_weights = torch.softmax(attn_scores, dim=-1)
weighted_values = attn_weights @ V
merged_heads_output = self._merge_heads(weighted_values)
output = self.W_o(merged_heads_output)
return output# Mixture-of-Experts Decoder
"""
A Decoder that combines:
1. Causal Multi-Head Self-Attention
2. MoE layer
"""
class MixtureOfExpertsDecoder(nn.Module):
def __init__(self, embedding_dim, ff_dim, num_heads, num_experts, top_k, dropout = 0.1):
super().__init__()
# Causal multi-head self-attention
self.attention = CausalMultiHeadSelfAttention(embedding_dim, num_heads)
# Mixture of experts
self.moe_layer = MixtureOfExpertsLayer(
embedding_dim = embedding_dim,
ff_dim = ff_dim,
num_experts = num_experts,
top_k = top_k,
dropout = dropout)
# Pre-LayerNorm
self.ln1 = nn.LayerNorm(embedding_dim) # LayerNorm before attention
self.ln2 = nn.LayerNorm(embedding_dim) # LayerNorm before MoE layer
# Dropout
self.dropout = nn.Dropout(dropout)
def forward(self, x):
# Self-Attention with residual connection
attn_output = self.attention(self.ln1(x))
x = x + self.dropout(attn_output)
# MoE layer with residual connection
moe_output, aux_loss = self.moe_layer(self.ln2(x))
x = x + self.dropout(moe_output)
return x, aux_lossBuilding the Mixture-of-Experts Transformer
It’s finally time to build the complete Mixture-of-Experts Transformer, as shown below.
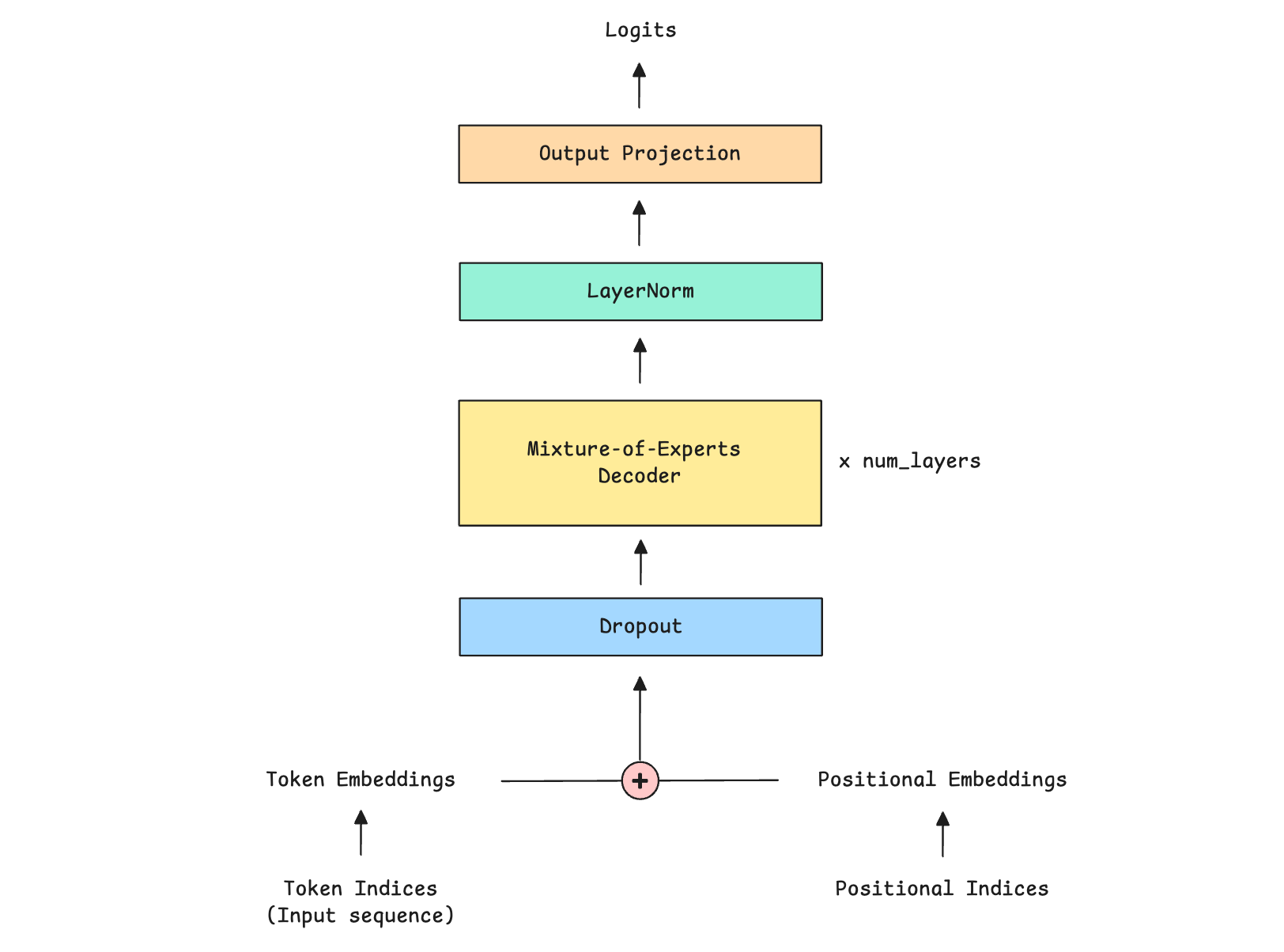
This is represented by the MixtureOfExpertsTransformer class.
The class first sets up all necessary components, which include:
Token embedding layer to convert token indices to embedding
Positional embedding layer to encode sequence positions to positional embedding
Dropout layer for regularization
Multiple MoE decoders, where each decoder contains both the Causal Multi-head self-attention mechanism and the Mixture-of-experts layer.
Layer normalization component
Output projection layer that transforms the final hidden states back to the vocabulary size
# MoE Decoder-only Transformer
class MixtureOfExpertsTransformer(nn.Module):
def __init__(
self,
vocab_size, # Total number of tokens in the vocabulary
embedding_dim, # Token embedding dimension
num_heads, # Number of attention heads in each decoder
ff_dim, # Hidden dimension of experts
num_layers, # Number of stacked MoE decoders
max_seq_length, # Max. input sequence length the model can handle
num_experts = 8, # Total number of experts per MoE layer
top_k = 3, # Number of experts to activate per token
dropout = 0.1, # Dropout
moe_aux_loss_coef = 0.01, # Coefficient for auxiliary load balancing loss
):
super().__init__()
self.max_seq_length = max_seq_length
self.moe_aux_loss_coef = moe_aux_loss_coef
# Token embedding layer
self.token_embedding = nn.Embedding(vocab_size, embedding_dim)
# Learned positional embedding layer
self.positional_embedding = nn.Embedding(max_seq_length, embedding_dim)
# Dropout
self.dropout = nn.Dropout(dropout)
# Stack of MoE decoders (total: 'num_layers')
self.decoders = nn.ModuleList([
MixtureOfExpertsDecoder(
embedding_dim,
ff_dim,
num_heads,
num_experts,
top_k,
dropout
)
for _ in range(num_layers)
])
# Final Layer Normalization layer
self.final_ln = nn.LayerNorm(embedding_dim)
# Linear layer to project hidden states to vocabulary size to get logits
self.output_proj = nn.Linear(embedding_dim, vocab_size)
def forward(self, x):
# x is token indices/ input sequence of shape (batch_size, sequence_length)
batch_size, sequence_length = x.shape
# Check that sequence length does not exceed maximum
if sequence_length > self.max_seq_length:
raise ValueError(f"Input sequence length {sequence_length} exceeds maximum sequence length {self.max_seq_length}.")
# Create positional indices: [0, 1, 2, ..., sequence_length-1]
positions = torch.arange(sequence_length, device=x.device)
# Create token embedding from token indices
token_embedding = self.token_embedding(x)
# Create positional embedding from positional indices
positional_embedding = self.positional_embedding(positions)
# Combine embeddings and add Dropout
x = self.dropout(token_embedding + positional_embedding)
# Array to store auxiliary losses from each MoE decoder
aux_losses = []
# Forward pass through MoE decoders sequentially
for decoder in self.decoders:
x, aux_loss = decoder(x)
aux_losses.append(aux_loss)
# Apply LayerNorm to the output
x = self.final_ln(x)
# Project to vocabulary size to get logits for next-token prediction
logits = self.output_proj(x)
# Mean auxiliary losses across all MoE decoders and scale by coefficient
aux_loss = torch.stack(aux_losses).mean() * self.moe_aux_loss_coef
return logits, aux_loss
Regarding the topic of the article, this is exactly what I needed after Part 1! That first lesson on the MoE layer was super clear, and now seeing how the router and expert classes connect for the full LLM build makes so much sense. Prety insightful stuff, Dr. Bamania!